NBA Lineup Analysis on Clustered Player Tendencies: a New Approach to the Positions of Basketball & Modeling Lineup Efficiency of Soft Lineup Aggregates
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Determine the Position of Basketball Players Using SMART (Simple Multi-Atribute Rating Technique) Method
Determine The Position of Basketball Players Using SMART (Simple Multi-Atribute Rating Technique) Method Muhammad Ali Syakur1, Sigit Susanto Putro 2, Achmad Roviqi3, Achmad Jauhari4, Devie Rosa Anamisa5, Eka Malasari Rochman6, Mula’ab 7 {[email protected], [email protected], [email protected]} Informatic Engineering Courses, The Faculty of Engineering, Universitas trunojoyo Madura Jalan Raya Telang, PO BOX 02 Kamal, Bangkalan – 691621234567 Abstract. Basketball players usually have some playing position. A coach will determine the right position in the competition by looking the data of players. Therefore, with decision support system determine the position of the basketball player by coach is very helpful to achieve the maximum result in every competition. For building decision support system, selection position of the player comes from the player’s data using the SMART method the purpose of providing recommendation to the coaches for the selection the each player’s position, as well knowing the needs of the five player who matched is placed on the center position, point guard, Shooting guard, small forward and power forward. The result of SMART can be implemented in the election system player’s position and has a 61% accuracy is obtained from the result of comparison between the result of the calculation system with the data of the coaches recommendation. Keywords: basket ball, player position, SMART. 1 Introduction Basketball is one exercise that is done for one’s physical fitness. Many exercise can do it by someone with the abilities and their talents. One of Exercise in Indonesia is Basketball, this exercise have many fans from student in high school and collage. -

2018-19 Phoenix Suns Media Guide 2018-19 Suns Schedule
2018-19 PHOENIX SUNS MEDIA GUIDE 2018-19 SUNS SCHEDULE OCTOBER 2018 JANUARY 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 SAC 2 3 NZB 4 5 POR 6 1 2 PHI 3 4 LAC 5 7:00 PM 7:00 PM 7:00 PM 7:00 PM 7:00 PM PRESEASON PRESEASON PRESEASON 7 8 GSW 9 10 POR 11 12 13 6 CHA 7 8 SAC 9 DAL 10 11 12 DEN 7:00 PM 7:00 PM 6:00 PM 7:00 PM 6:30 PM 7:00 PM PRESEASON PRESEASON 14 15 16 17 DAL 18 19 20 DEN 13 14 15 IND 16 17 TOR 18 19 CHA 7:30 PM 6:00 PM 5:00 PM 5:30 PM 3:00 PM ESPN 21 22 GSW 23 24 LAL 25 26 27 MEM 20 MIN 21 22 MIN 23 24 POR 25 DEN 26 7:30 PM 7:00 PM 5:00 PM 5:00 PM 7:00 PM 7:00 PM 7:00 PM 28 OKC 29 30 31 SAS 27 LAL 28 29 SAS 30 31 4:00 PM 7:30 PM 7:00 PM 5:00 PM 7:30 PM 6:30 PM ESPN FSAZ 3:00 PM 7:30 PM FSAZ FSAZ NOVEMBER 2018 FEBRUARY 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 2 TOR 3 1 2 ATL 7:00 PM 7:00 PM 4 MEM 5 6 BKN 7 8 BOS 9 10 NOP 3 4 HOU 5 6 UTA 7 8 GSW 9 6:00 PM 7:00 PM 7:00 PM 5:00 PM 7:00 PM 7:00 PM 7:00 PM 11 12 OKC 13 14 SAS 15 16 17 OKC 10 SAC 11 12 13 LAC 14 15 16 6:00 PM 7:00 PM 7:00 PM 4:00 PM 8:30 PM 18 19 PHI 20 21 CHI 22 23 MIL 24 17 18 19 20 21 CLE 22 23 ATL 5:00 PM 6:00 PM 6:30 PM 5:00 PM 5:00 PM 25 DET 26 27 IND 28 LAC 29 30 ORL 24 25 MIA 26 27 28 2:00 PM 7:00 PM 8:30 PM 7:00 PM 5:30 PM DECEMBER 2018 MARCH 2019 SUN MON TUE WED THU FRI SAT SUN MON TUE WED THU FRI SAT 1 1 2 NOP LAL 7:00 PM 7:00 PM 2 LAL 3 4 SAC 5 6 POR 7 MIA 8 3 4 MIL 5 6 NYK 7 8 9 POR 1:30 PM 7:00 PM 8:00 PM 7:00 PM 7:00 PM 7:00 PM 8:00 PM 9 10 LAC 11 SAS 12 13 DAL 14 15 MIN 10 GSW 11 12 13 UTA 14 15 HOU 16 NOP 7:00 -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -
No Fatalities in Melrose Train Crash
