Architecture and Design SAP Mobile Platform - Mobiliser 5.5
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Using SAP Crystal Reports with SAP Sybase SQL Anywhere
Using SAP Crystal Reports with SAP Sybase SQL Anywhere USING SAP CRYSTAL REPORTS WITH SAP SYBASE SQL ANYWHERE TABLE OF CONTENTS INTRODUCTION ............................................................................................................................................... 3 REQUIREMENTS .............................................................................................................................................. 3 CONNECTING TO SQL ANYWHERE WITH CRYSTAL REPORTS ............................................................... 4 CREATING A SIMPLE REPORT ...................................................................................................................... 7 Adding Data to Crystal Reports ............................................................................................................................ 7 Formatting Records in Crystal Reports ............................................................................................................... 8 Displaying Records on a Map in Crystal Reports ............................................................................................... 9 ADDING DATA TO CRYSTAL REPORTS USING A SQL QUERY .............................................................. 10 Inserting a Chart Displaying Queried Data ........................................................................................................15 CREATING A SALES REPORT .................................................................................................................... -

Resume Ready Resource Guide
Resume-Ready Skills & Certifications Finance | Commodities | Risk Management and Insurance Skills Advanced Microsoft Excel, Microsoft Access, SQL Financial Modeling, Financial Functions (NPV, IRR, PV, etc.), Bloomberg, Morningstar, thinkorswim Certifications - Finance Chartered Financial Analyst (CFA); Certified Financial Planner (CFP) Certified Fund Specialist (CFS); Commodities Trading Advisor (CTA) Series 3 (Commodities & Futures); Series 6 (Mutual Funds) Series 7 (Variable Annuities) ; Series 63/65/66 (State Law Exam) Series 79 (Investment Banking) Certifications - RMI Associate in Risk Management (ARM) Designation; RIMS Fellow (RF) Designation Chartered Property Casualty Underwriter (CPCU); Life and Health; Certified Insurance Counselor (CIC) Marketing Skills Social & Web: Facebook, GoogleAdwords, LinkedIn, Instagram, Twitter, Hootsuite; Marketing Automation: Marketo, Eloqua Marketing Analytics: Hubspot, Google Analytics, Facebook Insights, Web Trends, Omniture, Advanced Excel, SQL CRM | Email: Salesforce, Sendgrid, Responsys | Research: SurveyMonkey, Qualtrics CMS: SharePoint, WordPress | Languages: Java, HTML, CSS | Graphics: Adobe Creative Suite, Photoshop Digital Marketing Areas: PPC, SEO, SEM, Demand Generation Certifications Professional Certified Marketer (PCM) | Google Analytics Certification | Google Adwords Certification Hubspot Inbound Marketing Certification | Hootsuite Certification | Salesforce - Multiple Certifications Information Systems Skills Programming Languages: C, C++, C#, CSS, HTML, iOS, Java, JavaScript, Objective-C, -

Sap Sybase (Ase) W Third-Party Support
N SAP SYBASE (ASE) W THIRD-PARTY SUPPORT E S Overview SUPPORTED VERSIONS All Sybase database releases Spinnaker Support is a leading global provider of third-party support and managed and editions services for SAP Sybase (Adaptive Server Enterprise or ASE) database products. Spinnaker Support’s third-party software support replaces SAP’s annual maintenance and SUPPORTED PRODUCTS support. Third-party support is always at least half the cost of SAP support and provides more • Sybase Adaptive Server services through an assigned support team and other personalized service components. Enterprise (Sybase ASE) Your operations depend on Sybase running smoothly and efficiently so that your transactional • Sybase Advantage data is available at a moment’s notice. By switching to third-party Sybase support, you gain high Database Server responsiveness and faster problem resolution when problems do arise. You can remain on your (Sybase ADS) existing Sybase solutions for as long as needed and can rely on our expert advice when you eventually upgrade or migrate away from your current Sybase version. • Sybase Replication Server • Sybase IQ THE SYBASE DILEMMA • Sybase SQL Anywhere Following SAP’s acquisition of Sybase in 2011, Sybase customers have witnessed a steady decline in the commitment to deliver new innovations, product enhancements, and • Sybase PowerBuilder appropriate support resources. With the announced 2025 End of Mainstream Maintenance • Sybase PowerDesigner (EoMM) for Sybase 16.0, organizations are feeling new pressure to either upgrade to SAP HANA or migrate to an alternative database platform. • Sybase Mainframe Connect The Sybase EoMM, along with the rising cost and decreasing quality of SAP-provided support, has put IT leaders on the defensive, pressuring them to make a premature decision regarding the • Sybase EA Server future of their stable, reliable Sybase solution. -

