Simultaneous Likelihood-Based Bootstrap Confidence Sets for a Large Number of Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Principles of Agricultural Economics Credit Hours: 2+0 Prepared By: Dr
Study Material Course No: Ag Econ. 111 Course Title: Principles of Agricultural Economics Credit Hours: 2+0 Prepared By: Dr. Harbans Lal Course Contents: Sr. Topic Aprox.No. No. of Lectures Unit-I 1 Economics: Meaning, Definition, Subject Matter 2 2 Divisions of Economics, Importance of Economics 2 3 Agricultural Economics Meaning, Definition 2 Unit-II 4 Basic concepts (Demand, meaning, definition, kind of demand, demand 3 schedule, demand curve, law of demand, Extension and contraction Vs increase and decrease in demand) 5 Consumption 2 6 Law of Diminishing Marginal Utility meaning, Definition, Assumption, 3 Limitation, Importance Unit-III 7 Indifference curve approach: properties, Application, derivation of demand 3 8 Consumer’s Surplus, Meaning, Definition, Importance 2 9 Definition, Importance, Elasticity of demand, Types, degrees and method of 4 measuring Elasticity, Importance of elasticity of demand Unit-IV 10 National Income: Concepts, Measurement. Public finance: Meaning, Principle, 3 Public revenue 11 Public Revenue: meaning, Service tax, meaning, classification of taxes; 3 Cannons of taxation Unit-V 12 Public Expenditure: Meaning Principles 2 13 Inflation, meaning definition, kind of inflation. 2 Unit-I Lecture No. 1 Economics- Meaning, Definitions and Subject Matter The Economic problem: Economic theory deals with the law and principles which govern the functioning of an economy and it various parts. An economy exists because of two basic facts. Firstly human wants for goods and services are unlimited and secondly productive resources with which to produce goods and services are scarce. In other words, we have the problem of allocating scarce resource so as to achieve the greatest possible satisfaction of wants. -

How to Hedge Against in Ation Risk in Vietnam
How to Hedge Against Ination Risk in Vietnam T. Thanh-Binh Nguyen ( [email protected] ) Chaoyang University of Technology Research Keywords: asymmetric cointegration, gold price, ination hedge, MSI-VAR(1) model, the US dollar, Vietnam. Posted Date: August 2nd, 2021 DOI: https://doi.org/10.21203/rs.3.rs-753285/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License How to Hedge Against Inflation Risk in Vietnam T.Thanh-Binh, Nguyen* Department of Accounting, Chaoyang University of Technology, 168 Jifong E. Road, Wufong District, Taichung City, 41349, Taiwan E-mail: [email protected] * Corresponding author; Tel.: +886-4-2332-3000 ext 7804. E-mail address: [email protected] How to Hedge Against Inflation Risk in Vietnam Abstract Vietnam has experienced galloping inflation and faced serious dollarization since its reform. To effectively control its inflation for promoting price stability, it is necessary to find efficacious leading indicators and the hedging mechanism. Using monthly data over the period from January 1997 to June 2020, this study finds the predictive power and hedge effectiveness of both gold and the US dollar on inflation in the long-run and short-run within the asymmetric framework. Especially, the response of inflation to the shocks of gold price and the US dollar are quick and decisive, disclosing the sensitiveness of inflation to these two variables. Keywords: asymmetric cointegration, gold price, inflation hedge, MSI-VAR(1) model, the US dollar, Vietnam. JEL classification codes: C22, L85, P44 2 I. Introduction One of the most vital responsibilities of policymakers in several countries is to control inflation for promoting two long-run goals: price stability and sustainable economic growth since inflation connects tightly to the purchasing power of currency within its border and affects its standing on the international markets. -

