Annotation Efficient Language Identification from Weak Labels
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SL.NO CHANNEL LCN Genre STAR PLUS 101 HINDI GEC
SL.NO CHANNEL LCN Genre 1 STAR PLUS 101 HINDI GEC PAY 2 ZEE TV 102 HINDI GEC PAY 3 SET 103 HINDI GEC PAY 4 COLORS 104 HINDI GEC PAY 5 &TV 105 HINDI GEC PAY 6 SAB 106 HINDI GEC PAY 7 STAR BHARAT 107 HINDI GEC PAY 8 BIG MAGIC 108 HINDI GEC PAY 9 PAL 109 HINDI GEC PAY 10 COLORS RISHTEY 110 HINDI GEC PAY 11 STAR UTSAV 111 HINDI GEC PAY 12 ZEE ANMOL 112 HINDI GEC PAY 13 BINDASS 113 HINDI GEC PAY 14 ZOOM 114 HINDI GEC PAY 15 DISCOVERY JEET 115 HINDI GEC PAY 16 STAR GOLD 135 HINDI MOVIES PAY 17 ZEE CINEMA 136 HINDI MOVIES PAY 18 SONY MAX 137 HINDI MOVIES PAY 19 &PICTURES 138 HINDI MOVIES PAY 20 STAR GOLD 2 139 HINDI MOVIES PAY 21 ZEE BOLLYWOOD 140 HINDI MOVIES PAY 22 MAX 2 141 HINDI MOVIES PAY 23 ZEE ACTION 142 HINDI MOVIES PAY 24 SONY WAH 143 HINDI MOVIES PAY 25 COLORS CINEPLEX 144 HINDI MOVIES PAY 26 UTV MOVIES 145 HINDI MOVIES PAY 27 UTV ACTION 146 HINDI MOVIES PAY 28 ZEE CLASSIC 147 HINDI MOVIES PAY 29 ZEE ANMOL CINEMA 148 HINDI MOVIES PAY 30 STAR GOLD SELECT 149 HINDI MOVIES PAY 31 STAR UTSAV MOVIES 150 HINDI MOVIES PAY 32 RISHTEY CINEPLEX 151 HINDI MOVIES PAY 33 MTV 175 HINDI MUSIC PAY 34 ZING 178 HINDI MUSIC PAY 35 MTV BEATS 179 HINDI MUSIC PAY 36 9X M 181 HINDI MUSIC PAY 37 CNBC AWAAZ 201 HINDI NEWS PAY 38 ZEE BUSINESS 202 HINDI NEWS PAY 39 INDIA TODAY 203 HINDI NEWS PAY 40 NDTV INDIA 204 HINDI NEWS PAY 41 NEWS18 INDIA 205 HINDI NEWS PAY 42 AAJ TAK 206 HINDI NEWS PAY 43 ZEE NEWS 207 HINDI NEWS PAY 44 ZEE HINDUSTAN 209 HINDI NEWS PAY 45 TEZ 210 HINDI NEWS PAY 46 STAR JALSHA 251 BENGALI GEC PAY 47 ZEE BANGLA 252 BENGALI GEC PAY 48 COLORS -

Declaration Under Section 4 (4) of the Telecommunication (Broadcasting and Cable) Services Interconnection (Addressable System) Regulation, 2017 (No
Version 1.0/2019 Declaration Under Section 4 (4) of The Telecommunication (Broadcasting and Cable) Services Interconnection (Addressable System) Regulation, 2017 (No. 1 of 2017) 4(4)a: Target Market Distribution Network Location States/Parts of State covered as "Coverage Area" Bangalore Karnataka Bhopal Madhya Pradesh Delhi Delhi; Haryana; Rajasthan and Uttar Pradesh Hyderabad Telangana Kolkata Odisha; West Bengal; Sikkim Mumbai Maharashtra 4(4)b: Total Channel carrying capacity Distribution Network Location Capacity in SD Terms Bangalore 506 Bhopal 358 Delhi 384 Hyderabad 456 Kolkata 472 Mumbai 447 Kindly Note: 1. Local Channels considered as 1 SD; 2. Consideration in SD Terms is clarified as 1 SD = 1 SD; 1 HD = 2 SD; 3. Number of channels will vary within the area serviced by a distribution network location depending upon available Bandwidth capacity. 