Linear Approximation and the Rules of Differentiation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Linear Approximation of the Derivative
Section 3.9 - Linear Approximation and the Derivative Idea: When we zoom in on a smooth function and its tangent line, they are very close to- gether. So for a function that is hard to evaluate, we can use the tangent line to approximate values of the derivative. p 3 Example Usep a tangent line to approximatep 8:1 without a calculator. Let f(x) = 3 x = x1=3. We know f(8) = 3 8 = 2. We'll use the tangent line at x = 8. 1 1 1 1 f 0(x) = x−2=3 so f 0(8) = (8)−2=3 = · 3 3 3 4 Our tangent line passes through (8; 2) and has slope 1=12: 1 y = (x − 8) + 2: 12 To approximate f(8:1) we'll find the value of the tangent line at x = 8:1. 1 y = (8:1 − 8) + 2 12 1 = (:1) + 2 12 1 = + 2 120 241 = 120 p 3 241 So 8:1 ≈ 120 : p How accurate was this approximation? We'll use a calculator now: 3 8:1 ≈ 2:00829885. 241 −5 Taking the difference, 2:00829885 − 120 ≈ −3:4483 × 10 , a pretty good approximation! General Formulas for Linear Approximation The tangent line to f(x) at x = a passes through the point (a; f(a)) and has slope f 0(a) so its equation is y = f 0(a)(x − a) + f(a) The tangent line is the best linear approximation to f(x) near x = a so f(x) ≈ f(a) + f 0(a)(x − a) this is called the local linear approximation of f(x) near x = a. -

Generalized Finite-Difference Schemes
Generalized Finite-Difference Schemes By Blair Swartz* and Burton Wendroff** Abstract. Finite-difference schemes for initial boundary-value problems for partial differential equations lead to systems of equations which must be solved at each time step. Other methods also lead to systems of equations. We call a method a generalized finite-difference scheme if the matrix of coefficients of the system is sparse. Galerkin's method, using a local basis, provides unconditionally stable, implicit generalized finite-difference schemes for a large class of linear and nonlinear problems. The equations can be generated by computer program. The schemes will, in general, be not more efficient than standard finite-difference schemes when such standard stable schemes exist. We exhibit a generalized finite-difference scheme for Burgers' equation and solve it with a step function for initial data. | 1. Well-Posed Problems and Semibounded Operators. We consider a system of partial differential equations of the following form: (1.1) du/dt = Au + f, where u = (iti(a;, t), ■ ■ -, umix, t)),f = ifxix, t), ■ • -,fmix, t)), and A is a matrix of partial differential operators in x — ixx, • • -, xn), A = Aix,t,D) = JjüiD', D<= id/dXx)h--Yd/dxn)in, aiix, t) = a,-,...i„(a;, t) = matrix . Equation (1.1) is assumed to hold in some n-dimensional region Í2 with boundary An initial condition is imposed in ti, (1.2) uix, 0) = uoix) , xEV. The boundary conditions are that there is a collection (B of operators Bix, D) such that (1.3) Bix,D)u = 0, xEdti,B<E(2>. We assume the operator A satisfies the following condition : There exists a scalar product {,) such that for all sufficiently smooth functions <¡>ix)which satisfy (1.3), (1.4) 2 Re {A4,,<t>) ^ C(<b,<p), 0 < t ^ T , where C is a constant independent of <p.An operator A satisfying (1.4) is called semi- bounded. -

