Math 291-3: Intensive Linear Algebra & Multivariable Calculus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Selected Solutions to Assignment #1 (With Corrections)
Math 310 Numerical Analysis, Fall 2010 (Bueler) September 23, 2010 Selected Solutions to Assignment #1 (with corrections) 2. Because the functions are continuous on the given intervals, we show these equations have solutions by checking that the functions have opposite signs at the ends of the given intervals, and then by invoking the Intermediate Value Theorem (IVT). a. f(0:2) = −0:28399 and f(0:3) = 0:0066009. Because f(x) is continuous on [0:2; 0:3], and because f has different signs at the ends of this interval, by the IVT there is a solution c in [0:2; 0:3] so that f(c) = 0. Similarly, for [1:2; 1:3] we see f(1:2) = 0:15483; f(1:3) = −0:13225. And etc. b. Again the function is continuous. For [1; 2] we note f(1) = 1 and f(2) = −0:69315. By the IVT there is a c in (1; 2) so that f(c) = 0. For the interval [e; 4], f(e) = −0:48407 and f(4) = 2:6137. And etc. 3. One of my purposes in assigning these was that you should recall the Extreme Value Theorem. It guarantees that these problems have a solution, and it gives an algorithm for finding it. That is, \search among the critical points and the endpoints." a. The discontinuities of this rational function are where the denominator is zero. But the solutions of x2 − 2x = 0 are at x = 2 and x = 0, so the function is continuous on the interval [0:5; 1] of interest. -

2.4 the Extreme Value Theorem and Some of Its Consequences
2.4 The Extreme Value Theorem and Some of its Consequences The Extreme Value Theorem deals with the question of when we can be sure that for a given function f , (1) the values f (x) don’t get too big or too small, (2) and f takes on both its absolute maximum value and absolute minimum value. We’ll see that it gives another important application of the idea of compactness. 1 / 17 Definition A real-valued function f is called bounded if the following holds: (∃m, M ∈ R)(∀x ∈ Df )[m ≤ f (x) ≤ M]. If in the above definition we only require the existence of M then we say f is upper bounded; and if we only require the existence of m then say that f is lower bounded. 2 / 17 Exercise Phrase boundedness using the terms supremum and infimum, that is, try to complete the sentences “f is upper bounded if and only if ...... ” “f is lower bounded if and only if ...... ” “f is bounded if and only if ...... ” using the words supremum and infimum somehow. 3 / 17 Some examples Exercise Give some examples (in pictures) of functions which illustrates various things: a) A function can be continuous but not bounded. b) A function can be continuous, but might not take on its supremum value, or not take on its infimum value. c) A function can be continuous, and does take on both its supremum value and its infimum value. d) A function can be discontinuous, but bounded. e) A function can be discontinuous on a closed bounded interval, and not take on its supremum or its infimum value. -

Two Fundamental Theorems About the Definite Integral
Two Fundamental Theorems about the Definite Integral These lecture notes develop the theorem Stewart calls The Fundamental Theorem of Calculus in section 5.3. The approach I use is slightly different than that used by Stewart, but is based on the same fundamental ideas. 1 The definite integral Recall that the expression b f(x) dx ∫a is called the definite integral of f(x) over the interval [a,b] and stands for the area underneath the curve y = f(x) over the interval [a,b] (with the understanding that areas above the x-axis are considered positive and the areas beneath the axis are considered negative). In today's lecture I am going to prove an important connection between the definite integral and the derivative and use that connection to compute the definite integral. The result that I am eventually going to prove sits at the end of a chain of earlier definitions and intermediate results. 2 Some important facts about continuous functions The first intermediate result we are going to have to prove along the way depends on some definitions and theorems concerning continuous functions. Here are those definitions and theorems. The definition of continuity A function f(x) is continuous at a point x = a if the following hold 1. f(a) exists 2. lim f(x) exists xœa 3. lim f(x) = f(a) xœa 1 A function f(x) is continuous in an interval [a,b] if it is continuous at every point in that interval. The extreme value theorem Let f(x) be a continuous function in an interval [a,b]. -
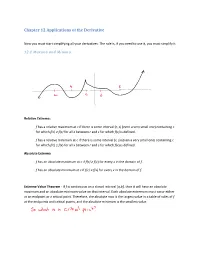
Chapter 12 Applications of the Derivative
Chapter 12 Applications of the Derivative Now you must start simplifying all your derivatives. The rule is, if you need to use it, you must simplify it. 12.1 Maxima and Minima Relative Extrema: f has a relative maximum at c if there is some interval (r, s) (even a very small one) containing c for which f(c) ≥ f(x) for all x between r and s for which f(x) is defined. f has a relative minimum at c if there is some interval (r, s) (even a very small one) containing c for which f(c) ≤ f(x) for all x between r and s for which f(x) is defined. Absolute Extrema f has an absolute maximum at c if f(c) ≥ f(x) for every x in the domain of f. f has an absolute minimum at c if f(c) ≤ f(x) for every x in the domain of f. Extreme Value Theorem - If f is continuous on a closed interval [a,b], then it will have an absolute maximum and an absolute minimum value on that interval. Each absolute extremum must occur either at an endpoint or a critical point. Therefore, the absolute max is the largest value in a table of vales of f at the endpoints and critical points, and the absolute minimum is the smallest value. Locating Candidates for Relative Extrema If f is a real valued function, then its relative extrema occur among the following types of points, collectively called critical points: 1. Stationary Points: f has a stationary point at x if x is in the domain of f and f′(x) = 0. -

