A Comparative Study on the Performance Isolation of Virtualization Technologies
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Integrating On-Premises Core Infrastructure with Microsoft Azure
Course 10992 • Microsoft Azure Integrating On-Premises Core Infrastructure with Microsoft Azure Length This 3-day, instructor-led workshop covers a range • 3 days of components, including Azure Compute, Azure Audience Storage, and network services that customers can • IT professionals who have used on- benefit from when deploying hybrid solutions. In premises virtualization technologies, including both this context, the term hybrid means integrating Hyper-V and VMware platforms, but who want to deploy, configure, infrastructure technologies that customers host in and administer services and virtual on-premises datacenters with Azure IaaS and PaaS machines in Azure • IT professionals who have used services. This course offers an overview of these Microsoft System Center to services, providing the knowledge necessary to manage and orchestrate an on- premises server infrastructure design hybrid solutions properly. It also includes • Windows and Linux administrators who are looking to evaluate and several demonstrations and labs that enable migrate on-premises workloads students to develop hands-on skills that are and services to the cloud • IT professionals who need to necessary when implementing such solutions. implement network connectivity between on-premises environments and services that Workshop Outline Azure or Microsoft Office 365 hosts • IT professionals who want to use Module 1: Introduction to Microsoft Azure Azure to increase the resiliency and • Overview of cloud computing and Azure agility of their on-premises • Overview of -

Ovirt and Docker Integration
oVirt and Docker Integration October 2014 Federico Simoncelli Principal Software Engineer – Red Hat oVirt and Docker Integration, Oct 2014 1 Agenda ● Deploying an Application (Old-Fashion and Docker) ● Ecosystem: Kubernetes and Project Atomic ● Current Status of Integration ● oVirt Docker User-Interface Plugin ● “Dockerized” oVirt Engine ● Docker on Virtualization ● Possible Future Integration ● Managing Containers as VMs ● Future Multi-Purpose Data Center oVirt and Docker Integration, Oct 2014 2 Deploying an Application (Old-Fashion) ● Deploying an instance of Etherpad # yum search etherpad Warning: No matches found for: etherpad No matches found $ unzip etherpad-lite-1.4.1.zip $ cd etherpad-lite-1.4.1 $ vim README.md ... ## GNU/Linux and other UNIX-like systems You'll need gzip, git, curl, libssl develop libraries, python and gcc. *For Debian/Ubuntu*: `apt-get install gzip git-core curl python libssl-dev pkg- config build-essential` *For Fedora/CentOS*: `yum install gzip git-core curl python openssl-devel && yum groupinstall "Development Tools"` *For FreeBSD*: `portinstall node, npm, git (optional)` Additionally, you'll need [node.js](http://nodejs.org) installed, Ideally the latest stable version, be careful of installing nodejs from apt. ... oVirt and Docker Integration, Oct 2014 3 Installing Dependencies (Old-Fashion) ● 134 new packages required $ yum install gzip git-core curl python openssl-devel Transaction Summary ================================================================================ Install 2 Packages (+14 Dependent -

Container and Kernel-Based Virtual Machine (KVM) Virtualization for Network Function Virtualization (NFV)
Container and Kernel-Based Virtual Machine (KVM) Virtualization for Network Function Virtualization (NFV) White Paper August 2015 Order Number: 332860-001US YouLegal Lines andmay Disclaimers not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting: http://www.intel.com/ design/literature.htm. Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Learn more at http:// www.intel.com/ or from the OEM or retailer. Results have been estimated or simulated using internal Intel analysis or architecture simulation or modeling, and provided to you for informational purposes. Any differences in your system hardware, software or configuration may affect your actual performance. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. Tests document performance of components on a particular test, in specific systems. -

