Database Architects and Administrators Guide to Nosql
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aptum Database Administration Program September 2019 Overview
SERVICE GUIDE APTUM DATABASE ADMINISTRATION PROGRAM SEPTEMBER 2019 OVERVIEW Aptum’s Database Administration (DBA) Program was designed to DBA Plan hours can be leveraged for all database-related activities help our customers reduce the cost of normal operation and the risk of detailed within this document, up to the allocation purchased. If you application and database downtime. require more hours than are purchased in a plan for a given month, any excess will be billed on an hourly basis at the standard Database Customers can work with Aptum’s Solutions Engineers and Certified Administration rate. Database Administrators to obtain assistance with everything from database engine configuration, performance optimization, clustering Included Database Platforms: administration, and replication administration. Microsoft SQL Server To help you achieve your performance goals, we offer our DBA plans in MySQL/MariaDB/Percona block-hour increments: 4 hours* * Hours are monthly and renew at the 1st of each calendar month and do not roll over. Overage rates are applicable only after block hours are consumed. All hours are 8 hours* applicable to the entire solution not per server. 12 hours* 20 hours* THE NEED FOR DATABASE ADMINISTRATION Most applications—especially those that support enterprise processes enable e-commerce, or facilitate collaboration—are database-intensive and demand optimal performance from the database. Applications and database queries may utilize very lean and elegant code, but the structure and configuration of your databases can be a detriment to high performance. There are dozens, sometimes hundreds, of configuration settings that need to be optimally tuned to enhance database performance. When the database is installed, most configuration defaults are applied automatically. -

Database Administrator
Database Administrator Purpose: DGC is looking for a passionate Database Administrator to help support our platform, delivering the content of choice for casino operators and their players. You will be working in a small but high performing IT team to create something special. Online gaming is set to be one of the fastest growing industries in the US as regulation allows online gaming to expand into the various states. Our RGS platform is designed for fast and efficient deployments and seamless integration into a high performing library of online casino games. You will need to assist with the hosting, management and updating of this technology to ensure our success. As an DBA you will implement, design and improve processes relating to the administration of databases to ensure that they function correctly, perform optimally, preserve data and facilitate revenue generation. This role forms part of a rapidly expanding team which will require the ability to support a fast growing infrastructure and customer base. Duties include, but not limited to: • Set and maintain operational database standards on an ongoing basis • Develop and maintain OLAP environments • Develop and maintain OLTP environments • Develop and maintain ETL processes • Enforce and improve database integrity and performance using sound design principles and implementation of database design standards • Design and enforce data security policies to eliminate unauthorised access to data on managed data systems in accordance with IT Services technical specifications and business requirements • Ensure that effective data redundancy; archiving, backup and recovery mechanisms are in place to prevent the loss of data • Set up configurable pre-established jobs to automatically run daily in order to monitor and maintain the operational databases • Provide 24-hour standby support by being available on a 24/7 basis during specified periods This job description is not intended to be an exhaustive list of responsibilities. -

CSIT 1810 Introduction to Database Design
PELLISSIPPI STATE COMMUNITY COLLEGE MASTER SYLLABUS INTRODUCTION TO DATABASE DESIGN CSIT 1810 Class Hours: 3.0 Credit Hours: 4.0 Laboratory Hours: 3.0 Date Revised: Spring 2016 Catalog Course Description: A study of database management systems and their impact on information technology. Topics include database models, data modeling techniques, conceptual and physical design, storage techniques and data administration. Special emphasis will be placed on relational systems and application of query languages using relational operations. Entry Level Standards: The entering student should have a familiarity with the Windows environment. The student is expected to have moderate programming abilities in a high-level language or a scripting language. Problem solving skills will be essential. The student must have math, writing, verbal and English language skills at the college level. Prerequisites: CSIT 1110 or WEB 2010 Textbook(s) and Other Course Materials: Textbook: Database Systems: Design, Implementation and Management; (11th. Edition), by Coronel/Morris/Rob, Cengage, 2014, ISBN-13 978-1-285-19614-5, (Electronic Book at www.cengagebrain.com, ISBN-13 9781305323230.) Supplies: USB flash drive; ear buds or head phones for audio tutorials I. Week/Unit/Topic Basis: Week Chapter Topic 1 1 Database Systems 2 2 Database Models; Relational versus NoSQL databases 3 3 The Relational Database Model 4 9 Introduction to Systems & Database Design 5, 6 4, 5.1 Entity-Relationship Modeling 7 6 Normalization 8-10 7, SQL Queries, Creating Tables and Views in SQL 8.1,8.4 11 10 Transaction Management and Concurrency Control 12 12, 15 Distributed Systems, Database Management & Security 13 13 Business Intelligence & Data Warehouses 14 13 Big Data; final exam review 15 Final Exam II. -

