PROGRAMMING LANGUAGE EVOLUTION and SOURCE CODE REJUVENATION a Dissertation by PETER MATHIAS PIRKELBAUER Submitted to the Office
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reflection, Zips, and Generalised Casts Abstract
Scrap More Boilerplate: Reflection, Zips, and Generalised Casts Ralf L a¨mmel Vrije Universiteit & CWI, Amsterdam Abstract Writing boilerplate code is a royal pain. Generic programming promises to alleviate this pain b y allowing the programmer to write a generic #recipe$ for boilerplate code, and use that recipe in many places. In earlier work we introduced the #Scrap y our boilerplate$ approach to generic p rogramming, which exploits Haskell%s exist- ing type-class mechanism to support generic transformations and queries. This paper completes the picture. We add a few extra #introspec- tive$ or #reflective$ facilities, that together support a r ich variety of serialisation and de-serialisation. We also show how to perform generic #zips$, which at first appear to be somewhat tricky in our framework. Lastly, we generalise the ability to over-ride a generic function with a type-specific one. All of this can be supported in Haskell with independently-useful extensions: higher-rank types and type-safe cast. The GHC imple- mentation of Haskell readily derives the required type classes for user-defined data types. Categories and Subject Descriptors D.2. 13 [Software Engineering]: Reusable Software; D.1.1 [Programming Techniques]: Functional Programming; D.3. 1 [Programming Languages]: Formal Definitions and Theory General Terms Design, Languages Keywords Generic p rogramming, reflection, zippers, type cast 1 Introduction It is common to find that large slabs of a program consist of #boil- erplate$ code, which conceals b y its b ulk a smaller amount of #in- teresting$ code. So-called generic p rogramming techniques allow Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or c ommercial advantage and that copies b ear this notice and the full citation on the first page. -
Administering Unidata on UNIX Platforms
C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta UniData Administering UniData on UNIX Platforms UDT-720-ADMU-1 C:\Program Files\Adobe\FrameMaker8\UniData 7.2\7.2rebranded\ADMINUNIX\ADMINUNIXTITLE.fm March 5, 2010 1:34 pm Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Beta Notices Edition Publication date: July, 2008 Book number: UDT-720-ADMU-1 Product version: UniData 7.2 Copyright © Rocket Software, Inc. 1988-2010. All Rights Reserved. Trademarks The following trademarks appear in this publication: Trademark Trademark Owner Rocket Software™ Rocket Software, Inc. Dynamic Connect® Rocket Software, Inc. RedBack® Rocket Software, Inc. SystemBuilder™ Rocket Software, Inc. UniData® Rocket Software, Inc. UniVerse™ Rocket Software, Inc. U2™ Rocket Software, Inc. U2.NET™ Rocket Software, Inc. U2 Web Development Environment™ Rocket Software, Inc. wIntegrate® Rocket Software, Inc. Microsoft® .NET Microsoft Corporation Microsoft® Office Excel®, Outlook®, Word Microsoft Corporation Windows® Microsoft Corporation Windows® 7 Microsoft Corporation Windows Vista® Microsoft Corporation Java™ and all Java-based trademarks and logos Sun Microsystems, Inc. UNIX® X/Open Company Limited ii SB/XA Getting Started The above trademarks are property of the specified companies in the United States, other countries, or both. All other products or services mentioned in this document may be covered by the trademarks, service marks, or product names as designated by the companies who own or market them. License agreement This software and the associated documentation are proprietary and confidential to Rocket Software, Inc., are furnished under license, and may be used and copied only in accordance with the terms of such license and with the inclusion of the copyright notice. -

