SNP-Array Lesions in Core Binding Factor Acute Myeloid Leukemia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genome-Wide Human SNP Array 6.0
Data Sheet Genome-Wide Human SNP Array 6.0 Introduction The Genome-Wide Human SNP Array 6.0 contains more than 906,600 single nucleotide polymorphisms (SNPs) and more than 946,000 probes for the detection of copy number variation. SNPs on the array are present on 200 to 1,100 base pairs (bp) Nsp I or Sty I digested fragments in the human genome, and are amplified using the Genome-Wide Human SNP Nsp/Sty Assay Kit 5.0/6.0. This assay, which is also compatible with the SNP Array 5.0, now combines the Nsp and Sty fractions previously assayed on two separate arrays. SNPs on the SNP Array 6.0 were screened in more than 500 distinct samples, including 270 HapMap samples and separate diversity samples. Approximately 482,000 SNPs are derived from the previous-generation Mapping 500K and SNP 5.0 Arrays. The remaining 424,000 SNPs include tag SNP markers derived from the International HapMap Project. These novel markers have better representation of SNPs on chromosomes X and Y, mitochondrial SNPs, SNPs in recombination hotspots, and new SNPs added to the dbSNP database after completion of the GeneChip® Human Mapping 500K Array Set. This array contains a total of 946,000 non-polymorphic copy number probes. These probes—744,000 originally selected for their spacing and 202,000 selected based on known copy number changes reported in the Toronto Database of Genomic Variants (DGV)—enable you to detect de novo copy number changes and perform association studies by genotyping both SNP and known copy number polymorphism (CNP) loci (as The Genome-Wide Human SNP Array 6.0 reported by McCarroll, et al.). -

Palmitic Acid Effects on Hypothalamic Neurons
bioRxiv preprint doi: https://doi.org/10.1101/2021.08.03.454666; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Running title: Oleic and palmitic acid effects on hypothalamic neurons Concentration-dependent change in hypothalamic neuronal transcriptome by the dietary fatty acids: oleic and palmitic acids Fabiola Pacheco Valencia1^, Amanda F. Marino1^, Christos Noutsos1, Kinning Poon1* 1Department of Biological Sciences, SUNY Old Westbury, Old Westbury NY, United States ^Authors contributed equally to this work *Corresponding Author: Kinning Poon 223 Store Hill Rd Old Westbury, NY 11568, USA 1-516-876-2735 [email protected] bioRxiv preprint doi: https://doi.org/10.1101/2021.08.03.454666; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Abstract Prenatal high-fat diet exposure increases hypothalamic neurogenesis events in embryos and programs offspring to be obesity-prone. The molecular mechanism involved in these dietary effects of neurogenesis are unknown. This study investigated the effects of oleic and palmitic acids, which are abundant in a high-fat diet, on the hypothalamic neuronal transcriptome and how these changes impact neurogenesis events. The results show differential effects of low and high concentrations of oleic or palmitic acid treatment on differential gene transcription. -

An Integrated Map of Genetic Variation from 1,092 Human Genomes
ARTICLE doi:10.1038/nature11632 An integrated map of genetic variation from 1,092 human genomes The 1000 Genomes Project Consortium* By characterizing the geographic and functional spectrum of human genetic variation, the 1000 Genomes Project aims to build a resource to help to understand the genetic contribution to disease. Here we describe the genomes of 1,092 individuals from 14 populations, constructed using a combination of low-coverage whole-genome and exome sequencing. By developing methods to integrate information across several algorithms and diverse data sources, we provide a validated haplotype map of 38 million single nucleotide polymorphisms, 1.4 million short insertions and deletions, and more than 14,000 larger deletions. We show that individuals from different populations carry different profiles of rare and common variants, and that low-frequency variants show substantial geographic differentiation, which is further increased by the action of purifying selection. We show that evolutionary conservation and coding consequence are key determinants of the strength of purifying selection, that rare-variant load varies substantially across biological pathways, and that each individual contains hundreds of rare non-coding variants at conserved sites, such as motif-disrupting changes in transcription-factor-binding sites. This resource, which captures up to 98% of accessible single nucleotide polymorphisms at a frequency of 1% in related populations, enables analysis of common and low-frequency variants in individuals from diverse, including admixed, populations. Recent efforts to map human genetic variation by sequencing exomes1 individual genome sequences, to help separate shared variants from and whole genomes2–4 have characterized the vast majority of com- those private to families, for example. -