Database Administrator
Contra Costa Community College District – Classification Specification DATABASE ADMINISTRATOR Class Code OT Status EEO Category Represented Salary Effective Date Status Pages Status Grade Non-Exempt Technical/Paraprofessional PEU Local 1 75 07/01/2017 Classified 1 of 2 DEFINITION To support the relational databases on the various computer platform environments; to assist in the development, creation and maintenance of relational databases for present and future requirements; and to recommend and maintain security measures for the database environment. DISTINGUISHING CHARACTERISTICS Database Administrator – This is the journey-level classification in the Database Administrator Series. Positions in this classification are responsible for moderately complex projects with general supervision provided by the appropriate manager. Knowledge of database management theory and practice is reasonably extensive, and understanding of moderately complex database concepts is critical. Database Administrator, Senior – This is the most advanced level in the Database Administrator series. Positions in this classification are responsible for highly complex projects with general direction provided by the appropriate manager. Knowledge of database management theory and practice is extensive, and understanding of complex database concepts is critical. SUPERVISION RECEIVED AND EXERCISED Receives supervision from a departmental supervisor or manager. May receive technical or functional supervision from higher-level departmental personnel. May provide training and direction to student assistants or other assigned staff. EXAMPLES OF DUTIES Duties may include, but are not limited to, the following: Documents, designs, develops, optimizes, and improves new and existing logical and physical databases for custom and commercial applications to meet the changing needs of the user community. Coordinates database development as part of project team and individually, applying knowledge of database design standards, configuration, tools and services, and database management system. -

Junior Database Administrator
JUNIOR DATABASE ADMINISTRATOR The National Association of Counties (NACo) is seeking a highly organized individual with great attention to detail for the position of Database Administrator (DBA). The DBA ensures data quality for the entire organization. This position is responsible for maintaining database applications, ensuring information is accurate and entered in a timely manner to support NACo departments and program requirements. The position is also responsible for data entry, data structure, report customization, and analysis and data quality control. The database administrator (DBA) is responsible for the performance, integrity and security of NACo’s database. The DBA will be involved in the planning and development of the database, as well as in troubleshooting any issues on behalf of the users. The DBA will ensure data remains consistent across the database, data is clearly defined, users access data concurrently and in a form that suits their needs, and ensure all data is retrievable in an emergency. RESPONSIBILITIES: • Establish the needs of users and monitor user access and security • Monitor performance and manage parameters in order to provide fast responses to front-end users • Map out the conceptual design for a planned database • Ensure all data is retrievable in an emergency • Consider both back-end organization of data and front-end accessibility for end-users • Refine the logical design so that it can be translated into a specific data model • Install and test new versions of the database management system (DBMS) -

