A Semi-Supervised Heat Kernel Pagerank Mbo Algorithm for Data Classification∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Heat Kernels and Function Theory on Metric Measure Spaces
Heat kernels and function theory on metric measure spaces Alexander Grigor’yan Imperial College London SW7 2AZ United Kingdom and Institute of Control Sciences of RAS Moscow, Russia email: [email protected] Contents 1 Introduction 2 2 Definition of a heat kernel and examples 5 3 Volume of balls 8 4 Energy form 10 5 Besov spaces and energy domain 13 5.1 Besov spaces in Rn ............................ 13 5.2 Besov spaces in a metric measure space . 14 5.3 Identification of energy domains and Besov spaces . 15 5.4 Subordinated heat kernel ......................... 19 6 Intrinsic characterization of walk dimension 22 7 Inequalities for walk dimension 23 8 Embedding of Besov spaces into H¨olderspaces 29 9 Bessel potential spaces 30 1 1 Introduction The classical heat kernel in Rn is the fundamental solution to the heat equation, which is given by the following formula 1 x y 2 pt (x, y) = exp | − | . (1.1) n/2 t (4πt) − 4 ! x y 2 It is worth observing that the Gaussian term exp | − | does not depend in n, − 4t n/2 whereas the other term (4πt)− reflects the dependence of the heat kernel on the underlying space via its dimension. The notion of heat kernel extends to any Riemannian manifold M. In this case, the heat kernel pt (x, y) is the minimal positive fundamental solution to the heat ∂u equation ∂t = ∆u where ∆ is the Laplace-Beltrami operator on M, and it always exists (see [11], [13], [16]). Under certain assumptions about M, the heat kernel can be estimated similarly to (1.1). -

Heat Kernel Analysis on Graphs
Heat Kernel Analysis On Graphs Xiao Bai Submitted for the degree of Doctor of Philosophy Department of Computer Science June 7, 2007 Abstract In this thesis we aim to develop a framework for graph characterization by com- bining the methods from spectral graph theory and manifold learning theory. The algorithms are applied to graph clustering, graph matching and object recogni- tion. Spectral graph theory has been widely applied in areas such as image recog- nition, image segmentation, motion tracking, image matching and etc. The heat kernel is an important component of spectral graph theory since it can be viewed as describing the flow of information across the edges of the graph with time. Our first contribution is to investigate how to extract useful and stable invari- ants from the graph heat kernel as a means of clustering graphs. The best set of invariants are the heat kernel trace, the zeta function and its derivative at the origin. We also study heat content invariants. The polynomial co-efficients can be computed from the Laplacian eigensystem. Graph clustering is performed by applying principal components analysis to vectors constructed from the invari- ants or simply based on the unitary features extracted from the graph heat kernel. We experiment with the algorithms on the COIL and Oxford-Caltech databases. We further investigate the heat kernel as a means of graph embedding. The second contribution of the thesis is the introduction of two graph embedding methods. The first of these uses the Euclidean distance between graph nodes. To do this we equate the spectral and parametric forms of the heat kernel to com- i pute an approximate Euclidean distance between nodes. -

Inverse Spectral Problems in Riemannian Geometry
Inverse Spectral Problems in Riemannian Geometry Peter A. Perry Department of Mathematics, University of Kentucky, Lexington, Kentucky 40506-0027, U.S.A. 1 Introduction Over twenty years ago, Marc Kac posed what is arguably one of the simplest inverse problems in pure mathematics: "Can one hear the shape of a drum?" [19]. Mathematically, the question is formulated as follows. Let /2 be a simply connected, plane domain (the drumhead) bounded by a smooth curve 7, and consider the wave equation on /2 with Dirichlet boundary condition on 7 (the drumhead is clamped at the boundary): Au(z,t) = ~utt(x,t) in/2, u(z, t) = 0 on 7. The function u(z,t) is the displacement of the drumhead, as it vibrates, at position z and time t. Looking for solutions of the form u(z, t) = Re ei~tv(z) (normal modes) leads to an eigenvalue problem for the Dirichlet Laplacian on B: v(x) = 0 on 7 (1) where A = ~2/c2. We write the infinite sequence of Dirichlet eigenvalues for this problem as {A,(/2)}n=l,c¢ or simply { A-},~=1 co it" the choice of domain/2 is clear in context. Kac's question means the following: is it possible to distinguish "drums" /21 and/22 with distinct (modulo isometrics) bounding curves 71 and 72, simply by "hearing" all of the eigenvalues of the Dirichlet Laplacian? Another way of asking the question is this. What is the geometric content of the eigenvalues of the Laplacian? Is there sufficient geometric information to determine the bounding curve 7 uniquely? In what follows we will call two domains isospectral if all of their Dirichlet eigenvalues are the same. -

