Bayesian Analysis of Dyadic Data Arising in Basketball
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Georgia Tech in the 2001 Ncaa Tournament 2000-01 Georgia
GEORGIA TECH IN THE THE YELLOW JACKETS 2001 NCAA TOURNAMENT IN SAN DIEGO NCAA West First & Second Rounds ¥ San Diego, Calif. Facility Thursday, March 15 & Saturday, March 17 Cox Arena 5500 Canyon Crest Drive PRACTICE/PRESS CONFERENCE, Wednesday, March 14 San Diego, CA 92182 All Times Local (Pacific Standard) Phone: 619-594-0234 Georgia Tech Press Conference, 1:30-2:00 p.m. Georgia Tech Practice, 2:10-3:00 p.m. Team Hotel: Town and Country Resort FIRST ROUND PAIRINGS, Thursday, March 15 500 Hotel Circle North All Times Local (Pacific Standard) San Diego, CA 92108 #8 Georgia Tech (17-12) vs. #9 St. Joseph’s (25-6), 11:42 a.m. Phone: 619-297-6006 #1 Stanford (28-2) vs. #16 UNC Greensboro (19-11), 30 min. following Fax: 619-294-5957 #4 Indiana (21-12) vs. #13 Kent State (23-9), 4:55 p.m. #5 Cincinnati (23-9) vs. #12 Brigham Young (23-8), 25 min. following SID: Mike Stamus cell: 404-218-9723 SECOND ROUND, Saturday, March 17 [email protected] All Times Local (Pacific Standard) Assoc. SID: Allison George Cincinnati-Brigham Young winner vs. Indiana-Kent State winner, cell: 678-595-7728 2:38 p.m. [email protected] Stanford-UNC Greensboro winner vs. Georgia Tech-St. Joseph’s winner, 30 min. following Media Hotel: San Diego Marriott Mission Valley 2000-01 GEORGIA TECH ROSTER 8757 Rio San Diego Drive No. Name Pos. Ht. Wt. Cl. Hometown (High School/College) San Diego, CA 92108 2 Darryl LaBarrie G 6-3 196 Sr.-R Decatur, Ga. -

Probable Starters
UTAH JAZZ (35-30) at MEMPHIS GRIZZLIES (18-46) Game #66 • ROAD Game #34 • FedExForum • MEMPHIS March 9, 2018 • 6 p.m. (MT) • TV: AT&T SportsNet RADIO: 1280 AM/97.5 FM DATE OPP. TIME (MT) RECORD/TV 10/18 DEN W, 106-96 1-0 10/20 @MIN L, 97-100 1-1 LAST GAME’S STARTERS (2017-18 averages) 10/21 OKC W, 96-87 2-1 10/24 @LAC L, 84-102 2-2 • Notched first career double-double (11 points, 10/25 @PHX L, 88-97 2-3 career-high 10 assists) at IND on 3/7 10/28 LAL W, 96-81 3-3 PPG • 10.9 10/30 DAL W, 104-89 4-3 2 • Second in the league in three-point 11/1 POR W, 112-103 (OT) 5-3 RPG • 4.1 percentage (.445) 11/3 TOR L, 100-109 5-4 JOE INGLES • Has eight games this season with 5+ 3FG 11/5 @HOU L, 110-137 5-5 11/7 PHI L, 97-104 5-6 F • 6-8 • 226 • Australia APG • 4.3 • Appeared in his 200th straight game on 2/24 11/10 MIA L, 74-84 5-7 vs. DAL 11/11 BKN W, 114-106 6-7 11/13 MIN L, 98-109 6-8 • Has made a three-pointer in consecutive 11/15 @NYK L, 101-106 6-9 PPG • 12.2 games for just the second time in his career 11/17 @BKN L, 107-118 6-10 15 11/18 @ORL W, 125-85 7-10 RPG • 7.4 • Ranks seventh in Jazz history in blocked shots 11/20 @PHI L, 86-107 7-11 DERRICK FAVORS (641) 11/22 CHI W, 110-80 8-11 Jazz are 11-3 when he records a double- 11/25 MIL W, 121-108 9-11 • APG • 1.3 11/28 DEN W, 106-77 10-11 F • 6-10 • 265 • Georgia Tech double 11/30 @LAC W, 126-107 11-11 st 12/1 NOP W, 114-108 12-11 • Posted his 21 double-double of the season 12/4 WAS W, 116-69 13-11 27 PPG • 13.6 (23 points and 14 rebounds) at IND (3/7) 12/5 @OKC L, 94-100 13-12 • Made a career-high 12 free throws and scored 12/7 HOU L, 101-112 13-13 RPG • 10.5 12/9 @MIL L, 100-117 13-14 RUDY GOBERT a season-high 26 points vs. -
