Combining Heritrix and Phantomjs for Better Crawling of Pages with Javascript Justin F
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Netscape 6.2.3 Software for Solaris Operating Environment
What’s New in Netscape 6.2 Netscape 6.2 builds on the successful release of Netscape 6.1 and allows you to do more online with power, efficiency and safety. New is this release are: Support for the latest operating systems ¨ BETTER INTEGRATION WITH WINDOWS XP q Netscape 6.2 is now only one click away within the Windows XP Start menu if you choose Netscape as your default browser and mail applications. Also, you can view the number of incoming email messages you have from your Windows XP login screen. ¨ FULL SUPPORT FOR MACINTOSH OS X Other enhancements Netscape 6.2 offers a more seamless experience between Netscape Mail and other applications on the Windows platform. For example, you can now easily send documents from within Microsoft Word, Excel or Power Point without leaving that application. Simply choose File, “Send To” to invoke the Netscape Mail client to send the document. What follows is a more comprehensive list of the enhancements delivered in Netscape 6.1 CONFIDENTIAL UNTIL AUGUST 8, 2001 Netscape 6.1 Highlights PR Contact: Catherine Corre – (650) 937-4046 CONFIDENTIAL UNTIL AUGUST 8, 2001 Netscape Communications Corporation ("Netscape") and its licensors retain all ownership rights to this document (the "Document"). Use of the Document is governed by applicable copyright law. Netscape may revise this Document from time to time without notice. THIS DOCUMENT IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND. IN NO EVENT SHALL NETSCAPE BE LIABLE FOR INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES OF ANY KIND ARISING FROM ANY ERROR IN THIS DOCUMENT, INCLUDING WITHOUT LIMITATION ANY LOSS OR INTERRUPTION OF BUSINESS, PROFITS, USE OR DATA. -

Casperjs Documentation Release 1.1.0-DEV Nicolas Perriault
CasperJs Documentation Release 1.1.0-DEV Nicolas Perriault February 04, 2016 Contents 1 Installation 3 1.1 Prerequisites...............................................3 1.2 Installing from Homebrew (OSX)....................................3 1.3 Installing from npm...........................................4 1.4 Installing from git............................................4 1.5 Installing from an archive........................................4 1.6 CasperJS on Windows..........................................5 1.7 Known Bugs & Limitations.......................................5 2 Quickstart 7 2.1 A minimal scraping script........................................7 2.2 Now let’s scrape Google!........................................8 2.3 CoffeeScript version...........................................9 2.4 A minimal testing script......................................... 10 3 Using the command line 11 3.1 casperjs native options.......................................... 12 3.2 Raw parameter values.......................................... 13 4 Selectors 15 4.1 CSS3................................................... 15 4.2 XPath................................................... 16 5 Testing 17 5.1 Unit testing................................................ 17 5.2 Browser tests............................................... 18 5.3 Setting Casper options in the test environment............................. 19 5.4 Advanced techniques........................................... 20 5.5 Test command args and options.................................... -

Webassembly a New World of Native Exploits on the Web Agenda
WebAssembly A New World Of Native Exploits On The Web Agenda • Introduction • The WebAssembly Platform • Emscripten • Possible Exploit Scenarios • Conclusion Wasm: What is it good for? ● Archive.org web emulators ● Image/processing ● Video Games ● 3D Modeling ● Cryptography Libraries ● Desktop Application Ports Wasm: Crazy Incoming ● Browsix, jslinux ● Runtime.js (Node), Nebulet ● Cervus ● eWASM Java Applet Joke Slide ● Sandboxed ● Virtual Machine, runs its own instruction set ● Runs in your browser ● Write once, run anywhere ● In the future, will be embedded in other targets What Is WebAssembly? ● A relatively small set of low-level instructions ○ Instructions are executed by browsers ● Native code can be compiled into WebAssembly ○ Allows web developers to take their native C/C++ code to the browser ■ Or Rust, or Go, or anything else that can compile to Wasm ○ Improved Performance Over JavaScript ● Already widely supported in the latest versions of all major browsers ○ Not limited to running in browsers, Wasm could be anywhere Wasm: A Stack Machine Text Format Example Linear Memory Model Subtitle Function Pointers Wasm in the Browser ● Wasm doesn’t have access to memory, DOM, etc. ● Wasm functions can be exported to be callable from JS ● JS functions can be imported into Wasm ● Wasm’s linear memory is a JS resizable ArrayBuffer ● Memory can be shared across instances of Wasm ● Tables are accessible via JS, or can be shared to other instances of Wasm Demo: Wasm in a nutshell Emscripten ● Emscripten is an SDK that compiles C/C++ into .wasm binaries ● LLVM/Clang derivative ● Includes built-in C libraries, etc. ● Also produces JS and HTML code to allow easy integration into a site. -