4(4)c: List of channels available on network List attached below in Annexure I 4(4)d: Number of channels which signals of television channels have been requested by the distributor from broadcasters and the interconnection agreements signed Nil Page 1 of 37 Version 1.0/2019 4(4)e: Spare channels capacity available on the network for the purpose of carrying signals of television channels Distribution Network Location Spare Channel Capacity in SD Terms Bangalore Nil Bhopal Nil Delhi Nil Hyderabad Nil Kolkata Nil Mumbai Nil 4(4)f: List of channels, in chronological order, for which requests have been received from broadcasters for distribution of their channels, the interconnection agreements -

Genre Channel Name Channel No Hindi Entertainment Star Bharat 114 Hindi Entertainment Investigation Discovery HD 136 Hindi Enter
Genre Channel Name Channel No Hindi Entertainment Star Bharat 114 Hindi Entertainment Investigation Discovery HD 136 Hindi Entertainment Big Magic 124 Hindi Entertainment Colors Rishtey 129 Hindi Entertainment STAR UTSAV 131 Hindi Entertainment Sony Pal 132 Hindi Entertainment Epic 138 Hindi Entertainment Zee Anmol 140 Hindi Entertainment DD National 148 Hindi Entertainment DD INDIA 150 Hindi Entertainment DD BHARATI 151 Infotainment DD KISAN 152 Hindi Movies Star Gold HD 206 Hindi Movies Zee Action 216 Hindi Movies Colors Cineplex 219 Hindi Movies Sony Wah 224 Hindi Movies STAR UTSAV MOVIES 225 Hindi Zee Anmol Cinema 228 Sports Star Sports 1 Hindi HD 282 Sports DD SPORTS 298 Hindi News ZEE NEWS 311 Hindi News AAJ TAK HD 314 Hindi News AAJ TAK 313 Hindi News NDTV India 317 Hindi News News18 India 318 Hindi News Zee Hindustan 319 Hindi News Tez 326 Hindi News ZEE BUSINESS 331 Hindi News News18 Rajasthan 335 Hindi News Zee Rajasthan News 336 Hindi News News18 UP UK 337 Hindi News News18 MP Chhattisgarh 341 Hindi News Zee MPCG 343 Hindi News Zee UP UK 351 Hindi News DD UP 400 Hindi News DD NEWS 401 Hindi News DD LOK SABHA 402 Hindi News DD RAJYA SABHA 403 Hindi News DD RAJASTHAN 404 Hindi News DD MP 405 Infotainment Gyan Darshan 442 Kids CARTOON NETWORK 449 Kids Pogo 451 Music MTV Beats 482 Music ETC 487 Music SONY MIX 491 Music Zing 501 Marathi DD SAHYADRI 548 Punjabi ZEE PUNJABI 562 Hindi News News18 Punjab Haryana Himachal 566 Punjabi DD PUNJABI 572 Gujrati DD Girnar 589 Oriya DD ORIYA 617 Urdu Zee Salaam 622 Urdu News18 Urdu 625 Urdu -
Tata Sky Channel List
Sr. No. Channel Name HD/SD Genre EPG No. FTA/Pay MRP MRP + Tax NCF Counter 1 DD National SD Hindi Entertainment 114 FTA FTA FTA 0 2 Star Plus HD HD Hindi Entertainment 115 Pay ₹ 19.00 ₹ 22.42 2 3 Star Plus SD Hindi Entertainment 117 Pay ₹ 19.00 ₹ 22.42 1 4 Star Bharat HD HD Hindi Entertainment 121 Pay ₹ 19.00 ₹ 22.42 2 5 Star Bharat SD Hindi Entertainment 122 Pay ₹ 10.00 ₹ 11.80 1 6 SET HD HD Hindi Entertainment 128 Pay ₹ 19.00 ₹ 22.42 2 7 SET SD Hindi Entertainment 130 