Errors in Survey Data Duplicates in Social Sciences
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

9Th GESIS Summer School in Survey Methodology August 2020
9th GESIS Summer School in Survey Methodology August 2020 Syllabus for short course C: “Applied Systematic Review and Meta-Analysis” Lecturers: Dr. Jessica Daikeler Sonila Dardha E-mail: [email protected] [email protected] Homepage: https://www.gesis.org/en/institute/ https://www.researchgate.net/profile/Sonila_Dard /staff/person/Jessica.wengrzik ha Date: 12-14 August 2020 Time: 10:00-16:00 Time zone: CEST, course starts on Wednesday at 10:00 Venue: Online via Zoom About the Lecturers: Jessica is a survey methodologist and works at GESIS in the Survey Operations and Survey Statistics teams in the Survey Design and Methodology department. Jessica wrote her dissertation on "The Application of Evidence- Based Methods in Survey Methodology" with Prof. Michael Bosnjak (University of Trier & ZPID) and Prof. Florian Keusch (University of Mannheim). At GESIS she is involved in the application of evidence-based methods, in par- ticular experiments, systematic reviews and meta-analyses. She has lots of experience with different systematic review and meta-analysis projects. Her research is currently focused on data quality in web and mobile surveys, link of nonresponse and measurement errors, data linkage and, of course, methods for the accumulation of evi- dence. Sonila is a survey methodologist researching interviewer effects, response patterns, nonresponse error and 3MC surveys, and a survey practitioner coordinating cross-country comparative projects. She is currently pursuing her PhD in Survey Research Methodology at City, University of London, the home institution of the European Social Survey (ESS ERIC). Sonila has previously obtained three Master degrees, one of which in M.Sc in Statistics (Quan- titative Analysis for the Social Sciences) from KU Leuven, Belgium. -

Journal of Econometrics an Empirical Total Survey Error Decomposition
Journal of Econometrics xxx (xxxx) xxx Contents lists available at ScienceDirect Journal of Econometrics journal homepage: www.elsevier.com/locate/jeconom An empirical total survey error decomposition using data combination ∗ Bruce D. Meyer a,b,c, Nikolas Mittag d, a Harris School of Public Policy Studies, University of Chicago, 1307 E. 60th Street, Chicago, IL 60637, United States of America b NBER, United States of America c AEI, United States of America d CERGE-EI, joint workplace of Charles University and the Economics Institute of the Czech Academy of Sciences, Politických v¥z¬· 7, Prague 1, 110 00, Czech Republic article info a b s t r a c t Article history: Survey error is known to be pervasive and to bias even simple, but important, estimates Received 16 July 2019 of means, rates, and totals, such as the poverty and the unemployment rate. In order Received in revised form 16 July 2019 to summarize and analyze the extent, sources, and consequences of survey error, we Accepted 5 March 2020 define empirical counterparts of key components of the Total Survey Error Framework Available online xxxx that can be estimated using data combination. Specifically, we estimate total survey Keywords: error and decompose it into three high level sources of error: generalized coverage Total survey error error, item non-response error and measurement error. We further decompose these Administrative data sources into lower level sources such as failure to report a positive amount and errors Measurement error in amounts conditional on reporting a positive value. For errors in dollars paid by two Linked data large government transfer programs, we use administrative records on the universe Data combination of program payments in New York State linked to three major household surveys to estimate the error components previously defined. -

American Community Survey Design and Methodology (January 2014) Chapter 15: Improving Data Quality by Reducing Non-Sampling Erro
American Community Survey Design and Methodology (January 2014) Chapter 15: Improving Data Quality by Reducing Non-Sampling Error Version 2.0 January 30, 2014 ACS Design and Methodology (January 2014) – Improving Data Quality Page ii [This page intentionally left blank] Version 2.0 January 30, 2014 ACS Design and Methodology (January 2014) – Improving Data Quality Page iii Table of Contents Chapter 15: Improving Data Quality by Reducing Non-Sampling Error ............................... 1 15.1 Overview .......................................................................................................................... 1 15.2 Coverage Error ................................................................................................................. 2 15.3 Nonresponse Error............................................................................................................ 3 15.4 Measurement Error ........................................................................................................... 6 15.5 Processing Error ............................................................................................................... 7 15.6 Census Bureau Statistical Quality Standards ................................................................... 8 15.7 References ........................................................................................................................ 9 Version 2.0 January 30, 2014 ACS Design and Methodology (January 2014) – Improving Data Quality Page iv [This page intentionally left -