Database Administrator
OFFICE OF THE STATE AUDITOR DATABASE ADMINISTRATOR Posting Number 2015-26 SALARY RANGE (Grade 14A): $59,452.85 to $89,178.87 (Commensurate with experience) GENERAL STATEMENT OF DUTIES The Office of the State Auditor is seeking an experienced Database Administrator responsible for managing databases on Microsoft SQL Server platform. The DBA will administer databases on several Microsoft Windows database servers with databases that serve internally developed applications, external third party applications, as well as data warehouses. The DBA will help migrate older databases to latest versions, and implement advanced database technologies such as columnar databases, tabular model, database replications as well as implement uniform access control practices and advise on other technologies that may help the organization. SUPERVISION RECEIVED Receives supervision and direction from the Assistant Director of Data Analytics. SUPERVISION EXERCISED Provides technical supervision over 1-3 contract personnel on an as needed or by project basis DUTIES AND RESPONSIBILITIES • Setup, upgrade, and manage MS SQL Server database hosts by installing and configuring software. • Manage database schemas and schema objects such as constraints, indexes, etc. to provide application support and database tuning. • Manage storage by understanding and reporting the current space utilization, organizing current data, and developing proper mechanisms to ensure storage is efficiently utilized. This may also include monitoring and reporting of storage utilization and cleanup/removal of orphan data. • Inventory the current database servers and individual databases by performing discovery or working with other team members, then ensure that all databases are adequately being maintained. • Inventory the current access control mechanisms used in the organization and modify the access to ensure that a uniform access control mechanism is implemented consistent with security policies. -

Database Administration Maturity Model Version
This document is the intellectual property of TrueNorth Consulting, Inc., Copyright © 1996, 1998, 1999, all rights reserved. Database Administration Maturity Model Version 1.1 File: C:\tnc\dba\Tom's White Papers\DBAMM.doc Page 1 Author: Thomas B. Cox This document is the intellectual property of TrueNorth Consulting, Inc., Copyright © 1996, 1998, 1999, all rights reserved. Table of Contents LEVELS OF THE DBA MM (DATABASE ADMINISTRATION MATURITY MODEL)............................................................................3 DIFFERENCES BETWEEN DATA ADMINISTRATORS, DBAS, AND DATA ARCHITECTS...............................................3 QUALITATIVE DIFFERENCES BETWEEN TASK AREAS.............................................................................................................................4 Data Architecture .........................................................................................................................................................................4 Data Administration......................................................................................................................................................................4 Database Administration...............................................................................................................................................................4 DATABASE LIFE CYCLE.............................................................................................................................................................6 QUALITATIVE -
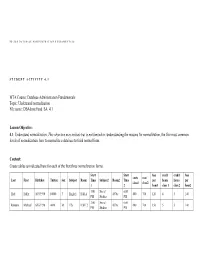
Database Administration Fundamentals Topic: Understand Normalization File Name: Dbadminfund SA 4.1
98-364 D ATABASE A DMINISTRATION F UNDAMENTALS STUDENT ACTIVITY 4.1 MTA Course: Database Administration Fundamentals Topic: Understand normalization File name: DBAdminFund_SA_4.1 Lesson Objective: 4.1: Understand normalization. This objective may include but is not limited to: understanding the reasons for normalization, the five most common levels of normalization, how to normalize a database to third normal form. Content: Create tables as indicated here for each of the first three normalization forms. Start Start fees credit credit fees costs cost Last First Birthday Tuition Sex Subject Room Time Subject2 Room2 Time per hours hours per class1 class2 1 2 hour1 class 1 class 2 hour2 1:00 Social 6:00 Holt Holly 10/5/1990 10000 F English Hall A 4576c 480 700 120 4 5 140 PM Studies PM 3:00 Social 6:00 Raheem Michael 6/18/1990 4000 M CIS Hall 12 4576c 600 700 150 5 5 140 PM Studies PM 98-364 D ATABASE A DMINISTRATION F UNDAMENTALS 3:00 Social 6:00 Raheem Michael 6/18/1990 4000 M CIS Hall 12 4576c 600 700 150 5 5 140 PM Studies PM Social 6:00 1:00 Jacobsen Lola 8/7/1997 9000 F 4576c English Hall A 700 480 140 5 4 120 Studies PM PM 1:00 4:00 Higa Sidney 11/21/2000 12000 F English Hall A Math 2354c 480 1404 120 4 6 234 PM PM 1:00 4:00 Johnson Brian 4/15/1989 500 M English Hall A Math 2354c 1404 1701 234 6 3 567 PM PM 3:00 Social 6:00 Raheem Michael 6/18/1990 4000 M CIS Hall 12 4576c 600 700 150 5 5 140 PM Studies PM 2:00 Social 6:00 Bentley Sean 2/17/1990 350 M Science Hall B 4576c 1701 700 567 3 5 140 PM Studies PM Social 6:00 3:00 Price Jeff 10/5/1990 2000 M 4576c CIS Hall 12 700 600 140 5 5 150 Studies PM PM 3:00 Social 6:00 Raheem Michael 6/18/1990 4000 M CIS Hall 12 4576c 600 700 150 5 5 140 PM Studies PM Social 6:00 3:00 Ashton Chris 1/1/1951 50 M 4576c CIS Hall 12 480 1404 120 4 6 234 Studies PM PM 98-364 D ATABASE A DMINISTRATION F UNDAMENTALS Use the First Normal Form (1NF) with the previous table. -