Pay ₹ 19.00 ₹ 22.42 1 8 Sony SAB HD HD Hindi Entertainment 132 Pay ₹ 19.00 ₹ 22.42 2 9 Sony SAB SD Hindi Entertainment 134 Pay ₹ 19.00 ₹ 22.42 1 10 &TV HD HD Hindi Entertainment 137 Pay ₹ 19.00 ₹ 22.42 2 11 &TV SD Hindi Entertainment 139 Pay ₹ 12.00 ₹ 14.16 1 12 Zee TV HD HD Hindi Entertainment 141 Pay ₹ 19.00 ₹ 22.42 2 13 Zee TV SD Hindi Entertainment 143 Pay ₹ 19.00 ₹ 22.42 1 14 Colors HD HD Hindi Entertainment 147 Pay ₹ 19.00 ₹ 22.42 2 15 Colors SD Hindi Entertainment 149 Pay ₹ 19.00 ₹ 22.42 1 16 UTV Bindass SD Hindi Entertainment 153 Pay ₹ 1.00 ₹ 1.18 1 17 Investigation Discovery SD Hindi Entertainment 155 Pay ₹ 1.00 ₹ 1.18 1 18 Naaptol SD Shopping 156 FTA FTA FTA 0 19 Ezmall SD Others 158 FTA FTA FTA 0 20 Star Utsav SD Hindi Entertainment 171 Pay ₹ 1.00 ₹ 1.18 1 21 Zee Anmol SD Hindi Entertainment 172 Pay ₹ 0.10 ₹ 0.12 1 22 Colors Rishtey SD Hindi Entertainment 173 Pay ₹ 1.00 ₹ 1.18 1 23 Sony Pal SD Hindi Entertainment 174 Pay ₹ 1.00 ₹ 1.18 1 24 The Q India SD Hindi Entertainment 175 FTA FTA FTA 0 25 Big Magic SD Hindi Entertainment 176 Pay ₹ 0.10 ₹ 0.12 1 26 Dangal -

List of Bouquets of FTA Basic Service Tier
List of Bouquets of FTA Basic Service Tier BST North Channel Genre DD7 Bangla Bangla Aakash aath Bangla Dhoom Music Bangla News Time Bangla Sangeet Bangla Bangla R Plus Bangla ABP Ananda Bangla DD Bihar Bihar Sangeet Bhojpuri Bihar Dangal TV Bihar Bhojpuri Cinema Bihar Dabang Bihar Aastha Devotional Aastha Bhajan Devotional Arihant TV Devotional Divya TV Devotional GOD TV Devotional Ishwar TV Devotional Mahavira Devotional Peace of Mind Devotional Sanskar Devotional Satsang Devotional Vedic Devotional Sadhna Bhakti Devotional Shubh TV Devotional India Ahead Eng News Republic TV Eng News DD Girnar Gujarati TV9 Gujarati Gujarati GS TV Gujarati Sandesh News Gujarati ABP Asmita Gujarati DD India Hindi Gec DD Bharati Hindi Gec DD National Hindi Gec Big Magic Hindi Gec Box Cinema Hindi Movie Maha Movie Hindi Movies WOW Cinema Hindi Movies Cinema TV Hindi Movies Manoranjan Movies Hindi Movies Manoranjan TV Hindi Movies Housefull Movies Hindi Movies B4U Movies Hindi Movies Sky Star Hindi Movies Enterr10 Hindi Movies Movie House Hindi Movies DD9 Chandana (Kannada) Kannada DD Kashir Kashmir DD Loksabha Hindi News DD Rajyasabha Hindi News DD News Hindi News Aaj Tak Hindi News ABP news Hindi News Sadhana Plus Hindi News India News Hindi News India tv Hindi News News Nation Hindi News News 24 Hindi News Zee Hindustan Hindi News Zee News Hindi News Republic Bharat Hindi News DD Kisan Infotainment Digishala Infotainment CGTN International France 24 International Russia Today International Home shop 18 Lifestyle/Fashion NT 1 Lifestyle/Fashion Divyarishi -

LIST of MEDIA RIGHTS VIOLATIONS by JOURNALIST SAFETY INDICATES (JSIS), MAY 2018 to APRIL 2019 the Media Violations Are Categorised by the Journalist Safety Indicators