Lesson 4: Optimize a Query Using the Sybase IQ Query Plan
Author: Courtney Claussen – SAP Sybase IQ Technical Evangelist Contributor: Bruce McManus – Director of Customer Support at Sybase Getting Started with SAP Sybase IQ Column Store Analytics Server Lesson 4: Optimize a Query using the SAP Sybase IQ Query Plan Copyright (C) 2012 Sybase, Inc. All rights reserved. Unpublished rights reserved under U.S. copyright laws. Sybase and the Sybase logo are trademarks of Sybase, Inc. or its subsidiaries. SAP and the SAP logo are trademarks or registered trademarks of SAP AG in Germany and in several other countries all over the world. All other trademarks are the property of their respective owners. (R) indicates registration in the United States. Specifications are subject to change without notice. Table of Contents 1. Introduction ................................................................................................................1 2. SAP Sybase IQ Query Processing ............................................................................2 3. SAP Sybase IQ Query Plans .....................................................................................4 4. What a Query Plan Looks Like ................................................................................5 5. What a Query Plan Will Tell You ............................................................................7 5.1 Query Tree Nodes and Node Detail ......................................................................7 5.1.1 Root Node Details ..........................................................................................7 -

Sybase Adaptive Server Enterprise (ASE) Plug-In User's Guide 13.2.1.0 E73486-01
Oracle® Enterprise Manager Sybase Adaptive Server Enterprise (ASE) Plug-in User©s Guide 13.2.1.0 E73486-01 June 2016 Oracle Enterprise Manager Sybase Adaptive Server Enterprise (ASE) Plug-in User's Guide, 13.2.1.0 E73486-01 Copyright © 2015, 2016, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency- specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Management Strategies for the Cloud Revolution
MANAGEMENT STRATEGIES FOR CLOUDTHE REVOLUTION MANAGEMENT STRATEGIES FOR CLOUDTHE REVOLUTION How Cloud Computing Is Transforming Business and Why You Can’t Afford to Be Left Behind CHARLES BABCOCK New York Chicago San Francisco Lisbon London Madrid Mexico City Milan New Delhi San Juan Seoul Singapore Sydney Toronto Copyright © 2010 by Charles Babcock. All rights reserved. Except as permitted under the United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior written permission of the publisher. ISBN: 978-0-07-174227-6 MHID: 0-07-174227-1 The material in this eBook also appears in the print version of this title: ISBN: 978-0-07-174075-3, MHID: 0-07-174075-9. All trademarks are trademarks of their respective owners. Rather than put a trademark symbol after every occurrence of a trademarked name, we use names in an editorial fashion only, and to the benefi t of the trademark owner, with no intention of infringement of the trademark. Where such designations appear in this book, they have been printed with initial caps. McGraw-Hill eBooks are available at special quantity discounts to use as premiums and sales promotions, or for use in corporate training programs. To contact a representative please e-mail us at [email protected]. This publication is designed to provide accurate and authoritative information in regard to the subject matter covered. It is sold with the understanding that the publisher is not engaged in rendering legal, accounting, or other professional service. -

Expert Analytics User Guide Content
PUBLIC SAP BusinessObjects Predictive Analytics 3.1 2016-11-22 Expert Analytics User Guide Content 1 About Expert Analytics........................................................6 1.1 Expert Analytics Overview.......................................................6 1.2 New in Expert Analytics 3.1......................................................6 1.3 Document History............................................................ 6 1.4 Documentation Resources...................................................... 7 1.5 What this Guide Contains.......................................................8 1.6 Target Audience..............................................................9 2 Getting Started with Expert Analytics........................................... 10 2.1 Basics of Expert Analytics......................................................10 2.2 Understanding Online and Agnostic Modes ..........................................11 2.3 Launching Expert Analytics.....................................................12 2.4 Installing R and the Required Packages.............................................12 2.5 Configuring R...............................................................14 2.6 Understanding Expert Analytics..................................................15 Designer View............................................................15 Results View.............................................................16 2.7 Using Expert Analytics from Start to Finish..........................................16 2.8 Configuring Advanced -