THURSDAY,APRIL 6, 2017 Inside: 75¢ STEM program reaching out — Page 2A Vol. 89 ◆ No. 5 SERVING CLOVIS, PORTALES AND THE SURROUNDING COMMUNITIES EasternNewMexicoNews.com Candidate grilled on arts, retention ❏ Charles Crespy of Michigan third to be interviewed at ENMU. By Alisa Boswell MANAGING EDITOR [email protected] PORTALES — The third candi- date for Eastern New Mexico University president as he was greeted with concerns surround- ing fine arts, liberal arts, retention and more. After giving a brief introduction Staff photo: Tony Bullocks of himself in which he shared an extensive background in New One member of the train crew was transported to the hospital, but there were no fatalities in the crash on Melrose's east side. Mexico and Texas, including four degrees from the University of New Mexico in Albuquerque, Charles Crespy of Michigan answered questions from faculty members Wednesday afternoon. No fatalities “As we’re looking at them (the state) shifting the way they’re using gen. eds. (general education requirements) or the way they’re viewing a college degree, what we’re seeing is the humanity pro- in Melrose grams are suffering, not just in terms of people not taking the same amount of gen eds, but stu- dents not even knowing what degrees in certain areas mean,” said Liberal Arts Department train crash Staff photo: Tony Bullocks Chair Carol Erwin. “I’m wonder- ❏ Witness: ‘I thought attempting to cross the tracks. The accident occurred just before 10 a.m. when a train struck a ing what your philosophy is but Witnesses described hearing a semi-tractor attempting to cross the tracks. -
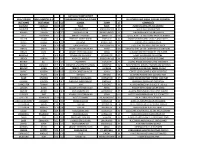
July 10-11 Camp Report (A-B-C Order) Bold Denotes D-1
JULY 10-11 CAMP REPORT (A-B-C ORDER) BOLD DENOTES D-1 UNDERLINED/ITALICS=D-2/NAIA ALL OTHERS HAVE SMALL COLLEGE POTENTIAL LAST NAME FIRST NAME HT CL SCHOOL TOWN ST COMMENTS ASHFORD MARCUS 5'10 12 PARIS PARIS KY POINT CREATES OFF THE DRIBBLE BALDWIN TYLER 6'1 10 GRACE BAPTIST MADISONVILLE KY SOLID ROLE PLAYER TYPE BARNES JOSHUA 5'10 11 SIMON KENTON INDEPENDENCE KY LEAD MAN HANDLES AND PASSES BELL CAMAYAN 5'5 8 MARIETTA MIDDLE MARIETTA GA QUICK, ATHLETIC AND LONG BACKCOURTMAN BILITER EVAN 5'8 7 PINEVILLE INDEPENDENT PINEVILLE KY HARD WORKER WHO SHOOTS AND PASSES BOLES ISAIAH 6'5 12 CAVERNA HORSE CAVE KY STRONG POST BANGS INSIDE BOX LIAM 5'10 10 GRACE BAPTIST MADISONVILLE KY EXCELS AT DISTRIBUTING THE ROCK BRADS JAMES 5'9 12 LEGACY CHRISTIAN ACAD XENIA OH POSSESSES ALL OF THE INGREDIENTS FOR POINT BRADS CLINT LEGACY CHRISTIAN ACAD XENIA OH A LEADER ON BOTH ENDS OF THE FLOOR BRANNEN CJ 6'2 11 COVINGTON CATHOLIC COVINGTON KY LANKY SWINGMAN CAN SCORE BROCK ABRAM 5'7 8 KNOX CO. MIDDLE BARBOURVILLE KY CRAFTY POINT GUARD GOT GAME BROWN ELI 5'7 9 TILGHMAN PADUCAH KY A LONG RANGE SHOOTER WHO STROKES IT BROWN DOMINIC 5'7 9 MEMPHIS UNIVERSITY SCHOOL MEMPHIS TN POINT SHOOTS, DRIVES, FINISHES AND DEFENDS BRYANT VANN 6'7 12 TRINITY CHRISTIAN JACKSON TN MOBILE 3-4 CAN PLAY INSIDE OR OUT BURKE ASHTON 5'10 12 LEGACY CHRISTIAN ACAD XENIA OH CRAFTY LEAD GUARD IS VERY VERSATILE BURNEY KYLAN 6'0 12 ANTIOCH ANTIOCH TN SLASHING PENETRATOR DEFENDS TOO BUSH LINCOLN 6'5 10 FREDERICK DOUGLASS LEXINGTON KY GOOD INSIDE/OUTSIDE THREAT CAN PLAY CALLEBS HAYDEN 5'9 8 PINEVILLE INDEPENDENT PINEVILLE KY POSSESSES EXCELLENT POTENTIAL CARPENTER TOMMY 5'9 8 IHM FLORENCE KY A HARD WORKER WHO GIVES IT HIS ALL CARSON BLAKE LEGACY CHRISTIAN ACAD XENIA OH PASSER WITH GOOD COURT SENSE CARVER ASHER 6'0 9 MUHLENBERG CO. -
Astronaut Gives Inspiration Vention’S March 30 Report, One in 88 Children Are Affected on the Web: by Hannah Jane Deciutiis June 2011
1 THE DAILY TEXAN Serving the University of Texas at Austin community since 1900 Nicki Minaj releases her second album Wildcats win their eighth national title with help of her alter ego, Roman Zolanski against Kansas LIFE&ARTS PAGE 12 SPORTS PAGE 7 >> Breaking news, blogs and more: www.dailytexanonline.com @thedailytexan facebook.com/dailytexan Tuesday, April 3, 2012 University shifts orientation focus to academics TODAY By Megan Strickland Powers Jr. said the increasing em- “Look at the map and think, ‘OK, so Powers said graduating in four ins and outs of living on their own Daily Texan Staff phasis on academics will include if I want to get to Boston there are years is something parents expect, while becoming oriented. making sure students know differ- a number of ways to get there, but I and without doing so students and “What goes on outside the class- With two months until the class ent pathways to graduation, to re- ought to start out heading out some- parents spend more on tuition, liv- room is a major part of what I call the Calendar of 2016 begins arriving on campus duce the number of students who where Northeast.’ You have a lot of ing expenses, and face the additional overall education of students, wheth- to register for their freshman classes, take more than four years to grad- students who get to their sophomore cost of lost income caused by late en- er they are working for The Dai- Terror Tuesday University officials announced Mon- uate. No specific programs have year and will report, ‘I started west try into the workforce. -

The Effect Alternate Player Efficiency Rating Has on NBA Franchises Regarding Winning and Individual Value to an Organization
St. John Fisher College Fisher Digital Publications Sport Management Undergraduate Sport Management Department Spring 2012 The Effect Alternate Player Efficiency Rating Has on NBA Franchises Regarding Winning and Individual Value to an Organization Anthony Van Curen St. John Fisher College Follow this and additional works at: https://fisherpub.sjfc.edu/sport_undergrad Part of the Sports Management Commons How has open access to Fisher Digital Publications benefited ou?y Recommended Citation Van Curen, Anthony, "The Effect Alternate Player Efficiency Rating Has on NBAr F anchises Regarding Winning and Individual Value to an Organization" (2012). Sport Management Undergraduate. Paper 35. Please note that the Recommended Citation provides general citation information and may not be appropriate for your discipline. To receive help in creating a citation based on your discipline, please visit http://libguides.sjfc.edu/citations. This document is posted at https://fisherpub.sjfc.edu/sport_undergrad/35 and is brought to you for free and open access by Fisher Digital Publications at St. John Fisher College. For more information, please contact [email protected]. The Effect Alternate Player Efficiency Rating Has on NBAr F anchises Regarding Winning and Individual Value to an Organization Abstract For NBA organizations, it can be argued that success is measured in terms of wins and championships. There are major emphases placed on the demand for “superstar” players and the ability to score. Both of which are assumed to be a player’s value to their respective organization. However, this study will attempt to show that scoring alone cannot measure success. The research uses statistics from the 2008-2011 seasons that can be used to measure success through aspects such as efficiency, productivity, value and wins a player contributes to their organization. -

Player Benchmarking and Outcomes: a Behavioral Science Approach
Player Benchmarking and Outcomes: A Behavioral Science Approach Ambra Mazzelli (Asia School of Business & MIT) Robert Nason (Concordia University) Track: Basketball Paper ID: 1548699 1. Introduction Benchmarking is important to monitor and provide feedback to players on their performance. (i.e. are they under or overperforming). Behavioral science research, especially that grounded in social psychology, indicates that performance feedback has a strong impact on human behavior including: individual motivation (Deci, 1972; DeNisi, Randolph, & Blencoe, 1982; Pavett, 1983), risk-taking (Kacperczyk et al., 2015; Krueger Jr & Dickson, 1994; March & Shapira, 1992), and performance (Sehunk, 1984; Smither, London, & Reilly, 2005). As a result, performance feedback that is provided to players has the potential to induce changes in player performance. For example, Hall of Famers Shaquille O'Neal and Charles Barkley recently gave voice to negative