Template Meta-Programming for Haskell
Template Meta-programming for Haskell Tim Sheard Simon Peyton Jones OGI School of Science & Engineering Microsoft Research Ltd Oregon Health & Science University [email protected] [email protected] Abstract C++, albeit imperfectly... [It is] obvious to functional programmers what the committee did not realize until We propose a new extension to the purely functional programming later: [C++] templates are a functional language evalu- language Haskell that supports compile-time meta-programming. ated at compile time...” [12]. The purpose of the system is to support the algorithmic construction of programs at compile-time. Robinson’s provocative paper identifies C++ templates as a ma- The ability to generate code at compile time allows the program- jor, albeit accidental, success of the C++ language design. De- mer to implement such features as polytypic programs, macro-like spite the extremely baroque nature of template meta-programming, expansion, user directed optimization (such as inlining), and the templates are used in fascinating ways that extend beyond the generation of supporting data structures and functions from exist- wildest dreams of the language designers [1]. Perhaps surprisingly, ing data structures and functions. in view of the fact that templates are functional programs, func- tional programmers have been slow to capitalize on C++’s success; Our design is being implemented in the Glasgow Haskell Compiler, while there has been a recent flurry of work on run-time meta- ghc. programming, much less has been done on compile-time meta- This version is very slightly modified from the Haskell Workshop programming. The Scheme community is a notable exception, as 2002 publication; a couple of typographical errors are fixed in Fig- we discuss in Section 10. -

DC Console Using DC Console Application Design Software
DC Console Using DC Console Application Design Software DC Console is easy-to-use, application design software developed specifically to work in conjunction with AML’s DC Suite. Create. Distribute. Collect. Every LDX10 handheld computer comes with DC Suite, which includes seven (7) pre-developed applications for common data collection tasks. Now LDX10 users can use DC Console to modify these applications, or create their own from scratch. AML 800.648.4452 Made in USA www.amltd.com Introduction This document briefly covers how to use DC Console and the features and settings. Be sure to read this document in its entirety before attempting to use AML’s DC Console with a DC Suite compatible device. What is the difference between an “App” and a “Suite”? “Apps” are single applications running on the device used to collect and store data. In most cases, multiple apps would be utilized to handle various operations. For example, the ‘Item_Quantity’ app is one of the most widely used apps and the most direct means to take a basic inventory count, it produces a data file showing what items are in stock, the relative quantities, and requires minimal input from the mobile worker(s). Other operations will require additional input, for example, if you also need to know the specific location for each item in inventory, the ‘Item_Lot_Quantity’ app would be a better fit. Apps can be used in a variety of ways and provide the LDX10 the flexibility to handle virtually any data collection operation. “Suite” files are simply collections of individual apps. Suite files allow you to easily manage and edit multiple apps from within a single ‘store-house’ file and provide an effortless means for device deployment. -
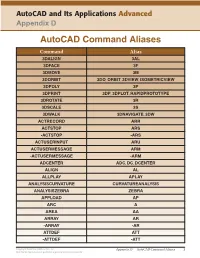
Autocad Command Aliases
AutoCAD and Its Applications Advanced Appendix D AutoCAD Command Aliases Command Alias 3DALIGN 3AL 3DFACE 3F 3DMOVE 3M 3DORBIT 3DO, ORBIT, 3DVIEW, ISOMETRICVIEW 3DPOLY 3P 3DPRINT 3DP, 3DPLOT, RAPIDPROTOTYPE 3DROTATE 3R 3DSCALE 3S 3DWALK 3DNAVIGATE, 3DW ACTRECORD ARR ACTSTOP ARS -ACTSTOP -ARS ACTUSERINPUT ARU ACTUSERMESSAGE ARM -ACTUSERMESSAGE -ARM ADCENTER ADC, DC, DCENTER ALIGN AL ALLPLAY APLAY ANALYSISCURVATURE CURVATUREANALYSIS ANALYSISZEBRA ZEBRA APPLOAD AP ARC A AREA AA ARRAY AR -ARRAY -AR ATTDEF ATT -ATTDEF -ATT Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 1 May not be reproduced or posted to a publicly accessible website. Command Alias ATTEDIT ATE -ATTEDIT -ATE, ATTE ATTIPEDIT ATI BACTION AC BCLOSE BC BCPARAMETER CPARAM BEDIT BE BLOCK B -BLOCK -B BOUNDARY BO -BOUNDARY -BO BPARAMETER PARAM BREAK BR BSAVE BS BVSTATE BVS CAMERA CAM CHAMFER CHA CHANGE -CH CHECKSTANDARDS CHK CIRCLE C COLOR COL, COLOUR COMMANDLINE CLI CONSTRAINTBAR CBAR CONSTRAINTSETTINGS CSETTINGS COPY CO, CP CTABLESTYLE CT CVADD INSERTCONTROLPOINT CVHIDE POINTOFF CVREBUILD REBUILD CVREMOVE REMOVECONTROLPOINT CVSHOW POINTON Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 2 May not be reproduced or posted to a publicly accessible website. Command Alias CYLINDER CYL DATAEXTRACTION DX DATALINK DL DATALINKUPDATE DLU DBCONNECT DBC, DATABASE, DATASOURCE DDGRIPS GR DELCONSTRAINT DELCON DIMALIGNED DAL, DIMALI DIMANGULAR DAN, DIMANG DIMARC DAR DIMBASELINE DBA, DIMBASE DIMCENTER DCE DIMCONSTRAINT DCON DIMCONTINUE DCO, DIMCONT DIMDIAMETER DDI, DIMDIA DIMDISASSOCIATE DDA DIMEDIT DED, DIMED DIMJOGGED DJO, JOG DIMJOGLINE DJL DIMLINEAR DIMLIN, DLI DIMORDINATE DOR, DIMORD DIMOVERRIDE DOV, DIMOVER DIMRADIUS DIMRAD, DRA DIMREASSOCIATE DRE DIMSTYLE D, DIMSTY, DST DIMTEDIT DIMTED DIST DI, LENGTH DIVIDE DIV DONUT DO DRAWINGRECOVERY DRM DRAWORDER DR Copyright Goodheart-Willcox Co., Inc. -