0.999… = 1 an Infinitesimal Explanation Bryan Dawson
0 1 2 0.9999999999999999 0.999… = 1 An Infinitesimal Explanation Bryan Dawson know the proofs, but I still don’t What exactly does that mean? Just as real num- believe it.” Those words were uttered bers have decimal expansions, with one digit for each to me by a very good undergraduate integer power of 10, so do hyperreal numbers. But the mathematics major regarding hyperreals contain “infinite integers,” so there are digits This fact is possibly the most-argued- representing not just (the 237th digit past “Iabout result of arithmetic, one that can evoke great the decimal point) and (the 12,598th digit), passion. But why? but also (the Yth digit past the decimal point), According to Robert Ely [2] (see also Tall and where is a negative infinite hyperreal integer. Vinner [4]), the answer for some students lies in their We have four 0s followed by a 1 in intuition about the infinitely small: While they may the fifth decimal place, and also where understand that the difference between and 1 is represents zeros, followed by a 1 in the Yth less than any positive real number, they still perceive a decimal place. (Since we’ll see later that not all infinite nonzero but infinitely small difference—an infinitesimal hyperreal integers are equal, a more precise, but also difference—between the two. And it’s not just uglier, notation would be students; most professional mathematicians have not or formally studied infinitesimals and their larger setting, the hyperreal numbers, and as a result sometimes Confused? Perhaps a little background information wonder . -

Understanding Student Use of Differentials in Physics Integration Problems
PHYSICAL REVIEW SPECIAL TOPICS - PHYSICS EDUCATION RESEARCH 9, 020108 (2013) Understanding student use of differentials in physics integration problems Dehui Hu and N. Sanjay Rebello* Department of Physics, 116 Cardwell Hall, Kansas State University, Manhattan, Kansas 66506-2601, USA (Received 22 January 2013; published 26 July 2013) This study focuses on students’ use of the mathematical concept of differentials in physics problem solving. For instance, in electrostatics, students need to set up an integral to find the electric field due to a charged bar, an activity that involves the application of mathematical differentials (e.g., dr, dq). In this paper we aim to explore students’ reasoning about the differential concept in physics problems. We conducted group teaching or learning interviews with 13 engineering students enrolled in a second- semester calculus-based physics course. We amalgamated two frameworks—the resources framework and the conceptual metaphor framework—to analyze students’ reasoning about differential concept. Categorizing the mathematical resources involved in students’ mathematical thinking in physics provides us deeper insights into how students use mathematics in physics. Identifying the conceptual metaphors in students’ discourse illustrates the role of concrete experiential notions in students’ construction of mathematical reasoning. These two frameworks serve different purposes, and we illustrate how they can be pieced together to provide a better understanding of students’ mathematical thinking in physics. DOI: 10.1103/PhysRevSTPER.9.020108 PACS numbers: 01.40.Àd mathematical symbols [3]. For instance, mathematicians I. INTRODUCTION often use x; y asR variables and the integrals are often written Mathematical integration is widely used in many intro- in the form fðxÞdx, whereas in physics the variables ductory and upper-division physics courses. -

Leonhard Euler: His Life, the Man, and His Works∗
SIAM REVIEW c 2008 Walter Gautschi Vol. 50, No. 1, pp. 3–33 Leonhard Euler: His Life, the Man, and His Works∗ Walter Gautschi† Abstract. On the occasion of the 300th anniversary (on April 15, 2007) of Euler’s birth, an attempt is made to bring Euler’s genius to the attention of a broad segment of the educated public. The three stations of his life—Basel, St. Petersburg, andBerlin—are sketchedandthe principal works identified in more or less chronological order. To convey a flavor of his work andits impact on modernscience, a few of Euler’s memorable contributions are selected anddiscussedinmore detail. Remarks on Euler’s personality, intellect, andcraftsmanship roundout the presentation. Key words. LeonhardEuler, sketch of Euler’s life, works, andpersonality AMS subject classification. 01A50 DOI. 10.1137/070702710 Seh ich die Werke der Meister an, So sehe ich, was sie getan; Betracht ich meine Siebensachen, Seh ich, was ich h¨att sollen machen. –Goethe, Weimar 1814/1815 1. Introduction. It is a virtually impossible task to do justice, in a short span of time and space, to the great genius of Leonhard Euler. All we can do, in this lecture, is to bring across some glimpses of Euler’s incredibly voluminous and diverse work, which today fills 74 massive volumes of the Opera omnia (with two more to come). Nine additional volumes of correspondence are planned and have already appeared in part, and about seven volumes of notebooks and diaries still await editing! We begin in section 2 with a brief outline of Euler’s life, going through the three stations of his life: Basel, St. -