USING the ZERTO RED HAT CLUSTER MANAGER ZVR-RHC-5.5U3 Rev 01 Dec2017
USING THE ZERTO RED HAT CLUSTER MANAGER ZVR-RHC-5.5U3 Rev 01 Dec2017 Using the Zerto Red Hat Cluster Manager, you can protect a Red Hat Cluster that is comprised of two virtual machines sharing a disk and is managed by Red Hat Clustering Services. Using Jenkins infrastructure hosted by Docker on a Linux virtual machine, Zerto Red Hat Cluster Manager periodically checks the status of the active and passive hosts. If they have changed, the Zerto Cluster Manager: ■ Pauses the VPG that contains the newly passive virtual machine, also known as the passive node. ■ Resumes the VPG that contains the newly active virtual machine, also known as the active node. ■ Forces a sync to ensure that the newly active virtual machine, the active node, is fully synchronized with the recovery site. You can also manually perform the tasks that the Zerto Red Hat Cluster Manager performs. This document describes the following: ■ “Zerto Red Hat Cluster Manager Requirements”, on page 1 ■ “Installing and Configuring the Zerto Red Hat Cluster Manager”, on page 2 ■ “Upgrading a Docker Container”, on page 3 ■ “Protecting a Red Hat Cluster with the Zerto Orchestrator”, on page 4 Zerto Red Hat Cluster Manager Requirements ■ The Zerto Red Hat Cluster Manager works with: ■ Zerto Virtual Replication 4.5 U1 and higher. ■ vCenter Server only. ■ Docker 1.10 and higher. ■ The shared disk in the cluster in the recovery site must be defined as an eager zeroed thick disk. Use this disk for preseeding after the VPG is created. ■ One task in the Zerto Red Hat Cluster Manager can work with a maximum of two nodes. -

Labtainers Student Guide
Labtainers Student Guide Fully provisioned cybersecurity labs December 1, 2020 1 Introduction This manual is intended for use by students performing lab exercises with Labtainers. Labtain- ers provide a fully provisioned execution environment for performing cybersecurity laboratory exercises, including network topologies that include several different interconnected computers. Labtainers assume you have a Linux system, e.g., a virtual machine appliance described below. If you are accessing a Labtainers VM via a web browser, you can skip to section2. 1.1 Obtaining and installing Labtainers The easiest way to obtain Labtainers is to download one of the pre-configured virtual machines from https://nps.edu/web/c3o/virtual-machine-images, and import it into either Virtu- alBox or VMWare. Follow the brief instructions on that download page. When you first boot the resulting VM, Labtainers will take a moment to update itself. You are then provided a terminal that includes some hints, and can be used to run Labtainers. Note that the VM's Ubuntu Linux distribution is configured to NOT automatically perform system updates. It may prompt you to download and install updates. That is typically not necessary and may tie up your network bandwidth. Yes, we are suggesting you not update your Linux VM unless and until you have the time and the bandwidth. You may now skip to section2. 1.2 Alternatives to the Labtainers VM Appliance Skip this section and go to section2 if you are using a Labtainers VM appliance or accessing Labtainers remotvely via a browser. Please note that Docker runs as a privileged service on your computer, and Labtainers containers run as privileged containers. -

Introduction to Containers
Introduction to Containers Martin Čuma Center for High Performance Computing University of Utah [email protected] Overview • Why do we want to use containers? • Containers basics • Run a pre-made container • Build and deploy a container • Containers for complex software 06-Nov-20 http://www.chpc.utah.edu Slide 2 Hands on setup 1. Download the talk slides http://home.chpc.utah.edu/~mcuma/chpc/Containers20s.pdf https://tinyurl.com/yd2xtv5d 2. Using FastX or Putty, ssh to any CHPC Linux machine, e.g. $ ssh [email protected] 3. Load the Singularity and modules $ module load singularity 06-Nov-20 http://www.chpc.utah.edu Slide 3 Hands on setup for building containers 1. Create a GitHub account if you don’t have one https://github.com/join {Remember your username and password!} 2. Go to https://cloud.sylabs.io/home click Remote Builder, then click Sign in to Sylabs and then Sign in with GitHub, using your GitHub account 3. Go to https://cloud.sylabs.io/builder click on your user name (upper right corner), select Access Tokens, write token name, click Create a New Access Token, and copy it 4. In the terminal on frisco, install it to your ~/.singularity/sylabs-token file nano ~/.singularity/sylabs-token, paste, ctrl-x to save 06-Nov-20 http://www.chpc.utah.edu Slide 4 Why to use containers? 06-Nov-20 http://www.chpc.utah.edu Slide 5 Software dependencies • Some programs require complex software environments – OS type and versions – Drivers – Compiler type and versions – Software dependencies • glibc, stdlibc++ versions • Other libraries -

