App Miscategorization Detection: a Case Study on Google Play
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Moresurprisesfromfairacres
Fiction ISBN1-56145-255-6 $14.95 www.peachtree-online.com EFFIE LELAND WILDER’S ou’d think that author Effie Wilder—at the age of first novel, OUT TO PASTURE ninety-two and with more than 500,000 copies of her H, MY GOODNESS! Hattie (BUT NOT OVER THE HILL) was is at it again! In spite of her published to great acclaim in Yfour best-selling books in print—would be content to O 1995 when she was eighty-five rest on her laurels. Fortunately for us, she isn’t the “retiring” surprises fr failing eyesight, inveterate journal- years old. Its three sequels, OVER WHAT HILL, re om keeper and eavesdropper extraordi- sort. In response to the flood of letters from fans requesting o Fair cres) OLDER BUT WILDER, and ONE MORE TIME, have (m A naire Hattie McNair is still reporting attracted an even wider readership. another visit to FairAcres Home, Mrs. Wilder has graciously on the antics of her lovable cohorts at Mrs. Wilder has lived in Summerville, invited us back for another delightfully uplifting and enter- FairAcres Home. South Carolina, for more than sixty years, the In her familiar journal entries, last fifteen of them at the Presbyterian Home. taining adventure. Whether you’re already acquainted with Hattie takes note of the laughter that She graduated from Converse College in 1930 Hattie and her friends or are meeting them for the first time, lightens their days as well as the tears and received the Distinguished Alumna Award you’re sure to be charmed by these folks who have a whole lot in 1982. -

Freedaily Paper of the Hay Festival Lionel Shriver What We Talk About
Freedaily paper of the Hay Festival The HaylyTelegraph telegraph.co.uk/hayfestival • 25/05/13 Published by The Telegraph, the Hay Festival’s UK media partner. Printed on recycled paper Lionel Shriver What we talk about when we talk about food Inside GlamFest FreeSpeech StandUp this issue David Gritten Andrew Solomon Dara Ó Briain, Jo gets on the says embrace the Brand, Ed Byrne, Great Gatsby child you have, not Sandi Toksvig, Lee roller coaster the one you want Mack – and more! 2 The Hayly Telegraph SATURDAY, MAY 25, 2013 We need to shut up about size JQ@MNOJMT%@MI@RIJQ@GDN<GG about it. In retrospect, that very obliviousness must have helped to keep me slim. <=JPOA<O =PO)DJI@G0CMDQ@M So perhaps one solution to our present-day <MBP@NDO]NODH@R@NOJKK@? dietary woes is to restore a measure of casualness about daily sustenance. We think J=N@NNDIB<=JPOJPMR@DBCO about food too much. We impute far too much significance, sociologically, Growing up in America, I was a picky eater. psychologically and morally, to how much Lunch was a pain; I’d rather have kept people weigh. Worst of all, we impute too playing. During an athletic adolescence I ate much significance to how much we weigh whatever I liked, impervious to the calorie- ourselves. Unrelenting self-torture over counting anxieties of my classmates. At 17, I poundage is ruining countless people’s summered in Britain with a much heavier lives, and I don’t mean only those with eating girlfriend. After hitting multiple bakeries, disorders. -
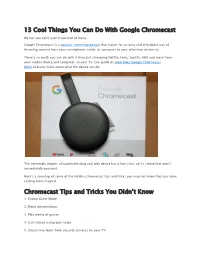
13 Cool Things You Can Do with Google Chromecast Chromecast
13 Cool Things You Can Do With Google Chromecast We bet you don't even know half of these Google Chromecast is a popular streaming dongle that makes for an easy and affordable way of throwing content from your smartphone, tablet, or computer to your television wirelessly. There’s so much you can do with it than just streaming Netflix, Hulu, Spotify, HBO and more from your mobile device and computer, to your TV. Our guide on How Does Google Chromecast Work explains more about what the device can do. The seemingly simple, ultraportable plug and play device has a few tricks up its sleeve that aren’t immediately apparent. Here’s a roundup of some of the hidden Chromecast tips and tricks you may not know that can make casting more magical. Chromecast Tips and Tricks You Didn’t Know 1. Enable Guest Mode 2. Make presentations 3. Play plenty of games 4. Cast videos using your voice 5. Stream live feeds from security cameras on your TV 6. Watch Amazon Prime Video on your TV 7. Create a casting queue 8. Cast Plex 9. Plug in your headphones 10. Share VR headset view with others 11. Cast on the go 12. Power on your TV 13. Get free movies and other perks Enable Guest Mode If you have guests over at your home, whether you’re hosting a family reunion, or have a party, you can let them cast their favorite music or TV shows onto your TV, without giving out your WiFi password. To do this, go to the Chromecast settings and enable Guest Mode. -