European University Institute. Digitised Version Produced by the EUI Library in 2020
EUROPEAN UNIVERSITY INSTITUTE, FLORENCE DEPARTMENT OF ECONOMICS Repository. Research Institute 320 University European Institute. E U I WORKING Cadmus, on INSTABILITY AND INDEXATION IN A LABOUR- MANAGED ECONOMY - A GENERAL EQUILIBRIUM University QUANTITY RATIONING APPROACH Access by it ick European Will Bartlett and Gerd Weinrich Open Author(s). Available içit The 2020. European University Institute University of Western Ontario © Badia Fiesolana Department of Economics in 50016 S. Domenico di Fiesole Social Science Centre Italy London, Canada N6A 5C2 Library EUI This paper was written while the second author was a Jean Monnet Fellow the at the European University Institute and presented at the Fourth Inter by national Conference on the Economics of Self-Management in Liège, Belgium, July 15-17, 1985. produced version BADIA FIESOLANA, SAN DOMENICO (FI) Digitised Repository. Research Institute University European Institute. Cadmus, on University Access European Open Printed in Italy in September 1985 Printed Italy September 1985 in in (C) Weinrich Will Gerd Bartlett and (C) reproduced in any form without without any reproduced form in No part may No part be of paper this European University Institute University European Institute - 50016 San Domenico (FI) Domenico - - San 50016 (FI) Author(s). Available permission of of author. permission the All rights All rights reserved. The 2020. Badia Fiesolana Badia Fiesolana © in Italy Library EUI the by produced version Digitised Repository. Research Institute University European managed economy based upon the general equilibrium quantity ra may lead to highly perverse and unstable price dynamics, as en Abstract households seek to maximize utility in consumption and leisure cient level of activity. -
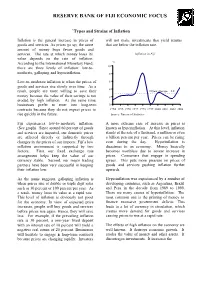
Types and Strains of Inflation
RESERVE BANK OF FIJI ECONOMIC FOCUS `Types and Strains of Inflation Inflation is the general increase in prices of will not make investments that yield returns goods and services. As prices go up, the same that are below the inflation rate. amount of money buys fewer goods and services. The rate at which money loses its Inflation in Fiji value depends on the rate of inflation. According to the International Monetary Fund, % there are three levels of inflation: low-to- 10 moderate, galloping and hyperinflation. 8 Low-to-moderate inflation is when the prices of 6 goods and services rise slowly over time. As a 4 result, people are more willing to save their 10 year average = 2.8 money because the value of their savings is not 2 eroded by high inflation. At the same time, businesses prefer to enter into long-term 0 contracts because they do not expect prices to 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 rise quickly in the future. Source: Bureau of Statistics Fiji experiences low-to-moderate inflation. A more extreme case of increase in prices is (See graph). Since around 60 percent of goods known as hyperinflation. At this level, inflation and services are imported, our domestic prices stands at the rate of a thousand, a million or even are affected directly or indirectly through a billion percent per year. Prices can be rising changes in the prices of our imports. Fiji’s low even during the day. Hyperinflation is inflation environment is supported by two disastrous to an economy. -

Types, Causes and Effects 1. Meaning of Inflation
Inflation: Types, Causes and Effects Inflation and unemployment are the two most talked-about words in the contemporary society. These two are the big problems that plague all the economies. Almost everyone is sure that he knows what inflation exactly is, but it remains a source of great deal of confusion because it is difficult to define it unambiguously. 1. Meaning of Inflation: Inflation is often defined in terms of its supposed causes. Inflation exists when money supply exceeds available goods and services. Or inflation is attributed to budget deficit financing. A deficit budget may be financed by the additional money creation. But the situation of monetary expansion or budget deficit may not cause price level to rise. Hence the difficulty of defining ‘inflation’. Inflation may be defined as ‘a sustained upward trend in the general level of prices’ and not the price of only one or two goods. G. Ackley defined inflation as ‘a persistent and appreciable rise in the general level or average of prices’. In other words, inflation is a state of rising prices, but not high prices. It is not high prices but rising price level that constitute inflation. It constitutes, thus, an overall increase in price level. It can, thus, be viewed as the devaluing of the worth of money. In other words, inflation reduces the purchasing power of money. A unit of money now buys less. Inflation can also be seen as a recurring phenomenon. While measuring inflation, we take into account a large number of goods and services used by the people of a country and then calculate average increase in the prices of those goods and services over a period of time. -

INFLATION and ITS CONTROL Everett E
INFLATION AND ITS CONTROL Everett E. Peterson, Extension Economist, University of Nebraska, and Richard G. Ford, Extension Economist, Federal Extension Service' The authors of the many speeches and writings on inflation can be divided roughly into two opinion groups. One group argues that a little inflation is good because it stimulates economic growth and bene- fits most people and that steps can be taken to care for those few who are injured. The second group holds that any inflation is bad, that creeping inflation will get out of hand, and that stable prices are con- sistent with full empoyment and economic growth. The following quotations are typical of current writings on inflation: Let us not minimize the explosive potentials of this economic outlaw. In its exaggerated form-when inflation shifts from a creep to a gallop- it has bred dictators, toppled governments, ruined nations. And, when it gets so out of hand, it can kill the goose that lays the golden eggs of eco- nomic growth by discouraging the savings with which we buy the machines to increase our productivity. Even in its creepiest form, inflation robs the needy by decreasing the purchasing power of money. The things that a pension or small salary will buy shrink with each creep forward of an inflationary movement. Thus, schoolteachers, pensioners, and those elder citizens who live upon income from a fixed amount of capital, find themselves poorer and poorer. The savings upon which so many of our people rely for their support in old age, or to gain earlier independence, are constantly diminished in value. -