Quizinfo Level
Accelerated Reader Test List Report Sort – Reading Level then Book Title Test Book Reading Point Number Title Author Level Value -------------------------------------------------------------------------- 41850EN Clifford Makes a Friend Norman Bridwell 0.4 0.5 64100EN Daniel's Pet Alma Flor Ada 0.5 0.5 35988EN The Day I Had to Play with My Si Crosby Bonsall 0.5 0.5 31542EN Mine's the Best Crosby Bonsall 0.5 0.5 58671EN I Am Water Jean Marzollo 0.6 0.5 88312EN Puppy Mudge Wants to Play Cynthia Rylant 0.6 0.5 59439EN Rosie's Walk Pat Hutchins 0.6 0.5 31610EN Here Comes the Snow Angela Shelf Medea 0.7 0.5 31613EN Itchy, Itchy Chicken Pox Grace Maccarone 0.7 0.5 9366EN The Golden Goose Margaret Hillert 0.8 0.5 84920EN Sid's Surprise Candace Carter 0.8 0.5 72788EN Don't Let the Pigeon Drive the B Mo Willems 0.9 0.5 114579EN Dora Helps Diego! Laura Driscoll 0.9 0.5 6494EN Gone Fishing Earlene Long 0.9 0.5 44651EN Mouse in Love Robert Kraus 0.9 0.5 5456EN Are You My Mother? P.D. Eastman 1.0 0.5 21245EN Arthur Tricks the Tooth Fairy Marc Brown 1.0 0.5 106265EN Biscuit Visits the Big City Alyssa Satin Capuc 1.0 0.5 104090EN Click, Clack, Splish, Splash: A Doreen Cronin 1.0 0.5 31600EN Harry Takes a Bath Harriet Ziefert 1.0 0.5 31601EN My Loose Tooth Stephen Krensky 1.0 0.5 113649EN Pigs Emily K. -

Set Info - Player - National Treasures Basketball
Set Info - Player - National Treasures Basketball Player Total # Total # Total # Total # Total # Autos + Cards Base Autos Memorabilia Memorabilia Luka Doncic 1112 0 145 630 337 Joe Dumars 1101 0 460 441 200 Grant Hill 1030 0 560 220 250 Nikola Jokic 998 154 420 236 188 Elie Okobo 982 0 140 630 212 Karl-Anthony Towns 980 154 0 752 74 Marvin Bagley III 977 0 10 630 337 Kevin Knox 977 0 10 630 337 Deandre Ayton 977 0 10 630 337 Trae Young 977 0 10 630 337 Collin Sexton 967 0 0 630 337 Anthony Davis 892 154 112 626 0 Damian Lillard 885 154 186 471 74 Dominique Wilkins 856 0 230 550 76 Jaren Jackson Jr. 847 0 5 630 212 Toni Kukoc 847 0 420 235 192 Kyrie Irving 846 154 146 472 74 Jalen Brunson 842 0 0 630 212 Landry Shamet 842 0 0 630 212 Shai Gilgeous- 842 0 0 630 212 Alexander Mikal Bridges 842 0 0 630 212 Wendell Carter Jr. 842 0 0 630 212 Hamidou Diallo 842 0 0 630 212 Kevin Huerter 842 0 0 630 212 Omari Spellman 842 0 0 630 212 Donte DiVincenzo 842 0 0 630 212 Lonnie Walker IV 842 0 0 630 212 Josh Okogie 842 0 0 630 212 Mo Bamba 842 0 0 630 212 Chandler Hutchison 842 0 0 630 212 Jerome Robinson 842 0 0 630 212 Michael Porter Jr. 842 0 0 630 212 Troy Brown Jr. 842 0 0 630 212 Joel Embiid 826 154 0 596 76 Grayson Allen 826 0 0 614 212 LaMarcus Aldridge 825 154 0 471 200 LeBron James 816 154 0 662 0 Andrew Wiggins 795 154 140 376 125 Giannis 789 154 90 472 73 Antetokounmpo Kevin Durant 784 154 122 478 30 Ben Simmons 781 154 0 627 0 Jason Kidd 776 0 370 330 76 Robert Parish 767 0 140 552 75 Player Total # Total # Total # Total # Total # Autos -

Revista Del Baloncesto Superior Nacional