Tortoisemerge a Diff/Merge Tool for Windows Version 1.11
TortoiseMerge A diff/merge tool for Windows Version 1.11 Stefan Küng Lübbe Onken Simon Large TortoiseMerge: A diff/merge tool for Windows: Version 1.11 by Stefan Küng, Lübbe Onken, and Simon Large Publication date 2018/09/22 18:28:22 (r28377) Table of Contents Preface ........................................................................................................................................ vi 1. TortoiseMerge is free! ....................................................................................................... vi 2. Acknowledgments ............................................................................................................. vi 1. Introduction .............................................................................................................................. 1 1.1. Overview ....................................................................................................................... 1 1.2. TortoiseMerge's History .................................................................................................... 1 2. Basic Concepts .......................................................................................................................... 3 2.1. Viewing and Merging Differences ...................................................................................... 3 2.2. Editing Conflicts ............................................................................................................. 3 2.3. Applying Patches ........................................................................................................... -

Process and Memory Management Commands
Process and Memory Management Commands This chapter describes the Cisco IOS XR software commands used to manage processes and memory. For more information about using the process and memory management commands to perform troubleshooting tasks, see Cisco ASR 9000 Series Aggregation Services Router Getting Started Guide. • clear context, on page 2 • dumpcore, on page 3 • exception coresize, on page 6 • exception filepath, on page 8 • exception pakmem, on page 12 • exception sparse, on page 14 • exception sprsize, on page 16 • follow, on page 18 • monitor threads, on page 25 • process, on page 29 • process core, on page 32 • process mandatory, on page 34 • show context, on page 36 • show dll, on page 39 • show exception, on page 42 • show memory, on page 44 • show memory compare, on page 47 • show memory heap, on page 50 • show processes, on page 54 Process and Memory Management Commands 1 Process and Memory Management Commands clear context clear context To clear core dump context information, use the clear context command in the appropriate mode. clear context location {node-id | all} Syntax Description location{node-id | all} (Optional) Clears core dump context information for a specified node. The node-id argument is expressed in the rack/slot/module notation. Use the all keyword to indicate all nodes. Command Default No default behavior or values Command Modes Administration EXEC EXEC mode Command History Release Modification Release 3.7.2 This command was introduced. Release 3.9.0 No modification. Usage Guidelines To use this command, you must be in a user group associated with a task group that includes appropriate task IDs. -