The Evidence from World Values Survey Data
Munich Personal RePEc Archive The return of religious Antisemitism? The evidence from World Values Survey data Tausch, Arno Innsbruck University and Corvinus University 17 November 2018 Online at https://mpra.ub.uni-muenchen.de/90093/ MPRA Paper No. 90093, posted 18 Nov 2018 03:28 UTC The return of religious Antisemitism? The evidence from World Values Survey data Arno Tausch Abstract 1) Background: This paper addresses the return of religious Antisemitism by a multivariate analysis of global opinion data from 28 countries. 2) Methods: For the lack of any available alternative we used the World Values Survey (WVS) Antisemitism study item: rejection of Jewish neighbors. It is closely correlated with the recent ADL-100 Index of Antisemitism for more than 100 countries. To test the combined effects of religion and background variables like gender, age, education, income and life satisfaction on Antisemitism, we applied the full range of multivariate analysis including promax factor analysis and multiple OLS regression. 3) Results: Although religion as such still seems to be connected with the phenomenon of Antisemitism, intervening variables such as restrictive attitudes on gender and the religion-state relationship play an important role. Western Evangelical and Oriental Christianity, Islam, Hinduism and Buddhism are performing badly on this account, and there is also a clear global North-South divide for these phenomena. 4) Conclusions: Challenging patriarchic gender ideologies and fundamentalist conceptions of the relationship between religion and state, which are important drivers of Antisemitism, will be an important task in the future. Multiculturalism must be aware of prejudice, patriarchy and religious fundamentalism in the global South. -

A Total Survey Error Perspective on Comparative Surveys
A Total Survey Error Perspective on Comparative Surveys October 2nd 2014 – ITSEW – Washington DC Beth-Ellen Pennell, University of Michigan Lars Lyberg, Stockholm University Peter Mohler, University of Mannheim Kristen Cibelli Hibben, University of Michigan (presenting author) Gelaye Worku, Stockholm University © 2014 by the Regents of the University of Michigan Presentation Outline 1. Background 2. Integrated Total Survey Error Model Contribution to Errors: Representation: Coverage, Sampling, Nonresponse errors Measurement: Validity, Measurement errors Measurement error – expanded view 3. Conclusion © 2014 by the Regents of the University of Michigan Background 1. The scope, scale, and number of multicultural, multiregional or multinational (3M) surveys continues to grow a. Examples: European Social Survey (20+ countries), the World Values Survey (75+ countries), the Gallup World Poll (160 countries) 2. The purpose is comparability – An estimate for one country should be reasonably comparable to another. 3. However, comparability in 3M surveys is affected by various error sources that we are used to considering plus some additional ones. © 2014 by the Regents of the University of Michigan Background, continued… 1. 3M surveys have an error typology that differs from monocultural surveys. a. Error sources in 3M surveys are typically amplified b. 3M surveys often require additional operations – i.e. adaptation, translation 2. Few attempts have been made to adapt the TSE framework to 3M surveys (except see: Smith’s (2011) refined TSE model). 3. The proposed TSE typology integrates error sources – and associated methodological and operational challenges that may limit comparability. © 2014 by the Regents of the University of Michigan Total Survey Error (Groves et al., 2004) © 2014 by the Regents of the University of Michigan An Integrated TSE Model Some general points: 1. -

Measurement Error Estimation Methods in Survey Methodology
Available at Applications and http://pvamu.edu/aam Applied Mathematics: Appl. Appl. Math. ISSN: 1932-9466 An International Journal (AAM) Vol. 11, Issue 1 (June 2016), pp. 97 - 114 ___________________________________________________________________________________________ Measurement Error Estimation Methods in Survey Methodology Alireza Zahedian1 and Roshanak Aliakbari Saba2 1Statistical Centre of Iran Dr. Fatemi Ave. Post code: 14155 – 6133 Tehran, Iran 2Statistical Research and Training Center Dr. Fatemi Ave., BabaTaher St., No. 145 Postal code: 14137 – 17911 Tehran, Iran [email protected] Received: May 7, 2014; Accepted: January 13, 2016 Abstract One of the most important topics that are discussed in survey methodology is the accuracy of statistics or survey errors that may occur in the parameters estimation process. In statistical literature, these errors are grouped into two main categories: sampling errors and non-sampling errors. Measurement error is one of the most important non-sampling errors. Since estimating of measurement error is more complex than other types of survey errors, much more research has been done on ways of preventing or dealing with this error. The main problem associated with measurement error is the difficulty to measure or estimate this error in surveys. Various methods can be used for estimating measurement error in surveys, but the most appropriate method in each survey should be adopted according to the method of calculating statistics and the survey conditions. This paper considering some practical experiences in calculating and evaluating surveys results, intends to help statisticians to adopt an appropriate method for estimating measurement error. So to achieve this aim, after reviewing the concept and sources of measurement error, some methods of estimating the error are revised in this paper. -