74 IFJ PRESS FREEDOM REPORT 2018–2019 LIST OF MEDIA RIGHTS VIOLATIONS BY JOURNALIST SAFETY INDICATES (JSIS), MAY 2018 TO APRIL 2019 The media violations are categorised by the Journalist Safety Indicators. Other notable incidents are media violations recorded by the IFJ in its violation mapping. *Other notable incidents are media violations recorded by the IFJ. These are violations that fall outside the JSIs and are included in IFJ mapping on the South Asia Media Solidarity Network (SAMSN) Hub - samsn.ifj.org Afghanistan, was killed in an attack on the Sayeed Ali ina Zafari, political programs operator police chief of Kandahar, General Abdul Raziq. on Wolesi Jerga TV; and a Wolesi Jerga TV driver AFGHANISTAN The Taliban-claimed attack took place in the were entering the MOFA road for an interview in governor’s compound during a high-level official Zanbaq square when they were confronted by a JOURNALIST KILLINGS: 12 (Journalists: 5, meeting. Angar, along with others, was killed in policeman. Media staff: 7. Male: 12, Female: 0) the cross-fire. THREATS AGAINST THE LIVES OF June 5, 2018: Takhar JOURNALISTS: 8 December 4, 2018: Nangarhar Milli TV Takhar province reporter Merajuddin OTHER THREATS TO JOURNALISTS: Engineer Zalmay, director and owner or Enikass Sharifi was beaten up by the head of the None recorded radio and TV stations was kidnapped at 5pm community after a verbal disagreement. NON-FATAL ATTACKS ON JOURNALISTS: during a shopping trip. He was taken by armed 61 (Journalists: 52; Media staff: 9) men who arrived in an armoured vehicle. His June 11, 2018, Ghor THREATS AGAINST MEDIA INSTITUTIONS: 3 driver was shot and taken to hospital where he Saam Weekly Director, Nadeem Ghori, had his ATTACKS ON MEDIA INSTITUTIONS: 3 later died. -

MRP of Pay Channels , Offered by Broadcasters to Subscriber As Reported to TRAI (New Regulatory Framework) (As on 19Th January 2019) S.No Name of the Broadcaster Sl
MRP of pay channels , offered by broadcasters to subscriber as reported to TRAI (New Regulatory Framework) (as on 19th January 2019) S.No Name of the broadcaster Sl. No Name of the channel Channel logo Reported Genre as Reported Language MRP as per Declared as per new Regulatory New SD or HD framework Regulatory Framework 2017 1 ABP News Network Pvt Limited 1 ABP Ananda News Bengali 0.50 SD 2 ABP Majha News Marathi 0.50 SD 2 AETN 18 Media Pvt Limited 3 The History Channel Infotainment Hindi 3.00 SD 4 FY1 TV18 Infotainment English 0.25 SD 5 FY1 TV18 (HD) Infotainment English 1.00 HD 6 Histroy TV 18 HD Infotainment Hindi 7.00 HD 3 Bangla Entertainment Private 7 AATH GEC Bangla 4.00 SD Limited 8 SONY Marathi GEC Marathi 4.00 SD 4 BBC Global News India Private 9 BBC World News News English 1.00 SD Limited 5 Bennett, Coleman & Company 10 Zoom GEC Hindi 0.50 SD Limited S.No Name of the broadcaster Sl. No Name of the channel Channel logo Reported Genre as Reported Language MRP as per Declared as per new Regulatory New SD or HD framework Regulatory Framework 2017 11 Romedy Now Movies English 6.00 SD 12 MN + Movies English 10.00 HD 13 Mirror Now News English/Hindi 2.00 SD 14 ET NOW News English/Hindi 3.00 SD 15 Times Now News English/Hindi 3.00 SD 16 Romedy Now HD Movies English 9.00 HD 17 Movies Now HD Movies English 12.00 HD 18 MNX HD Movies English 9.00 HD 19 MNX Movies English 6.00 SD 20 Times Now HD News English 5.00 HD 6 Celebrities Management Pvt 21 Travel XP HD Lifestyle English 9.00 HD Limited S.No Name of the broadcaster Sl. -

APNA CHOICE HINDI 225 225 ### (Pay Channels + Delhi FTA)
A DELHI / HARYANA /UTTAR PRADESH HATHWAY RECOMMENDED PACK DRP ₹ a (Excluding Tax) APNA CHOICE HINDI 225 225 ### (Pay Channels + Delhi FTA) SD 53 PAY CHANNELS HD 0 TOTAL: 53 LANGUAGE ~ GENRE CHANNEL NAME(S) CHANNEL TYPE ASSAMESE NEWS NEWS18 ASSAM/NE SD ENGLISH MUSIC VH1 SD ENGLISH NEWS CNBC TV18 SD CNN NEWS18 SD ET NOW SD INDIA TODAY SD MIRROR NOW SD NDTV 24X7 SD NDTV PROFIT SD TIMES NOW SD HINDI GEC COLORS SD COLORS RISHTEY SD SONY SD SONY PAL SD SONY SAB SD STAR BHARAT SD STAR PLUS SD STAR UTSAV SD ZOOM SD HINDI MOVIE COLORS CINEPLEX SD MOVIES OK SD SONY MAX SD SONY MAX 2 SD SONY WAH SD STAR GOLD SD STAR UTSAV MOVIES SD HINDI MUSIC MTV SD MTV BEATS SD SONY MIX SD HINDI NEWS AAJ TAK SD CNBC AWAAZ SD NDTV INDIA SD NEWS18 BR/JH SD NEWS18 INDIA SD NEWS18 MPCG SD NEWS18 RAJASTHAN SD NEWS18 UP/UK SD TEZ SD INFOTAINMENT FYI TV18 SD Page 1 of 186 HISTORY TV18 SD NAT GEO WILD SD NATIONAL GEOGRAPHIC SD NDTV GOODTIMES SD KIDS NICK SD NICK JR SD SONIC SD SONY YAY SD PUNJABI NEWS NEWS18 PB/HR/HP SD SPORTS STAR SPORTS 1 HINDI SD STAR SPORTS 2 SD STAR SPORTS 3 SD STAR SPORTS FIRST SD URDU NEWS NEWS18 URDU SD HATHWAY RECOMMENDED PACK DRP ₹ a (Excluding Tax) APNA CHOICE HINDI 275 275 ### (Pay Channels + Delhi FTA) SD 85 PAY CHANNELS HD 0 TOTAL: 85 LANGUAGE ~ GENRE CHANNEL NAME(S) CHANNEL TYPE ASSAMESE NEWS NEWS18 ASSAM/NE SD BHOJPURI GEC BIG GANGA SD ENGLISH MUSIC VH1 SD ENGLISH NEWS BBC WORLD NEWS SD CNBC TV18 SD CNN NEWS18 SD ET NOW SD INDIA TODAY SD MIRROR NOW SD NDTV 24X7 SD NDTV PROFIT SD TIMES NOW SD GUJARATI NEWS ZEE 24 KALAK SD HINDI GEC &TV -
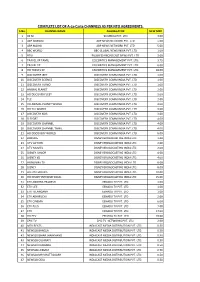
UPDATED LIST of PAY CHANNELS.Xlsx