Database Modeling and Design Lecture Notes
Database Modeling and Design 3rd Edition Toby J. Teorey University of Michigan Lecture Notes Contents I. Database Systems and the Life Cycle (Chapter 1)……………………2 Introductory concepts; objectives of database management 2 Relational database life cycle 3 Characteristics of a good database design process 7 II. Requirements Analysis (Chapter 3)………………………………….8 III. Entity-Relationship (ER) Modeling (Chapters 2-4)……………… 11 Basic ER modeling concepts 11 Schema integration methods 22 Entity-relationship 26 Transformations from ER diagrams to SQL Tables 29 IV. Normalization and normal forms (Chapter 5)………………………35 First normal form (1NF) to third normal form (3NF) and BCNF 35 3NF synthesis algorithm (Bernstein) 42 Fourth normal form (4NF) 47 V. Access Methods (Chapter 6)…………………………..………………50 Sequential access methods 50 Random access methods 52 Secondary Indexes 58 Denormalization 62 Join strategies 64 VI. Database Distribution Strategies (Chapter 8)……………………….66 Requirements of a generalized DDBMS: Date’s 12 Rules 68 Distributed database requirements 72 The non-redundant “ best fit” method 74 The redundant “all beneficial sites” method 77 VII. Data Warehousing, OLAP, and Data Mining (Chapter 9)…….....79 Data warehousing 79 On-line analytical processing (OLAP) 86 Data mining 93 Revised 11/18/98 – modify Section V Revised 11/21/98 – insertions into Section VII Revised 1/14/99 – modify Section VI Revised 2/11/99 – modify Section IV, 4NF (p.47 FD, MVD mix) 1 I. Database Systems and the Life Cycle Introductory Concepts data—a fact, something upon which an inference is based (information or knowledge has value, data has cost) data item—smallest named unit of data that has meaning in the real world (examples: last name, address, ssn, political party) data aggregate (or group) -- a collection of related data items that form a whole concept; a simple group is a fixed collection, e.g. -

Ddl) Lesson 1
LESSON 1 . 4 98-364 Database Administration Fundamentals Understand Data Definition Language (DDL) LESSON 1 . 4 98-364 Database Administration Fundamentals Lesson Overview 1.4 Understand data definition language (DDL) In this lesson, you will review: . DDL—DML relationship . DDL . Schema . CREATE . ALTER . DROP LESSON 1 . 4 98-364 Database Administration Fundamentals DDL—DML Relationship DML . Data Manipulation Language. (DML) In a database management system (DBMS), a language that is used to insert data in, update, and query a database. DMLs are often capable of performing mathematical and statistical calculations that facilitate generating reports. Acronym: DML. DML is used to manipulate the data of a database. In lesson review 1.3, you can find more details on DML. LESSON 1 . 4 98-364 Database Administration Fundamentals DDL . Data Definition Language (DDL) A language that defines all attributes and properties of a database, especially record layouts, field definitions, key fields, file locations, and storage strategy. Acronym: DDL. DDL is used to create the framework for the database, the schema of the database, or both. DDL works at the table level of the database. LESSON 1 . 4 98-364 Database Administration Fundamentals Schema . Schema A description of a database to a DBMS in the language provided by the DBMS. A schema defines aspects of the database, such as attributes (fields) and domains and parameters of the attributes. Schemas are generally defined as using commands from a DDL supported by the database system. LESSON 1 . 4 98-364 Database Administration Fundamentals CREATE . There are two forms of the CREATE statement. This statement creates a database called students. -

