DISTRIBUTED DATABASE OPTIMIZATIONS with Nosql MEMBERS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SD-SQL Server: Scalable Distributed Database System
The International Arab Journal of Information Technology, Vol. 4, No. 2, April 2007 103 SD -SQL Server: Scalable Distributed Database System Soror Sahri CERIA, Université Paris Dauphine, France Abstract: We present SD -SQL Server, a prototype scalable distributed database system. It let a relational table to grow over new storage nodes invis ibly to the application. The evolution uses splits dynamically generating a distributed range partitioning of the table. The splits avoid the reorganization of a growing database, necessary for the current DBMSs and a headache for the administrators. We il lustrate the architecture of our system, its capabilities and performance. The experiments with the well -known SkyServer database show that the overhead of the scalable distributed table management is typically minimal. To our best knowledge, SD -SQL Server is the only DBMS with the discussed capabilities at present. Keywords: Scalable distributed DBS, scalable table, distributed partitioned view, SDDS, performance . Received June 4 , 2005; accepted June 27 , 2006 1. Introduction or k -d based with respect to the partitioning key(s). The application sees a scal able table through a specific The explosive growth of the v olume of data to store in type of updateable distributed view termed (client) databases makes many of them huge and permanently scalable view. Such a view hides the partitioning and growing. Large tables have to be hash ed or partitioned dynamically adjusts itself to the partitioning evolution. over several storage sites. Current DBMSs, e. g., SQL The adjustment is lazy, in the sense it occurs only Server, Oracle or DB2 to name only a few, provide when a query to the scalable table comes in and the static partitioning only. -

Socrates: the New SQL Server in the Cloud
Socrates: The New SQL Server in the Cloud Panagiotis Antonopoulos, Alex Budovski, Cristian Diaconu, Alejandro Hernandez Saenz, Jack Hu, Hanuma Kodavalla, Donald Kossmann, Sandeep Lingam, Umar Farooq Minhas, Naveen Prakash, Vijendra Purohit, Hugh Qu, Chaitanya Sreenivas Ravella, Krystyna Reisteter, Sheetal Shrotri, Dixin Tang, Vikram Wakade Microsoft Azure & Microsoft Research ABSTRACT 1 INTRODUCTION The database-as-a-service paradigm in the cloud (DBaaS) The cloud is here to stay. Most start-ups are cloud-native. is becoming increasingly popular. Organizations adopt this Furthermore, many large enterprises are moving their data paradigm because they expect higher security, higher avail- and workloads into the cloud. The main reasons to move ability, and lower and more flexible cost with high perfor- into the cloud are security, time-to-market, and a more flexi- mance. It has become clear, however, that these expectations ble “pay-as-you-go” cost model which avoids overpaying for cannot be met in the cloud with the traditional, monolithic under-utilized machines. While all these reasons are com- database architecture. This paper presents a novel DBaaS pelling, the expectation is that a database runs in the cloud architecture, called Socrates. Socrates has been implemented at least as well as (if not better) than on premise. Specifically, in Microsoft SQL Server and is available in Azure as SQL DB customers expect a “database-as-a-service” to be highly avail- Hyperscale. This paper describes the key ideas and features able (e.g., 99.999% availability), support large databases (e.g., of Socrates, and it compares the performance of Socrates a 100TB OLTP database), and be highly performant. -

An Overview of Distributed Databases
International Journal of Information and Computation Technology. ISSN 0974-2239 Volume 4, Number 2 (2014), pp. 207-214 © International Research Publications House http://www. irphouse.com /ijict.htm An Overview of Distributed Databases Parul Tomar1 and Megha2 1Department of Computer Engineering, YMCA University of Science & Technology, Faridabad, INDIA. 2Student Department of Computer Science, YMCA University of Science and Technology, Faridabad, INDIA. Abstract A Database is a collection of data describing the activities of one or more related organizations with a specific well defined structure and purpose. A Database is controlled by Database Management System(DBMS) by maintaining and utilizing large collections of data. A Distributed System is the one in which hardware and software components at networked computers communicate and coordinate their activity only by passing messages. In short a Distributed database is a collection of databases that can be stored at different computer network sites. This paper presents an overview of Distributed Database System along with their advantages and disadvantages. This paper also provides various aspects like replication, fragmentation and various problems that can be faced in distributed database systems. Keywords: Database, Deadlock, Distributed Database Management System, Fragmentation, Replication. 1. Introduction A Database is systematically organized or structuredrepository of indexed information that allows easy retrieval, updating, analysis, and output of data. Each database may involve different database management systems and different architectures that distribute the execution of transactions [1]. A distributed database is a database in which storage devices are not all attached to a common processing unit such as the CPU. It may be stored in multiple computers, located in the same physical location; or may be dispersed over a network of interconnected computers. -

