Unsupervised Construction of a Product Knowledge Graph
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Surface Book 2 Technical Specification
Head Office: CCS Media Ltd, Old Birdholme House, Derby Road, Chesterfield, Derbyshire, S40 2EX Surface Book 2 Technical Specification Dimensions Memory Warranty • Surface Book 2 13.5″ • Surface Book 2 13.5″ • 1-year limited hardware warranty • i5: 12.3″ x 9.14″ x 0.51″-0.90″ (312mm x • 8GB or 16GB RAM 1866MHz LPDDR3 • Connections 232mm x 13 mm-23mm) • Surface Book 2 15″ • 2 x USB type-A (version 3.1 Gen 1) • i7: 12.3″ x 9.14″ x 0.59″-0.90″ (312mm x • 16GB RAM 1866MHz LPDDR3 • 1 x USB type-C (version 3.1 Gen 1 with 232mm x 15mm-23mm) USB Power Delivery revision 3.0) • Surface Book 2 15″ • 3.5mm headphone jack • 13.5″ x 9.87″ x 0.568-0.90″ (343mm x Graphics • 2 x Surface Connect ports 251mm x 15mm- 23mm) • Surface Book 2 13.5″ PixelSense™ Display • Full-size SDXC card reader • Intel® HD Graphics 620 integrated GPU • Compatible with Surface Dial* on- and (on Intel® i5-7300U model) off-screen interaction Storage3 • NVIDIA® GeForce® GTX 1050 discrete • Solid state drive (SSD) options: 256GB, GPU w/2GB GDDR5 graphics memory 512GB or 1TB PCIe SSD (on Intel® i7-8650U models) Security • Surface Book 2 15″ PixelSense™ Display • HW TPM 2.0 chip for enterprise security • NVIDIA® GeForce® GTX 1060 discrete • Enterprise-grade protection with Display GPU w/6GB GDDR5 graphics memory Windows Hello face sign-in • Surface Book 2 13.5″ PixelSense™ Display • • Cameras, video and audio • Screen: 13.5″ PixelSense™ Display Processor • Windows Hello face authentication • Resolution: 3000 x 2000 (267 PPI) • Surface Book 2 13.5″ camera (front-facing) • Aspect ratio: -

Meet Surface Book 2 Surface Product Marketing Using Meet Surface Book 2
Meet Surface Book 2 Surface Product Marketing Using Meet Surface Book 2 • This deck is the single source of product truth for those who want to tell the Surface Book 2 story in a compelling and consistent way • It is partner ready and can be used both internally and externally beginning October 17, 2017 • The copy should not be used as consumer facing messaging for marketing or advertising execution • Please visit Brand Central for approved copy and marketing guidelines • Edition: Last updated February 2018 • Updated 4Rs • Updated family slide • Updated POR The role of Surface at Microsoft Create and evolve categories to Bring the best of Microsoft Compete with Apple inspire innovation in the together and drive post sales in the premium market Windows ecosystem monetization and service usage Classified as Microsoft Highly Confidential The Surface Portfolio | 4 Reasons The ultimate laptop High Most versatile Innovative design Best of Microsoft performance Devices that transform from laptop to tablet The performance to run the most Every detail matters — clean corners, Designed by Microsoft, Surface is — desktop to studio — and everything in demanding professional apps as well as stunning touchscreens, rich colors, and the engineered to deliver the best Office and between. Plus creative tools like Surface games and 4K entertainment — all on highest-quality materials. Complement your Windows experience, and supported by Pen and Surface Dial. So you’re free to stunning PixelSense™ displays designed to style and preferences with the ultimate world-class customer care, so you can discover new ways to create, learn, be viewed, touched, and written on. -

Years 2018, 2017, and 2016, Research and Development Expense Was $14.7 Billion, $13.0 Billion, and $12.0 Billion, Respectively
UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, D.C. 20549 FORM 10-K ☒ ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the Fiscal Year Ended June 30, 2018 OR ☐ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the Transition Period From to Commission File Number 001-37845 MICROSOFT CORPORATION WASHINGTON 91-1144442 (STATE OF INCORPORATION) (I.R.S. ID) ONE MICROSOFT WAY, REDMOND, WASHINGTON 98052-6399 (425) 882-8080 www.microsoft.com/investor Securities registered pursuant to Section 12(b) of the Act: COMMON STOCK, $0.00000625 par value per share NASDAQ Securities registered pursuant to Section 12(g) of the Act: NONE Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. Yes ☒ No ☐ Indicate by check mark if the registrant is not required to file reports pursuant to Section 13 or Section 15(d) of the Exchange Act. Yes ☐ No ☒ Indicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. Yes ☒ No ☐ Indicate by check mark whether the registrant has submitted electronically and posted on its corporate website, if any, every Interactive Data File required to be submitted and posted pursuant to Rule 405 of Regulation S-T (§232.405 of this chapter) during the preceding 12 months (or for such shorter period that the registrant was required to submit and post such files). -

Surface Book 2 Tech Specs
Surface Book 2 tech specs Take a look at this table for all the tech specs. Everything you need to know about unleashing the power of Surface Book 2 can be found right here. Display Storage Dimensions Connections 13.5” or 15” PixelSense™ 256GB, 512GB, or 1TB PCIe SSD. Surface Book 2 13.5": 2 x full-size USB 3.1 Gen 1, 1 x Display with up to 3240 x 2160 2 i5: 12.3” x 9.14” x 0.51”-0.90” USB-C, 3.5mm headphone jack, resolution, 3:2 aspect ratio, 10 (312 mm x 232 mm x 13 mm-23 2 x Surface Connect ports (1 in point multi-touch, and ink. mm) tablet, 1 in base), full-size SDXC i7: 12.3” x 9.14” x 0.59”-0.90” card reader. (312 mm x 232 mm x 15 mm-23 mm) Surface Book 2 15": 13.5” x 9.87” x 0.568-0.90” (343 mm x 251 mm x 15 mm-23 mm) Tech specs Dimensions Surface Book 2 13.5” Storage 2 Solid state drive (SSD) i5: 12.3” x 9.14” x 0.51”-0.90” (312 options: 256GB, 512GB, or mm x 232 mm x 13 mm-23 mm) 1TB PCIe SSD i7: 12.3” x 9.14” x 0.59”-0.90” (312 mm x 232 mm x 15 mm-23 mm) Surface Book 2 15” 13.5” x 9.87” x 0.568-0.90” (343 mm x 251 mm x 15 mm-23 mm) Display Battery life Up to 17 hours of video Surface Book 2 13.5” playback 1 PixelSense™ Display Screen: 13.5” PixelSense™ Display Resolution: 3000 x 2000 (267 PPI) Aspect ratio: 3:2 Contrast ratio: 1600:1 Touch: 10 point multi-touch G5 Surface Book 2 15” PixelSense™ Display Screen: 15” PixelSense™ Display Resolution: 3240 x 2160, (260 PPI) 10 point multi-touch G5 Aspect ratio: 3:2 Contrast ratio: 1600:1 Memory Surface Book 2 13.5” Graphics Surface Book 2 13.5” 8GB or 16GB RAM 1866Mhz PixelSense™ -

View Annual Report
Dear shareholders, customers, partners and employees: As I reflect on our progress this past year, I first want to say thank you for your commitment and investment in Microsoft. I’m proud of what we’ve accomplished together as we innovate and help customers navigate their digital transformation, and I am even more optimistic about the opportunity ahead. We are living at a crucial time in history where the impact of technology on every part of our daily life and work and every aspect of our society and economy is more acute than ever before. It is incumbent upon leaders of our industry to ensure that the technology we build always creates opportunity. Too often, we celebrate technology disruption for the sake of disruption without reflecting on its unintended consequences. What the world needs is technology that benefits people and society more broadly and is trusted. Our mission is to empower every person and every organization on the planet to achieve more. Our business model is dependent on our customers’ and partners’ success. We are grounded in creating local economic opportunity in every community, helping to unlock the power of technology to address our customers’ most pressing challenges. Our platforms and tools enable creativity in all of us. They help drive small-business productivity, large business competitiveness and public-sector efficiency. They also support new startups, improve educational and health outcomes, and empower human ingenuity. Our sense of purpose lies in our customers’ success. Our culture enables us to pursue our mission with a growth mindset. It’s a continuous practice of learning, renewal and having the courage to confront our own fixed mindsets. -