Revista del Baloncesto Superior Nacional www.bsnpr.com 1-15 de julio - 2011 | Vol. VII 2 | TODO BASKET GRAN ANGULAR 1 - 15 | JULIO | 2011 1 - 15 | JULIO | 2011 GRAN ANGULAR TODO BASKET | 3 Mezcla de Juventud y Veteranía POR: Mario García | de Todo Basket ‘Bimbo’ Carmona. “Yo creo que es una mezcla interesante de juventud y veteranía”, comentó el piloto nacional Flor Meléndez, “y vamos a tratar de ver cómo podemos combinar eso. He hablado con la mayoría de esos jugadores y todos me han dicho que van a estar disponibles”. Como se esperaba, el listado lo encabezan los armadores Carlos Arroyo y José Juan Barea y el centro Peter John Ramos. El base Filiberto Rivera y los escoltas Guillermo Díaz y David Huertas también fueron incluidos, así como los aleros Angel LEE: AGILIDAD Y DESPEGUE FLOR Y BAREA SE REÚNEN NUEVAMENTE, YA QUE ESTUVIERON JUNTOS EN MAYAGÜEZ Y SANTURCE DÍAZ:ESTUVO EN EL MUNDIAL DE TURQUÍA l listado de 12 canasteros que integraron el Equipo La Federación de Baloncesto de Puerto Rico incluyó un gran total Nacional en el pasado Campeonato Mundial celebrado en Turquía, se le agregaron nuevas figuras en el de 25 canasteros en la Preselección Nacional, con miras a su armador Denis Clemente, los escoltas Johwen Villegas, AJohn Holland y Carlos Strong, los delanteros Alex Galindo, Angel ‘Piwi’ García, Víctor Dávila y el centro Jorge Bryan Díaz. participación en el Torneo Preolímpico de Las Américas que se jugará Otros jóvenes veteranos que han formado parte de la Selección o Preselección Nacional en el pasado también fueron convoca- en agosto y septiembre próximos en Mar del Plata, Argentina. -

Records All-Time Pistons Team Records All-Time Pistons Team Records
RECORDS ALL-TIME PISTONS TEAM RECORDS ALL-TIME PISTONS TEAM RECORDS SINGLE SEASON SINGLE GAME OR PORTION (CONTINUED) Most Points 9,725 1967-68 Steals 877 1976-77 MOST THREE-POINT FIELD GOALS ATTEMPTED Highest Scoring Average 118.6 1967-68 Blocked Shots 572 1982-83 LEADERSHIP Lowest Defensive Average 84.3 2003-04 Most Turnovers 1,858 1977-78 Game 47 at Memphis Apr. 8, 2018 Field Goals 3,840 1984-85 Fewest Turnovers *931 2005-06 Half 28 vs. Atlanta (2nd) Jan. 9, 2015 Field Goals Attempted 8,502 1965-66 Most Victories 64 2005-06 Quarter 15 vs. Atlanta (4th) Jan. 9, 2015 Field Goal % .494 1988-89 Fewest Victories 16 1979-80 MOST REBOUNDS Free Throws 2,408 1960-61 Best Winning % .780 (64-18) 2005-06 Game 107 vs. Boston (at New York) (OT) Nov. 15, 1960 Free Throws Attempted 3,220 1960-61 Poorest Winning % .195 (16-66) 1979-80 Half 52 vs. Seattle (2nd) Jan. 19, 1968 Free Throw % .788 1984-85 Most Home Victories 37 (of 41) 1988-89; 2005-06 Quarter 38 vs. St. Louis (at Olympia) (2nd) Dec. 7, 1960 Three-Point Field Goals 993 2018-19 Fewest Home Victories 9 (of 30) 1963-64 Three-Point Field Goals Attempted 2,854 2018-19 Most Road Victories 27 (of 41) 2005-06; 2006-07 MOST OFFENSIVE REBOUNDS 3-Point Field Goal % .404 1995-96 Fewest Road Victories 3 (of 19) 1960-61 Game 36 at L.A. Lakers Dec. 14, 1975 Most Rebounds 5,823 1961-62 3 (of 38) 1979-80 Half 19 vs. -

Fastest 40 Minutes in Basketball, 2012-2013