COMPLETE LIST OF A-La-Carte CHANNELS AS PER NTO AGREEMENTS. S.No. CHANNEL NAME AGGREGATOR NEW MRP 19X M 9X MEDIA PVT. LTD 3.00 2 ABP ANANDA ABP NEWS NETWORK PVT. LTD 5.00 3 ABP MAJHA ABP NEWS NETWORK PVT. LTD 5.00 4 BBC WORLD BBC GLOBAL NEWS INDIA PVT. LTD 1.00 5 BTVI BUSINESS BROADCAST NEWS PVT. LTD 3.00 6 TRAVEL XP TAMIL CELEBRITIES MANAGEMENT PVT. LTD. 3.75 7 TRAVEL XP CELEBRITIES MANAGEMENT PVT. LTD. 6.00 8 HD TRAVEL XP CELEBRITIES MANAGEMENT PVT. LTD. 18.00 9 DISCOVERY JEET DISCOVERY COMM INDIA PVT. LTD 1.00 10 DISCOVERY SCIENCE DISCOVERY COMM INDIA PVT. LTD 1.00 11 DISCOVERY TURBO DISCOVERY COMM INDIA PVT. LTD 1.00 12 ANIMAL PLANET DISCOVERY COMM INDIA PVT. LTD 2.00 13 HD DISCOVERY JEET DISCOVERY COMM INDIA PVT. LTD 2.00 14 TLC DISCOVERY COMM INDIA PVT. LTD 2.00 15 HD ANIMAL PLANET WORLD DISCOVERY COMM INDIA PVT. LTD 3.00 16 HD TLC WORLD DISCOVERY COMM INDIA PVT. LTD 3.00 17 DISCOVERY KIDS DISCOVERY COMM INDIA PVT. LTD 3.00 18 D SPORT DISCOVERY COMM INDIA PVT. LTD 4.00 19 DISCOVERY CHANNEL DISCOVERY COMM INDIA PVT. LTD 4.00 20 DISCOVERY CHANNEL TAMIL DISCOVERY COMM INDIA PVT. LTD 4.00 21 HD DISCOVERY WORLD DISCOVERY COMM INDIA PVT. LTD 6.00 22 BINDASS DISNEY BROADCASTING INDIA LTD. 1.00 23 UTV ACTION DISNEY BROADCASTING INDIA LTD. 2.00 24 UTV MOVIES DISNEY BROADCASTING INDIA LTD. 2.00 25 DISNEY JUNIOR DISNEY BROADCASTING INDIA LTD. -
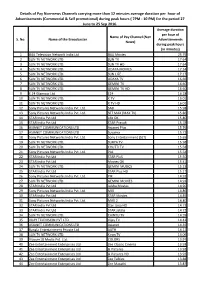
Details of Pay Non-News Channels Carrying More Than 12 Minutes
Details of Pay Non-news Channels carrying more than 12 minutes average duration per hour of Advertisements (Commercial & Self promotional) during peak hours ( 7PM - 10 PM) for the period 27 June to 25 Sep 2016. Average duration per hour of Name of Pay Channel (Non S. No. Name of the Broadcaster Advertisements News) during peak hours (in minutes) 1 B4U Television Network India Ltd B4U Movies 25.79 2 SUN TV NETWORK LTD. SUN TV 17.64 3 SUN TV NETWORK LTD. SUN TV HD 17.64 4 SUN TV NETWORK LTD. UDAYA MOVIES 17.34 5 SUN TV NETWORK LTD. SUN LIFE 17.17 6 SUN TV NETWORK LTD. UDAYA TV 16.66 7 SUN TV NETWORK LTD. GEMINI TV 16.60 8 SUN TV NETWORK LTD. GEMINI TV HD 16.60 9 E 24 Glamour Ltd E24 16.18 10 SUN TV NETWORK LTD. K TV 16.01 11 SUN TV NETWORK LTD. K TV HD 16.01 12 Sony Pictures Networks India Pvt. Ltd. SAB 15.98 13 Sony Pictures Networks India Pvt. Ltd. SET MAX (MAX TV) 15.86 14 STAR India Pvt Ltd Life OK 15.80 15 STAR India Pvt Ltd STAR Pravah 15.78 16 ASIANET COMMUNICATIONS LTD Asianet Plus 15.76 17 ASIANET COMMUNICATIONS LTD Suvarna 15.72 18 Sony Pictures Networks India Pvt. Ltd. Sony Entertainment (SET) 15.65 19 SUN TV NETWORK LTD. SURYA TV 15.58 20 SUN TV NETWORK LTD. CHUTTI TV 15.58 21 Sony Pictures Networks India Pvt. Ltd. PAL 15.54 22 STAR India Pvt Ltd STAR PluS 15.50 23 STAR India Pvt Ltd Movies OK 15.41 24 SUN TV NETWORK LTD. -

Channel List: 1 DD National SD Hindi Entertainment 114 FTA