A Modern Desktop and Beyond
Your journey to A MODERN DESKTOP AND BEYOND How businesses can evolve their security, productivity and connectivity with modern IT. CONTENT 01 The cloud, IT management and your Windows of opportunity 02 What Windows 7 end of life means for your business 03 What does Windows 7 end of support mean? 04 What is a modern desktop? 05 The benefits of a modern desktop 06 The benefits of Microsoft 365 on Surface devices 07 Beneath the Surface of the modern desktop 08 Begin on your journey to Microsoft 365 on Surface 01 THE CLOUD, This eBook looks to demystify these areas, explaining why and how small to medium- IT MANAGEMENT sized businesses (SMBs) should make AND YOUR the shift to a modern desktop. Not only to overcome Windows 7 End of Support WINDOWS OF (EOS), but to gain all the benefits of the OPPORTUNITY cloud without the hassle of a migration. According to NetMarketShare1, Windows 7 However, Windows 7 will soon be remains a hair’s width ahead of Windows superseded by Windows 10 as the most 10 as the most-used operating system by popular operating system by user count. version (38.89% vs 38.14%, respectively). In fact, it’s likely to occur around the same time as Windows 7 reaches end of support Despite being released almost 10 years (EOS) on January 14th, 2020. It’s at this ago, it’s understandable that Windows point where Microsoft will discontinue 7 remains such a prominent operating support for Windows 7 and SMBs still system. Windows 7 remains more than running the operating system must capable of running business operations consider how they can upgrade their IT smoothly. -
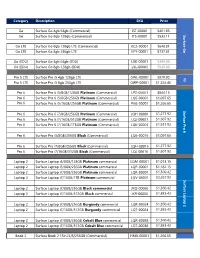
Microsoft-Surface-Price-List.Pdf
Category Description SKU Price Go Surface Go 4gb 64gb (Commercial) JST-00001 $401.85 Go Surface Go 8gb 128gb (Commercial) JTS-00001 $533.11 Surface Go Go LTE Surface Go 8gb 128gb LTE (Commercial) KC2-00001 $648.81 Go LTE Surface Go 8gb 256gb LTE KFY-00001 $737.81 Go (EDU) Surface Go 4gb 64gb (EDU) LXK-00001 $399.00 Go (EDU) Surface Go 8gb 128gb (EDU) LXL-00001 $549.00 Pro 5 LTE Surface Pro i5 4gb 128gb LTE GWL-00001 $970.90 V5 Pro 5 LTE Surface Pro i5 8gb 256gb LTE GWP-00001 $1,224.40 Pro 6 Surface Pro 6 i5/8GB/128GB Platinum (Commercial) LPZ-00001 $844.15 Pro 6 Surface Pro 6 i5/8GB/256GB Platinum (Commercial) LQ6-00001 $1,097.65 Pro 6 Surface Pro 6 i5/16GB/256GB Platinum (Commercial) P6G-00001 $1,266.65 Surface Pro 6 Surface Pro Pro 6 Surface Pro 6 i7/8GB/256GB Platinum (Commercial) LQH-00001 $1,277.92 Pro 6 Surface Pro 6 i7/16GB/512GB Platinum (Commercial) LQJ-00001 $1,607.92 Pro 6 Surface Pro 6 i7/16GB/1TBGB Platinum (Commercial) LQK-00001 $1,937.92 Pro 6 Surface Pro i5/8GB/256GB Black (Commercial) LQ6-00016 $1,097.65 Pro 6 Surface Pro i7/8GB/256GB Black (Commercial) LQH-00016 $1,277.92 Pro 6 Surface Pro i7/16GB/512GB Black (Commercial) LQJ-00016 $1,607.92 Laptop 2 Surface Laptop i5/8GB/128GB Platinum commercial LQM-00001 $1,013.15 Laptop 2 Surface Laptop i5/8GB/256GB Platinum commercial LQP-00001 $1,182.15 Laptop 2 Surface Laptop i7/8GB/256GB Platinum commercial LQR-00001 $1,360.42 Laptop 2 Surface Laptop i7/16GB/1TB Platinum commercial LQV-00001 $2,267.92 Surface Laptop 2 Laptop Surface Laptop 2 Surface Laptop i7/8GB/256GB Black commercial -

Material Safety Data Sheets (MSDS)/Safety Data Sheets (SDS) Are Required by Various National and International Occupational Worker Safety Regulations