Calculus I - Lecture 15 Linear Approximation & Differentials
Calculus I - Lecture 15 Linear Approximation & Differentials Lecture Notes: http://www.math.ksu.edu/˜gerald/math220d/ Course Syllabus: http://www.math.ksu.edu/math220/spring-2014/indexs14.html Gerald Hoehn (based on notes by T. Cochran) March 11, 2014 Equation of Tangent Line Recall the equation of the tangent line of a curve y = f (x) at the point x = a. The general equation of the tangent line is y = L (x) := f (a) + f 0(a)(x a). a − That is the point-slope form of a line through the point (a, f (a)) with slope f 0(a). Linear Approximation It follows from the geometric picture as well as the equation f (x) f (a) lim − = f 0(a) x a x a → − f (x) f (a) which means that x−a f 0(a) or − ≈ f (x) f (a) + f 0(a)(x a) = L (x) ≈ − a for x close to a. Thus La(x) is a good approximation of f (x) for x near a. If we write x = a + ∆x and let ∆x be sufficiently small this becomes f (a + ∆x) f (a) f (a)∆x. Writing also − ≈ 0 ∆y = ∆f := f (a + ∆x) f (a) this becomes − ∆y = ∆f f 0(a)∆x ≈ In words: for small ∆x the change ∆y in y if one goes from x to x + ∆x is approximately equal to f 0(a)∆x. Visualization of Linear Approximation Example: a) Find the linear approximation of f (x) = √x at x = 16. b) Use it to approximate √15.9. Solution: a) We have to compute the equation of the tangent line at x = 16. -

Chapter 3, Lecture 1: Newton's Method 1 Approximate
Math 484: Nonlinear Programming1 Mikhail Lavrov Chapter 3, Lecture 1: Newton's Method April 15, 2019 University of Illinois at Urbana-Champaign 1 Approximate methods and asumptions The final topic covered in this class is iterative methods for optimization. These are meant to help us find approximate solutions to problems in cases where finding exact solutions would be too hard. There are two things we've taken for granted before which might actually be too hard to do exactly: 1. Evaluating derivatives of a function f (e.g., rf or Hf) at a given point. 2. Solving an equation or system of equations. Before, we've assumed (1) and (2) are both easy. Now we're going to figure out what to do when (2) and possibly (1) is hard. For example: • For a polynomial function of high degree, derivatives are straightforward to compute, but it's impossible to solve equations exactly (even in one variable). • For a function we have no formula for (such as the value function MP(z) from Chapter 5, for instance) we don't have a good way of computing derivatives, and they might not even exist. 2 The classical Newton's method Eventually we'll get to optimization problems. But we'll begin with Newton's method in its basic form: an algorithm for approximately finding zeroes of a function f : R ! R. This is an iterative algorithm: starting with an initial guess x0, it makes a better guess x1, then uses it to make an even better guess x2, and so on. We hope that eventually these approach a solution. -

The Linear Algebra Version of the Chain Rule 1
Ralph M Kaufmann The Linear Algebra Version of the Chain Rule 1 Idea The differential of a differentiable function at a point gives a good linear approximation of the function – by definition. This means that locally one can just regard linear functions. The algebra of linear functions is best described in terms of linear algebra, i.e. vectors and matrices. Now, in terms of matrices the concatenation of linear functions is the matrix product. Putting these observations together gives the formulation of the chain rule as the Theorem that the linearization of the concatenations of two functions at a point is given by the concatenation of the respective linearizations. Or in other words that matrix describing the linearization of the concatenation is the product of the two matrices describing the linearizations of the two functions. 1. Linear Maps Let V n be the space of n–dimensional vectors. 1.1. Definition. A linear map F : V n → V m is a rule that associates to each n–dimensional vector ~x = hx1, . xni an m–dimensional vector F (~x) = ~y = hy1, . , yni = hf1(~x),..., (fm(~x))i in such a way that: 1) For c ∈ R : F (c~x) = cF (~x) 2) For any two n–dimensional vectors ~x and ~x0: F (~x + ~x0) = F (~x) + F (~x0) If m = 1 such a map is called a linear function. Note that the component functions f1, . , fm are all linear functions. 1.2. Examples. 1) m=1, n=3: all linear functions are of the form y = ax1 + bx2 + cx3 for some a, b, c ∈ R. -