Ethical Considerations in the Total Survey Error Context
Ethical Considerations in the Total Survey Error Context Julie de Jong 3MCII International Conference July 26-29, 2016 Chicago, Illinois © 2014 by the Regents of the University of Michigan Acknowledgements • Invited paper in Advances in Comparative Survey Methods: Multicultural, Multinational and Multiregional Contexts (3MC), edited by T.P. Johnson, B.E. Pennell, I.A.L. Stoop, & B. Dorer. New York, NY: John Wiley & Sons. • Special thanks to Kirsten Alcser, Christopher Antoun, Ashley Bowers, Judi Clemens, Christina Lien, Steve Pennell, and Kristen Cibelli Hibben who contributed substantially to earlier iterations of the chapter “Ethical Considerations” in the Cross-Cultural Survey Guidelines from which this chapter draws material. © 2014 by the Regents of the University of Michigan Overview – Legal and professional regulations and socio-political contexts can lead to differences in how ethical protocols are realized across countries. – Differences in the implementation of ethical standards contributes to the sources of total survey error (TSE) • TSE describes statistical properties of survey estimates by incorporating a variety of error sources and is used in the survey design stage, in the data collection process, and evaluation and post survey adjustments (Groves & Lyberg, 2010) • The TSE framework is generally used to design and evaluate a single-country survey – The framework has been extended to 3MC surveys and the impact of TSE on overall comparison error (Smith 2011) 3 © 2014 by the Regents of the University of Michigan Objectives -

The Total Survey Error Paradigm and Challenges to Its Application in the Arab World
The Total Survey Error Paradigm and Challenges to its Application in the Arab World Kathrin Thomas1 Michael Robbins1,2 1 Princeton University 2University of Michigan 5 June 2018 Where to begin... "Honest discussions about the extent, sources of, an solutions for quality issues [...] are needed. Regionally specific issues [...] raise concerns about social desirability and underscore the need for methodological research. Technological advances [...] oer possibilities for real-time monitoring and [...] research [...]. Yet apart from a handful of studies on interviewer eects, anchoring vignettes, and a few other topics, almost no research systematically assesses the impact of the survey methods used on data quality in the Arab world." (Benstead, 2018) Puzzle Is the Arab survey world just a few decades behind? Surveys and polling fairly new: beginning in 1980s, but real interest since the Arab uprising 2011 (Benstead, 2018) While core principles of Total Survey Error (TSE) are followed, holistic concept not (yet) recognised Survey practice in the Arab world may also make application of TSE more dicult The TSE MEASUREMENT REPRESENTATION Construct Population Validity Coverage Error Measurement Sampling Frame Measurement Sampling Error Error Response Sample Processing Nonresponse Error Error Edited Data Respondents Survey Statistic (Groves & Lyberg, 2010) Representation Potentially poor coverage due to past or ongoing security treats Absence of transparent sampling frames and/or outdated censuses Limited attention given to nonresponse and incomplete -

Quality Issues in Survey Research
QualityQuality IssuesIssues inin SurveySurvey ResearchResearch DANSDANS SymposiumSymposium onon SurveySurvey DataData QualityQuality Amsterdam, April 9, 2008 Joop J. Hox & Edith D. de Leeuw, Utrecht University WhatWhat isis Quality?Quality? W. Edwards Deming Statistician & quality control expert WW II: Statistical quality control Influential in Japan’s reconstruction after WW II Forgotten in US, picked up around 1980 by Joseph Juran Deming: build quality into the process, do not rely on quality checks Focus on quality, costs will then decrease Focus on costs, quality will decrease but costs will nox 2 WhatWhat isis Quality?Quality? Juran: Quality is “Fitness for Use” Juran started thinking about quality in a wider context Attention to process quality Collect process data to monitor quality Management tools to maintain quality Maintaining quality as a continuous process This has strongly influenced the ISO (International standard setting 3 WhatWhat isis Quality?Quality? Juran: Quality is “Fitness for Use” Multi-dimensional, subjective notion depending on product, production process, and user Construction quality (e.g., IKEA quality) Operational quality (e.g., max. # of defects) Sampling statistics quality (e.g., Mean Square Error) Total Quality Management (e.g., Process quality) 4 QualityQuality inin Surveys:Surveys: FrameworkFramework Data Quality Timeliness Accuracy Accessibility Accuracy Costs = Small Errors 5 TotalTotal SurveySurvey QualityQuality More than just minimizing total survey error Add fitness for use -