SAP Businessobjects Mobile Clients Supported Platforms (PAM)
SAP BusinessObjects Mobile Clients Supported Platforms (PAM) May 23, 2013 Updated: June 27, 2013 Disclaimer: This document is subject to change and may be changed by SAP at any time without notice. The document is not intended to be binding upon SAP to any particular course of business, product strategy, and/or development. SAP BusinessObjects Mobile Clients Supported Platforms Mobile Client Sybase Mobile Mobile Client Mobile Client Mobile Client Platform Platform Mobile BI Server Version(s) Version Platform Version(s) Version(s) SAP BusinessObjects Mobile 5.0(*2) Blackberry 4.7 to 6.0 N/A(*3) BI 4.1 and Edge BI 4.1 XI 3.1 and Edge XI 3.1: SP03 FP6 and above BI 4.0 and Edge BI 4.0: SP02 and above BI 4.1 and Edge BI 4.1 SUP 2.1 and SAP BusinessObjects Mobile 5.0 iOS iOS 6 (*1) Crystal Reports Server XI 3.1: SP03 FP6 and above above Crystal Server 2011: SP02 and above Crystal Server 2013 XI 3.1 and Edge XI 3.1: SP03 FP6 and above BI 4.0 and Edge BI 4.0: SP02 and above BI 4.1 and Edge BI 4.1 SAP BusinessObjects Mobile iOS SUP 2.1 and 5.0 iOS iOS 6 (*1) Crystal Reports Server XI 3.1: SP03 FP6 and SDK above above Crystal Server 2011: SP02 and above Crystal Server 2013 BI 4.0 and Edge BI 4.0: SP02 Patch 13 and SUP 2.1 and SAP BusinessObjects Mobile 5.0 Android 2.2 - 4.2 above above BI 4.1 and Edge BI 4.1 XI 3.2 and Edge XI 3.2: SP4 and above SAP BusinessObjects Explorer 4.1.7 iOS iOS 5.1, iOS 6 N/A(*3) BI 4.0 and Edge BI 4.0: SP2 and above BI 4.1 and Edge BI 4.1 Based on the backend server version, the features supported will be different. -
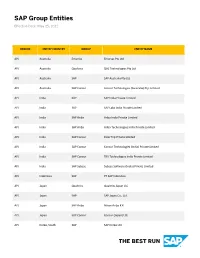
SAP Group Entities Effective Date: May 25, 2021
SAP Group Entities Effective Date: May 25, 2021 REGION ENTITY COUNTRY GROUP ENTITY NAME APJ Australia Emarsys Emarsys Pty Ltd APJ Australia Qualtrics QAL Technologies Pty Ltd APJ Australia SAP SAP Australia Pty Ltd APJ Australia SAP Concur Concur Technologies (Australia) Pty. Limited APJ India SAP SAP India Private Limited APJ India SAP SAP Labs India Private Limited APJ India SAP Ariba Ariba India Private Limited APJ India SAP Ariba Ariba Technologies India Private Limited APJ India SAP Concur ClearTrip Private Limited APJ India SAP Concur Concur Technologies (India) Private Limited APJ India SAP Concur TRX Technologies India Private Limited APJ India SAP Sybase Sybase Software (India) Private Limited APJ Indonesia SAP PT SAP Indonesia APJ Japan Qualtrics Qualtrics Japan LLC APJ Japan SAP SAP Japan Co., Ltd. APJ Japan SAP Ariba Nihon Ariba K.K. APJ Japan SAP Concur Concur (Japan) Ltd. APJ Korea, South SAP SAP Korea Ltd. REGION ENTITY COUNTRY GROUP ENTITY NAME APJ Korea, South SAP SAP Labs Korea, Inc. APJ Malaysia SAP SAP Malaysia Sdn. Bhd. APJ Malaysia SAP Concur CNQR Operations Mexico S. de. R.L. de. C.V. APJ Myanmar SAP SAP System Application and Products Asia Myanmar Limited APJ New Zealand SAP SAP New Zealand Limited APJ Philippines SAP SAP Philippines, Inc. APJ Philippines SAP SuccessFactors SuccessFactors (Philippines), Inc. APJ Singapore Emarsys Emarsys Pte Ltd APJ Singapore Qualtrics QSL Technologies Pte. Ltd. APJ Singapore SAP SAP Asia Pte Ltd APJ Singapore SAP Ariba Ariba International Singapore Pte Ltd APJ Singapore SAP Concur Concur Technologies (Singapore) Pte Ltd APJ Taiwan, China SAP SAP Taiwan Co., Ltd. -