2.8 Linear Approximation and Differentials
196 the derivative 2.8 Linear Approximation and Differentials Newton’s method used tangent lines to “point toward” a root of a function. In this section we examine and use another geometric charac- teristic of tangent lines: If f is differentiable at a, c is close to a and y = L(x) is the line tangent to f (x) at x = a then L(c) is close to f (c). We can use this idea to approximate the values of some commonly used functions and to predict the “error” or uncertainty in a compu- tation if we know the “error” or uncertainty in our original data. At the end of this section, we will define a related concept called the differential of a function. Linear Approximation Because this section uses tangent lines extensively, it is worthwhile to recall how we find the equation of the line tangent to f (x) where x = a: the tangent line goes through the point (a, f (a)) and has slope f 0(a) so, using the point-slope form y − y0 = m(x − x0) for linear equations, we have y − f (a) = f 0(a) · (x − a) ) y = f (a) + f 0(a) · (x − a). If f is differentiable at x = a then an equation of the line L tangent to f at x = a is: L(x) = f (a) + f 0(a) · (x − a) Example 1. Find a formula for L(x), the linear function tangent to the p ( ) = ( ) ( ) ( ) graph of f x p x atp the point 9, 3 . Evaluate L 9.1 and L 8.88 to approximate 9.1 and 8.88. -

Propagation of Error Or Uncertainty
Propagation of Error or Uncertainty Marcel Oliver December 4, 2015 1 Introduction 1.1 Motivation All measurements are subject to error or uncertainty. Common causes are noise or external disturbances, imperfections in the experimental setup and the measuring devices, coarseness or discreteness of instrument scales, unknown parameters, and model errors due to simpli- fying assumptions in the mathematical description of an experiment. An essential aspect of scientific work, therefore, is quantifying and tracking uncertainties from setup, measure- ments, all the way to derived quantities and resulting conclusions. In the following, we can only address some of the most common and simple methods of error analysis. We shall do this mainly from a calculus perspective, with some comments on statistical aspects later on. 1.2 Absolute and relative error When measuring a quantity with true value xtrue, the measured value x may differ by a small amount ∆x. We speak of ∆x as the absolute error or absolute uncertainty of x. Often, the magnitude of error or uncertainty is most naturally expressed as a fraction of the true or the measured value x. Since the true value xtrue is typically not known, we shall define the relative error or relative uncertainty as ∆x=x. In scientific writing, you will frequently encounter measurements reported in the form x = 3:3 ± 0:05. We read this as x = 3:3 and ∆x = 0:05. 1.3 Interpretation Depending on context, ∆x can have any of the following three interpretations which are different, but in simple settings lead to the same conclusions. 1. An exact specification of a deviation in one particular trial (instance of performing an experiment), so that xtrue = x + ∆x : 1 Of course, typically there is no way to know what this true value actually is, but for the analysis of error propagation, this interpretation is useful. -

Characterization of Non-Differentiable Points in a Function by Fractional Derivative of Jumarrie Type
Characterization of non-differentiable points in a function by Fractional derivative of Jumarrie type Uttam Ghosh (1), Srijan Sengupta(2), Susmita Sarkar (2), Shantanu Das (3) (1): Department of Mathematics, Nabadwip Vidyasagar College, Nabadwip, Nadia, West Bengal, India; Email: [email protected] (2):Department of Applied Mathematics, Calcutta University, Kolkata, India Email: [email protected] (3)Scientist H+, RCSDS, BARC Mumbai India Senior Research Professor, Dept. of Physics, Jadavpur University Kolkata Adjunct Professor. DIAT-Pune Ex-UGC Visiting Fellow Dept. of Applied Mathematics, Calcutta University, Kolkata India Email (3): [email protected] The Birth of fractional calculus from the question raised in the year 1695 by Marquis de L'Hopital to Gottfried Wilhelm Leibniz, which sought the meaning of Leibniz's notation for the derivative of order N when N = 1/2. Leibnitz responses it is an apparent paradox from which one day useful consequences will be drown. Abstract There are many functions which are continuous everywhere but not differentiable at some points, like in physical systems of ECG, EEG plots, and cracks pattern and for several other phenomena. Using classical calculus those functions cannot be characterized-especially at the non- differentiable points. To characterize those functions the concept of Fractional Derivative is used. From the analysis it is established that though those functions are unreachable at the non- differentiable points, in classical sense but can be characterized using Fractional derivative. In this paper we demonstrate use of modified Riemann-Liouvelli derivative by Jumarrie to calculate the fractional derivatives of the non-differentiable points of a function, which may be one step to characterize and distinguish and compare several non-differentiable points in a system or across the systems. -