Chapter 12, Survey Design and Implementation Cross-Cutting
Chapter 12: Survey Design and Implementation Cross-Cutting Protocols for Estimating Gross Savings Robert Baumgartner, Tetra Tech Subcontract Report NREL/SR-7A30-53827 April 2013 Chapter 12 – Table of Contents 1 Introduction ............................................................................................................................ 2 2 The Total Survey Error Framework ....................................................................................... 4 2.1 TSE Framework for Evaluating Survey and Data Quality .............................................. 4 2.2 Sampling Errors ............................................................................................................... 5 2.3 Nonresponse Errors .......................................................................................................... 5 2.4 Coverage Errors ............................................................................................................... 6 2.5 Measurement Errors ......................................................................................................... 7 3 Developing Questions .......................................................................................................... 14 3.1 Order of Response Alternatives ..................................................................................... 14 3.2 Rating or Ranking? ........................................................................................................ 14 3.3 Summary of Best Practices for Question Design and Order -
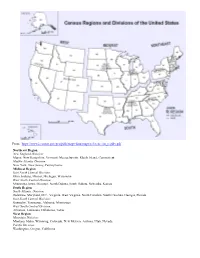
Methodology-2020.Pdf
From: https://www2.census.gov/geo/pdfs/maps-data/maps/reference/us_regdiv.pdf Northeast Region New England Division: Maine, New Hampshire, Vermont, Massachusetts, Rhode Island, Connecticut Middle Atlantic Division: New York, New Jersey, Pennsylvania Midwest Region East North Central Division: Ohio, Indiana, Illinois, Michigan, Wisconsin West North Central Division: Minnesota, Iowa, Missouri, North Dakota, South Dakota, Nebraska, Kansas South Region South Atlantic Division: Delaware, Maryland, D.C., Virginia, West Virginia, North Carolina, South Carolina, Georgia, Florida East South Central Division: Kentucky, Tennessee, Alabama, Mississippi West South Central Division: Arkansas, Louisiana, Oklahoma, Texas West Region Mountain Division: Montana, Idaho, Wyoming, Colorado, New Mexico, Arizona, Utah, Nevada Pacific Division: Washington, Oregon, California Terms and Definitions The following terms and definitions provide a detailed description of specific terms and phrases used in this publication. In addition, items in the publication tables that carry the note “See Appendix” are explained. Census Divisions: groupings of states that are subdivisions of the four census regions. There are nine census divisions, which the U.S. Census Bureau adopted in 1910 for the presentation of data. Also, see previous page with Census Regions and Divisions for the United States. For additional information, see U.S. Census Bureau’s website. Census Regions: groupings of states that subdivide the United States for the presentation of data. There are four census regions- Northeast, Midwest, South, and West. Each of the four census regions is divided into two or more census divisions. Before 1984, the Midwest region was named the North Central region. From 1910, when census regions were established, through the 1940s, there were three census regions- North, South, and West. -

The Total Survey Error Paradigm and Comparison Error: a Component-Level Evaluation
The Total Survey Error Paradigm and Comparison Error: A Component-Level Evaluation Tom W. Smith NORC at the University of Chicago International Workshop on Comparative Survey Design and Implementation Warsaw, March, 2019 Figure 1: TSE Omissions Frame Duplications Errant Inclusions Household Sampling Selection Respondent Drawing Sample Statistical Weighting Inference Coverage Nonobservation Refusals Nonresponse Unavailable Other Total Survey Error Sponsor Medium Data Collector Auspice Omission Content Instrument Other Wording Collection Response Scale Interviewer Context Distractions Setting Nonsampling Confidentiality Respondent Observation Recall Cognitive Data Entry Comprehension Presentational Coding Processing Editing/Cleaning Transferring Documentation Conceptual Weighting Analysis Statistical Tabulation Presentational Figure 2: TSE and Multiple Surveys Frame Frame Household Sampling Selection Respondent Household Sampling Selection Respondent Statistical Refusals Statistical Refusals Coverage Unavailable Coverage Nonobservation Unavailable Nonresponse Nonobservation Other Nonresponse Other Total Survey Error Total Survey Error Medium Medium Content Content Auspice Auspice Wording Wording Instrument Instrument Collection Response Scale Response Scale Collection Context Interviewer Context Nonsampling Interviewer Observation Setting Setting Nonsampling Cognitive Observation Respondent Presentational Cognitive Respondent Data Entry Presentational Data Entry Coding Processing Coding Editing/Cleaning Processing Editing/Cleaning Transferring