Kubernetes Vs Docker: a Quick Comparison
Kubernetes vs Docker: A Quick Comparison Kubernetes and Docker are different technologies that may work separately—but they’re best paired to facilitate high scalability and availability in containerized applications. While Docker specifically manages containers on individual nodes, Kubernetes helps you automate tasks likeload balancing, scaling, container provisioning, and networking across several hosts within a cluster. Increasing organizational best practices patterns also suggests integrating Kubernetes and Docker to create an isolation mechanism that lets you augment container resources more efficiently. With these constructs, developers can collaborate on complex projects without having to replicate the entire application in their respective IDEs. (This article is part of our Kubernetes Guide. Use the right- hand menu to navigate.) Docker overview Docker is an open-sourcecontainerization platform that simplifies the deployment of applications on any computing infrastructure. While there is a host of other containerized technologies worldwide, Docker continues to be the most popular Platform as a Service for application build and deployment. Through a text file format (dockerfile), Docker lets you package applications as self-sufficient, portable components that you can easily deploy on-premises or on the cloud. Docker’s runtime environment, theDocker Engine, allows developers to build applications on any machine and share images through a registry for faster deployments. Kubernetes overview As applications scale up in size, they require multiple containers hosted on distributed servers. When many distributed containers make operating the application tedious and complicated, Kubernetes forms a framework that efficiently controls how containers run. Besides allowing your containers to run, Kubernetes also solves issues that arise when scaling several distributed containers by orchestrating a cluster ofvirtual machines (VMs) and creates a schedule for running containers on each VM. -

A Comparative Study of Containers and Virtual Machines in Big Data Environment
A Comparative Study of Containers and Virtual Machines in Big Data Environment Qi Zhang1, Ling Liu2, Calton Pu2, Qiwei Dou3, Liren Wu3, and Wei Zhou3 1IBM Thomas J. Watson Research, New York, USA 2College of Computing, Georgia Institute of Technology, Georgia, USA 3Department of Computer Science, Yunnan University, Yunnan, China Abstract—Container technique is gaining increasing attention able to handle peak resources demands, even when there in recent years and has become an alternative to traditional exist free resources [37], [36]. Another example is the poor virtual machines. Some of the primary motivations for the reproducibility for scientific research when the workloads are enterprise to adopt the container technology include its convenience to encapsulate and deploy applications, lightweight moved from one cloud environment to the other [15]. Even operations, as well as efficiency and flexibility in resources though the workloads are the same, their dependent softwares sharing. However, there still lacks an in-depth and systematic could be slightly different, which leads to inconsistent results. comparison study on how big data applications, such as Spark Recently, container-based techniques, such as Docker[3], jobs, perform between a container environment and a virtual OpenVZ [8], and LXC(Linux Containers) [5], become machine environment. In this paper, by running various Spark applications with different configurations, we evaluate the two an alternative to traditional virtual machines because of environments from many interesting aspects, such as how their agility. The primary motivations for containers to be convenient the execution environment can be set up, what are increasingly adopted are their conveniency to encapsulate, makespans of different workloads running in each setup, how deploy, and isolate applications, lightweight operations, as well efficient the hardware resources, such as CPU and memory, are as efficiency and flexibility in resource sharing. -

Making Containers Easier with HPC Container Maker
Making Containers Easier with HPC Container Maker Scott McMillan NVIDIA Corporation Champaign IL, USA [email protected] Abstract—Containers make it possible for scientists and engi- the HPC data center must be redeployed inside the container. neers to easily use portable and reproducible software environ- This paper describes HPC Container Maker (HPCCM), an ments. However, if the desired application is not already available open source project to address the challenges of creating HPC from a container registry, generating a custom container image from scratch can be challenging for users accustomed to a bare application containers [7]. metal software environment. HPC Container Maker (HPCCM) is an open source project to address these challenges. HPCCM A. Related Work provides a high level, configurable Python recipe format for Environment modules [8] are typically used on HPC sys- deploying HPC components into container images according to tems to manage the software development and runtime envi- best practices. HPCCM recipes are more portable and powerful than native container specification formats, easier to create, and ronment. Whether building an application from source or using produce smaller, well-constructed container images. a pre-compiled binary, the user loads the set of environment Index Terms—containers, singularity, docker, high- modules appropriate for the application, e.g., a compiler, performance computing MPI library, math libraries, and other supporting software components. The software packages have been pre-installed I. INTRODUCTION on the system by the system administrator. A typical HPC Containers simplify software deployments in HPC data system may have hundreds of inter-dependent environment centers by wrapping applications into isolated virtual en- modules. -