EBF1 Drives Hallmark B Cell Gene Expression by Enabling the Interaction of PAX5 with the MLL H3K4 Methyltransferase Complex Charles E
www.nature.com/scientificreports OPEN EBF1 drives hallmark B cell gene expression by enabling the interaction of PAX5 with the MLL H3K4 methyltransferase complex Charles E. Bullerwell1, Philippe Pierre Robichaud1,2, Pierre M. L. Deprez1, Andrew P. Joy1, Gabriel Wajnberg1, Darwin D’Souza1,3, Simi Chacko1, Sébastien Fournier1, Nicolas Crapoulet1, David A. Barnett1,2, Stephen M. Lewis1,2 & Rodney J. Ouellette1,2* PAX5 and EBF1 work synergistically to regulate genes that are involved in B lymphocyte diferentiation. We used the KIS-1 difuse large B cell lymphoma cell line, which is reported to have elevated levels of PAX5 expression, to investigate the mechanism of EBF1- and PAX5-regulated gene expression. We demonstrate the lack of expression of hallmark B cell genes, including CD19, CD79b, and EBF1, in the KIS-1 cell line. Upon restoration of EBF1 expression we observed activation of CD19, CD79b and other genes with critical roles in B cell diferentiation. Mass spectrometry analyses of proteins co-immunoprecipitated with PAX5 in KIS-1 identifed components of the MLL H3K4 methylation complex, which drives histone modifcations associated with transcription activation. Immunoblotting showed a stronger association of this complex with PAX5 in the presence of EBF1. Silencing of KMT2A, the catalytic component of MLL, repressed the ability of exogenous EBF1 to activate transcription of both CD19 and CD79b in KIS-1 cells. We also fnd association of PAX5 with the MLL complex and decreased CD19 expression following silencing of KMT2A in other human B cell lines. These data support an important role for the MLL complex in PAX5-mediated transcription regulation. -

Chromosome SNP Microarray a New High-Density Allele-Specific Diagnostic Platform
Chromosome SNP Microarray A New High-density Allele-specific Diagnostic Platform Analysis of submicroscopic genomic changes can pair (allele) targets that have two different forms, revealing which form is present at that locus as well as the number of copies of that detect the cause of congenital anomalies and/or DNA segment. CGH-based arrays cannot detect polymorphic allele learning disabilities. targets (only dosage), resulting in a significant advantage for the SNP array. This advantage is based both on added confirmation of Introduction dosage changes through allele comparisons and the identification of Genetic imbalances are often associated with multiple birth defects, syndrome-associated “copy neutral” contiguous stretches of allele developmental delay, growth retardation, and dysmorphic features. homozygosity. The presence of the latter allows for detection of Standard cytogenetic analysis can identify visible chromosomal uniparental disomy for all chromosomes and, when consanguinity alterations, such as an extra chromosome band, but small deletions is present, it will provide the degree as well as the resulting genomic or duplications in the genome cannot be reliably detected. location of regions of recessive allele risk.5,6 Submicroscopic unbalanced rearrangements have been found in approximately 3% of patients with learning disabilities and mental Increase in Genomic Targets retardation of unknown cause using a set of FISH (fluorescence The initial 262,000 SNP microarray has been upgraded to offer a in situ hybridization) probes that can only target the ends of the much more dense array of 1.8 million genomic targets (marker every chromosomes.1 700 bp).7 The ultra dense array is much more sensitive in identifying extremely small genomic variations and more statistically reliable Advances in molecular cytogenetics further improved the sensitivity due to the large increase in markers through which each variation is of testing through the application of microarray-based comparative detected. -