Types and Programming Languages by Benjamin C
< Free Open Study > . .Types and Programming Languages by Benjamin C. Pierce ISBN:0262162091 The MIT Press © 2002 (623 pages) This thorough type-systems reference examines theory, pragmatics, implementation, and more Table of Contents Types and Programming Languages Preface Chapter 1 - Introduction Chapter 2 - Mathematical Preliminaries Part I - Untyped Systems Chapter 3 - Untyped Arithmetic Expressions Chapter 4 - An ML Implementation of Arithmetic Expressions Chapter 5 - The Untyped Lambda-Calculus Chapter 6 - Nameless Representation of Terms Chapter 7 - An ML Implementation of the Lambda-Calculus Part II - Simple Types Chapter 8 - Typed Arithmetic Expressions Chapter 9 - Simply Typed Lambda-Calculus Chapter 10 - An ML Implementation of Simple Types Chapter 11 - Simple Extensions Chapter 12 - Normalization Chapter 13 - References Chapter 14 - Exceptions Part III - Subtyping Chapter 15 - Subtyping Chapter 16 - Metatheory of Subtyping Chapter 17 - An ML Implementation of Subtyping Chapter 18 - Case Study: Imperative Objects Chapter 19 - Case Study: Featherweight Java Part IV - Recursive Types Chapter 20 - Recursive Types Chapter 21 - Metatheory of Recursive Types Part V - Polymorphism Chapter 22 - Type Reconstruction Chapter 23 - Universal Types Chapter 24 - Existential Types Chapter 25 - An ML Implementation of System F Chapter 26 - Bounded Quantification Chapter 27 - Case Study: Imperative Objects, Redux Chapter 28 - Metatheory of Bounded Quantification Part VI - Higher-Order Systems Chapter 29 - Type Operators and Kinding Chapter 30 - Higher-Order Polymorphism Chapter 31 - Higher-Order Subtyping Chapter 32 - Case Study: Purely Functional Objects Part VII - Appendices Appendix A - Solutions to Selected Exercises Appendix B - Notational Conventions References Index List of Figures < Free Open Study > < Free Open Study > Back Cover A type system is a syntactic method for automatically checking the absence of certain erroneous behaviors by classifying program phrases according to the kinds of values they compute. -

How to Dump and Load
How To Dump And Load Sometimes it becomes necessary to reorganize the data in your database (for example, to move data from type i data areas to type ii data areas so you can take advantage of the latest features)or to move parts of it from one database to another. The process for doping this can be quite simple or quite complex, depending on your environment, the size of your database, what features you are using, and how much time you have. Will you remember to recreate the accounts for SQL users? To resotre theie privileges? Will your loaded database be using the proper character set and collations? What about JTA? Replication? etc. We will show you how to do all the other things you need to do in addition to just dumping and loading the data in your tables. 1 How To Dump and Load gus bjorklund head groundskeeper, parmington foundation 2 What do we mean by dumping and loading? • Extract all the data from a database (or storage area) • Insert the data into a new database (or storage area) • Could be entire database or part 3 Why do we dump and load? 4 Why do we dump & load? • To migrate between platforms • To upgrade OpenEdge to new version • To repair corruption • To “improve performance” • To change storage area configuration • To defragment or improve “scatter” • To fix a “long rm chain” problem • Because it is October 5 Ways to dump and load • Dictionary • 4GL BUFFER-COPY • Binary • Replication triggers (or CDC) • Table partitioning / 4GL • Incremental by storage area 6 Binary Dump & Load • binary dump files – not "human readable" -

A Morphic Based Live Programming Graphical User Interface Implemented in Python
Final Thesis PyMorphic - a Morphic based Live Programming Graphical User Interface implemented in Python by Anders Osterholm¨ LIU-KOGVET-D--06/12--SE 23th August 2006 PyMorphic - a Morphic based Live Programming Graphical User Interface implemented in Python Final Thesis performed at Human Centered Systems division in the Department of Computer and Information Science at Link¨oping University by Anders Osterholm¨ LIU-KOGVET-D--06/12--SE 23th August 2006 Examiner: Dr. Mikael Kindborg Department of Computer and Information Science at Link¨oping University Abstract Programming is a very complex activity that has many simultaneous learn- ing elements. The area of Live-programming offers possibilities for enhanc- ing programming work by speeding up the feedback loop and providing means for reducing the cognitive load on the working memory during the task. This could allow for better education for novice programmers. In this work a number of systems with a shared aim of providing educational tools for scholars from compulsory level to undergraduate college were studied. The common approach in the majority of the tools was to use program ab- stractions like tangible morphs, playing cards, capsules for code segments, and visual stories. For the user these abstractions and tools offer better focus on the constructive and creative side of programming because they relieve the user from the cumbersome work of writing program code, but they also sacrifice some of the expressiveness of a low-level language. A Live programming system, called PyMorphic, based on the Morphic model was built in the Python programming language. Two different so- lutions, based on the Wx toolkit for Python, were constructed and evalu- ated. -