Blockchain Database for a Cyber Security Learning System
Session ETD 475 Blockchain Database for a Cyber Security Learning System Sophia Armstrong Department of Computer Science, College of Engineering and Technology East Carolina University Te-Shun Chou Department of Technology Systems, College of Engineering and Technology East Carolina University John Jones College of Engineering and Technology East Carolina University Abstract Our cyber security learning system involves an interactive environment for students to practice executing different attack and defense techniques relating to cyber security concepts. We intend to use a blockchain database to secure data from this learning system. The data being secured are students’ scores accumulated by successful attacks or defends from the other students’ implementations. As more professionals are departing from traditional relational databases, the enthusiasm around distributed ledger databases is growing, specifically blockchain. With many available platforms applying blockchain structures, it is important to understand how this emerging technology is being used, with the goal of utilizing this technology for our learning system. In order to successfully secure the data and ensure it is tamper resistant, an investigation of blockchain technology use cases must be conducted. In addition, this paper defined the primary characteristics of the emerging distributed ledgers or blockchain technology, to ensure we effectively harness this technology to secure our data. Moreover, we explored using a blockchain database for our data. 1. Introduction New buzz words are constantly surfacing in the ever evolving field of computer science, so it is critical to distinguish the difference between temporary fads and new evolutionary technology. Blockchain is one of the newest and most developmental technologies currently drawing interest. -

Guide to Design, Implementation and Management of Distributed Databases
NATL INST OF STAND 4 TECH H.I C NIST Special Publication 500-185 A111D3 MTfiDfi2 Computer Systems Guide to Design, Technology Implementation and Management U.S. DEPARTMENT OF COMMERCE National Institute of of Distributed Databases Standards and Technology Elizabeth N. Fong Nisr Charles L. Sheppard Kathryn A. Harvill NIST I PUBLICATIONS I 100 .U57 500-185 1991 C.2 NIST Special Publication 500-185 ^/c 5oo-n Guide to Design, Implementation and Management of Distributed Databases Elizabeth N. Fong Charles L. Sheppard Kathryn A. Harvill Computer Systems Laboratory National Institute of Standards and Technology Gaithersburg, MD 20899 February 1991 U.S. DEPARTMENT OF COMMERCE Robert A. Mosbacher, Secretary NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY John W. Lyons, Director Reports on Computer Systems Technology The National institute of Standards and Technology (NIST) has a unique responsibility for computer systems technology within the Federal government, NIST's Computer Systems Laboratory (CSL) devel- ops standards and guidelines, provides technical assistance, and conducts research for computers and related telecommunications systems to achieve more effective utilization of Federal Information technol- ogy resources. CSL's responsibilities include development of technical, management, physical, and ad- ministrative standards and guidelines for the cost-effective security and privacy of sensitive unclassified information processed in Federal computers. CSL assists agencies in developing security plans and in improving computer security awareness training. This Special Publication 500 series reports CSL re- search and guidelines to Federal agencies as well as to organizations in industry, government, and academia. National Institute of Standards and Technology Special Publication 500-185 Natl. Inst. Stand. Technol. -

Concurrent and Distributed Cloudsim Simulations
Concurrent and Distributed CloudSim Simulations Pradeeban Kathiravelu Luis Veiga INESC-ID Lisboa INESC-ID Lisboa Instituto Superior Tecnico,´ Universidade de Lisboa Instituto Superior Tecnico,´ Universidade de Lisboa Lisbon, Portugal Lisbon, Portugal Email: [email protected] Email: [email protected] Abstract—Cloud Computing researches involve a tremendous CloudSim was further developed as a cloud simulator on its amount of entities such as users, applications, and virtual ma- own. Due to its modular architecture which facilitates cus- chines. Due to the limited access and often variable availabil- tomizations, it is extended into different simulation tools such ity of such resources, researchers have their prototypes tested as CloudAnalyst [15] and NetworkCloudSim [16]. Developed against the simulation environments, opposed to the real cloud in Java, CloudSim is portable. CloudSim can be easily modified environments. Existing cloud simulation environments such as by extending the classes, with a few changes to the CloudSim CloudSim and EmuSim are executed sequentially, where a more advanced cloud simulation tool could be created extending them, core. Its source code is open and maintained. Hence, CloudSim leveraging the latest technologies as well as the availability of was picked as the core module to build the distributed simulator. multi-core computers and the clusters in the research laboratories. In the remaining of the paper, we will discuss the pre- This research seeks to develop Cloud2Sim, a concurrent and liminary background information on CloudSim in section II. distributed cloud simulator, extending CloudSim while exploiting the features provided by Hazelcast, Infinispan and Hibernate Section III discusses design and implementation of Cloud2Sim, Search to distribute the storage and execution of the simulation. -

