Trust in Official Statistics. an Econometric Search for Determinants
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Generic Law on Official Statistics for Latin America
Generic Law on Official Statistics for Latin America Statistical Conference of the Americas of ECLAC Thank you for your interest in this ECLAC publication ECLAC Publications Please register if you would like to receive information on our editorial products and activities. When you register, you may specify your particular areas of interest and you will gain access to our products in other formats. www.cepal.org/en/publications ublicaciones www.cepal.org/apps Generic Law on Official Statistics for Latin America Statistical Conference of the Americas of ECLAC The Generic Law on Official Statistics for Latin America was adopted by the Statistical Conference of the Americas of the Economic Commission for Latin America and the Caribbean at its tenth meeting, held in Santiago from 19 to 21 November 2019. Thanks are conveyed to the Inter-American Development Bank (IDB) for its support in the preparation of this document. IDB provided consultants who were involved throughout the process and financial support for the organization of the Regional workshop on legal frameworks for the production of official statistics, held in Bogotá, from 3 to 5 July 2018, and for the meeting at which the final text was discussed, in San Salvador, on 29 and 30 August 2019. United Nations publication LC/CEA.10/8 Distribution: L Copyright © United Nations, 2020 All rights reserved Printed at United Nations, Santiago S.20-00045 This publication should be cited as: Economic Commission for Latin America and the Caribbean (ECLAC), Generic Law on Official Statistics for Latin America (LC/CEA.10/8), Santiago, 2020. Applications for authorization to reproduce this work in whole or in part should be sent to the Economic Commission for Latin America and the Caribbean (ECLAC), Publications and Web Services Division, publicaciones. -

List of Participants
List of participants Conference of European Statisticians 69th Plenary Session, hybrid Wednesday, June 23 – Friday 25 June 2021 Registered participants Governments Albania Ms. Elsa DHULI Director General Institute of Statistics Ms. Vjollca SIMONI Head of International Cooperation and European Integration Sector Institute of Statistics Albania Argentina Sr. Joaquin MARCONI Advisor in International Relations, INDEC Mr. Nicolás PETRESKY International Relations Coordinator National Institute of Statistics and Censuses (INDEC) Elena HASAPOV ARAGONÉS National Institute of Statistics and Censuses (INDEC) Armenia Mr. Stepan MNATSAKANYAN President Statistical Committee of the Republic of Armenia Ms. Anahit SAFYAN Member of the State Council on Statistics Statistical Committee of RA Australia Mr. David GRUEN Australian Statistician Australian Bureau of Statistics 1 Ms. Teresa DICKINSON Deputy Australian Statistician Australian Bureau of Statistics Ms. Helen WILSON Deputy Australian Statistician Australian Bureau of Statistics Austria Mr. Tobias THOMAS Director General Statistics Austria Ms. Brigitte GRANDITS Head International Relation Statistics Austria Azerbaijan Mr. Farhad ALIYEV Deputy Head of Department State Statistical Committee Mr. Yusif YUSIFOV Deputy Chairman The State Statistical Committee Belarus Ms. Inna MEDVEDEVA Chairperson National Statistical Committee of the Republic of Belarus Ms. Irina MAZAISKAYA Head of International Cooperation and Statistical Information Dissemination Department National Statistical Committee of the Republic of Belarus Ms. Elena KUKHAREVICH First Deputy Chairperson National Statistical Committee of the Republic of Belarus Belgium Mr. Roeland BEERTEN Flanders Statistics Authority Mr. Olivier GODDEERIS Head of international Strategy and coordination Statistics Belgium 2 Bosnia and Herzegovina Ms. Vesna ĆUŽIĆ Director Agency for Statistics Brazil Mr. Eduardo RIOS NETO President Instituto Brasileiro de Geografia e Estatística - IBGE Sra. -