Product Data Sheet Section I – Product and Company Information Product: Lithium ion and Lithium ion polymer batteries Manufacturer: Models: See Microsoft Product Battery Information Table, Section 14 Microsoft Corporation Effective Date: January 10, 2020 One Microsoft Way Version: 2020A Redmond, WA 98052-6399 Tel 425 882 8080 Section II – Composition Information Not chemically dangerous during normal use in accordance with Microsoft recommendations as stated in the user manuals or other similar documentation. Exposure to hazardous chemicals is not expected with normal handling and use. In particular, the cell or battery should not be opened or burned. Section III – Hazards Identification Emergency Overview: Do not open or disassemble cells or batteries or expose them to fire or open flame. Do not puncture or deform. Cells and batteries present a hazard only if mishandled in a way that causes damage to the cell or battery or compromises their integrity. Primary Routes of Exposure: Risk of exposure to hazardous materials will only occur if the cell or battery is physically, thermally or electrically abused to the extent that the integrity of the cell or battery is compromised. In this case, exposure to the electrolyte can occur through ingestion, inhalation, eye contact and skin contact. Potential Health Effects: If the battery or cell has been damaged or ruptured, the electrolyte solution, which is corrosive, could be released and cause burns to the eyes, skin or respiratory tract. Ingestion of the electrolyte can cause serious burns of the gastrointestinal tract. Section IV – First Aid Measures If you get electrolyte in your eyes, flush with water for 15 minutes without rubbing and immediately contact a physician. -

5G Security Huawei-Facts Not Myths.Pdf
5G Security Huawei: Facts, Not Myths The U.S. government has been spreading misinformation about Huawei for more than a year. Now, the U.S. State Department has published a recycled list of misrepresentations, while implying that State Department staff somehow understand networking technology better than the telecom operators who use our equipment every day. To rebut the charges made against us, we’re using the format the State Department employed in its latest attack. 1 1 https://policystatic.state.gov/uploads/2019/12/5G-Myth_Fact4.pdf facts.huawei.com facts.huawei.com False Allegation #1: Huawei offers the cheapest equipment because it gets Chinese government funding. The Facts We never said our equipment was the cheapest. We just said it was affordable. Actually, in many cases our prices are higher than those quoted by other vendors. Our equipment provides value to our customers, who are demanding, knowledgeable veterans of the telecommunications industry. As any MBA student knows, being cheap isn’t necessarily a competitive advantage. Telecom operators don’t automatically buy the least expensive gear they can find irrespective of quality, security, and other important criteria. They spend a lot of money to build and maintain their networks, and like all businesses, they consider many factors before making a capital-intensive investment. But they do want value for money, and we give it to them. One reason is that we invest heavily in research and development. In 2018, for example, we spent US$14.3 billion on R&D. That’s more than Apple, Intel, or Cisco spent that year – and 30% more than the combined R&D spending of Ericsson and Nokia, Huawei’s two biggest competitors in the network gear business. -

HNA Digital-Device Program: Minimum and Recommended Specifications for Devices UPDATED Feb
LAST UPDATE: February 25, 2020 HOLY NAMES ACADEMY: Minimum and Recommended Specifications for Devices What type of device is required? Recommended: All students are expected to have a primary digital device that has the full capabilities of a laptop computer, such as the Microsoft Surface Pro line (Surface 6 or newer, Surface Laptop 3, Surface Book 2) or the Apple MacBook line. Not recommended: Secondary devices such as the iPad, iPhone, Android tablet (Google), Chromebook, Nook, Kindle, Microsoft Surface RT, Surface 2, Surface Go, or Surface Pro X will not meet our minimum specifications. Important: Devices powered by Microsoft Windows 10 in S Mode operating system must be switched out of S Mode: https://support.microsoft.com/en-us/help/4456067/windows-10-switch-out- of-s-mode What platform is recommended for the HNA Digital-Device Program? Because our students use Microsoft Office 365 resources every day for Outlook