Mapping the Paraphrase Database to Wordnet
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Robust Ontology Acquisition from Machine-Readable Dictionaries
Robust Ontology Acquisition from Machine-Readable Dictionaries Eric Nichols Francis Bond Daniel Flickinger Nara Inst. of Science and Technology NTT Communication Science Labs CSLI Nara, Japan Nippon Telegraph and Telephone Co. Stanford University [email protected] Keihanna, Japan California, U.S.A. [email protected] [email protected] Abstract Our basic approach is to parse dictionary definition sen- tences with multiple shallow and deep processors, generating In this paper, we outline the development of a semantic representations of varying specificity. The seman- system that automatically constructs ontologies by tic representation used is robust minimal recursion semantics extracting knowledge from dictionary definition (RMRS: Section 2.2). We then extract ontological relations sentences using Robust Minimal Recursion Se- using the most informative semantic representation for each mantics (RMRS), a semantic formalism that per- definition sentence. mits underspecification. We show that by com- In this paper we discuss the construction of an ontology for bining deep and shallow parsing resources through Japanese using the the Japanese Semantic Database Lexeed the common formalism of RMRS, we can extract [Kasahara et al., 2004]. The deep parser uses the Japanese ontological relations in greater quality and quan- Grammar JACY [Siegel and Bender, 2002] and the shallow tity. Our approach also has the advantages of re- parser is based on the morphological analyzer ChaSen. quiring a very small amount of rules and being We carried out two evaluations. The first gives an automat- easily adaptable to any language with RMRS re- ically obtainable measure by comparing the extracted onto- sources. logical relations by verifying the existence of the relations in exisiting WordNet [Fellbaum, 1998]and GoiTaikei [Ikehara 1 Introduction et al., 1997] ontologies. -

Lemma Selection in Domain Specific Computational Lexica – Some Specific Problems
Lemma selection in domain specific computational lexica – some specific problems Sussi Olsen Center for Sprogteknologi Njalsgade 80, DK-2300, Denmark Phone: +45 35 32 90 90 Fax: +45 35 32 90 89 e-mail: [email protected] URL: www.cst.dk Abstract This paper describes the lemma selection process of a Danish computational lexicon, the STO project, for domain specific language and focuses on some specific problems encountered during the lemma selection process. After a short introduction to the STO project and an explanation of why the lemmas are selected from a corpus and not chosen from existing dictionaries, the lemma selection process for domain specific language is described in detail. The purpose is to make the lemma selection process as automatic as possible but a manual examination of the final candidate lemma lists is inevitable. The lemmas found in the corpora are compared to a list of lemmas of general language, sorting out lemmas already encoded in the database. Words that have already been encoded as general language words but that are also found with another meaning and perhaps another syntactic behaviour in a specific domain should be kept on a list and the paper describes how this is done. The recognition of borrowed words the spelling of which have not been established constitutes a big problem to the automatic lemma selection process. The paper gives some examples of this problem and describes how the STO project tries to solve it. The selection of the specific domains is based on the 1. Introduction potential future applications and at present the following The Danish STO project, SprogTeknologisk Ordbase, domains have been selected, while – at least – one is still (i.e. -