User Manual Introduction
Item No. 8015 User Manual Introduction Congratulations on choosing the Robosapien Blue™, a sophisticated fusion of technology and personality. With a full range of dynamic motion, interactive sensors and a unique personality, Robosapien Blue™ is more than a mechanical companion; he’s a multi-functional, thinking, feeling robot with attitude! Explore Robosapien Blue™ ’s vast array of functions and programs. Mold his behavior any way you like. Be sure to read this manual carefully for a complete understanding of the many features of your new robot buddy. Product Contents: Robosapien Blue™ x1 Infra-red Remote Controller x1 Pick Up Accessory x1 THUMP SWEEP SWEEP THUMP TALK BACKPICK UP LEAN PICK UP HIGH 5 STRIKE 1 STRIKE 1 LEAN THROW WHISTLE THROW BURP SLEEP LISTEN STRIKE 2 STRIKE 2 B U LL P D E O T Z S E R R E S E T P TU E R T N S S N T R E U P T STRIKE 3 R E S E R T A O R STRIKE 3 B A C K S S P T O E O P SELECT RIGHT T LEF SONIC DANCE D EM 2 EXECUTE O O 1 DEM EXECUTE ALL DEMO WAKE UP POWER OFF Robosapien Blue™ Remote Pick Up Controller Accessory For more information visit: www.wowwee.com P. 1 Content Introduction & Contents P.1-2 Battery Details P.3 Robosapien Blue™ Overview P.4 Robosapien Blue™ Operation Overview P.5 Controller Index P.6 RED Commands - Upper Controller P.7 RED Commands - Middle & Lower Controller P.8 GREEN Commands - Upper Controller P.9 GREEN Commands - Middle & Lower Controller P.10 ORANGE Commands - Upper Controller P.11 ORANGE Commands - Middle & Lower Controller P.12 Programming Mode - Touch Sensors P.13 Programming Mode - Sonic Sensor P.14 Programming Mode - Master Command P.15 Troubleshooting Guide P.16 Warranty P.17 App Functionality P.19 P. -

9 Movie Release Dates
Student Workbook 2nd edition www.bepublishing.com ©2011 b.e. Publishing, inc. All rights reserved. Student Workbook 2nd edition Published by Excel It! 2E • Student Workbook Permissions isbN: 1-934422-32-0 To use materials from this text, please contact us: Copyright © 2011 by b.e. Publishing, inc. b.e. Publishing, inc. All Rights Reserved. No part of this work covered by P.O. box 8558 copyright hereon may be reproduced or used in any Warwick, Ri 02888 form or by any means—including but not limited to u.s.A. graphic, electronic, or mechanical, including photocopy- ing, recording, taping, Web distribution, or information Tel: 888.781.6921 storage and retrieval systems—without the expressed Fax: 401.781.7608 written permission of the publisher. e-mail: [email protected] Editors All references made to specific software applications The development Team at b.e. Publishing and/or companies used within this book are registered Kathleen hicks trademarks of their respective companies. diane silvia linda Viveiros Printed in the u.s.A. Design Fernando botelho Acti vity Layout ACTIVITY 7 The GAP® New Skills New Skills Activity Overview Activity Overview Format cells as 1. he Gap® is a worldwide retail clothing store that off ers premium clothing numbers. Tand accessories. They provide consumers with a wide assortment of fresh, 2. Increase a cell’s casual, and American style clothing. The Gap® has everything people need to lists the new skill or skills decimal places. Provides a description of each activity, express a personal style. From jeans and T’s, to khakis and oxfords, the Gap® has fashion at great prices for adults, teens, kids, and babies. -