University of Arkansas, Fayetteville ScholarWorks@UARK Arkansas Men’s Basketball Athletics 2013 Media Guide: Fastest 40 Minutes in Basketball, 2012-2013 University of Arkansas, Fayetteville. Athletics Media Relations Follow this and additional works at: https://scholarworks.uark.edu/basketball-men Citation University of Arkansas, Fayetteville. Athletics Media Relations. (2013). Media Guide: Fastest 40 Minutes in Basketball, 2012-2013. Arkansas Men’s Basketball. Retrieved from https://scholarworks.uark.edu/ basketball-men/10 This Periodical is brought to you for free and open access by the Athletics at ScholarWorks@UARK. It has been accepted for inclusion in Arkansas Men’s Basketball by an authorized administrator of ScholarWorks@UARK. For more information, please contact [email protected]. TABLE OF CONTENTS This is Arkansas Basketball 2012-13 Razorbacks Razorback Records Quick Facts ........................................3 Kikko Haydar .............................48-50 1,000-Point Scorers ................124-127 Television Roster ...............................4 Rashad Madden ..........................51-53 Scoring Average Records ............... 128 Roster ................................................5 Hunter Mickelson ......................54-56 Points Records ...............................129 Bud Walton Arena ..........................6-7 Marshawn Powell .......................57-59 30-Point Games ............................. 130 Razorback Nation ...........................8-9 Rickey Scott ................................60-62 -

2019-20 Panini Flawless Basketball Checklist
2019-20 Flawless Basketball Player Card Totals 281 Players with Cards; Hits = Auto+Auto Relic+Relic Only **Totals do not include 2018/19 Extra Autographs TOTAL TOTAL Auto Relic Block Team Auto HITS CARDS Relic Only Chain A.C. Green 177 177 177 Aaron Gordon 141 141 141 Aaron Holiday 112 112 112 Admiral Schofield 77 77 77 Adrian Dantley 115 115 59 56 Al Horford 385 386 177 169 39 1 Alex English 177 177 177 Allan Houston 236 236 236 Allen Iverson 332 387 295 1 36 55 Allonzo Trier 286 286 118 168 Alonzo Mourning 60 60 60 Alvan Adams 177 177 177 Andre Drummond 90 90 90 Andrea Bargnani 177 177 177 Andrew Wiggins 484 485 118 225 141 1 Anfernee Hardaway 9 9 9 Anthony Davis 453 610 118 284 51 157 Arvydas Sabonis 59 59 59 Avery Bradley 118 118 118 B.J. Armstrong 177 177 177 Bam Adebayo 92 92 92 Ben Simmons 103 132 103 29 Bill Bradley 9 9 9 Bill Russell 186 213 177 9 27 Bill Walton 59 59 59 Blake Griffin 90 90 90 Bob McAdoo 177 177 177 Bobby Portis 118 118 118 Bogdan Bogdanovic 230 230 118 112 Bojan Bogdanovic 90 90 90 GroupBreakChecklists.com 2019-20 Flawless Basketball Player Card Totals TOTAL TOTAL Auto Relic Block Team Auto HITS CARDS Relic Only Chain Bradley Beal 93 95 93 2 Brandon Clarke 324 434 59 226 39 110 Brandon Ingram 39 39 39 Brook Lopez 286 286 118 168 Buddy Hield 90 90 90 Calvin Murphy 236 236 236 Cam Reddish 380 537 59 228 93 157 Cameron Johnson 290 291 225 65 1 Carmelo Anthony 39 39 39 Caron Butler 1 2 1 1 Charles Barkley 493 657 236 170 87 164 Charles Oakley 177 177 177 Chauncey Billups 177 177 177 Chris Bosh 1 2 1 1 Chris Kaman -

For Release, December 16, 1998 Contact
FOR IMMEDIATE RELEASE Contact: Julie Mason (412-496-3196) GATORADE® NATIONAL BOYS BASKETBALL PLAYER OF THE YEAR: BRANDON KNIGHT Former Miami Heat Center and Gatorade Boys Basketball Player of the Year Alonzo Mourning Surprises Standout with Elite Honor FORT LAUDERDALE, Fla. (March 23, 2010) – In its 25th year of honoring the nation’s best high school athletes, The Gatorade Company, in collaboration with ESPN RISE, today announced Brandon Knight of Pine Crest School (Fort Lauderdale, Fla.) as