Identity-By-Descent Detection Across 487,409 British Samples Reveals Fine Scale Population Structure and Ultra-Rare Variant Asso
ARTICLE https://doi.org/10.1038/s41467-020-19588-x OPEN Identity-by-descent detection across 487,409 British samples reveals fine scale population structure and ultra-rare variant associations ✉ Juba Nait Saada 1 , Georgios Kalantzis 1, Derek Shyr 2, Fergus Cooper 3, Martin Robinson 3, ✉ Alexander Gusev 4,5,7 & Pier Francesco Palamara 1,6,7 1234567890():,; Detection of Identical-By-Descent (IBD) segments provides a fundamental measure of genetic relatedness and plays a key role in a wide range of analyses. We develop FastSMC, an IBD detection algorithm that combines a fast heuristic search with accurate coalescent-based likelihood calculations. FastSMC enables biobank-scale detection and dating of IBD segments within several thousands of years in the past. We apply FastSMC to 487,409 UK Biobank samples and detect ~214 billion IBD segments transmitted by shared ancestors within the past 1500 years, obtaining a fine-grained picture of genetic relatedness in the UK. Sharing of common ancestors strongly correlates with geographic distance, enabling the use of genomic data to localize a sample’s birth coordinates with a median error of 45 km. We seek evidence of recent positive selection by identifying loci with unusually strong shared ancestry and detect 12 genome-wide significant signals. We devise an IBD-based test for association between phenotype and ultra-rare loss-of-function variation, identifying 29 association sig- nals in 7 blood-related traits. 1 Department of Statistics, University of Oxford, Oxford, UK. 2 Department of Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA 02115, USA. 3 Department of Computer Science, University of Oxford, Oxford, UK. -

Regions of Homozygosity Identified by SNP Microarray Analysis Aid in The
ORIGINAL RESEARCH ARTICLE ©American College of Medical Genetics and Genomics Regions of homozygosity identified bySN P microarray analysis aid in the diagnosis of autosomal recessive disease and incidentally detect parental blood relationships Kristen Lipscomb Sund, PhD, MS1, Sarah L. Zimmerman, PhD1, Cameron Thomas, MD2, Anna L. Mitchell, MD, PhD3, Carlos E. Prada, MD1, Lauren Grote, BS1, Liming Bao, MD, PhD1, Lisa J. Martin, PhD1 and Teresa A. Smolarek, PhD1 Purpose: The purpose of this study was to document the ability of was suspected in the parents of at least 11 patients with regions of single-nucleotide polymorphism microarray to identify copy-neutral homozygosity covering >21.3% of their autosome. In four patients regions of homozygosity, demonstrate clinical utility of regions of from two families, homozygosity mapping discovered a candidate homozygosity, and discuss ethical/legal implications when regions of gene that was sequenced to identify a clinically significant mutation. homozygosity are associated with a parental blood relationship. Conclusion: This study demonstrates clinical utility in the identifica- Methods: Study data were compiled from consecutive samples tion of regions of homozygosity, as these regions may aid in diagnosis sent to our clinical laboratory over a 3-year period. A cytogenetics of the patient. This study establishes the need for careful reporting, database identified patients with at least two regions of homozygosity thorough pretest counseling, and careful electronic documentation, >10 Mb on two separate chromosomes. A chart review was conduct- as microarray has the capability of detecting previously unknown/ ed on patients who met the criteria. unreported relationships. Results: Of 3,217 single-nucleotide polymorphism microarrays, Genet Med 2013:15(1):70–78 59 (1.8%) patients met inclusion criteria. -

Genetic Profiles of 103,106 Individuals in the Taiwan Biobank Provide Insights Into the Health and History of Han Chinese
UCSF UC San Francisco Previously Published Works Title Genetic profiles of 103,106 individuals in the Taiwan Biobank provide insights into the health and history of Han Chinese. Permalink https://escholarship.org/uc/item/9s81s8g7 Journal NPJ genomic medicine, 6(1) ISSN 2056-7944 Authors Wei, Chun-Yu Yang, Jenn-Hwai Yeh, Erh-Chan et al. Publication Date 2021-02-11 DOI 10.1038/s41525-021-00178-9 Peer reviewed eScholarship.org Powered by the California Digital Library University of California www.nature.com/npjgenmed ARTICLE OPEN Genetic profiles of 103,106 individuals in the Taiwan Biobank provide insights into the health and history of Han Chinese Chun-Yu Wei1,4, Jenn-Hwai Yang1,4, Erh-Chan Yeh1, Ming-Fang Tsai1, Hsiao-Jung Kao1, Chen-Zen Lo1, Lung-Pao Chang1, Wan-Jia Lin1, Feng-Jen Hsieh1, Saurabh Belsare 2, Anand Bhaskar 3, Ming-Wei Su1, Te-Chang Lee1, Yi-Ling Lin1, Fu-Tong Liu1, Chen-Yang Shen1, ✉ Ling-Hui Li1, Chien-Hsiun Chen1, Jeffrey D. Wall2, Jer-Yuarn Wu1 and Pui-Yan Kwok 1,2 Personalized medical care focuses on prediction of disease risk and response to medications. To build the risk models, access to both large-scale genomic resources and human genetic studies is required. The Taiwan Biobank (TWB) has generated high- coverage, whole-genome sequencing data from 1492 individuals and genome-wide SNP data from 103,106 individuals of Han Chinese ancestry using custom SNP arrays. Principal components analysis of the genotyping data showed that the full range of Han Chinese genetic variation was found in the cohort. -