Q: What Is Inflation? What Are Its Types? Explain. Ans: Inflation Is the Rate
Q: What is inflation? What are its types? Explain. Ans: Inflation is the rate at which the general level of prices for goods and services is rising and, consequently, the purchasing power of currency is falling. It measures the average price change in a basket of commodities and services over time. According to Peterson, “The word inflation in the broadest possible sense refers to any increase in the general price-level which is sustained and non-seasonal in character.” Broadly, inflation can be of three types based on its rate, which are as follows: (a) Moderate Inflation: When the prices of goods and services rise at a single digit rate annually, then moderate inflation takes place. This inflation is also termed as creeping inflation. When an economy passes through moderate inflation, the prices of goods and services increase but at moderate rate. Under this type of inflation, the rate of increase in prices vary from country to country. Moderate inflation is a type of inflation which can be anticipated; therefore, individuals hold money as a store of value. (b) Galloping Inflation: When the prices of goods and services increase at two-digit or three-digit rate per annum, then galloping inflation takes place. Galloping inflation is also known as jumping inflation. In the words of Baumol and Blinder, “Galloping inflation refers to an inflation that proceeds at an exceptionally high.” Galloping inflation has adverse effect on middle and low income groups in the society. As a result, individuals are not able to save money for future. This kind of situation requires strict measures to control inflation. -

Unit 4 Inflation
UNIT 4 INFLATION Structure Objectives Introduction Meaning of Inflation Types of Inflation 4.3.1 Demand-Pull Inflation 4.3.2 Cost-Push Inflation Effects of Inflation Control of Inflation Let Us Sum Up Key Words Answers to Check Your Progress Terminal Questions 4.0 OBJECTIVES After studying this unit, you should be able to : explain the meaning and defmition of inflation explain the types of inflation outline the concept of inflationary gap describe the demand-pull and cost-push inflation comprehend the effects of inflation suggest' how inflation can be controlled. 4.1 INTRODUCTION The modem economies in general have been facing the problem of inflation more severely in recent years. These economies, therefore, concentrate on the study of specific causes of price rise and designing of policies to promote price stability. Earlier, only the underdeveloped economies of the world faced the serious problem of persistent price rise. But lately even the developed countries have fallen victim to this problem. In this unit we will discuss the meaning and nature of inflation, types of inflation, effects of inflation and various methods available to overcome this problem. 4.2 MEANING OF INFLATION According to Pigou inflation takes place "when money income is expanding relatively to the output of work done by the productive agents for which it is the payment". At another place he says that "inflation exists when money income is I expanding 'more than in proportion to income earning activity". RC. Hawtrey associates inflation with "the issue of too much currency". T.E. I Gregory calls it a state of "abnormal increase in the quantity of purchasing power". -

MODULE I: (B) MACROECONOMICS: MONEY 2. INFLATION After Reading
MODULE I: (B) MACROECONOMICS: MONEY 2. INFLATION After reading this unit you should be able to understand: Inflation Kinds of inflation INTRODUCTION Inflation and unemployment are the two most significant problems of the Indian economy. These two are the big problems that plague all the economies. Almost everyone is sure that he knows what inflation exactly is, but it remains a source of great deal of confusion because it is difficult to define it unambiguously. One primary macroeconomic concern in market economies is the maintenance of stable prices, or the control of inflation. Inflation is a situation where prices are persistently rising, thereby reducing the value of money. It refers to a situation of constantly rising prices of commodities and factors of production. The opposite situation is known as deflation—a situation of constantly falling prices of commo- dities and factors of production. Inflation is an increase in the general level of prices. It does not mean that prices are high, but, rather, that they are increasing. For example, assume that over the past 2 years the price of a particular combination of consumer goods in country A has been stable at Rs. 100. Assume that in country B the price of that same combination of consumer goods has gone up from Rs. 10 to Rs. 30 over the last 2 years. Country B, not country A, faces a problem with inflation. Inflation refers to price movements, not price levels. With inflation, the price of every good and service does not need to increase because inflation refers to an increase in the general level of prices. -