Three Examples of Quantum Dynamics on the Half-Line with Smooth Bouncing
Three examples of quantum dynamics on the half-line with smooth bouncing C. R. Almeida Universidade Federal do Esp´ıritoSanto, Vit´oria,29075-910, ES, Brazil H. Bergeron ISMO, UMR 8214 CNRS, Univ Paris-Sud, France J.P. Gazeau Laboratoire APC, UMR 7164, Univ Paris Diderot, Sorbonne Paris-Cit´e75205 Paris, France A.C. Scardua Centro Brasileiro de Pesquisas F´ısicas, Rua Xavier Sigaud 150, 22290-180 - Rio de Janeiro, RJ, Brazil Abstract This article is an introductory presentation of the quantization of the half-plane based on affine coherent states (ACS). The half-plane is viewed as the phase space for the dynamics of a positive physical quantity evolving with time, and its affine symmetry is preserved due to the covariance of this type of quantization. We promote the interest of such a procedure for transforming a classical model into a quantum one, since the singularity at the origin is systematically removed, and the arbitrari- ness of boundary conditions can be easily overcome. We explain some important mathematical aspects of the method. Three elementary examples of applications are presented, the quantum breathing of a massive sphere, the quantum smooth bounc- ing of a charged sphere, and a smooth bouncing of \dust" sphere as a simple model of quantum Newtonian cosmology. Keywords: Integral quantization, Half-plane, Affine symmetry, Coherent states, arXiv:1708.06422v2 [quant-ph] 31 Aug 2017 Quantum smooth bouncing Email addresses: [email protected] (C. R. Almeida), [email protected] (H. Bergeron), [email protected] (J.P. -

Introduction
Traceglobfin June 3, 2011 Copyrighted Material Introduction The purpose of this book is to use the hypoelliptic Laplacian to evaluate semisimple orbital integrals, in a formalism that unifies index theory and the trace formula. 0.1 The trace formula as a Lefschetz formula Let us explain how to think formally of such a unified treatment, while allowing ourselves a temporarily unbridled use of mathematical analogies. Let X be a compact Riemannian manifold, and let ΔX be the corresponding Laplace-Beltrami operator. For t > 0, consider the trace of the heat kernel Tr pexp h ΔX 2m . If X is the Hilbert space of square-integrable functions t = L2 on X, Tr pexp htΔX =2 m is the trace of the ‘group element’ exp htΔX =2 m X acting on L2 . X X Suppose that L2 is the cohomology of an acyclic complex R on which Δ acts. Then Tr pexp htΔX =2 m can be viewed as the evaluation of a Lefschetz trace, so that cohomological methods can be applied to the evaluation of this trace. In our case, R will be the fibrewise de Rham complex of the total space Xb of a flat vector bundle over X, which contains TX as a subbundle. The Lefschetz fixed point formulas of Atiyah-Bott [ABo67, ABo68] provide a model for the evaluation of such cohomological traces. R The McKean-Singer formula [McKS67] indicates that if D is a Hodge like Laplacian operator acting on R and commuting with ΔX , for any b > 0, X L2 p hX m R p h X R 2m Tr exp tΔ =2 = Trs exp tΔ =2 − tD =2b : (0.1) In (0.1), Trs is our notation for the supertrace. -