SNP Ascertainment Bias in Population Genetic Analyses: Why It Is Important, and How to Correct It Recently in Press
Prospects & Overviews SNP ascertainment bias in population genetic analyses: Why it is important, and how to correct it Recently in press Joseph Lachanceà and Sarah A. Tishkoff Whole genome sequencing and SNP genotyping arrays African hunter-gatherers and the power can paint strikingly different pictures of demographic of whole genome sequencing history and natural selection. This is because genotyping arrays contain biased sets of pre-ascertained SNPs. In this Due to technological advances and increases in computation- al power, the cost of genotyping has plummeted over the past short review, we use comparisons between high-coverage few years. Because of this, it is now feasible to conduct whole genome sequences of African hunter-gatherers and population genetic analyses of whole genome sequencing data from genotyping arrays to highlight how SNP data. One advantage of whole genome sequencing is that ascertainment bias distorts population genetic inferences. SNP ascertainment bias is reduced compared to alternative Sample sizes and the populations in which SNPs are genotyping technologies. This lack of SNP ascertainment bias discovered affect the characteristics of observed variants. is critical for accurate population genetic analyses where allele frequency distributions are used to infer demographic We find that SNPs on genotyping arrays tend to be older history and scan for past targets of natural selection. Using the and present in multiple populations. In addition, geno- technology of Complete Genomics [1], we recently sequenced typing arrays cause allele frequency distributions to be the whole genomes of 15 African hunter-gatherers at >60 shifted towards intermediate frequency alleles, and coverage [2]. Sequenced individuals included five Pygmies estimates of linkage disequilibrium are modified. -

Mutagenesys: Estimating Individual Disease Susceptibility Based On
Vol. 24 no. 3 2008, pages 440–442 BIOINFORMATICS APPLICATIONS NOTE doi:10.1093/bioinformatics/btm587 Databases and ontologies MutaGeneSys: estimating individual disease susceptibility based on genome-wide SNP array data Julia Stoyanovich* and Itsik Pe’er Department of Computer Science, Columbia University, 1214 Amsterdam Avenue, New York, NY 10025, USA Received on May 29, 2007; revised on October 16, 2007; accepted on November 22, 2007 Advance Access publication November 29, 2007 Associate Editor: Jonathan Wren ABSTRACT First and foremost, genetic information remains expensive Summary: We present MutaGeneSys: a system that uses genome- to collect, and it is currently economically prohibitive to wide genotype data to estimate disease susceptibility. Our system make a complete set of an individual’s genotypes of SNPs integrates three data sources: the International HapMap project, available for analysis. Nature Genetics’ ‘Question of the Year’ whole-genome marker correlation data and the Online Mendelian (www.nature.com/ng/qoty) announced the sequencing of the Inheritance in Man (OMIM) database. It accepts SNP data of indivi- entire human genome for $1000 as a goal for the genetics duals as query input and delivers disease susceptibility hypotheses community. Cost-effective methods (e.g. SNP arrays) currently even if the original set of typed SNPs is incomplete. Our system exist for collecting genetic data from 1% to 5% of all 11 million is scalable and flexible: it produces population, technology and human SNPs. This calls for the development of techniques that confidence-specific predictions in interactive time. can effectively utilize partial genetic information for disease Availability: Our system is available as an online resource at http:// prediction. -