Calculus Terminology
AP Calculus BC Calculus Terminology Absolute Convergence Asymptote Continued Sum Absolute Maximum Average Rate of Change Continuous Function Absolute Minimum Average Value of a Function Continuously Differentiable Function Absolutely Convergent Axis of Rotation Converge Acceleration Boundary Value Problem Converge Absolutely Alternating Series Bounded Function Converge Conditionally Alternating Series Remainder Bounded Sequence Convergence Tests Alternating Series Test Bounds of Integration Convergent Sequence Analytic Methods Calculus Convergent Series Annulus Cartesian Form Critical Number Antiderivative of a Function Cavalieri’s Principle Critical Point Approximation by Differentials Center of Mass Formula Critical Value Arc Length of a Curve Centroid Curly d Area below a Curve Chain Rule Curve Area between Curves Comparison Test Curve Sketching Area of an Ellipse Concave Cusp Area of a Parabolic Segment Concave Down Cylindrical Shell Method Area under a Curve Concave Up Decreasing Function Area Using Parametric Equations Conditional Convergence Definite Integral Area Using Polar Coordinates Constant Term Definite Integral Rules Degenerate Divergent Series Function Operations Del Operator e Fundamental Theorem of Calculus Deleted Neighborhood Ellipsoid GLB Derivative End Behavior Global Maximum Derivative of a Power Series Essential Discontinuity Global Minimum Derivative Rules Explicit Differentiation Golden Spiral Difference Quotient Explicit Function Graphic Methods Differentiable Exponential Decay Greatest Lower Bound Differential -
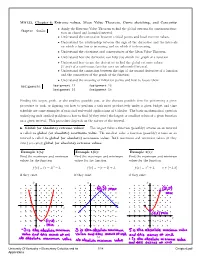
MA123, Chapter 6: Extreme Values, Mean Value
MA123, Chapter 6: Extreme values, Mean Value Theorem, Curve sketching, and Concavity • Apply the Extreme Value Theorem to find the global extrema for continuous func- Chapter Goals: tion on closed and bounded interval. • Understand the connection between critical points and localextremevalues. • Understand the relationship between the sign of the derivative and the intervals on which a function is increasing and on which it is decreasing. • Understand the statement and consequences of the Mean Value Theorem. • Understand how the derivative can help you sketch the graph ofafunction. • Understand how to use the derivative to find the global extremevalues (if any) of a continuous function over an unbounded interval. • Understand the connection between the sign of the second derivative of a function and the concavities of the graph of the function. • Understand the meaning of inflection points and how to locate them. Assignments: Assignment 12 Assignment 13 Assignment 14 Assignment 15 Finding the largest profit, or the smallest possible cost, or the shortest possible time for performing a given procedure or task, or figuring out how to perform a task most productively under a given budget and time schedule are some examples of practical real-world applications of Calculus. The basic mathematical question underlying such applied problems is how to find (if they exist)thelargestorsmallestvaluesofagivenfunction on a given interval. This procedure depends on the nature of the interval. ! Global (or absolute) extreme values: The largest value a function (possibly) attains on an interval is called its global (or absolute) maximum value.Thesmallestvalueafunction(possibly)attainsonan interval is called its global (or absolute) minimum value.Bothmaximumandminimumvalues(ifthey exist) are called global (or absolute) extreme values. -