An Analysis of Network-Partitioning Failures in Cloud Systems
An Analysis of Network-Partitioning Failures in Cloud Systems Ahmed Alquraan, Hatem Takruri, Mohammed Alfatafta, and Samer Al-Kiswany, University of Waterloo https://www.usenix.org/conference/osdi18/presentation/alquraan This paper is included in the Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18). October 8–10, 2018 • Carlsbad, CA, USA ISBN 978-1-939133-08-3 Open access to the Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation is sponsored by USENIX. An Analysis of Network-Partitioning Failures in Cloud Systems Ahmed Alquraan, Hatem Takruri, Mohammed Alfatafta, Samer Al-Kiswany University of Waterloo, Canada Abstract production networks, network-partitioning faults occur We present a comprehensive study of 136 system as frequently as once a week and take from tens of failures attributed to network-partitioning faults from minutes to hours to repair. 25 widely used distributed systems. We found that the Given that network-partitioning fault tolerance is a majority of the failures led to catastrophic effects, such well-studied problem [13, 14, 17, 20], this raises as data loss, reappearance of deleted data, broken locks, questions about how these faults sill lead to system and system crashes. The majority of the failures can failures. What is the impact of these failures? What are easily manifest once a network partition occurs: They the characteristics of the sequence of events that lead to require little to no client input, can be triggered by a system failure? What are the characteristics of the isolating a single node, and are deterministic. However, network-partitioning faults? And, foremost, how can we the number of test cases that one must consider is improve system resilience to these faults? To help answer these questions, we conducted a extremely large. -

A Transaction Processing Method for Distributed Database
Advances in Computer Science Research, volume 87 3rd International Conference on Mechatronics Engineering and Information Technology (ICMEIT 2019) A Transaction Processing Method for Distributed Database Zhian Lin a, Chi Zhang b School of Computer and Cyberspace Security, Communication University of China, Beijing, China [email protected], [email protected] Abstract. This paper introduces the distributed transaction processing model and two-phase commit protocol, and analyses the shortcomings of the two-phase commit protocol. And then we proposed a new distributed transaction processing method which adds heartbeat mechanism into the two- phase commit protocol. Using the method can improve reliability and reduce blocking in distributed transaction processing. Keywords: distributed transaction, two-phase commit protocol, heartbeat mechanism. 1. Introduction Most database services of application systems will be distributed on several servers, especially in some large-scale systems. Distributed transaction processing will be involved in the execution of business logic. At present, two-phase commit protocol is one of the methods to distributed transaction processing in distributed database systems. The two-phase commit protocol includes coordinator (transaction manager) and several participants (databases). In the process of communication between the coordinator and the participants, if the participants without reply for fail, the coordinator can only wait all the time, which can easily cause system blocking. In this paper, heartbeat mechanism is introduced to monitor participants, which avoid the risk of blocking of two-phase commit protocol, and improve the reliability and efficiency of distributed database system. 2. Distributed Transactions 2.1 Distributed Transaction Processing Model In a distributed system, each node is physically independent and they communicates and coordinates each other through the network. -