Etytree: a Graphical and Interactive Etymology Dictionary Based on Wiktionary
Etytree: A Graphical and Interactive Etymology Dictionary Based on Wiktionary Ester Pantaleo Vito Walter Anelli Wikimedia Foundation grantee Politecnico di Bari Italy Italy [email protected] [email protected] Tommaso Di Noia Gilles Sérasset Politecnico di Bari Univ. Grenoble Alpes, CNRS Italy Grenoble INP, LIG, F-38000 Grenoble, France [email protected] [email protected] ABSTRACT a new method1 that parses Etymology, Derived terms, De- We present etytree (from etymology + family tree): a scendants sections, the namespace for Reconstructed Terms, new on-line multilingual tool to extract and visualize et- and the etymtree template in Wiktionary. ymological relationships between words from the English With etytree, a RDF (Resource Description Framework) Wiktionary. A first version of etytree is available at http: lexical database of etymological relationships collecting all //tools.wmflabs.org/etytree/. the extracted relationships and lexical data attached to lex- With etytree users can search a word and interactively emes has also been released. The database consists of triples explore etymologically related words (ancestors, descendants, or data entities composed of subject-predicate-object where cognates) in many languages using a graphical interface. a possible statement can be (for example) a triple with a lex- The data is synchronised with the English Wiktionary dump eme as subject, a lexeme as object, and\derivesFrom"or\et- at every new release, and can be queried via SPARQL from a ymologicallyEquivalentTo" as predicate. The RDF database Virtuoso endpoint. has been exposed via a SPARQL endpoint and can be queried Etytree is the first graphical etymology dictionary, which at http://etytree-virtuoso.wmflabs.org/sparql. -

Illustrative Examples in a Bilingual Decoding Dictionary: an (Un)Necessary Component
http://lexikos.journals.ac.za Illustrative Examples in a Bilingual Decoding Dictionary: An (Un)necessary Component?* Alenka Vrbinc ([email protected]), Faculty of Economics, University of Ljubljana, Ljubljana, Slovenia and Marjeta Vrbinc ([email protected]), Faculty of Arts, Department of English, University of Ljubljana, Ljubljana, Slovenia Abstract: The article discusses the principles underlying the inclusion of illustrative examples in a decoding English–Slovene dictionary. The inclusion of examples in decoding bilingual diction- aries can be justified by taking into account the semantic and grammatical differences between the source and the target languages. Among the differences between the dictionary equivalent, which represents the most frequent translation of the lemma in a particular sense, and the translation of the lemma in the illustrative example, the following should be highlighted: the differences in the part of speech; context-dependent translation of the lemma in the example; the one-word equiva- lent of the example; zero equivalence; and idiomatic translation of the example. All these differ- ences are addressed and discussed in detail, together with the sample entries taken from a bilingual English–Slovene dictionary. The aim is to develop criteria for the selection of illustrative examples whose purpose is to supplement dictionary equivalent(s) in the grammatical, lexical, semantic and contextual senses. Apart from that, arguments for translating examples in the target language are put forward. The most important finding is that examples included in a bilingual decoding diction- ary should be chosen carefully and should be translated into the target language, since lexical as well as grammatical changes in the translation of examples demand not only a high level of knowl- edge of both languages, but also translation abilities. -

And User-Related Definitions in Online Dictionaries
S. Nielsen Centre for Lexicography, Aarhus University, Denmark FUNCTION- AND USER-RELATED DEFINITIONS IN ONLINE DICTIONARIES 1. Introduction Definitions play an important part in the use and making of dictionaries. A study of the existing literature reveals that the contributions primarily concern printed dictionaries and show that definitions are static in that only one definition should be provided for each sense of a lemma or entry word (see e.g. Jackson, 2002, 86-100; Landau, 2001, 153-189). However, online dictionaries provide lexicographers with the option of taking a more flexible and dynamic approach to lexicographic definitions in an attempt to give the best possible help to users. Online dictionaries vary in size and shape. Some contain many data, some contain few data, some are intended to be used by adults, and some are intended to be used by children. These dictionaries contain data that reflect the differences between these groups of users, not only between general competences of children and adults but also between various competences among adults. The main distinction is between general and specialised dictionaries because their intended users belong to different types of users based on user competences and user needs. Even though lexicographers are aware of this distinction, “surprisingly little has been written about the relationship between the definition and the needs and skills of those who will use it” (Atkins/Rundell, 2008, 407). Most relevant contributions addressing definitions and user competences concern specialised dictionaries, but there are no reasons why the principles discussed should not be adopted by lexicographers at large (Bergenholtz/Kauffman, 1997; Bergenholtz/Nielsen, 2002). -