UNWTO/DG GROW Workshop Measuring the Economic Impact Of
UNWTO/DG GROW Workshop Measuring the economic impact of tourism in Europe: the Tourism Satellite Account (TSA) Breydel building – Brey Auditorium Avenue d'Auderghem 45, B-1040 Brussels, Belgium 29-30 November 2017 LIST OF PARTICIPANTS Title First name Last name Institution Position Country EU 28 + COSME COUNTRIES State Tourism Committee of the First Vice Chairman of the State Tourism Mr Mekhak Apresyan Armenia Republic of Armenia Committee of the Republic of Armenia Trade Representative of the RA to the Mr Varos Simonyan Trade Representative of the RA to the EU Armenia EU Head of balance of payments and Ms Kristine Poghosyan National Statistical Service of RA Armenia foreign trade statistics division Mr Gagik Aghajanyan Central Bank of the Republic of Armenia Head of Statistics Department Armenia Mr Holger Sicking Austrian National Tourist Office Head of Market Research Austria Federal Ministry of Science, Research Ms Angelika Liedler Head of International Tourism Affairs Austria and Economy Department of Tourism, Ministry of Consultant of Planning and Organization Ms Liya Stoma Sports and Tourism of the Republic of Belarus of Tourism Activities Division Belarus Ms Irina Chigireva National Statistical Committee Head of Service and Domestic Trade Belarus Attachée - Observatoire du Tourisme Ms COSSE Véronique Commissariat général au Tourisme Belgium wallon Mr François VERDIN Commissariat général au Tourisme Veille touristique et études de marché Belgium 1 Title First name Last name Institution Position Country Agency for statistics of Bosnia -
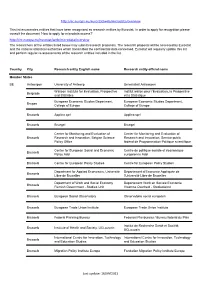
Eurostat: Recognized Research Entity
http://ec.europa.eu/eurostat/web/microdata/overview This list enumerates entities that have been recognised as research entities by Eurostat. In order to apply for recognition please consult the document 'How to apply for microdata access?' http://ec.europa.eu/eurostat/web/microdata/overview The researchers of the entities listed below may submit research proposals. The research proposal will be assessed by Eurostat and the national statistical authorities which transmitted the confidential data concerned. Eurostat will regularly update this list and perform regular re-assessments of the research entities included in the list. Country City Research entity English name Research entity official name Member States BE Antwerpen University of Antwerp Universiteit Antwerpen Walloon Institute for Evaluation, Prospective Institut wallon pour l'Evaluation, la Prospective Belgrade and Statistics et la Statistique European Economic Studies Department, European Economic Studies Department, Bruges College of Europe College of Europe Brussels Applica sprl Applica sprl Brussels Bruegel Bruegel Center for Monitoring and Evaluation of Center for Monitoring and Evaluation of Brussels Research and Innovation, Belgian Science Research and Innovation, Service public Policy Office fédéral de Programmation Politique scientifique Centre for European Social and Economic Centre de politique sociale et économique Brussels Policy Asbl européenne Asbl Brussels Centre for European Policy Studies Centre for European Policy Studies Department for Applied Economics, -

United Nations Fundamental Principles of Official Statistics
UNITED NATIONS United Nations Fundamental Principles of Official Statistics Implementation Guidelines United Nations Fundamental Principles of Official Statistics Implementation guidelines (Final draft, subject to editing) (January 2015) Table of contents Foreword 3 Introduction 4 PART I: Implementation guidelines for the Fundamental Principles 8 RELEVANCE, IMPARTIALITY AND EQUAL ACCESS 9 PROFESSIONAL STANDARDS, SCIENTIFIC PRINCIPLES, AND PROFESSIONAL ETHICS 22 ACCOUNTABILITY AND TRANSPARENCY 31 PREVENTION OF MISUSE 38 SOURCES OF OFFICIAL STATISTICS 43 CONFIDENTIALITY 51 LEGISLATION 62 NATIONAL COORDINATION 68 USE OF INTERNATIONAL STANDARDS 80 INTERNATIONAL COOPERATION 91 ANNEX 98 Part II: Implementation guidelines on how to ensure independence 99 HOW TO ENSURE INDEPENDENCE 100 UN Fundamental Principles of Official Statistics – Implementation guidelines, 2015 2 Foreword The Fundamental Principles of Official Statistics (FPOS) are a pillar of the Global Statistical System. By enshrining our profound conviction and commitment that offi- cial statistics have to adhere to well-defined professional and scientific standards, they define us as a professional community, reaching across political, economic and cultural borders. They have stood the test of time and remain as relevant today as they were when they were first adopted over twenty years ago. In an appropriate recognition of their significance for all societies, who aspire to shape their own fates in an informed manner, the Fundamental Principles of Official Statistics were adopted on 29 January 2014 at the highest political level as a General Assembly resolution (A/RES/68/261). This is, for us, a moment of great pride, but also of great responsibility and opportunity. In order for the Principles to be more than just a statement of noble intentions, we need to renew our efforts, individually and collectively, to make them the basis of our day-to-day statistical work. -