Volume XI, 2015
ISSN 2380-3525 (Print) ISSN 2380-3517 (Online) Critical Review A Publication of Society for Mathematics of Uncertainty Volume XI, 2015 Editors: Paul P. Wang John N. Mordeson Mark J. Wierman Florentin Smarandache Publisher: Center for Mathematics of Uncertainty Creighton University Critical Review A Publication of Society for Mathematics of Uncertainty Volume XI, 2015 Editors: Paul P. Wang John N. Mordeson Mark J. Wierman Florentin Smarandache Publisher: Center for Mathematics of Uncertainty Creighton University We devote part of this issue of Critical Review to Lotfi Zadeh. The Editors. Paul P. Wang Department of Electrical and Computer Engineering Pratt School of Engineering Duke University Durham, NC 27708-0271 [email protected] John N. Mordeson Department of Mathematics Creighton University Omaha, Nebraska 68178 [email protected] Mark J. Wierman Department of Journalism Media & Computing Creighton University Omaha, Nebraska 68178 [email protected] Florentin Smarandache University of New Mexico 705 Gurley Ave., Gallup, NM 87301, USA [email protected] Contents Florentin Smarandache 5 Neutrosophic Systems and Neutrosophic Dynamic Systems Kalyan Mondal, Surapati Pramanik 26 Tri-complex Rough Neutrosophic Similarity Measure and its Application in Multi-attribute Decision Making Partha Pratim Dey, Surapati Pramanik, Bibhas C. Giri 41 Generalized Neutrosophic Soft Multi-attribute Group Decision Making Based on TOPSIS Vladik Kreinovich, Chrysostomos D. Stylios 57 When Should We Switch from Interval-Valued Fuzzy to Full Type-2 Fuzzy (e.g., -

Price Indices, Monetary Analysis, and Inflation: a Macro-Theoretical
PRICE INDICES, MONETARY ANALYSIS, AND INFLATION A MACRO-THEORETICAL INVESTIGATION Sergio Rossi University College London Department of Economics Ph.D. Thesis 2000 ProQuest Number: U643111 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest. ProQuest U643111 Published by ProQuest LLC(2015). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code. Microform Edition © ProQuest LLC. ProQuest LLC 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106-1346 ABSTRACT This thesis investigates inflation from a macro-theoretical point of view. It originates in a critical appraisal of traditional inflation analysis, where the latter phenomenon is identified with an ongoing increase in the level of aggregate prices because ‘too much money is chasing too few goods’. It argues that the prevalent idea of money and output being two separate and autonomous objects can neither explain the value of money nor its variations over time. It also argues that output as a whole cannot be measured in this widely-shared analytical framework. A new theory is called for. The problem of inflation in the alternative framework developed in the thesis reveals its essentially macroeconomic nature. It is argued that to gain an understanding of inflation it is necessary to focus analysis on the formation of national income and not on its distribution. -

The Great Inflation
This PDF is a selecon from a published volume from the Naonal Bureau of Economic Research Volume Title: The Great Inflaon: The Rebirth of Modern Central Banking Volume Author/Editor: Michael D. Bordo and Athanasios Orphanides, editors Volume Publisher: University of Chicago Press Volume ISBN: 0‐226‐006695‐9, 978‐0‐226‐06695‐0 (cloth) Volume URL: hp://www.nber.org/books/bord08‐1 Conference Date: September 25‐27, 2008 Publicaon Date: June 2013 Chapter Title: The Great Inflaon in the United States and the United Kingdom: Reconciling Policy Decisions and Data Outcomes Chapter Author(s): Riccardo DiCecio, Edward Nelson Chapter URL: hp://www.nber.org/chapters/c9172 Chapter pages in book: (p. 393 ‐ 438) 8 The Great Infl ation in the United States and the United Kingdom Reconciling Policy Decisions and Data Outcomes Riccardo DiCecio and Edward Nelson 8.1 Introduction In this chapter we study the Great Infl ation in both the United States and the United Kingdom. Our concentration on more than one country refl ects our view that a sound explanation should account for the experience of the Great Infl ation both in the United States and beyond. We emphasize further that an explanation for the Great Infl ation should be consistent with both the data and what we know about the views that guided policymakers. Figure 8.1 plots four- quarter infl ation for the United Kingdom using the Retail Price Index (RPI), and four- quarter US infl ation using the Consumer Price Index (CPI). The peaks in infl ation in the mid- 1970s and 1980 are over 20 percent in the United Kingdom, far higher than the corresponding US peaks.