From Monolingual to Bilingual Dictionary: the Case of Semi-Automated Lexicography on the Example of Estonian–Finnish Dictionary
From Monolingual to Bilingual Dictionary: The Case of Semi-automated Lexicography on the Example of Estonian–Finnish Dictionary Margit Langemets1, Indrek Hein1, Tarja Heinonen2, Kristina Koppel1, Ülle Viks1 1 Institute of the Estonian Language, Roosikrantsi 6, 10119 Tallinn, Estonia 2 Institute for the Languages of Finland, Hakaniemenranta 6, 00530 Helsinki, Finland E-mail: [email protected], [email protected], [email protected], [email protected], [email protected] Abstract We describe the semi-automated compilation of the bilingual Estonian–Finnish online dictionary. The compilation process involves different stages: (a) reusing and combining data from two different databases: the monolingual general dictionary of Estonian and the opposite bilingual dictionary (Finnish–Estonian); (b) adjusting the compilation of the entries against time; (c) bilingualizing the monolingual dictionary; (d) deciding about the directionality of the dictionary; (e) searching ways for presenting typical/good L2 usage examples for both languages; (f) achieving the understanding about the necessity of linking of different lexical resources. The lexicographers’ tasks are to edit the translation equivalent candidates (selecting and reordering) and to decide whether or not to translate the existing usage examples, i.e. is the translation justified for being too difficult for the user. The project started in 2016 and will last for 18 months due to the unpostponable date: the dictionary is meant to celebrate the 100th anniversary of both states (Finland in December 2017, Estonia in February 2018). Keywords: bilingual lexicography; corpus linguistics; usage examples; GDEX; Estonian; Finnish 1. Background The idea of compiling the new Estonian–Finnish dictionary is about 15 years old: it first arose in 2003, after the successful publication of the voluminous Finnish–Estonian dictionary, a project which benefitted from necessary and sufficient financing, adequate time (5 years) and staff (7 lexicographers), and effective management. -

A Framework for Understanding the Role of Morphology in Universal Dependency Parsing
A Framework for Understanding the Role of Morphology in Universal Dependency Parsing Mathieu Dehouck Pascal Denis Univ. Lille, CNRS, UMR 9189 - CRIStAL Magnet Team, Inria Lille Magnet Team, Inria Lille 59650 Villeneuve d’Ascq, France 59650 Villeneuve d’Ascq, France [email protected] [email protected] Abstract as dependency parsing. Furthermore, morpholog- ically rich languages for which we hope to see a This paper presents a simple framework for real impact from those morphologically aware rep- characterizing morphological complexity and resentations, might not all rely to the same extent how it encodes syntactic information. In par- on morphology for syntax encoding. Some might ticular, we propose a new measure of morpho- syntactic complexity in terms of governor- benefit mostly from reducing data sparsity while dependent preferential attachment that ex- others, for which paradigm richness correlate with plains parsing performance. Through ex- freer word order (Comrie, 1981), will also benefit periments on dependency parsing with data from morphological information encoding. from Universal Dependencies (UD), we show that representations derived from morpholog- ical attributes deliver important parsing per- This paper aims at characterizing the role of formance improvements over standard word form embeddings when trained on the same morphology as a syntax encoding device for vari- datasets. We also show that the new morpho- ous languages. Using simple word representations, syntactic complexity measure is predictive of we measure the impact of morphological informa- the gains provided by using morphological at- tion on dependency parsing and relate it to two tributes over plain forms on parsing scores, measures of language morphological complexity: making it a tool to distinguish languages using the basic form per lemma ratio and a new measure morphology as a syntactic marker from others. -