Lecture # 10 - Derivatives of Functions of One Variable (Cont.)
Lecture # 10 - Derivatives of Functions of One Variable (cont.) Concave and Convex Functions We saw before that • f 0 (x) 0 f (x) is a decreasing function ≤ ⇐⇒ Wecanusethesamedefintion for the second derivative: • f 00 (x) 0 f 0 (x) is a decreasing function ≤ ⇐⇒ Definition: a function f ( ) whose first derivative is decreasing(and f (x) 0)iscalleda • · 00 ≤ concave function In turn, • f 00 (x) 0 f 0 (x) is an increasing function ≥ ⇐⇒ Definition: a function f ( ) whose first derivative is increasing (and f (x) 0)iscalleda • · 00 ≥ convex function Notes: • — If f 00 (x) < 0, then it is a strictly concave function — If f 00 (x) > 0, then it is a strictly convex function Graphs • Importance: • — Concave functions have a maximum — Convex functions have a minimum. 1 Economic Application: Elasticities Economists are often interested in analyzing how demand reacts when price changes • However, looking at ∆Qd as ∆P =1may not be good enough: • — Change in quantity demanded for coffee when price changes by 1 euro may be huge — Change in quantity demanded for cars coffee when price changes by 1 euro may be insignificant Economist look at relative changes, i.e., at the percentage change: what is ∆% in Qd as • ∆% in P We can write as the following ratio • ∆%Qd ∆%P Now the rate of change can be written as ∆%x = ∆x . Then: • x d d ∆Q d ∆%Q d ∆Q P = Q = ∆%P ∆P ∆P Qd P · Further, we are interested in the changes in demand when ∆P is very small = Take the • ⇒ limit ∆Qd P ∆Qd P dQd P lim = lim = ∆P 0 ∆P · Qd ∆P 0 ∆P · Qd dP · Qd µ → ¶ µ → ¶ So we have finally arrived to the definition of price elasticity of demand • dQd P = dP · Qd d dQd P P Example 1 Consider Q = 100 2P. -
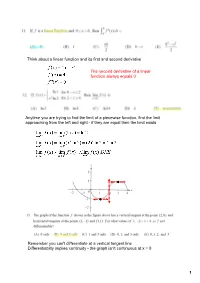
1 Think About a Linear Function and Its First and Second Derivative The
Think about a linear function and its first and second derivative The second derivative of a linear function always equals 0 Anytime you are trying to find the limit of a piecewise function, find the limit approaching from the left and right if they are equal then the limit exists Remember you can't differentiate at a vertical tangent line Differentiabilty implies continuity the graph isn't continuous at x = 0 1 To find the velocity, take the first derivative of the position function. To find where the velocity equals zero, set the first derivative equal to zero 2 From the graph, we know that f (1) = 0; Since the graph is increasing, we know that f '(1) is positive; since the graph is concave down, we know that f ''(1) is negative Possible points of inflection need to set up a table to see where concavity changes (that verifies points of inflection) (∞, 1) (1, 0) (0, 2) (2, ∞) + + + concave up concave down concave up concave up Since the concavity changes when x = 1 and when x = 0, they are points of inflection. x = 2 is not a point of inflection 3 We need to find the derivative, find the critical numbers and use them in the first derivative test to find where f (x) is increasing and decreasing (∞, 0) (0, ∞) + Decreasing Increasing 4 This is the graph of y = cos x, shifted right (A) and (C) are the only graphs of sin x, and (A) is the graph of sin x, which reflects across the xaxis 5 Take the derivative of the velocity function to find the acceleration function There are no critical numbers, because v '(t) doesn't ever equal zero (you can verify this by graphing v '(t) there are no xintercepts). -