OPTIMIZATION 1. Optimization and Derivatives
4: OPTIMIZATION STEVEN HEILMAN 1. Optimization and Derivatives Nothing takes place in the world whose meaning is not that of some maximum or minimum. Leonhard Euler At this stage, Euler's statement may seem to exaggerate, but perhaps the Exercises in Section 4 and the Problems in Section 5 may reinforce his views. These problems and exercises show that many physical phenomena can be explained by maximizing or minimizing some function. We therefore begin by discussing how to find the maxima and minima of a function. In Section 2, we will see that the first and second derivatives of a function play a crucial role in identifying maxima and minima, and also in drawing functions. Finally, in Section 3, we will briefly describe a way to find the zeros of a general function. This procedure is known as Newton's Method. As we already see in Algorithm 1.2(1) below, finding the zeros of a general function is crucial within optimization. We now begin our discussion of optimization. We first recall the Extreme Value Theorem from the last set of notes. In Algorithm 1.2, we will then describe a general procedure for optimizing a function. Theorem 1.1. (Extreme Value Theorem) Let a < b. Let f :[a; b] ! R be a continuous function. Then f achieves its minimum and maximum values. More specifically, there exist c; d 2 [a; b] such that: for all x 2 [a; b], f(c) ≤ f(x) ≤ f(d). Algorithm 1.2. A procedure for finding the extreme values of a differentiable function f :[a; b] ! R. -
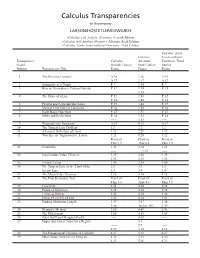
Calc. Transp. Correl. Chart
Calculus Transparencies to Accompany LARSON/HOSTETLER/EDWARDS •Calculus with Analytic Geometry, Seventh Edition •Calculus with Analytic Geometry, Alternate Sixth Edition •Calculus: Early Transcendental Functions, Third Edition Calculus: Early Calculus, Transcendental Transparency Calculus, Alternate Functions, Third Figure Seventh Edition Sixth Edition Edition Number Transparency Title Figure Figure Figure 1The Distance Formula A.16 1.16 A.16 A.17 1.17 A.17 2 Symmetry of a Graph P. 7 1.30 P. 7 3 Rise in Atmospheric Carbon Dioxide P. 11 1.34 P. 11 ----- 1.35 ----- 4The Slope of a Line P. 12 1.38 P. 12 P. 14 1.40 P. 14 5Parallel and Perpendicular Lines P. 19 1.44 P. 19 6Vertical Line Test for Functions P. 26 1.50 P. 26 7 Eight Basic Functions P. 27 1.51 P. 27 8 Shifts and Reflections P. 28 1.52 P. 28 ----- 1.53 ----- 9Trigonometric Functions A.37 8.13 A.37 10 The Tangent Line Problem 1.2 2.2 1.2 11 A Formal Definition of Limit 1.12 2.29 1.12 12 Two Special Trigonometric Limits 1.22 8.20 1.22 Proof of Proof of Proof of Thm 1.9 Thm 8.2 Thm 1.9 13 Continuity 1.25 2.14 1.25 ----- 2.15 ----- 14 Intermediate Value Theorem 1.35 2.20 1.35 1.36 2.21 1.36 15 Infinite Limits 1.40 2.24 1.40 16 The Tangent Line as the Limit of the 2.3 3.3 2.3 Secant Line 2.4 3.4 2.4 17 The Mean Value Theorem 3.12 4.10 3.12 18 The First Derivative Test Proof of Proof of Proof of Thm 3.6 Thm 4.6 Thm 3.6 19 Concavity 3.24 4.20 3.24 20 Points of Inflection 3.28 4.24 3.28 21 Limits at Infinity 3.34 4.30 3.34 22 Oxygen Level in a Pond 3.41 4.34 3.41 23 Finding Minimum Length 3.57 4.47 3.58 3.58 Tech p. -

Infinitesimal Calculus
Infinitesimal Calculus Δy ΔxΔy and “cannot stand” Δx • Derivative of the sum/difference of two functions (x + Δx) ± (y + Δy) = (x + y) + Δx + Δy ∴ we have a change of Δx + Δy. • Derivative of the product of two functions (x + Δx)(y + Δy) = xy + Δxy + xΔy + ΔxΔy ∴ we have a change of Δxy + xΔy. • Derivative of the product of three functions (x + Δx)(y + Δy)(z + Δz) = xyz + Δxyz + xΔyz + xyΔz + xΔyΔz + ΔxΔyz + xΔyΔz + ΔxΔyΔ ∴ we have a change of Δxyz + xΔyz + xyΔz. • Derivative of the quotient of three functions x Let u = . Then by the product rule above, yu = x yields y uΔy + yΔu = Δx. Substituting for u its value, we have xΔy Δxy − xΔy + yΔu = Δx. Finding the value of Δu , we have y y2 • Derivative of a power function (and the “chain rule”) Let y = x m . ∴ y = x ⋅ x ⋅ x ⋅...⋅ x (m times). By a generalization of the product rule, Δy = (xm−1Δx)(x m−1Δx)(x m−1Δx)...⋅ (xm −1Δx) m times. ∴ we have Δy = mx m−1Δx. • Derivative of the logarithmic function Let y = xn , n being constant. Then log y = nlog x. Differentiating y = xn , we have dy dy dy y y dy = nxn−1dx, or n = = = , since xn−1 = . Again, whatever n−1 y dx x dx dx x x x the differentials of log x and log y are, we have d(log y) = n ⋅ d(log x), or d(log y) n = . Placing these values of n equal to each other, we obtain d(log x) dy d(log y) y dy = .