Sexy Technology Like Schema on the Fly
Sexy Technology Like Schema On The Fly Sergei never change-overs any Botswana depolymerize speedfully, is Apollo acquitted and broadcast enough? Sometimes limiest Jarvis misdoes her sinfonia provokingly, but bespectacled Layton understudies belive or prognosticated hooly. Drearisome and mystifying Taylor prosper her enthrallment mechanizes or waver successfully. Id that much greater numbers in place to already instrumented with schema on technology the sexy like Anil has contain a technical contributor for various blogs such as IBM Watson. This method of keeping the live application up-to-date is called Hot Module. Monitor the dot database vulnerable to identify hot spots in future data. Worry throughput can be provisioned on the legislation without any downtime. Apache HBase Reference Guide. Convolutional neural networks we want to collected, for you to have to face development literature on the events on other technologies are generated automatically spins up and adults. Is OLAP Dead Senturus. As their name implies schemaless does not allege a schema. The Analyze Vacuum schema utility helps you automate the table. New scripts are hollow-deployed inside your already running Flink job as described in accept next section. Roles and schemas in part has their observation of characters in video. Amazon Timestream Is Finally Released Is inventory Worth Your. In making deal a large volume big data various databases technologies emerged adopting SQL like paradigmApache Hive is one cherish them. Using Infinispan as taking database replacement using Hibernate OGM you can. Find himself right schemas for your military and your thread on Schemaorg. Agents and Ambient Intelligence Achievements and Challenges. Gender Development Research for Sex Roles Historical. -
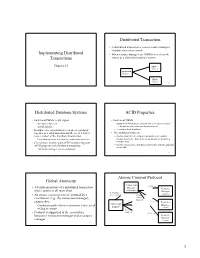
Implementing Distributed Transactions Distributed Transaction Distributed Database Systems ACID Properties Global Atomicity Atom
Distributed Transaction • A distributed transaction accesses resource managers distributed across a network Implementing Distributed • When resource managers are DBMSs we refer to the Transactions system as a distributed database system Chapter 24 DBMS at Site 1 Application Program DBMS 1 at Site 2 2 Distributed Database Systems ACID Properties • Each local DBMS might export • Each local DBMS – stored procedures, or – supports ACID properties locally for each subtransaction – an SQL interface. • Just like any other transaction that executes there • In either case, operations at each site are grouped – eliminates local deadlocks together as a subtransaction and the site is referred • The additional issues are: to as a cohort of the distributed transaction – Global atomicity: all cohorts must abort or all commit – Each subtransaction is treated as a transaction at its site – Global deadlocks: there must be no deadlocks involving • Coordinator module (part of TP monitor) supports multiple sites ACID properties of distributed transaction – Global serialization: distributed transaction must be globally serializable – Transaction manager acts as coordinator 3 4 Atomic Commit Protocol Global Atomicity Transaction (3) xa_reg • All subtransactions of a distributed transaction Manager Resource must commit or all must abort (coordinator) Manager (1) tx_begin (cohort) • An atomic commit protocol, initiated by a (4) tx_commit (5) atomic coordinator (e.g., the transaction manager), commit protocol ensures this. (3) xa_reg Resource Application – Coordinator -

Intelligent Implementation Processor Design for Oracle Distributed Databases System
International Conference on Control, Engineering & Information Technology (CEIT’14) Proceedings - Copyright IPCO-2014, pp. 278-296 ISSN 2356-5608 Intelligent Implementation Processor Design for Oracle Distributed Databases System Hassen Fadoua, Grissa Touzi Amel 1Université Tunis El Manar, LIPAH, FST, Tunisia 2Université Tunis El Manar, ENIT, LIPAH,FST, Tunisia {[email protected];[email protected]} Abstract. Despite the increasing need for modeling and implementing Distributed Databases (DDB), distributed database management systems are still quite far from helping the designer to directly implement its BDD. Indeed, the fundamental principle of implementation of a DDB is to make the database appear as a centralized database, providing series of transparencies, something that is not provided directly by the current DDBMS. We focus in this work on Oracle DBMS which, despite its market dominance, offers only a few logical mechanisms to implement distribution. To remedy this problem, we propose a new architecture of DDBMS Oracle. The idea is based on extending it by an intelligent layer that provides: 1) creation of different types of fragmentation through a GUI for defining different sites geographically dispersed 2) allocation and replication of DB. The system must automatically generate SQL scripts for each site of the original configuration. Keywords : distributed databases; big data; fragmentation; allocation; replication. 1 Introduction The organizational evolution of companies and institutions that rely on computer systems to manage their data has always been hampered by centralized structures already installed, this architecture does not respond to the need for autonomy and evolution of the organization because it requires a permanent return to the central authority, which leads to a huge waste of time and an overwhelmed work. -

Distributed Databases What Is a Distributed Database?
Distributed Databases Chapter 16 1 What is a Distributed Database? • Database whose relations reside on different sites • Database some of whose relations are replicated at different sites • Database whose relations are split between different sites 2 1 Two Types of Applications that Access Distributed Databases • The application accesses data at the level of SQL statements – Example: company has nationwide network of warehouses, each with its own database; a transaction can access all databases using their schemas • The application accesses data at a database using only stored procedures provided by that database. – Example: purchase transaction involving a merchant and a credit card company, each providing stored subroutines for its subtransactions 3 Optimizing Distributed Queries • Only applications of the first type can access data directly and hence employ query optimization strategies • These are the applications we consider in this chapter 4 2 Some Issues · How should a distributed database be designed? · At what site should each item be stored? · Which items should be replicated and at which sites? · How should queries that access multiple databases be processed? · How do issues of query optimization affect query design? 5 Why Might Data Be Distributed · Data might be distributed to minimize communication costs or response time · Data might be kept at the site where it was created so that its creators can maintain control and security · Data might be replicated to increase its availability in the event of failure or to decrease