its 2009-10 Gatorade National Boys Basketball Player of the Year. Knight was surprised with the news during his second period class at Pine Crest School by former Miami Heat Center Alonzo Mourning, who earned Gatorade National Boys Basketball Player of the Year honors in 1987-88. “When I received this award in 1988, it was a really significant moment for me, so it felt great to surprise Brandon with the news and invite him into one of the most prestigious legacy programs in high school sports,” said Mourning, a Gold Medalist, seven-time NBA All-Star, and two-time NBA Defensive Player of the Year. “Gatorade has been on the sidelines fueling athletic performance for years, so to be recognized by a brand that understands the game and truly helps athletes perform is a huge honor for these kids.” Knight becomes the first-ever student athlete from the state of Florida to repeat as Gatorade National Player of the Year in any sport. He joins 2009 NBA MVP LeBron James (2002-03 & 2001-02, St. Vincent-St. Mary, Akron, Ohio) and 2007 NBA Draft Number One Overall Pick Greg Oden (2005-06 & 2004-05, Lawrence North, Indianapolis, Ind.) as the only student-athletes to win Gatorade National Boys Basketball Player of the Year honors in consecutive seasons. -
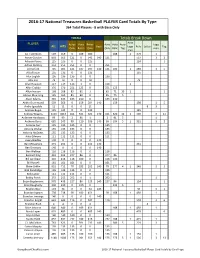
2016-17 National Treasures Basketball PLAYER Card Totals by Type 364 Total Players - 8 with Base Only
2016-17 National Treasures Basketball PLAYER Card Totals By Type 364 Total Players - 8 with Base Only TOTALS Totals Break Down Auto PLAYER Autos Auto Relics Auto Auto Auto Logo ALL HITS Base Logo Relic Letter Tag Only Relics Only Only Relic Tag man man A.J. Hammons 569 569 0 189 380 188 1 379 1 Aaron Gordon 803 663 121 0 542 140 121 537 3 2 Adreian Payne 125 125 0 0 125 124 1 Adrian Dantley 251 251 251 0 0 251 Al Horford 745 605 121 187 297 140 121 186 1 289 3 5 Al Jefferson 135 135 0 0 135 135 Alex English 136 136 136 0 0 136 Alex Len 79 79 0 0 79 79 Allan Houston 117 117 116 1 0 116 1 Allen Crabbe 376 376 251 125 0 251 125 Allen Iverson 168 168 85 82 1 85 71 10 1 1 Alonzo Mourning 165 165 85 80 0 85 75 5 Alvan Adams 345 345 135 210 0 135 210 Andre Drummond 503 363 0 159 204 140 159 198 1 5 Andre Iguodala 11 11 0 0 11 8 3 Andrew Bogut 135 135 0 0 135 135 Andrew Wiggins 1153 1013 161 331 521 140 161 320 10 1 507 3 11 Anfernee Hardaway 99 99 2 96 1 2 91 5 1 Anthony Davis 685 545 99 110 336 140 99 104 5 1 331 3 2 Antoine Carr 135 135 135 0 0 135 Antoine Walker 135 135 135 0 0 135 Antonio McDyess 135 135 135 0 0 135 Artis Gilmore 111 111 111 0 0 111 Avery Bradley 140 0 0 0 0 140 Ben McLemore 371 231 0 0 231 140 231 Ben Simmons 140 0 0 0 0 140 Ben Wallace 116 116 116 0 0 116 Bernard King 333 333 247 86 0 247 86 Bill Laimbeer 216 216 116 100 0 116 100 Bill Russell 161 161 161 0 0 161 Blake Griffin 852 712 78 282 352 140 78 277 4 1 346 3 3 Bob Dandridge 135 135 135 0 0 135 Bob Lanier 111 111 111 0 0 111 Bobby Portis 253 253 252 0 1 252 1 Bojan Bogdanovic 578 438 227 86 125 140 227 86 124 1 Brad Daugherty 230 230 0 230 0 225 5 Bradley Beal 174 34 0 0 34 140 30 3 1 Brandon Ingram 738 738 98 189 451 98 188 1 450 1 Brandon Jennings 140 0 0 0 0 140 Brandon Knight 643 643 116 0 527 116 518 3 6 Brandon Rush 4 4 0 0 4 4 Brice Johnson 640 640 0 189 451 188 1 450 1 Brook Lopez 625 485 0 0 485 140 479 6 Bryn Forbes 140 140 140 0 0 140 Buddy Hield 837 837 232 189 416 232 188 1 415 1 C.J. -