New Insights in the Design and Compilation of Digital Bilingual Lexicographical Products: the Case of the Diccionarios Valladolid-Uva Pedro A
http://lexikos.journals.ac.za; https://doi.org/10.5788/28-1-1460 New Insights in the Design and Compilation of Digital Bilingual Lexicographical Products: The Case of the Diccionarios Valladolid-UVa Pedro A. Fuertes-Olivera, International Centre for Lexicography, University of Valladolid, Spain; and Department of Afrikaans and Dutch, University of Stellenbosch, South Africa ([email protected]) Sven Tarp, International Centre for Lexicography, University of Valladolid, Spain; Department of Afrikaans and Dutch, University of Stellenbosch, South Africa; and Centre for Lexicography, University of Aarhus, Denmark ([email protected]) and Peter Sepstrup, Ordbogen A/S, Odense, Denmark ([email protected]) Abstract: This contribution deals with a new digital English–Spanish–English lexicographical project that started as an assignment from the Danish high-tech company Ordbogen A/S which signed a contract with the University of Valladolid (Spain) for designing and compiling a digital lexi- cographical product that is economically and commercially feasible and can be used for various purposes in connection with its expansion into new markets and the launching of new tools and services which make use of lexicographical data. The article presents the philosophy underpinning the project, highlights some of the innovations introduced, e.g. the use of logfiles for compiling the initial lemma list and the order of compilation, and illustrates a compilation methodology which starts by assuming the relevance of new concepts, i.e. object and auxiliary languages instead of target and source languages. The contribution also defends the premise that the future of e-lexicog- raphy basically rests on a close cooperation between research centers and high-tech companies which assures the adequate use of disruptive technologies and innovations. -
Lexical Access and the Phonology of Morphologically Complex Words
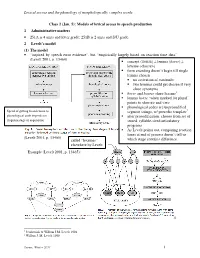
Lexical access and the phonology of morphologically complex words Class 2 (Jan. 5): Models of lexical access in speech production 1 Administrative matters • 251A is 4 units and letter grade; 251B is 2 units and S/U grade. 2 Levelt’s model (1) The model • “inspired by speech error evidence”, but “empirically largely based on reaction time data” (Levelt 2001, p. 13464) concept ( HORSE ) ≠ lemma ( horse ) ≠ lexeme (<horse>) form encoding doesn’t begin till single lemma chosen no activation of <animal> two lemmas could get chosen if very close synonyms horse and hoarse share lexeme 1 lemma horse “when marked for plural” points to <horse> and < ɪz> phonological codes are unprosodified Speed of getting from lemma to segment strings, w/ prosodic template 2 phonological code depends on after prosodification, choose from set of frequency/age of acquisition stored, syllable-sized articulatory programs As Levelt points out, comparing reaction times at end of process doesn’t tell us (Levelt 2001, p. 13465) which stage contains difference. called “lexemes” elsewhere by Levelt Example (Levelt 2001, p. 13465): 12 1 Jescheniak & Willem J.M. Levelt 1994 2 Willem J. M. Levelt 1999 Zuraw, Winter 2011 1 Lexical access and the phonology of morphologically complex words (2) Model’s interpretation of tip-of-the-tongue states (TOT) • Lemma is accessed, but then its phonological code is accessed partly or not at all. o Should we expect, in this model, to sometimes get activation of just one morpheme—e.g., <ment> but not <assort>? o Can we tell the difference between the TOT state that would result and what we’d get from partial access of a whole-word code <assortment>? (3) Model’s interpretation of semantic interference Discussion and data from Schriefers, Meyer, & Levelt 1990, with retrospective interpretation from or following Levelt 2001 • Lemmas compete for selection: At each timestep, prob. -