World Carillon Congress Antwerp – Bruges 6/29 – 7/6 2014 Protective Committee World Carillon Congress Antwerp/Bruges 2014
WORLD CARILLON CONGRESS ANTWERP – BRUGES 6/29 – 7/6 2014 Protective Committee World Carillon Congress Antwerp/Bruges 2014 Herman Van Rompuy, President European Council Kris Peeters, Minister-President Flemish Government Joke Schauvliege, Flemish Minister of Culture Cathy Berx, Governor Province Antwerp Carl Decaluwé, Governor Province West-Flanders Luc Lemmens, Representative for Culture - Province Antwerp Myriam Vanlerberghe, Representative for Culture - Province West-Flanders Bart De Wever, Mayor of the city of Antwerp Frank Bogaerts, Mayor of the city of Lier Renaat Landuyt, Mayor of the city of Brugge Roland Crabbe, Mayor of the city of Nieuwpoort Jan Durnez, Mayor of the city of Ieper Philip Heylen, Vice Mayor for Culture of the city of Antwerp Mieke Hoste, Alderman for Culture of the city of Brugge Jef Verschoore, Alderman for Culture of the city of Ieper Joachim Coens, Managing Director MBZ Paul Breyne, General Commissioner for the Commemoration of World War I in Belgium Dear congress participants, Tsar Peter the Great was inspired by the sound of the carillon in the low countries. Japanese tourists are fond of this instrument and two of the world’s most famous carillon- neurs come from Antwerp and are playing now carillon also abroad, one in St. Petersburg and one in Lake Wales, Florida. The carillon is an instrument of the world and thus it feels like the world of the carillon is coming home in our city. The city of Antwerp is greatly honored to host the World Carillon Congress 2014. Our city has a fascinating carillon history, which goes back to the end of the 15th century. -

Protect Yourself from These 5 Common Google Play Gift Card Scams
Protect Yourself From These 5 Common Google Play Gift Card Scams According to the FTC, $74.3M has been reported lost due to gift card and reload card scams in the first 9 months of this year (source). To help protect consumers against scams involving the Google Play gift card, Google is working to raise awareness and educate consumers on protecting themselves from gift card scams. Google Play is the official app store for Android smartphones and tablets. Google Play gift cards are easy-to-give gifts, but can only be used to purchase apps, movies, books, and other video game or app-related purchases through the Google Play store. But because Google Play gift cards are so easy to use, some bad actors request them as an alternative payment method in sophisticated scam scenarios. Don’t be misled. If anyone ever asks you to pay them with a Google Play gift card, it’s a scam. Period. 5 Common Google Play Gift Card Scam Scenarios: 1. IRS & Government You may get a phone call from someone claiming to be the IRS, police, or another official government entity. If this caller tries to scare you into buying gift cards as payment for back taxes or for other legal situations hang up the phone--this caller is a scammer. Even if the caller knows and recites the last four digits of your social security number, this is still a scam. The caller may become hostile or insulting and they may threaten you with arrest, deportation, or suspension of a business or driver’s license, etc. -
Youtube Premium App Download Redit Youtube Premium Review: I Finally Caved – Is It Worth It? Youtube Is One of the Most Popular Apps and Websites on the Web
youtube premium app download redit YouTube Premium Review: I Finally Caved – Is It Worth It? YouTube is one of the most popular apps and websites on the web. Around 2 billion people access YouTube every month . On top of that, around 73% of US adults use YouTube on a daily basis . YouTube is a big deal basically. And its main revenue is adverts – lots and lots of adverts. If you want to make adverts disappear on YouTube, you have to sign up for YouTube Premium. It costs £11.99 a month (though you do get a free 30-day trial) and this also gets you access to YouTube Music as well (you can also move all your music from Google Play Music over to YouTube Music too). I signed up for YouTube Premium a few weeks back to see if it was for me. I had grown tired of interacting with Google’s never-ending pop-up spam on the app which seemed to appear every single time I opened the app. Google broke me. I caved and signed up. What’s ironic about all this, however, is the Google actively penalizes websites that use similar marketing tactics online. They call it spamming. Apparently it’s OK when Google does it though. If you use YouTube regularly, you’ll know exactly what I’m talking about. You get pop-ups like the ones listed below pretty much every time you open the app… SIGN-UP TO YouTube Premium! Hey, try YouTube Premium for free Do you want YouTube Premium? YouTube Premium is ad-free Get YouTube Premium now. -

Google Pay-FAQ
Frequently Asked Questions 1. What is Google Pay? You can also open the Google Pay app, swipe left at the top to find the card you want to make default, then tap Pay Google Pay is a mobile payments app that can store your credit, debit, prepaid, loyalty Cards, etc. It is the fastest, simplest with this card 19. Can I continue to use Google Pay if my physical Credit / Debit / Prepaid card is due to expire? way to pay in millions of places – online, in stores. It brings together everything you need at checkout and protects your You can continue to use Google Pay till your card expiry date. Once you receive and activate your renewed card, you payment info with multiple layers of security. 9. Is Google Pay secure? will need to add it into Google Pay. Yes. Google Pay is secure because it processes transactions through a tokenisation service. This service replaces a 2. How do I set up Google Pay? Card’s primary account number with a random numerical sequence unique to a specific device, merchant, transaction 20. Will the card image in Google Pay match my physical card? •It only takes a few minutes to get up and running with Google Pay. type or channel. Actual account numbers are not stored on the device, or on mobile servers, and cashiers will no The card image may not be an exact match. Keep in mind this doesn't affect how your cards work with Google Pay. •Download the app on Google Play or the App Store, or visit pay.google.com. -