Heat Kernels
Chapter 3 Heat Kernels In this chapter, we assume that the manifold M is compact and the general- ized Laplacian H is not necessarily symmetric. Note that if M is non-compact and H is symmetric, we can study the heat kernel following the lines of Spectral theorem and the Schwartz kernel theorem. We will not discuss it here. 3.1 heat kernels 3.1.1 What is kernel? Let H be a generalized Laplacian on a vector bundle E over a compact Riemannian oriented manifold M. Let E and F be Hermitian vector bundles over M. Let p1 and p2 be the projections from M × M onto the first and the second factor M respectively. We denote by ⊠ ∗ ⊗ ∗ E F := p1E p2F (3.1.1) over M × M. Definition 3.1.1. A continuous section P (x; y) on F ⊠E∗) is called a kernel. Using P (x; y), we could define an operator P : C 1(M; E) ! C 1(M; F ) by Z (P u)(x) = hP (x; y); u(y)iEdy: (3.1.2) y2M The kernel P (x; y) is also called the kernel of P , which is also denoted by hxjP jyi. 99 100 CHAPTER 3. HEAT KERNELS Proposition 3.1.2. If P has a kernel P (x; y), then the adjoint operator P ∗ has a kernel P ∗(x; y) = P (y; x)∗ 2 C 1(M × M; E∗ ⊠ F )1. Proof. For u 2 L2(M; E), v 2 L2(M; F ∗), we have Z ⟨Z ⟩ (P u; v)L2 = hP (x; y); u(y)iEdy; v(x) dx x2MZ y2⟨M Z F ⟩ ∗ = u(y); hP (x; y) ; v(x)iF dx dy Z ⟨ y2M Z x2M ⟩ E ∗ ∗ = u(x); hP (y; x) ; v(y)iF dy dx = (u; P v)L2 : (3.1.3) x2M y2M E So for any v 2 L2(M; F ∗), Z ∗ ∗ P v = hP (y; x) ; v(y)iF dy: (3.1.4) y2M The proof of Proposition 3.1.2 is completed. -
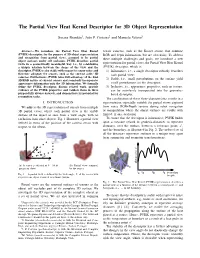
The Partial View Heat Kernel Descriptor for 3D Object Representation
The Partial View Heat Kernel Descriptor for 3D Object Representation Susana Brandao˜ 1, Joao˜ P. Costeira2 and Manuela Veloso3 Abstract— We introduce the Partial View Heat Kernel sensor cameras, such as the Kinect sensor, that combine (PVHK) descriptor, for the purpose of 3D object representation RGB and depth information, but are also noisy. To address and recognition from partial views, assumed to be partial these multiple challenges and goals, we introduce a new object surfaces under self occlusion. PVHK describes partial views in a geometrically meaningful way, i.e., by establishing representation for partial views, the Partial View Heat Kernel a unique relation between the shape of the view and the (PVHK) descriptor, which is: descriptor. PVHK is also stable with respect to sensor noise and 1) Informative, i.e., a single descriptor robustly describes therefore adequate for sensors, such as the current active 3D each partial view; cameras. Furthermore, PVHK takes full advantage of the dual 3D/RGB nature of current sensors and seamlessly incorporates 2) Stable, i.e., small perturbations on the surface yield appearance information onto the 3D information. We formally small perturbations on the descriptor; define the PVHK descriptor, discuss related work, provide 3) Inclusive, i.e., appearance properties, such as texture, evidence of the PVHK properties and validate them in three can be seamlessly incorporated into the geometry- purposefully diverse datasets, and demonstrate its potential for based descriptor. recognition tasks. The combination of these three characteristics results in a I. INTRODUCTION representation especially suitable for partial views captured We address the 3D representation of objects from multiple from noisy RGB+Depth sensors during robot navigation 3D partial views, where each partial view is the visible or manipulation where the object surfaces are visible with surface of the object as seen from a view angle, with no limited, if any, occlusion. -