Page 3, Xx/Xx.Qxd
LOCAL/OP-ED The Gardner News, Weekend, July 10-11, 2010 - 3 LeBron hourlong show brings end to free agent ‘decision’ circus ven with six possible and come away confident of a If James wanted to take on a dusting off Isiah Thomas. This spotlight with two other stars: Celtics’ fold three years ago, the destinations that free return. Hurculean challenge, Clipper-land was the same embarrassment, Dwyane Wade, who has been in two and Pierce were tagged with a Eagent LeBron James was That leaves the other five, who was certainly beckoning, but who as president was pushed out Miami for his each of his seven familiar nickname from the 1980s purportedly “considering” as worked themselves into a lather to many a player has headed to that the door two years ago by the years and earned one ring, and when Larry Bird, Kevin McHale cities where to continue his NBA have enough cap room to sign sad franchise, only to quickly dis- Knicks with an agreement pre- Chris Bosh, another top free agent and Robert Parish were running career, his self-aggrandizing James to a maximum deal, or at cover that only miracles akin to venting him from contacting signee from Toronto, likely mean- the parquet floor in Boston: The ESPN special Thursday night least close to one. turning water into wine might Knicks players. With all other ing that their power has likely dis- Big Three. proved to be the cherry on top, make the Clippers a .500 fran- NBA teams scared at the prospect appeared. Move the clock to the begin- reaching new levels of how a ON THE SUBJECT OF chise. -

Brilliant Bryant Energizes Lakers Push
SPORTS CHINA DAILY WEDNESDAY MARCH 28, 2007 23 TOPSHOT Brilliant Bryant energizes Lakers push Maradona movie set for Italian release ROME: A movie biopic based on the rise and fall of Argentine football Kobe scoring consistently high to keep legend Diego Maradona is set to be released in cinemas throughout his team on course for playoff berth Italy on Friday. Directed by Marco Risi, Maradona La LOS ANGELES: Los Angeles Lakers the court.” Mano di Dio, or The Hand of God, the superstar Kobe Bryant, stung by two Even more important, however, phrase the Argentine used to explain National Basketball Association sus- is that Bryant’s heroics have turned how he scored a controversial goal pensions, has responded by writing things around for a Lakers team that against England with his hand in the himself into the record books. had fallen to 33-32 as they battled to 1986 World Cup quarter-fi nals, takes Last week Bryant joined Wilt overcome injuries to four key players. in different phases of the player’s life Chamberlain as the only player in Bryant’s 65-point outburst against including his drug problems. NBA history to record four or more Portland on March 16 saw the team Risi said that he wanted to show the straight games of 50 points or more. end a seven-game losing streak. humanity of a player regarded as In the process he turned in per- “If we don’t win games now, we one of the all-time greats, but who formances of 65 and 60 points, tying miss the playoffs, which means we’re has battled drugs and ill health.