e-mail, OneDrive for cloud storage, and OneNote and Teams for collaboration, we STRONGLY recommend the use of a Windows 10 device. From experience, we have found that most Windows 10 devices integrate well with our technology, and we have provided all faculty and many staff with Microsoft Surface Pro devices. The Mac OS operating system has been successfully used by some students and staff and will meet the recommended requirements for our program at this time. Do I need to purchase a new device if my daughter already has a laptop computer or digital device? If you have a laptop or digital device that satisfies our recommended specifications (see page 2), then your daughter should have a device compatible with the school’s requirements for the near future. -
Surface Book 2 13ˮ External Pitch Deck Script
Surface Book 2 13” External Pitch Deck Script # Slide Talk Track [no notes] A note on the talk tracks: 1 Each reason to believe follows a three-step rhythm: first, introduce the pillar; then discuss the Surface Book 2 features; and finally, explore the “Day in the Life” scenario, which features some marketing research—ideally, you will customize the talk track on this slide for your audience. Today we’re here to talk about Surface Book 2—the most powerful Surface Book to date. 2 Feature call-outs Surface Book 2 was designed to expand and improve upon the revolutionary Surface Book. Now Microsoft’s most performant laptop comes with two times the power, better performance, better graphics, a vibrant PixelSense™ display, and longer battery life. 3 [Talk through features] What I want to drive home today is that Surface Book 2 is more than just a versatile device—it’s a business powerhouse that adapts to the way your teams work. Pillars We leveraged customer feedback to design the new and improved Surface Book 2—our most powerful, most versatile laptop ever. This device was created and refined with four things in mind. Surface Book 2 is built to: 4 Outfit your teams with best-in-class performance Adapt to the way your team works Showcase your team’s creativity with its beautiful design Unlock the best of Microsoft What does that mean? Let’s walk through how Surface Book 2 can help your teams hit the next level. Performance – intro 5 [no notes] Performance – detail High-speed dual- or quad-core Intel® Core™ i5 and i7 processors The Surface Book 2 is available with i5 and i7 processors and is twice as powerful as the previous Surface Book. -
Cybersecurity Solutions
National Security Agency/ Central Security Service CYBERSECURITY SOLUTIONS DATA AT REST CAPABILITY PACKAGE Version 4.8 October 2019 Data-at-Rest Capability Package CHANGE HISTORY Title Version Date Change Summary Commercial Solutions 0.8 July 2014 Initial draft of CSfC Data-at-Rest (DAR) for Classified (CSfC) requirements Data-at-Rest (DAR) Capability Package Commercial Solutions 1.0 September 2014 Official release of CSfC DAR requirements for Classified (CSfC) Introduced SWFDE/FE (SF) Solution Data-at-Rest (DAR) Design Capability Package Aligned with SW FDE Protection Profile (PP) 1.0 & FE Extended Package (EP) 1.0 Commercial Solutions 1.8 October 2014 Initial draft of CSfC DAR Version 2 for Classified (CSfC) requirements Data-at-Rest (DAR) Capability Package Commercial Solutions 2.0 December 2014 Official release of CSfC DAR Version 2 for Classified (CSfC) requirements Data-at-Rest (DAR) Added PE/FE (PF) Solution Design Capability Package Aligned with MDF PP 3.0 Commercial Solutions 2.8 May 2015 Initial draft of CSfC DAR Version 3 for Classified (CSfC) requirements Data-at-Rest (DAR) Capability Package Commercial Solutions 3.0 March 2016 Official release of CSfC DAR Version 3 for Classified (CSfC) requirements. Data-at-Rest (DAR) Added HWFDE/FE and HWFDE/SW FDE Capability Package (HF and HS) Solution Design Updated requirements to reflect new FDE Collaborative Protection Profile (cPP) 2.0 Discussed the associated Independent Software Vendor (ISV) technology which aligns with the FDE cPP 2.0 Added Lost and Found (LF) use case