World Health Statistics 2007
100010010010100101111101010100001010111111001010001100100100100010001010010001001001010000010001010101000010010010010100001001010 00100101010010111011101000100101001001000101001010101001010010010010010100100100100100101010100101010101001010101001101010010000 101010100111101010001010010010010100010100101001010100100100101010000101010001001010111110010101010100100101000010100100010100101 001010010001001000100100101001011111010101000010101111110010100011001001001000100010100100010010010100000100010101010000100100100 1010000100101000100101010010111011101000100101001001000101001010101001010010010010010100100100100100101010100101010101001010101le e 0 ib n n lí po n s e i a d 01101010010000101010100n 1111010100010100100100101000101001010010101001001001010100001010100010010101111100101010101001001010000101 W é i b 0010001010010100101001000100010001001001010010 11111010101000010101111110010100011001001001000100010100100010010010100000100010101 m a t ORLD 0100001001001001010000100101000100101010010111011101000100101001001000101001010101001010010010010010100100100100100101010100101 0 101010010101010011010100100001010101001111010100010100100100101000101001010010101001001001010100001010100010010101 111100101010101 e www.who.int/whosis n 0010010100001010010001010010100101001000100010001001001010010111110101010000101011111100101000110010010010001000101001000100100 g 10 i é l n g 1000001000101010100001001001001010000100101000100101010010111011101000100101001001000101001010101001010010010010010100100100100a e 1 H le le 00101010100101010101001010101001101010010000101010100ment -

Jacob Oleson
JACOB J. OLESON The University of Iowa College of Public Health Department of Biostatistics Iowa City, IA 52242 [email protected] Citizenship: USA EDUCATION: Ph.D. Statistics University of Missouri – Columbia 2002 M.A. Statistics University of Missouri – Columbia 1999 B.A. Mathematics Central College (Pella, Iowa) 1997 EMPLOYMENT: 2015 – present Director of Graduate Studies, Department of Biostatistics, The University of Iowa 2014 – present Director – Center for Public Health Statistics – College of Public Health – The University of Iowa 2012 – present Associate Professor – Department of Biostatistics – College of Public Health – The University of Iowa 2004 – 2012 Assistant Professor – Department of Biostatistics – College of Public Health – The University of Iowa 2002 – 2004 Assistant Professor – Department of Mathematics & Statistics – Arizona State University 2000 – 2002 Research Assistant – University of Missouri - Columbia; Missouri Department of Conservation 1999 – 2002 Research Assistant – University of Missouri - Columbia; Biostatistics. 1997 – 2000 Graduate Instructor – University of Missouri - Columbia COURSES TAUGHT: The University of Iowa • 171:161 – Introduction to Biostatistics (3 terms) • 171:162 – Introduction to Biostatistics WWW (online) (4 terms; supervisor 10 terms) • 171:162 – Design and Analysis of Biomedical Studies (6 terms; supervisor 6 terms) • 171:241 – Applied Categorical Data Analysis (2 terms) • 171:202 – Biostatistical Methods II (3 terms) • 171:281 – Independent Study (Spatial Statistics, Survey Statistics, -