Sql Server Dba Responsibilities & Implications of Integration
▲ E-Guide SQL SERVER DBA RESPONSIBILITIES & IMPLICATIONS OF INTEGRATION SearchSQLServer SQL SERVER DBA RESPONSIBILITIES & IMPLICATIONS OF INTEGRATION Home Defining Half a Dozen Daily SQL Server DBA Responsibilities In-Memory SQL Server: The Implica- tions of Integration ATABASE MANAGEMENT” MAY sound like one “D responsibility to the uninitiated, but those who are more familiar know it’s just an umbrella term. Read on to explore six du- ties that are the building blocks of effective SQL Server administration. PAGE 2 OF 15 SPONSORED BY SQL SERVER DBA RESPONSIBILITIES & IMPLICATIONS OF INTEGRATION DEFINING HALF A DOZEN DAILY SQL SERVER DBA RESPONSIBILITIES Basit Farooq Home Defining Half a Dozen SQL Server database administration can be a complex and stressful job. Daily SQL Server DBA Responsibilities Database administrators’ responsibilities cover the performance, integrity and security of business data and SQL Server databases. To fulfill their duties In-Memory SQL Server: The Implica- and to make business data available to its users, database administrators have tions of Integration to perform routine DBA checks on their SQL Servers to monitor their status. So, what critical aspects of SQL Server should all DBAs include in their daily checklist? Here are six daily DBA responsibilities that every SQL Server manager should perform. PAGE 3 OF 15 SPONSORED BY SQL SERVER DBA RESPONSIBILITIES & IMPLICATIONS OF INTEGRATION VERIFY ALL SQL SERVER INSTANCES ARE UP Check the connectivity of each SQL Server on the network, and make sure all SQL Server instances are up. Ensure that all databases hosted on SQL Server instances are online. In addition to this, validate the storage of database data Home on the hard disk, which can be done by running the Database Consistency Defining Half a Dozen Checker (DBCC) CHECKDBcommand against each database on every SQL Daily SQL Server DBA Responsibilities Server instance. -

SQL Database Administrator
ORION COMMUNICATIONS, INC. Job Description JOB TITLE: SQL Database Administrator Reports To: Orion Operations Manager Exempt POSITION SUMMARY: The SQL Database Administration is responsible for the implementation, configuration, maintenance, and performance of critical SQL Server RDBMS systems, to ensure the availability and consistent performance of the Orion Workforce Management PLUS applications. This is a “hands-on” position requiring solid technical skills, as well as excellent interpersonal and communication skills. This position is responsible for the development and sustainment of the SQL Server Warehouse, ensuring its operational readiness (security, health and performance), executing data loads, and performing data modeling in support of multiple development teams. The data warehouse supports an enterprise application suite of program management tools. This position must be capable of working independently and collaboratively. POSITION ACTIVITIES Core duties and responsibilities include the following. Other duties may be assigned. • Manage SQL Server databases through multiple product lifecycle environments, from development to mission-critical production systems. • Configure and maintain database servers and processes, including monitoring of system health and performance, to ensure high levels of performance, availability, and security. • Apply data modeling techniques to ensure development and implementation support efforts meet integration and performance expectations • Independently analyze, solve, and correct issues in real time, providing problem resolution end-to-end. • Refine and automate regular processes, track issues, and document changes • Assist developers with complex query tuning and schema refinement. • Provide 24x7 support for critical production systems. • Perform scheduled maintenance and support release deployment activities after hours. • Share domain and technical expertise, providing technical mentorship and cross-training to other peers and team members.