How Access Your Debit Card Using Apple, Google Or Samsung Pay
How Access your Debit Card using Apple, Google or Samsung Pay Apple Pay Open “Wallet” which is pre-installed on your phone. Tap the + button at the top-right of the screen to add one. If you don't have Touch ID setup yet, you'll be walked through registering your fingerprints. Next, use the camera viewfinder to scan in your card. Just center it in the frame and Apple Pay will grab all of the details, or you can enter them manually. Like with the other payment options, you'll need to verify your card using a text message or email code sent to you from your bank. Enter that and you're all set. To use Apple Pay while your phone is locked, just double tap the home button. It'll bring up your favorite debit or credit card, or you can select others at the bottom of the screen. Hold your finger to Touch ID as you tap the phone on an Apple Pay-approved reader. Google Pay Download Google Pay from the Google Play App Store. Open the app and tap "Add Credit or Debit card." You can choose cards already associated with your Google Account or add a new one. Agree to the terms and conditions that pop up. Then verify your card via email (you'll receive a number to enter into the app) That's it! Now, the next time you see a card reader with the Google Pay logo, just open the app, choose your card, and tap to pay. Samsung Pay Open up Samsung Pay, which should be pre-installed on your Samsung smartphone. -

Nexus 7 Guidebook Ii Table of Contents
For AndroidTM mobile technology platform 4.1 Copyright © 2012 Google Inc. All rights reserved. Google, Android, Gmail, Google Maps, Chrome, Nexus 7, Google Play, You- Tube, Google+, and other trademarks are property of Google Inc. A list of Google trademarks is available at http://www.google.com/permissions/ guidelines.html. ASUS and the ASUS logo are trademarks of ASUSTek Computer Inc. All other marks and trademarks are properties of their respective owners. The content of this guide may differ in some details from the product or its software. All information in this document is subject to change without notice. The Nexus 7 tablet is certified by ASUS under the name ASUS Pad ME370T. For online help and support, visit support.google.com/nexus. NEXUS 7 GUIDEBOOK ii Table of contents 1. Get started 1 Turn on & sign in 1 Charge the battery 2 Why use a Google Account? 3 Jelly Bean tips 4 2. Play & explore 7 Browse Home screens 7 Swipe up for Google Now 8 Swipe down for notifications 10 Get around 12 Touch & type 14 Try Face Unlock 15 3. Make yourself at home 16 Relax with Google Play 16 Manage downloads 19 Use apps 20 Organize your Home screens 21 Start Gmail 22 Find People 23 Manage your Calendar 24 Change sound settings 25 Change the wallpaper 25 NEXUS 7 GUIDEBOOK iii 4. Make Search personal 27 About Google Now 27 Use Google Now 30 Turn off Google Now 32 Control location reporting, history, & services 32 Search & Voice Actions basics 34 Search tips & tricks 36 Use Voice Actions 37 Voice Actions commands 38 Search settings 40 Privacy and accounts 42 5. -

Roborock S6 Pure Robot Vacuum Cleaner User Manual Read This User Manual Carefully Before Using This Product and Store It Properly for Future Reference
Roborock S6 Pure Robot Vacuum Cleaner User Manual Read this user manual carefully before using this product and store it properly for future reference. • Safety Information 1 • Table of Faults 5 • Product Introduction 6 • Installation 10 • Instructions for Use 14 • Routine Maintenance 18 • Environmental protection description 23 • Basic Parameters 24 • Troubleshooting 25 • FAQs 27 • EU Declaration of Conformity 29 • WEEE Information 32 • Warranty Information 33 Safety Information Restrictions • This product is designed for indoor floor cleaning only, do not use it outdoors (such as on an open-ended terrace), on any surface other than the ground (such as a sofa), or in any commercial or industrial environment. • Do not use this product on elevated surfaces without barriers such as the floor of a loft, an open-ended terrace, or on top of furniture. • Do not use the product when the ambient temperature is higher than 104°F (40°C), lower than 39°F (4°C), or if there are liquids or tacky substances on the floor. • Before using the product, move wires off the ground or place them to the side to prevent them being pulled on by the cleaner. • To prevent blocking the product and to avoid damage to valuables, remove light-weight items (such as plastic bags) and fragile objects (such as vases) from the floor before cleaning. • Children should be supervised to ensure that they do not play with the appliance. • This product is not intended for use by persons (including children) with reduced physical, sensory or mental capabilities, or lack of experience and knowledge,unless they have been given supervision or instruction concerning use of the product by a person responsible for their safety (CB).