In-Depth Review of the Role of the Statistical Community in Climate Action
Informal document 21/Add.1 English only (A summary document carrying symbol ECE/CES/2020/21 is available in English, French and Russian on the web page of the 68th CES plenary session) Economic Commission for Europe Conference of European Statisticians Sixty-eighth plenary session Geneva, 22-24 June 2020 Item 9 of the provisional agenda Coordination of international statistical work in the United Nations Economic Commission for Europe region: outcomes of the recent in-depth reviews carried out by the Bureau of the Conference of European Statisticians In-depth review of the role of the statistical community in climate action Note by the Steering Group on climate change-related statistics and the Secretariat Summary This document is a full version of the in-depth review paper on the role of the statistical community in climate action. The in-depth review was mandated by the Bureau of the Conference of European Statisticians (CES) to examine the role of the statistical community in providing data and statistics for climate action. The document presents an analysis of the policy frameworks in place, an overview of multiple international activities related to climate change statistics and data, a description of country practices regarding the involvement of national statistical offices in climate change-related statistics, and a list identified issues and challenges. The last section summarises the discussion and decision by the Bureau in February 2020. After the Bureau meeting, the document was circulated to the described organizations and updated based on their input. An abridged version of this in-depth review paper has been prepared for translation purposes and is available in English, French and Russian on the webpage of the sixty-eighth CES plenary session as document ECE/CES/2020/21. -

A Report on the Contents and Comparability of the Eu-Silc Income Variables
HERMAN DELEECK CENTRE FOR SOCIAL POLICY Tim Goedemé and Lorena Zardo Trindade METASILC 2015: A REPORT ON THE CONTENTS AND COMPARABILITY OF THE EU-SILC INCOME VARIABLES WORKING PAPER NO. 20.01 January 2020 University of Antwerp Herman Deleeck Centre for Social Policy centrumvoorsociaalbeleid.be METASILC 2015: A REPORT ON THE CONTENTS AND COMPARABILITY OF THE EU-SILC INCOME VARIABLES Tim Goedemé1,2 and Lorena Zardo Trindade1 (eds.) 1Herman Deleeck Centre for Social Policy University of Antwerp 2Institute for New Economic Thinking at the Oxford Martin School Department of Social Policy and Intervention University of Oxford This report is also available as INET Oxford Working Paper No. 2020-01, January 2020, Employment, Equity & Growth Programme 2020 Please cite this report and the MetaSILC 2015 database as: Goedemé, T. and Zardo Trindade, L. (eds.) (2020). MetaSILC 2015: A report on the contents and comparability of the EU-SILC income variables, INET Working Paper 2020-1 & CSB Working Paper WP 20/01. Oxford: Institute for New Economic Thinking, University of Oxford & Antwerp: Herman Deleeck Centre for Social Policy, University of Antwerp. Goedemé, T. and Zardo Trindade, L. (2020). MetaSILC 2015: A database on the contents and comparability of the EU-SILC income variables [Data file], Antwerp: Herman Deleeck Centre for Social Policy, University of Antwerp & Oxford: Institute for New Economic Thinking, University of Oxford. https://doi.org/10.7910/DVN/TLSZ4S. 1 ACRONYMS AND ABBREVIATIONS CYSTAT Statistical Service of the Republic of Cyprus -

Official Statistics for the Next Decade-- Methodological Issues and Challenges
Official Statistics for the Next Decade-- Methodological Issues and Challenges Danny Pfeffermann Conference on New Techniques and Technologies for Statistics (NTTS) March, 2015 1 List of tough challenges A- Collection and management of big data for POS √ B- Integration of computer science for POS from big data C- Data accessibility, privacy and confidentiality D- Possible use of Internet panels √ E- How to deal with mode effects √ G- Future censuses and small area estimation √ F- Integration of statistics and geospatial information. Ques. Are Universities preparing students for NSOs? √ 2 Collection and management of big data for POS Exp. 1. Count of number of vehicles crossing road sections. Presently done in a very primitive way. Why not get the information and much more from cell phone companies? Available in principle for each time point. Exp. 2. Use the BPP, based on 5 million commodities sold on line to predict the CPI requires two costly surveys. 3 Big Data Big Problems Big headache Coverage/selection bias (we are talking of POS) Data accessibility New legislation Privacy (data protection) Disclosure control Computer storage Computation and Analysis Linkage of different files Risk of data manipulation 4 Two types of big data Type 1. Data obtained from sensors, cameras, cell phones…, - generally structured and accurate, Type 2. Data obtained from social networks, e-commerce etc.,- diverse, unstructured and appears irregularly. Type 1 measurements available continuously. Should POS publications be mostly in the form of graphs and pictures? If aggregate data needed, how should big data be transformed to monthly aggregates? By sampling? Will random sampling continue playing an important role when processing big data? 5 Other important issues Coverage bias- major concern in use of big data for POS. -