Casperjs Documentation Release 1.1.0-DEV
CasperJs Documentation Release 1.1.0-DEV Nicolas Perriault Sep 13, 2018 Contents 1 Installation 3 1.1 Prerequisites...............................................3 1.2 Installing from Homebrew (OSX)....................................4 1.3 Installing from npm...........................................4 1.4 Installing from git............................................4 1.5 Installing from an archive........................................5 1.6 CasperJS on Windows..........................................5 1.7 Known Bugs & Limitations.......................................6 2 Quickstart 7 2.1 A minimal scraping script........................................7 2.2 Now let’s scrape Google!........................................8 2.3 CoffeeScript version...........................................9 2.4 A minimal testing script......................................... 10 3 Using the command line 11 3.1 casperjs native options.......................................... 12 3.2 Raw parameter values.......................................... 13 4 Selectors 15 4.1 CSS3................................................... 15 4.2 XPath................................................... 16 5 Testing 17 5.1 Unit testing................................................ 17 5.2 Browser tests............................................... 18 5.3 Setting Casper options in the test environment............................. 19 5.4 Advanced techniques........................................... 20 5.5 Test command args and options.................................... -

Comparing Javascript Engines
Comparing Javascript Engines Xiang Pan, Shaker Islam, Connor Schnaith Background: Drive-by Downloads 1. Visiting a malicious website 2. Executing malicious javascript 3. Spraying the heap 4. Exploiting a certain vulnerability 5. Downloading malware 6. Executing malware Background: Drive-by Downloads 1. Visiting a malicious website 2. Executing malicious javascript 3. Spraying the heap 4. Exploiting a certain vulnerability 5. Downloading malware 6. Executing malware Background: Drive-by Downloads Background: Drive-by Downloads Setup: Making the prototype null while in the prototype creates a pointer to something random in the heap. Background: Drive-by Downloads Environment: gc( ) is a function call specific to Firefox, so the attacker would want to spray the heap with an exploit specific to firefox. Background: Drive-by Downloads Obfuscation: If the browser executing the javascript it firefox,the code will proceed to the return statement. Any other browser will exit with an error due to an unrecognized call to gc( ). Background: Drive-by Downloads Download: The return will be to a random location in the heap and due to heap-spraying it will cause shell code to be executed. Background: Goal of Our Project ● The goal is to decode obfuscated scripts by triggering javascript events ● The problem is when triggering events, some errors, resulting from disparity of different engines or some other reasons, may occur and terminate the progress ● We need to find ways to eliminate the errors and Ex 1therefore generate more de-obfuscated scripts <script> function f(){ //some codes gc(); var x=unescape(‘%u4149%u1982%u90 […]’)); eval(x); } </script> Ex 2 <script type="text/javascript" src="/includes/jquery/jquery.js"></script> Project Overview - Part One ● Modify WebKit engine so that it can generate error informations. -

HTML Tips and Tricks
Here are some common HTML/JavaScript codes to use in your survey building. To use these codes click on the purple drop down to the left of a question. Then click on “add java script”. Replace the part that says” /*Place Your Javascript Here*/” with the codes below. Some codes are to be used in the source view or answer choices. Again these codes should be pasted into your question when you have accessed the “code view” in the upper right of the questions text box or if you’re in the rich text editor click on the “source” button in the upper right corner of the rich text editor. Below you will find 18 codes. The blue text specifies where the code should be placed (java script editor or source view). To customize the codes you will need to change the red text in the codes below. 1. Append text to the right of text entry choices (ex. TE Form) This allows you to ask questions such as "Approx how many hours a day do you watch TV? [TEXT ENTRY SHORT] hrs" (Java script editor) var questionId = this.questionId; var choiceInputs = $$('#'+this.questionId + ' .ChoiceStructure input'); for (var i=0; i < choiceInputs.length; i++) {var choiceInput = choiceInputs[i]; try {if (choiceInput && choiceInput.parentNode) {choiceInput.parentNode.appendChild(QBuilder('span',{},'hrs')); } } catch(e) { } } 2. Puts a calendar into the question (This code only works when placed in the source view. Or use the question saved in the Qualtrics Library. ) <link rel="stylesheet" type="text/css" href="http://yui.yahooapis.com/2.7.0/build/calendar/assets/skins/sam/calendar.css"> -
Features Guide [email protected] Table of Contents
Features Guide [email protected] Table of Contents About Us .................................................................................. 3 Make Firefox Yours ............................................................... 4 Privacy and Security ...........................................................10 The Web is the Platform ...................................................11 Developer Tools ..................................................................13 2 About Us About Mozilla Mozilla is a global community with a mission to put the power of the Web in people’s hands. As a nonprofit organization, Mozilla has been a pioneer and advocate for the Web for more than 15 years and is focused on creating open standards that enable innovation and advance the Web as a platform for all. We are committed to delivering choice and control in products that people love and can take across multiple platforms and devices. For more information, visit www.mozilla.org. About Firefox Firefox is the trusted Web browser of choice for half a billion people around the world. At Mozilla, we design Firefox for how you use the Web. We make Firefox completely customizable so you can be in control of creating your best Web experience. Firefox has a streamlined and extremely intuitive design to let you focus on any content, app or website - a perfect balance of simplicity and power. Firefox makes it easy to use the Web the way you want and offers leading privacy and security features to help keep you safe and protect your privacy online. Mozilla continues to move the Web forward by pioneering new open source technologies such as asm.js, Emscripten and WebAPIs. Firefox also has a range of amazing built-in developer tools to provide a friction-free environment for building Web apps and Web content. -