An Aid to Consistency in Dictionary Entry Design
Lexicological issues ofLexicographical Relevance Lexicographic Profiling: an Aid to Consistency in Dictionary Entry Design SueAtkins Lexicography MasterClass Ltd. River House Church Lane Lewes East Sussex BN7 2JA UK Valerie Grundy Lexicographic Consultant Bellevue 07440 Boffres France Abstract The first phase of any new dictionary project includes the detailed design of the dictionary entries. This involves writing sample entries. Deciding which lemmas to write entries for tends to be random, for lack of theory-based criteria for selection. This paper describes a database of the lexicographic proper- ties of English lemmas, reflecting the work of theorists such as Apresjan, Cruse, Fillmore, Lakoff, Levin and MenEuk. It was used successfully in the selection process during the planning phase of a major new English bilingual dictionary, ensuring that all major policy decisions on entry structure were made early in the project, and resulting in a DTD well able to cope with 50,000 entries and a Style Guide already comprehensive at the start of the main project. The method described here ("lexico- graphic profiling") is applicable to any language, although of course the actual properties of lemmas are to some extent language specific. 1 The background The paper describes a systematic approach to the microstructure design for a totally new corpus-based bilingual dictionary, tried and tested in Phase 1 of the New English Irish Dic- tionary (NEID) project.1 The following packages were completed on time and within the rather modest budget in the course of the one-year first phase of this project: ' This project was launched in the summer of 2003. -

COMMON and DIFFERENT ASPECTS in a SET of COMMENTARIES in DICTIONARIES and SEMANTIC TAGS Akhmedova Dildora Bakhodirovna a Teacher
International Scientific Forum on language, literature, translation, literary criticism: international scientific-practical conference on modern approaches and perspectives. Web: https://iejrd.com/ COMMON AND DIFFERENT ASPECTS IN A SET OF COMMENTARIES IN DICTIONARIES AND SEMANTIC TAGS Akhmedova Dildora Bakhodirovna A teacher, BSU Hamidova Iroda Olimovna A student, BSU Annotation: This article discusses dictionaries that can be a source of information for the language corpus, the structure of the dictionary commentary, and the possibilities of this information in tagging corpus units. Key words:corpus linguistics, lexicography, lexical units, semantic tagging, annotated dictionary, general vocabulary, limited vocabulary, illustrative example. I.Introduction Corpus linguistics is closely related to lexicography because the linguistic unit in the dictionary, whose interpretation serves as a linguo-lexicographic supply for tagging corpus units. Digitization of the text of existing dictionaries in the Uzbek language is the first step in linking the dictionary with the corpus. Uzbek lexicography has come a long way, has a rich treasure that serves as a material for the corps. According to Professor E. Begmatov, systematicity in the lexicon is not as obvious as in other levels of language. Lexical units are more numerous than phonemes, morphemes in terms of quantity, and have the property of periodic instability. Therefore, it is not possible to identify and study the lexicon on a scale. Today, world linguistics has begun to solve this problem with the help of language corpora and has already achieved results. Qualitative and quantitative inventory of vocabulary, the possibility of comprehensive research has expanded. The main source for semantic tagging of language units is the explanatory dictionary of the Uzbek language. -

Sandro Nielsen* Bilingual Dictionaries for Communication in the Domain
161 Sandro Nielsen* Bilingual Dictionaries for Communication in the Domain of Economics: Function-Based Translation Dictionaries Abstract With their focus on terms, bilingual dictionaries are important tools for translating texts on economics. The most common type is the multi-fi eld dictionary covering several related subject fi elds; however, multi-fi eld dictionaries treat one or few fi elds extensively thereby neglecting other fi elds in contrast to single-fi eld and sub-fi eld dictionaries. Furthermore, recent research shows that economic translation is not limited to terms so lexicographers who identify and analyse the needs of translators, usage situations and stages in translating economic texts will have a sound basis for designing their lexicographic tools. The function theory allows lexicographers to study these basics so that they can offer translation tools to the domain of economics. Dictionaries should include data about terms, their grammatical properties, and their combinatorial potential as well as language varieties such as British, American and international English to indicate syntactic options and restrictions on language use. Secondly, translators need to know the meaning of domain-specifi c terms to properly understand the differences in the structure of the domains in the cultures involved. Finally, pragmatic data will tell authors and translators how textual resources are conventionally used and what is textually appropriate in communication within the fi eld of economics. The focus will mainly be on translations between Danish and English. 1. Introduction Being able to communicate correctly about economic issues in international contexts is an ability that has been in high demand for some time, in particular due to increased litigation and regula- tion in the wake of the fi nancial crisis.