Integration of Successfactors Business Execution Into SAP Netweaver Portal Via Single Sign-On
Cookbook Integration of SuccessFactors Business Execution into SAP NetWeaver Portal via Single Sign-On Target Audience ■ System Administrators CUSTOMER Document version: 1.20 – 2013-04-24 Document History CAUTION Before you start the implementation, make sure you have the latest version of this document. For the latest version, see: http://service.sap.com/hcm Media Library – SuccessFactors Integration The following table provides an overview of the most important document changes: Version Date Description 1.00 2012-06-29 First released version 1.10 2012-07-06 ■ Note on SAP NetWeaver Portal version added to section Integrating SuccessFactors BizX in SAP NetWeaver Porta [page 19]l ■ List of deep links added to section Using Deep Links for SuccessFactors BizX [page 20] 1.20 2013-04-24 Sections added: ■ Configuring User Mapping [page 11] ■ Configuring SAP NetWeaver Portal 7.0x [page 12] ■ Enabling Authentication with Logon Tickets in the Identity Provider [page 13] ■ Tools for Troubleshooting [page 23] Sections updated: ■ Information about identity provider solution added to section Introduction [page 5] ■ Information about identical users in SAP NetWeaver Portal and SuccessFactors BizX removed from section Prerequisites [page 7] ■ Navigation specified in more detail in section Adding a Trusted Provider [page 10] ■ Information about option By Uploading Certificate Manually added to section Setting Up a Trusted System for SAP NetWeaver Portal 7.0x [page 12] ■ Section Collecting Additional Information [page 15] renamed ■ Information about use of downloaded certificate added to section Downloading a Certificate [page 15] ■ Information about use of logon URL corrected in section Identifying a Global Logon URL [page 15] ■ Information about testing added to section Creating a URL iView in SAP NetWeaver Portal [page 19] ■ Links added to section Using Deep Links for SuccessFactors BizX [page 20] 2/28 CUSTOMER 2013-04-24 Table of Contents Chapter 1 Introduction ................................................. -

View Annual Report
2011 ANNUAL REPORT FINANCIAL AND NON-FINANCIAL PERFORMANCE IMPROVING PEOPLE’S LIVES The Best-Run Businesses Run SAP® To be all set for the future, 183,000 customers in 120 countries look to SAP for new technologies, tools, and strategies today. SAP solutions help them respond to the needs of people living longer, healthier lives; analyze and understand the complex connections between climate change and business operations; open up new opportunities and business mod- els in globalized markets; and apply technology and innovation that makes work simpler and more efficient. SAP helps our customers run their businesses with ideas and solutions that make them leaders. Key Facts Performance Summary € millions, unless otherwise stated 2011 2010 Change in % Financial key performance indicators Software revenue 3,971 3,265 22 Software and software-related service revenue (IFRS) 11,319 9,794 16 Non-IFRS adjustments 27 74 –64 Software and software-related service revenue (non-IFRS) 11,346 9,868 15 Total revenue (IFRS) 14,233 12,464 14 Non-IFRS adjustments 27 74 –64 Total revenue (non-IFRS) 14,260 12,538 14 Operating profit (IFRS) 4,881 2,591 88 Non-IFRS adjustments –171 1,416 –112 Operating profit (non-IFRS) 4,710 4,007 18 Operating margin in % (IFRS) 34.3 20.8 65 Operating margin in % (non-IFRS) 33 32 3 Free cash flow 3,333 2,588 29 Net liquidity 1,636 –850 292 Days’ sales outstanding (DSO) 60 65 –8 Equity ratio (total equity as a percentage of the total assets) 54.7 47.0 16 Research and development Research and development expenses 1,939 1,729 -

How to Include Item Pictures in SAP Business One
PUBLIC How to include item pictures in SAP Business One Applicable Release: SAP Business One 9.0 (valid for all countries) December 2012 HOW-TO-GUIDE PROCEDURE 1. Go to the demo DB: Administration->System Initialization->General Settings, under the Path tab, sets the Pictures Folder that you want to store images, such as item pictures. 2. Extract the item pictures which are provided together with this guide to the ‘Pictures Folder’ path configured in step 1. 2 HOW-TO-GUIDE 3. Preview item pictures in Item Master Data: Go to the demo DB: InventoryÆItem Master Data, check the existing items, like A00001, go to the ‘Remarks’ tab, there you can see the related item picture. 3 HOW-TO-GUIDE 4. Example on how item pictures could benefit, by using a Crystal Report Layout which includes item pictures: 4 www.sap.com © 2012 SAP AG. All rights reserved. SAP, R/3, SAP NetWeaver, Duet, PartnerEdge, ByDesign, SAP BusinessObjects Explorer, StreamWork, SAP HANA, and other SAP products and services mentioned herein as well as their respective logos are trademarks or registered trademarks of SAP AG in Germany and other countries. Business Objects and the Business Objects logo, BusinessObjects, Crystal Reports, Crystal Decisions, Web Intelligence, Xcelsius, and other Business Objects products and services mentioned herein as well as their respective logos are trademarks or registered trademarks of Business Objects Software Ltd. Business Objects is an SAP company. Sybase and Adaptive Server, iAnywhere, Sybase 365, SQL Anywhere, and other Sybase products and services mentioned herein as well as their respective logos are trademarks or registered trademarks of Sybase Inc.