A Plug-In and an XPCOM Component for Controlling Firefox Browser Requests1
A Plug-in and an XPCOM Component for Controlling Firefox Browser 1 Requests Mozilla’s Firefox offers useful programming APIs to enhance or modify the behavior of browser [2]. The APIs are part of XPCOM (Cross Platform Component Object Model) which provides a set of classes and related methods to perform useful and primitive operations such as file creation and intercepting requests or responses. Most of the XPCOM components are available either through the HTML rendering engine (e.g., Gecko) or JavaScript engine (e.g., SeaMonkey). However, one of the most interesting aspects of Mozilla’s Firefox runtime environment is that it offers us to build customized plug-ins and XPCOM components [1, 4]. It also allows one to implement plug-ins and components in a number of programming languages such as JavaScript. Currently, there exist many plug-ins and XPCOM components that allow programmers to access web pages and browser requests. However, they cannot control browser requests based on HTML form-based requests. This project aims to fill this gap. The project has two parts. First, a plug-in for Firefox browser needs to be developed so that a user can control which requests should be allowed or blocked. To obtain the desired functionalities, one requires implementing a number of JavaScript methods to validate requests (or URLs). The plug-in, when enabled, should perform the following three major functionalities: (i) initialization, (ii) checking requests and HTML forms, (iii) stopping a request and conditionally allowing a request to proceed. The above functionalities will be tested using a set of test cases discussed in [3]. -

Webkit DOM Programming Topics
WebKit DOM Programming Topics Apple Applications > Safari 2008-10-15 MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. AS A RESULT, THIS DOCUMENT IS Apple Inc. PROVIDED “AS IS,” AND YOU, THE READER, ARE © 2004, 2008 Apple Inc. ASSUMING THE ENTIRE RISK AS TO ITS QUALITY AND ACCURACY. All rights reserved. IN NO EVENT WILL APPLE BE LIABLE FOR DIRECT, INDIRECT, SPECIAL, INCIDENTAL, OR No part of this publication may be reproduced, CONSEQUENTIAL DAMAGES RESULTING FROM ANY stored in a retrieval system, or transmitted, in DEFECT OR INACCURACY IN THIS DOCUMENT, even if advised of the possibility of such damages. any form or by any means, mechanical, THE WARRANTY AND REMEDIES SET FORTH ABOVE electronic, photocopying, recording, or ARE EXCLUSIVE AND IN LIEU OF ALL OTHERS, ORAL otherwise, without prior written permission of OR WRITTEN, EXPRESS OR IMPLIED. No Apple dealer, agent, or employee is authorized to make Apple Inc., with the following exceptions: Any any modification, extension, or addition to this person is hereby authorized to store warranty. documentation on a single computer for Some states do not allow the exclusion or limitation personal use only and to print copies of of implied warranties or liability for incidental or consequential damages, so the above limitation or documentation for personal use provided that exclusion may not apply to you. This warranty gives the documentation contains Apple’s copyright you specific legal rights, and you may also have notice. other rights which vary from state to state. The Apple logo is a trademark of Apple Inc. Use of the “keyboard” Apple logo (Option-Shift-K) for commercial purposes without the prior written consent of Apple may constitute trademark infringement and unfair competition in violation of federal and state laws. -