Heat Kernel Smoothing in Irregular Image Domains Moo K
1 Heat Kernel Smoothing in Irregular Image Domains Moo K. Chung1, Yanli Wang2, Gurong Wu3 1University of Wisconsin, Madison, USA Email: [email protected] 2Institute of Applied Physics and Computational Mathematics, Beijing, China Email: [email protected] 3University of North Carolina, Chapel Hill, USA Email: [email protected] Abstract We present the discrete version of heat kernel smoothing on graph data structure. The method is used to smooth data in an irregularly shaped domains in 3D images. New statistical properties are derived. As an application, we show how to filter out data in the lung blood vessel trees obtained from computed tomography. The method can be further used in representing the complex vessel trees parametrically and extracting the skeleton representation of the trees. I. INTRODUCTION Heat kernel smoothing was originally introduced in the context of filtering out surface data defined on mesh vertices obtained from 3D medical images [1], [2]. The formulation uses the tangent space projection in approximating the heat kernel by iteratively applying Gaussian kernel with smaller bandwidth. Recently proposed spectral formulation to heat kernel smoothing [3] constructs the heat kernel analytically using the eigenfunctions of the Laplace-Beltrami (LB) operator, avoiding the need for the linear approximation used in [1], [4]. In this paper, we present the discrete version of heat kernel smoothing on graphs. Instead of Laplace- Beltrami operator, graph Laplacian is used to construct the discrete version of heat kernel smoothing. New statistical properties are derived for kernel smoothing that utilizes the fact heat kernel is a probability distribution. Heat kernel smoothing is used to smooth out data defined on irregularly shaped domains in 3D images. -

Estimates of Heat Kernels for Non-Local Regular Dirichlet Forms
TRANSACTIONS OF THE AMERICAN MATHEMATICAL SOCIETY Volume 366, Number 12, December 2014, Pages 6397–6441 S 0002-9947(2014)06034-0 Article electronically published on July 24, 2014 ESTIMATES OF HEAT KERNELS FOR NON-LOCAL REGULAR DIRICHLET FORMS ALEXANDER GRIGOR’YAN, JIAXIN HU, AND KA-SING LAU Abstract. In this paper we present new heat kernel upper bounds for a cer- tain class of non-local regular Dirichlet forms on metric measure spaces, in- cluding fractal spaces. We use a new purely analytic method where one of the main tools is the parabolic maximum principle. We deduce an off-diagonal upper bound of the heat kernel from the on-diagonal one under the volume reg- ularity hypothesis, restriction of the jump kernel and the survival hypothesis. As an application, we obtain two-sided estimates of heat kernels for non-local regular Dirichlet forms with finite effective resistance, including settings with the walk dimension greater than 2. Contents 1. Introduction 6397 2. Terminology and main results 6402 3. Tail estimates for quasi-local Dirichlet forms 6407 4. Heat semigroup of the truncated Dirichlet form 6409 5. Proof of Theorem 2.1 6415 6. Heat kernel bounds using effective resistance 6418 7. Appendix A: Parabolic maximum principle 6437 8. Appendix B: List of lettered conditions 6438 References 6439 1. Introduction We are concerned with heat kernel estimates for a class of non-local regular Dirichlet forms. Let (M,d) be a locally compact separable metric space and let μ be a Radon measure on M with full support. The triple (M,d,μ) will be referred to as a metric measure space. -