WP1105 Modeling Mortality with a Bayesian Vector
ARC Centre of Excellence in Population Ageing Research Working Paper 2011/5 Modeling Mortality with a Bayesian Vector Autoregression Carolyn Njenga and Michael Sherris* * Njenga is a doctoral student in the School of Risk and Actuarial at the University of New South Wales (UNSW) and a Research Assistant at the ARC Centre of Excellence in Population Ageing Research (CEPAR). Sherris is Professor of Actuarial Studies at UNSW and a CEPAR Chief Investigator. This paper can be downloaded without charge from the ARC Centre of Excellence in Population Ageing Research Working Paper Series available at www.cepar.edu.au Modeling Mortality with a Bayesian Vector Autoregression Carolyn Ndigwako Njenga Australian School of Business University of New South Wales, Sydney, NSW, 2052 Australia Email: [email protected] Michael Sherris Australian School of Business University of New South Wales, Sydney, NSW, 2052 Email: [email protected] 4th March 2011 Abstract Mortality risk models have been developed to capture trends and common fac- tors driving mortality improvement. Multiple factor models take many forms and are often developed and fitted to older ages. In order to capture trends from young ages it is necessary to take into account the richer age structure of mortality im- provement from young ages to middle and then into older ages. The Heligman and Pollard (1980) model is a parametric model which captures the main features of period mortality tables and has parameters that are interpreted according to age range and effect on rates. Although time series techniques have been applied to model parameters in various parametric mortality models, there has been limited analysis of parameter risk using Bayesian techniques. -

Big Data and Modernizing Federal Statistics: Update Bill Bostic Associate Director Economic Programs Directorate
Big Data and Modernizing Federal Statistics: Update Bill Bostic Associate Director Economic Programs Directorate Ron Jarmin Ph.D. Assistant Director, Research and Methodology Directorate August 2015 1 Big Data Trends and Challenges . Trends . Increasingly data-driven economy . Individuals are increasingly mobile . Technology changes data uses . Stakeholder expectations are changing . Agency budgets and staffing remain flat/reduced. The next generation of official statistics . Utilize broad sources of information . Increase granularity, detail, and timeliness . Reduce cost & burden . Maintain confidentiality and security . Measure impact of a global economy . Multi-disciplinary challenges : . Computation, statistics, informatics, social science, policy 2 MIT Workshop Series Objectives . Convene experts – . in computer science, social science, statistics, informatics and business . Explore . challenges to building the next generation of official statistics . Identify . new opportunities for using big data to augment official statistics . core computational and methodological challenges . ongoing research that should inform the Big Data research program 3 Workshop Organizers Series Conveners . Census: Cavan Capps, Ron Prevost . MIT: Micah Altman Workshop conveners . First Workshop: Ron Duych (DOT), Joy Sharp (DOT) . Second Workshop Amy O’Hara, Laura McKenna, Robin Bachman . Third Workshop: Peter Miller, Benjamin Reist, Michael Thieme Workshop Sponsors . William Bostic, Ron Jarmin 4 Workshop Coverage Approach . Examine a set of broad topical questions through a specific case . Link broad issues to specific approach case Acquisition . Link specific challenge of case to broad challenge Topics Big Data Access Retention Challenges Acquisition – Data Sources Using New forms of Information for Official Economic Statistics [August 3-4] Access -- Privacy Challenges Analysis Location Confidentiality and Official Surveys [October 5-6] Analysis – Inference Challenges Transparency and Inference [December 7-8] 5 Preliminary Observations from First Workshop .