Algebra Vocabulary List (Definitions for Middle School Teachers)
Algebra Vocabulary List (Definitions for Middle School Teachers) A Absolute Value Function – The absolute value of a real number x, x is ⎧ xifx≥ 0 x = ⎨ ⎩−<xifx 0 http://www.math.tamu.edu/~stecher/171/F02/absoluteValueFunction.pdf Algebra Lab Gear – a set of manipulatives that are designed to represent polynomial expressions. The set includes representations for positive/negative 1, 5, 25, x, 5x, y, 5y, xy, x2, y2, x3, y3, x2y, xy2. The manipulatives can be used to model addition, subtraction, multiplication, division, and factoring of polynomials. They can also be used to model how to solve linear equations. o For more info: http://www.stlcc.cc.mo.us/mcdocs/dept/math/homl/manip.htm http://www.awl.ca/school/math/mr/alg/ss/series/algsrtxt.html http://www.picciotto.org/math-ed/manipulatives/lab-gear.html Algebra Tiles – a set of manipulatives that are designed for modeling algebraic expressions visually. Each tile is a geometric model of a term. The set includes representations for positive/negative 1, x, and x2. The manipulatives can be used to model addition, subtraction, multiplication, division, and factoring of polynomials. They can also be used to model how to solve linear equations. o For more info: http://math.buffalostate.edu/~it/Materials/MatLinks/tilelinks.html http://plato.acadiau.ca/courses/educ/reid/Virtual-manipulatives/tiles/tiles.html Algebraic Expression – a number, variable, or combination of the two connected by some mathematical operation like addition, subtraction, multiplication, division, exponents and/or roots. o For more info: http://www.wtamu.edu/academic/anns/mps/math/mathlab/beg_algebra/beg_alg_tut11 _simp.htm http://www.math.com/school/subject2/lessons/S2U1L1DP.html Area Under the Curve – suppose the curve y=f(x) lies above the x axis for all x in [a, b]. -

Generic Continuous Functions and Other Strange Functions in Classical Real Analysis
Georgia State University ScholarWorks @ Georgia State University Mathematics Theses Department of Mathematics and Statistics 4-17-2008 Generic Continuous Functions and other Strange Functions in Classical Real Analysis Douglas Albert Woolley Follow this and additional works at: https://scholarworks.gsu.edu/math_theses Part of the Mathematics Commons Recommended Citation Woolley, Douglas Albert, "Generic Continuous Functions and other Strange Functions in Classical Real Analysis." Thesis, Georgia State University, 2008. https://scholarworks.gsu.edu/math_theses/44 This Thesis is brought to you for free and open access by the Department of Mathematics and Statistics at ScholarWorks @ Georgia State University. It has been accepted for inclusion in Mathematics Theses by an authorized administrator of ScholarWorks @ Georgia State University. For more information, please contact [email protected]. GENERIC CONTINUOUS FUNCTIONS AND OTHER STRANGE FUNCTIONS IN CLASSICAL REAL ANALYSIS by Douglas A. Woolley Under the direction of Mihaly Bakonyi ABSTRACT In this paper we examine continuous functions which on the surface seem to defy well-known mathematical principles. Before describing these functions, we introduce the Baire Cate- gory theorem and the Cantor set, which are critical in describing some of the functions and counterexamples. We then describe generic continuous functions, which are nowhere differ- entiable and monotone on no interval, and we include an example of such a function. We then construct a more conceptually challenging function, one which is everywhere differen- tiable but monotone on no interval. We also examine the Cantor function, a nonconstant continuous function with a zero derivative almost everywhere. The final section deals with products of derivatives. INDEX WORDS: Baire, Cantor, Generic Functions, Nowhere Differentiable GENERIC CONTINUOUS FUNCTIONS AND OTHER STRANGE FUNCTIONS IN CLASSICAL REAL ANALYSIS by Douglas A.