Extending Adobe Captivate with Javascript
EXTENDING ADOBE CAPTIVATE WITH JAVASCRIPT ADVANCED TECHNIQUES FROM A WEB DEVELOPER’S PERSPECTIVE HTTPS://GITHUB.COM/SDWARWICK/CAPTIVATE-DEMOS STEVEN WARWICK, ELEARNINGOCEAN.COM [email protected] COPYRIGHT (C)2017 ELEARNING OCEAN LLC 1 AUDIENCE • Learning interaction designers • Project managers / Course strategy developers • Web Developers • eLearning methodology strategists • Content Authors COPYRIGHT (C)2017 ELEARNING OCEAN LLC 2 CONTEXT • Captivate • HTML projects • “Responsive” design • Windows 10 development environment • JavaScript ECMA 2015 • Chrome browser • Notepad++ text editor COPYRIGHT (C)2017 ELEARNING OCEAN LLC 3 PLAN • Captivate as a web development platform • Efficient development of JavaScript/Captivate scripts • Example Scripts • Fully custom quiz interactions • Full-screen mode • D&D • Adobe documented vs. undocumented functions • Bridging between JavaScript and Captivate • Overview of other possibilities with JavaScript • Questions COPYRIGHT (C)2017 ELEARNING OCEAN LLC 4 CAPTIVATE FROM THE WEB DEVELOPERS PERSPECTIVE • WYSIWYG website builders: • “Closed” builders generate sites that cannot easily be modified after being generated • Easy to get started building, limited access to potential of modern design • Weebly, Wix, Squarespace • “Open” builders support direct modification of generated sites & continued editing • Deeper understanding of web technologies needed • Pinegrow, Bootstrap Studio, Bootply • Captivate – 90% closed / 10% open • Custom features valuable for eLearning • Reasonable strategy given -
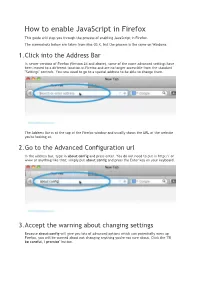
How to Enable Javascript in Firefox This Guide Will Step You Through the Process of Enabling Javascript in Firefox
How to enable JavaScript in Firefox This guide will step you through the process of enabling JavaScript in Firefox. The screenshots below are taken from Mac OS X, but the process is the same on Windows. 1. Click into the Address Bar In newer versions of Firefox (Version 24 and above), some of the more advanced settings have been moved to a different location in Firefox and are no longer accessible from the standard "Settings" controls. You now need to go to a special address to be able to change them. The Address Bar is at the top of the Firefox window and usually shows the URL of the website you're looking at. 2. Go to the Advanced Configuration url In the address bar, type in about:config and press enter. You do not need to put in http:// or www or anything like that; simply put about:config and press the Enter key on your keyboard. 3. Accept the warning about changing settings Because about:config will give you lots of advanced options which can potentially mess up Firefox, you will be warned about not changing anything you're not sure about. Click the "I'll be careful, I promise" button. This warning will appear each time you visit about:config unless you untick the "Show this warning next time" button. We recommend keeping this box ticked to remind you each time! 4. You will now see the list of advanced settings The list of advanced settings looks like this: This warning will appear each time you visit about:config unless you untick the "Show this warning next time" button. -
Download Javascript for Google Chrome Browser How to Enable Javascript in Your Browser
download javascript for google chrome browser How to enable JavaScript in your browser. JavaScript is a dynamic programming language that is used by websites to provide interactive user experience. It is used to make webpages more interactive and dynamic. Mobile Browsers. Desktop PC Browsers. Guidelines for web developers. You might consider linking to this JavaScript download site to notify your script-disabled users on how to enable JavaScript in their browser. Feel free to customize text according to your own needs. Chrome Mobile. Open the Chrome Browser on your phone. Tap the menu icon by clicking ⋮ on the right-top of your screen. Tap on settings. Under the Advance section, tap on Site settings . Tap on JavaScript . Turn on JavaScript and browse your favorite sites. Safari on Apple iPhone. Open the Setting app. Find Safari and tap on it. Find Advanced at the bottom. Turn on JavaScript by swiping the button if it’s disabled. Enjoy your favorite sites with JavaScript Enabled Browser. Google Chrome. You do not need to download JavaScript in the Google Chrome browser; it’s part of the browser. Follow this setting to enable JS in your browser on Windows 10, Windows 7, or macOS. Open the Google Chrome menu by clicking the menu button (⋮) on the right top of the browser. Click on Settings . Scroll down to the Privacy and security section. Click on Site settings . Scroll down to the Content section and click on JavaScript . Enable JavaScript if it’s disabled. It will show “Allowed” when JavaScript is enabled. Apple Safari on Mac. In the top toolbar menu, click on Safari .