performance feedback regarding Philadelphia 76ers Center Joel Embiid by openly criticizing him on TNT’s Inside the NBA. Early in the 2019 season, Joel Embiid’s player efficiency rating (PER) currently ranks an impressive 11th in the league (24.73), but is under his own past performance (2018/2019 PER = 26.21)1. Shaq and Charles suggested that Embiid’s recent relative underperformance was due to a lack of motivation and made a point of comparing Embiid to centers on other teams with higher PERs, such as Giannis Antetokounmpo and Anthony Davis. In the next game following Shaq and Charles comments (December 12, 2019 vs. the Boston Celtics) Embiid posted his best game of the season with a season high 38 points and a plus minus of +21 (in a game that the Sixers only won by 6 points). -

Box Score Hawks
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX Saturday, March 17, 2018 BMO Harris Bradley Center, Milwaukee, WI Officials: #42 Eric Lewis, #20 Leroy Richardson, #59 Gary Zielinski Game Duration: 2:22 Attendance: 18717 (Sellout) VISITOR: Atlanta Hawks (20-50) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 12 Taurean Prince F 39:45 13 26 4 13 8 8 2 6 8 1 2 0 4 2 -7 38 20 John Collins F 26:28 6 8 0 0 3 3 2 10 12 1 4 0 2 0 13 15 14 Dewayne Dedmon C 31:24 3 7 2 4 2 2 1 7 8 2 3 2 5 2 -2 10 2 Tyler Dorsey G 17:51 1 3 1 3 0 0 0 3 3 3 1 1 1 0 -5 3 17 Dennis Schroder G 34:34 6 13 1 2 5 5 0 3 3 9 6 1 3 0 7 18 31 Mike Muscala 28:13 4 9 2 5 2 2 2 4 6 0 1 1 3 0 -18 12 22 Isaiah Taylor 24:57 1 4 0 1 5 6 0 2 2 6 4 1 0 0 -13 7 8 Damion Lee 20:54 2 8 1 4 2 2 1 1 2 1 4 1 1 0 0 7 4 Andrew White III 09:20 3 6 1 3 0 0 0 0 0 0 0 0 0 0 2 7 34 Tyler Cavanaugh 06:34 0 1 0 1 0 0 0 0 0 0 0 0 0 0 -2 0 95 DeAndre' Bembry NWT - Injury/Illness - Abdominal strain 11 Josh Magette DNP - Coach's decision 18 Miles Plumlee DNP - Coach's decision 240:00 39 85 12 36 27 28 8 36 44 23 25 7 19 4 -5 117 45.9% 33.3% 96.4% TM REB: 5 TOT TO: 19 (22 PTS) HOME: MILWAUKEE BUCKS (37-32) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 22 Khris Middleton F 37:03 6 14 2 4 9 9 0 7 7 2 4 1 3 0 8 23 34 Giannis Antetokounmpo F 39:24 12 25 2 6 7 8 4 8 12 7 5 4 2 2 2 33 31 John Henson C 34:28 3 8 0 0 5 6 3 4 7 2 1 1 1 2 7 11 21 Tony Snell G 29:13 4 8 3 5 0 0 0 5 5 1 1 1 0 0 13 11 6 Eric Bledsoe G 30:32 5 10 1 2 8 9 1 2 3 9 4 2 5 1 2 19 11 Brandon Jennings 17:28 1 4 0 2 0 0 0 2 2 5 1 0 0 2 3 2 23 Sterling Brown 07:33 0 0 0 0 0 0 0 2 2 0 1 1 0 0 -4 0 7 Thon Maker 12:01 3 4 2 2 0 0 0 1 1 1 4 0 0 0 -2 8 12 Jabari Parker 20:30 7 12 1 3 0 0 1 3 4 2 1 0 0 0 -5 15 3 Jason Terry 11:48 0 1 0 1 0 0 0 1 1 2 2 2 1 1 1 0 15 Shabazz Muhammad DNP - Coach's decision 40 Marshall Plumlee DNP - Coach's decision 5 D.J. -

Forecasting Most Valuable Players of the National Basketball Association
FORECASTING MOST VALUABLE PLAYERS OF THE NATIONAL BASKETBALL ASSOCIATION by Jordan Malik McCorey A thesis submitted to the faculty of The University of North Carolina at Charlotte in partial fulfillment of the requirements for the degree of Master of Science in Engineering Management Charlotte 2021 Approved by: _______________________________ Dr. Tao Hong _______________________________ Dr. Linquan Bai _______________________________ Dr. Pu Wang ii ©2021 Jordan Malik McCorey ALL RIGHTS RESERVED iii ABSTRACT JORDAN MALIK MCCOREY. Forecasting Most Valuable Players of the National Basketball Association. (Under the direction of DR. TAO HONG) This thesis aims at developing models that would accurately forecast the Most Valuable Player (MVP) of the National Basketball Association (NBA). R programming language was used in this study to implement different techniques, such as Artificial Neural Networks (ANN), K- Nearest Neighbors (KNN), and Linear Regression Models (LRM). NBA statistics were extracted from all of the past MVP recipients and the top five runner-up MVP candidates from the last ten seasons (2009-2019). The objective is to forecast the Point Total Ratio (PTR) for MVP during the regular season. Seven different underlying models were created and applied to the three techniques in order to produce potential outputs for the 2018-19 season. The best models were then selected and optimized to form the MVP forecasting algorithm, which was validated by predicting the MVP of the 2019-20 season. Ultimately, two underlying models were most robust under the LRM framework, which is considered the champion approach. As a result, two combination models were constructed based on the champion approach and proved to be most efficient. -