Time Provisioning Evaluation of KVM, Docker and Unikernels in a Cloud Platform
2016 16th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing Time provisioning Evaluation of KVM, Docker and Unikernels in a Cloud Platform Bruno Xavier Tiago Ferreto Luis Jersak Pontif´ıcia Universidade Cat´olica Pontif´ıcia Universidade Cat´olica Pontif´ıcia Universidade Cat´olica do Rio Grande do Sul (PUCRS) do Rio Grande do Sul (PUCRS) do Rio Grande do Sul (PUCRS) Email: [email protected] Email: [email protected] Email: [email protected] Abstract—Unikernels are a promising alternative for applica- of the Rally benchmark tool [7] and OSProfiler library [8], tion deployment in cloud platforms. They comprise a very small we conducted the spawning of several instances to investigate footprint, providing better deployment agility and portability the impact on provisioning time under parallel conditions. We among virtualization platforms. Similar to Linux containers, they are a lightweight alternative for deploying distributed applica- choose the OSv project as the Unikernel representative, since it tions based on microservices. However, the comparison of uniker- supports different hypervisors and language runtimes, enabling nels with other virtualization options regarding the concurrent a fairer comparison to Docker and KVM. provisioning of instances, as in the case of microservices-based applications, is still lacking. This paper provides an evaluation II. BACKGROUND of KVM (Virtual Machines), Docker (Containers), and OSv (Unikernel), when provisioning multiple instances concurrently This section presents an overview on the virtualization in an OpenStack cloud platform. We confirmed that OSv out- performs the other options and also identified opportunities for platforms used in our evaluation: KVM, Docker and OSv. -
Docker Issues & Solutions
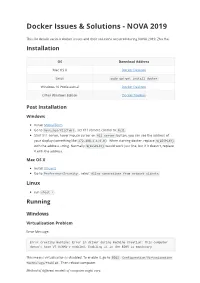
Docker Issues & Solutions - NOVA 2019 This file details various docker issues and their solutions occurred during NOVA 2019, Zhu Hai. Installation OS Download Address Mac OS X Docker Desktop Linux sudo apt-get install docker Windows 10 Professional Docker Desktop Other Windows Edition Docker Toolbox Post Installation Windows Install MobaXTerm Go to Settings/X11(Tab) , set X11 remote control to full Start X11 server, hover mouse cursor on X11 server button, you can see the address of your display (something like 172.168.1.1:0.0 ). When starting docker, replace ${DISPLAY} with the address string. Normally ${DISPLAY} would work just fine, but if it doesn't, replace it with the address. Mac OS X Install XQuartz Go to Preference/Security , select Allow connections from network clients Linux run xhost + Running Windows Virtualisation Problem Error Message: Error creating machine: Error in driver during machine creation: This computer doesn't have VT_X/AMD-v enabled. Enabling it in the BIOS is mandatory This means virtualisation is disabled. To enable it, go to BIOS : Configuration/Virtualization Technology/Enabled . Then reboot computer. Method of different models of computer might vary. Docker Toolbox: Docker Quickstart Terminal Frozen on waiting for an IP Start PowerShell , input docker-machine ls to check current docker virtual machine status. If there's no virtual machine, create one with docker-machine create --driver=virtualbox default . After this, use docker-machine ls to confirm that our docker vm is running. Get docker vm environment variable: docker-machine env default Input docker-machine env default | Invoke-Expression Now you can use PowerShell to run Docker. -

Docker Containers Across Red Hat Solutions
Portable, lightweight, & interoperable Docker containers across Red Hat solutions Jérôme Petazzoni Alexander Larsson Tinkerer Extraordinaire Principal Software engineer Docker, Inc Red Hat, Inc What? Why? Deploy everything •Webapps •Backends •SQL, NoSQL •Big data •Message queues •… and desktop apps and more If it runs on Linux, it will run in a Docker container! Deploy almost everywhere •Linux servers! •Virtual machines •Bare metal •Any distro •Recent kernel Currently: focus on x86_64. (But people reported success on arm.) Deploy reliably & consistently Deploy reliably & consistently •If it works locally, it will work on the server •With exactly the same behavior •Regardless of versions •Regardless of distros •Regardless of dependencies Deploy efficiently •Containers are lightweight • Typical laptop runs 10-100 containers easily • Typical server can run 100-1000 containers •Containers can run at native speeds • Lies, damn lies, and other benchmarks: http://qiita.com/syoyo/items/bea48de8d7c6d8c73435 The performance! It's over 9000! NativeNative Docker container Native Docker container Is there really no overhead at all? •Processes are isolated, but run straight on the host •CPU performance = native performance •Memory performance = a few % shaved off for (optional) accounting •Network performance = small overhead; can be reduced to zero •Disk I/O performance = copy-on-write overhead; can be reduced to zero (use volumes) … Container ? Containers look like lightweight VMs •Own process space •Own network interface •Can run stuff as root •Can