Motor Vehicle Division Prestige License Plate Application
For State or County use only: Denied Refund Form MV-9B (Rev. 08-2017) Web and MV Manual Georgia Department of Revenue - Motor Vehicle Division Prestige License Plate Application ______________________________________________________________________________________ Purpose of this Form: This form is to be used by a vehicle owner to request the manufacture of a Special Prestige (Personalized) License Plate. This form should not be used to record a change of ownership, change of address, or change of license plate classification. How to submit this form: After reviewing the MV-9B form instructions, this fully completed form must be submitted to your local County tag office. Please refer to our website at https://mvd.dor.ga.gov/motor/tagoffices/SelectTagOffice.aspx to locate the address(es) for your specific County. OWNER INFORMATION First Name Middle Initial Last Name Suffix Owners’ Full Legal Name: Mailing Address: City: State: Zip: Telephone Number: Owner(s)’ Full Legal Name: First Name Middle Initial Last Name Suffix If secondary Owner(s) are listed Mailing Address: City: State: Zip: Telephone Number: VEHICLE INFORMATION Vehicle Identification Number (VIN): Year: Make: Model: LICENSE PLATE COMBINATION Private Passenger Vehicle (Includes Motor Home and Non-Commercial Trailer) Note: Private passenger vehicles cannot exceed seven (7) letters and/or numbers including spaces. Meaning: ___________________________ Meaning: ___________________________ Meaning: ___________________________ (Required) (Required) (Required) Motorcycle Note: Motorcycles cannot exceed six (6) letters and/or numbers including spaces. Meaning: ___________________________ Meaning: ___________________________ Meaning: ___________________________ (Required) (Required) (Required) Note: No punctuation or symbols are allowed on a license plate. Only letters, numbers, and spaces are allowed. I request that a personal prestige license plate be manufactured. -

Feihong Hsu 217 S
Feihong Hsu 217 S. Leavitt St., #1S Chicago, IL 60612 Cell: 847.219.6000, Home: 312.738.3179 [email protected] www.cs.uic.edu/~fhsu EDUCATION: University of Illinois at Chicago Expected graduation in May 2004 Master of Science in Computer Science GPA: 4.80/5.00 University of Illinois at Urbana-Champaign Graduated December 2000 Bachelor of Science in Mathematics & Computer Science GPA: 3.78/4.00 Courses : Software Engineering, Database Systems, User Interface Design, Computer Networks, Object-Oriented Languages & Environments, Computer Architecture, Numerical Methods, Combinatorial Algorithms, Programming Languages & Compilers, Artificial Intelligence EXPERIENCE: Teaching Assistant , Introduction to Programming , August 2002-December 2003 University of Illinois at Chicago, Computer Science Department http://logos.cs.uic.edu/102 • Teach up to 30 students in weekly lab sections (C/C++/Java). • Develop online material, quizzes, lab assignments. Assist in writing exam problems. • Proposed and implemented new hands-on approach to labs, causing students to become visibly more engaged in the material. • Designed assignment in which students programmed an image manipulation application which included convolution and distortion filters. Teaching Assistant , Computer Literacy , January 2004-Present University of Illinois at Chicago, Computer Science Department http://wiggins.cs.uic.edu/cs100 • Most duties are similar to above. • Propose course topics and determine direction of the course Research Assistant , Team Engineering Collaboratory (TEC) , May 2000-December 2001 University of Illinois at Urbana-Champaign, Speech Communications Department http://www.spcomm.uiuc.edu/Projects/TECLAB/ • Continued development of Blanche, a modeling and simulation environment for the study of social networks. • Managed two undergrad programmers. Maintained project web page and distributions.