Heat Kernel Voting with Geometric Invariants
Minnesota State University, Mankato Cornerstone: A Collection of Scholarly and Creative Works for Minnesota State University, Mankato All Theses, Dissertations, and Other Capstone Graduate Theses, Dissertations, and Other Projects Capstone Projects 2020 Heat Kernel Voting with Geometric Invariants Alexander Harr Minnesota State University, Mankato Follow this and additional works at: https://cornerstone.lib.mnsu.edu/etds Part of the Algebraic Geometry Commons, and the Geometry and Topology Commons Recommended Citation Harr, A. (2020). Heat kernel voting with geometric invariants [Master’s thesis, Minnesota State University, Mankato]. Cornerstone: A Collection of Scholarly and Creative Works for Minnesota State University, Mankato. https://cornerstone.lib.mnsu.edu/etds/1021/ This Thesis is brought to you for free and open access by the Graduate Theses, Dissertations, and Other Capstone Projects at Cornerstone: A Collection of Scholarly and Creative Works for Minnesota State University, Mankato. It has been accepted for inclusion in All Theses, Dissertations, and Other Capstone Projects by an authorized administrator of Cornerstone: A Collection of Scholarly and Creative Works for Minnesota State University, Mankato. Heat Kernel Voting with Geometric Invariants By Alexander Harr Supervised by Dr. Ke Zhu A thesis submitted in partial fulfillment of the requirements for the degree of Master of Arts at Mankato State University, Mankato Mankato State University, Mankato Mankato, Minnesota May 2020 May 8, 2020 Heat Kernel Voting with Geometric Invariants Alexander Harr This thesis has been examined and approved by the following members of the student's committee: Dr. Ke Zhu (Supervisor) Dr. Wook Kim (Committee Member) Dr. Brandon Rowekamp (Committee Member) ii Acknowledgements This has been difficult, and anything worthwhile here is due entirely to the help of others. -

The Heat Kernel on Noncompact Symmetric Spaces Jean-Philippe Anker, Patrick Ostellari
The heat kernel on noncompact symmetric spaces Jean-Philippe Anker, Patrick Ostellari To cite this version: Jean-Philippe Anker, Patrick Ostellari. The heat kernel on noncompact symmetric spaces. S. G. Gindikin. Lie groups and symmetric spaces, Amer. Math. Soc., pp.27-46, 2003, Amer. Math. Soc. Transl. Ser. 2, vol. 210. hal-00002509 HAL Id: hal-00002509 https://hal.archives-ouvertes.fr/hal-00002509 Submitted on 9 Aug 2004 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. THE HEAT KERNEL ON NONCOMPACT SYMMETRIC SPACES Jean{Philippe Anker & Patrick Ostellari In memory of F. I. Karpeleviˇc (1927{2000) The heat kernel plays a central role in mathematics. It occurs in several fields : analysis, geometry and { last but not least { probability theory. In this survey, we shall focus on its analytic aspects, specifically sharp bounds, in the particular setting of Riemannian symmetric spaces of noncompact type. It is a natural tribute to Karpeleviˇc, whose pioneer work [Ka] inspired further study of the geometry of theses spaces and of the analysis of the Laplacian thereon. This survey is based on lectures delivered by the first author in May 2002 at IHP in Paris during the Special Quarter Heat kernels, random walks & analysis on manifolds & graphs. -

What Is the Heat Kernel?
What is the heat kernel? Asilya Suleymanova June 2015 Contents 1 Introduction 1 2 Integral operator on a manifold 1 3 Heat kernel 2 3.1 Heat equation . .2 3.2 Asymptotic expansion . .3 3.3 The index theorem . .5 1 Introduction We begin with the definition of a linear integral operation and a notion of a kernel of an integral operator. Some illustrative examples and basic properties will be provided. Before we define the heat kernel on a compact manifold, we construct the explicit formulas for some model spaces such as Euclidian space and hyperbolic space. In the end the main idea of the heat kernel approach to the proof of the index theorem will be given. Let M be a compact manifold with a non-negative measure µ. 2 Integral operator on a manifold Definition 1. Let k : M × M ! R be a continuous function. An linear integral operator Lk with kernel k is formally defined by Z Lkf(x) = k(x; y)f(y)dµ(d); (2.1) M where f : M ! R is a continuous function. 1 Remark. For a compact manifold 2.1 is indeed a linear bounded operator on C(M). For a non-compact manifold see [J] An integral operator is a generalisation of an ordinary matrix multiplica- n tion. Let A = (aij) be n × n matrix and let u 2 R be a vector. Then Au is also a n-dimensional vector and n X (Au)i = aijuj; i = 1; :::; n: i=1 Thus, the function values k(x; y) are analogous to the entries aij of the matrix A, and the values Lkf(x) are analogous to the entries (Au)i.