Channel List: - Channels, EPG numbers and prices are subject to change. - MRP: Maximum Retail Price, per month. DRP (Distributor Retail Price) of all channels is the same as the MRP. - Pack lock-in duration: 1 day Sr. Channel Name HD/SD Genre EPG No. FTA/Pay MRP MRP + No. Tax 1 DD National SD Hindi Entertainment 114 FTA FTA FTA 2 Star Plus HD HD Hindi Entertainment 115 Pay ₹ 19.00 ₹ 22.42 3 Star Plus SD Hindi Entertainment 117 Pay ₹ 19.00 ₹ 22.42 4 Star Bharat HD HD Hindi Entertainment 121 Pay ₹ 19.00 ₹ 22.42 5 Star Bharat SD Hindi Entertainment 122 Pay ₹ 10.00 ₹ 11.80 6 SET HD HD Hindi Entertainment 128 Pay ₹ 19.00 ₹ 22.42 7 SET SD Hindi Entertainment 130 Pay ₹ 19.00 ₹ 22.42 8 Sony SAB HD HD Hindi Entertainment 132 Pay ₹ 19.00 ₹ 22.42 9 Sony SAB SD Hindi Entertainment 134 Pay ₹ 19.00 ₹ 22.42 10 &TV HD HD Hindi Entertainment 137 Pay ₹ 19.00 ₹ 22.42 11 &TV SD Hindi Entertainment 139 Pay ₹ 12.00 ₹ 14.16 12 Zee TV HD HD Hindi Entertainment 141 Pay ₹ 19.00 ₹ 22.42 13 Zee TV SD Hindi Entertainment 143 Pay ₹ 19.00 ₹ 22.42 14 Colors HD HD Hindi Entertainment 147 Pay ₹ 19.00 ₹ 22.42 15 Colors SD Hindi Entertainment 149 Pay ₹ 19.00 ₹ 22.42 16 UTV Bindass SD Hindi Entertainment 153 Pay ₹ 1.00 ₹ 1.18 17 Investigation Discovery SD Hindi Entertainment 155 Pay ₹ 1.00 ₹ 1.18 18 Naaptol SD Shopping 156 FTA FTA FTA 19 Ezmall SD Others 158 FTA FTA FTA 20 Star Utsav SD Hindi Entertainment 171 Pay ₹ 1.00 ₹ 1.18 21 Zee Anmol SD Hindi Entertainment 172 Pay ₹ 0.10 ₹ 0.12 22 Colors Rishtey SD Hindi Entertainment 173 Pay ₹ 1.00 ₹ 1.18 23 Sony Pal SD Hindi Entertainment -

Swagat - Rs.192*
HINDI Swagat - Rs.192* Genre Channels Zee Anmol Star Utsav Star Bharat Sony Pal SAB Rishtey TV Hindi Gec Discovery Jeet DD National DD India DD Bharati Bindass &Tv Zee Bollywood Zee Anmol Cinema Zee Action UTV Movies UTV Action Star Utsav Movies Hindi Movies Sony Wah Sky Star RISHTEY CINEPLEX Movies OK Max 2 B4U Movies &Pictures Sadhana Plus News18 India India News Hindi News DD Rajyasabha DD News DD Loksabha FYI TV18 Infotainment Discovery Turbo Discovery Science • Subject to change • Applicable taxes extra • Network Capacity Fee (NCF) slabs are: o For the first 100 channels - ₹130 + Taxes o For every slab of next 25 channels or less - ▪ ₹20 + taxes if no. of channels is more than 15 ▪ ₹1 per channel + taxes for 15 or less channels Discovery DD Kisan Animal Planet Vedic Satsang Sanskar Peace of Mind Mahavira Devotional Ishwar TV GOD TV Divya TV Arihant TV Aastha Bhajan Aastha TLC Shop CJ1 Lifestyle/Fashion NT 7 Living Foodz Divyarishi Kids Discovery Kids Republic TV Eng News India Ahead Bangla DD7 Bangla Bihar DD Bihar Business News- English BTVi Business News- Hindi Zee Business TV9 Gujarati Gujarati DD Girnar Russia Today International France 24 CGTN Kannada DD9 Chandana (Kannada) Kashmir DD Kashir Malayalam DD4 Malayalam Fakt Marathi Marathi DD10 Sahyadri (Marathi) MP DD MP Zing Music Zee ETC Bollywood Music India North East DD North East • Subject to change • Applicable taxes extra • Network Capacity Fee (NCF) slabs are: o For the first 100 channels - ₹130 + Taxes o For every slab of next 25 channels or less - ▪ ₹20 + taxes if no.