New Coach + Quick Learners = Fast Start First-Year Coach Luke Flockerzi Introduces a New Offensive System As Men’S Basketball Gets Off to a Quick Start
sPoRts mEn’s BaskEtBall New Coach + Quick Learners = Fast Start First-year coach luke Flockerzi introduces a new offensive system as men’s basketball gets off to a quick start. By Dennis O'Donnell Where’s the center? And the power forwards, for that matter? As the Roches- ter men’s basketball team takes to the court this winter, Yellowjacket fans used to see- ing players in traditional positions will need to acquaint themselves with a new way of thinking about how to organize five athletes and a basketball. Gone is the standard system geared to- ward a point guard, off guard, small for- ward, power forward, and center. Instead, the Yellowjackets feature four perimeter positions and a low-post threat, known as the “hub.” Let first-year coach Luke Flockerzi draw it up: Most times on offense, Rochester will set four players high on the perimeter and one—the hub—low, closer to the basket. The players will analyze what the defense shows, then run the best offense to counter- act it. It’s not one-on-one basketball. It’s a mixture of seeing, thinking, and reacting— an approach that Flockerzi believes gives his players the freedom to make decisions and play basketball. “Anyone can bring the ball up the court,” Flockerzi says. “The point guard doesn’t have to initiate the offense because posi- tions are interchangeable.” Flockerzi debuted the system this win- ter as he took over the head coaching du- ties for the Yellowjackets. The former head coach at Skidmore College, Flockerzi suc- ceeds Mike Neer '88W (MS), who stepped down last spring after leading the Yellow- jackets for 34 seasons and establishing the program as one of the winningest in NCAA Division III. -

How to Play Basketball Offense - Description of Team Positions
How to Play Basketball Offense - Description of Team Positions Over the years, as shooting, passing, and dribbling have become more sophisticated, offensive alignments have changed. They probably will continue changing in the future. Rule changes often dictate this. For example, take the three-point shot. This is changing the philosophy of a lot of coaches. Previous to the three-point shot, big men were dominating the game. Teams constantly looked for ONLY a close-in shot. As a result, most defenses packed back in tight. The three-point shot is changing all this. This new rule has opened up the game. Defenses must come out. It is quite common to see coaches using 3 and 4 guard offenses. Some of them even have their offensive teams and defensive teams, substituting freely to suit the particular need. Fundamentals, however, remain much as they were 40 years ago. Things that worked then, still work today. The terminology used to describe offensive alignments are different than they were 40 years ago. Some team offenses have evolved so that every player must be able to play at any and all positions. The flex offense is an example. Yet, this type offense is over 30 years old. Us old timers called it "the shuffle." In either offense, the center often finds himself out at a guard position. This type offense is well suited for today's rules; however, adjustments are made to fit the abilities of available players. High school coaches always have to adapt. College coaches simply recruit the players to fill a void.