Pharmacogenomics and Personalized Medicine: the Plunge Into Next-Generation Sequencing Mia Wadelius1* and Ana Al Revic2
Wadelius and Alrevic Genome Medicine 2011, 3:78 http://genomemedicine.com/content/3/12/78 MEETING REPORT Pharmacogenomics and personalized medicine: the plunge into next-generation sequencing Mia Wadelius1* and Ana Alrevic2 Abstract technology has led to a drastic drop in the cost (>10,000-fold) and time (from 10 years to 1 week) needed A report on the 9th Annual Cold Spring Harbor/ to sequence a genome. NGS is now being introduced as a Wellcome Trust meeting ‘Pharmacogenomics and method to personalize medicine. Personalized Medicine’, Hinxton, Cambridge, UK, Yingrui Li (Beijing Genomics Institute, China) des- 29 September to 2 October 2011. cribed the sequencing revolution that has made personal Keywords Consortium, genome-wide association genomes affordable, while it remains difficult and costly study, meta-analysis, next-generation sequencing, to interpret the results. Recent whole genome sequencing pharmacogenomics/pharmacogenetics, public health of individuals at the Beijing Genomics Institute has genomics, P4 medicine. shown an excess of rare deleterious SNPs together with extensive structural variations and novel individual specific sequences with potential functional impact. ese In recent years, pharmacogenomics has moved beyond new genetic variants are likely to explain part of the candidate gene and genome-wide association studies missing heritability seen with previous GWASs. Interest- (GWASs) towards truly personalized genomics. e use ingly, Li reported that more ethnic-specific haplotypes of new biotechnological, mathematical and computa- exist than previously thought and that each defined tional tools has enabled an exponential increase in the population will need its own genome-wide tag SNP array. number of biomarkers for drug safety and efficacy; how- is is a general problem that must be considered when ever, their clinical utility in achieving personalized performing pharmacogenetic GWASs in non-Caucasian therapy remains to be determined. -
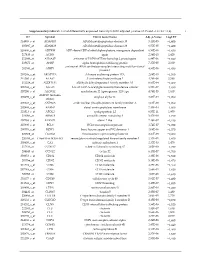
Supplementary Table S1. List of Differentially Expressed
Supplementary table S1. List of differentially expressed transcripts (FDR adjusted p‐value < 0.05 and −1.4 ≤ FC ≥1.4). 1 ID Symbol Entrez Gene Name Adj. p‐Value Log2 FC 214895_s_at ADAM10 ADAM metallopeptidase domain 10 3,11E‐05 −1,400 205997_at ADAM28 ADAM metallopeptidase domain 28 6,57E‐05 −1,400 220606_s_at ADPRM ADP‐ribose/CDP‐alcohol diphosphatase, manganese dependent 6,50E‐06 −1,430 217410_at AGRN agrin 2,34E‐10 1,420 212980_at AHSA2P activator of HSP90 ATPase homolog 2, pseudogene 6,44E‐06 −1,920 219672_at AHSP alpha hemoglobin stabilizing protein 7,27E‐05 2,330 aminoacyl tRNA synthetase complex interacting multifunctional 202541_at AIMP1 4,91E‐06 −1,830 protein 1 210269_s_at AKAP17A A‐kinase anchoring protein 17A 2,64E‐10 −1,560 211560_s_at ALAS2 5ʹ‐aminolevulinate synthase 2 4,28E‐06 3,560 212224_at ALDH1A1 aldehyde dehydrogenase 1 family member A1 8,93E‐04 −1,400 205583_s_at ALG13 ALG13 UDP‐N‐acetylglucosaminyltransferase subunit 9,50E‐07 −1,430 207206_s_at ALOX12 arachidonate 12‐lipoxygenase, 12S type 4,76E‐05 1,630 AMY1C (includes 208498_s_at amylase alpha 1C 3,83E‐05 −1,700 others) 201043_s_at ANP32A acidic nuclear phosphoprotein 32 family member A 5,61E‐09 −1,760 202888_s_at ANPEP alanyl aminopeptidase, membrane 7,40E‐04 −1,600 221013_s_at APOL2 apolipoprotein L2 6,57E‐11 1,600 219094_at ARMC8 armadillo repeat containing 8 3,47E‐08 −1,710 207798_s_at ATXN2L ataxin 2 like 2,16E‐07 −1,410 215990_s_at BCL6 BCL6 transcription repressor 1,74E‐07 −1,700 200776_s_at BZW1 basic leucine zipper and W2 domains 1 1,09E‐06 −1,570 222309_at