A Pitch Detection Algorithm Based on Windowless Autocorrelation Function and Modified Cepstrum Method in Noisy Environments
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cepstrum Analysis and Gearbox Fault Diagnosis
Cepstrum Analysis and Gearbox Fault Diagnosis 13-150 CEPSTRUM ANALYSIS AND GEARBOX FAULT DIAGNOSIS by R.B. Randall B.Tech., B.A. INTRODUCTION Cepstrum Analysis is a tool for the detection of periodicity in a frequency spectrum, and seems so far to have been used mainly in speech analysis for voice pitch determination and related questions. (Refs. 1, 2) In that case the periodicity in the spectrum is given by the many harmonics of the fundamental voice frequency, but another form of periodicity which can also be detected by cepstrum analysis is the presence of sidebands spaced at equal intervals around one or a number of carrier frequencies. The presence of such sidebands is of interest in the analysis of gearbox vibration signals, since a number of faults tend to cause modulation of the vibration pattern resulting from tooth meshing, and this modulation (either amplitude or frequency modulation) gives rise to sidebands in the frequency spectrum. The sidebands are grouped around the tooth-meshing frequency and its harmonics, spaced at multiples of the modulating frequencies (Refs. 3, 4, 5), and determination of these modulation frequencies can be very useful in diagnosis of the fault. The cepstrum is defined (Refs. 6, 1) as the power spectrum of the logarithmic power spectrum (i.e. in dB amplitude form), and is thus related to the autocorrelation function, which can be obtained by inverse Fourier transformation of the power spectrum with linear ordinates. The advantages of using the cepstrum instead of the autocorrelation function in certain circumstances can be inter preted in two different ways. -

Cepstral Peak Prominence: a Comprehensive Analysis
Cepstral peak prominence: A comprehensive analysis Ruben Fraile*, Juan Ignacio Godino-Llorente Circuits & Systems Engineering Department, ETSIS Telecomunicacion, Universidad Politecnica de Madrid, Campus Sur, Carretera de Valencia Km.7, 28031 Madrid, Spain ABSTRACT An analytical study of cepstral peak prominence (CPP) is presented, intended to provide an insight into its meaning and relation with voice perturbation parameters. To carry out this analysis, a parametric approach is adopted in which voice production is modelled using the traditional source-filter model and the first cepstral peak is assumed to have Gaussian shape. It is concluded that the meaning of CPP is very similar to that of the first rahmonic and some insights are provided on its dependence with fundamental frequency and vocal tract resonances. It is further shown that CPP integrates measures of voice waveform and periodicity perturbations, be them either amplitude, frequency or noise. 1. Introduction Merk et al. proposed the variability in CPP to be used as a cue to detect neurogenic voice disorders [16], Rosa et al. reported that Cepstral peak prominence (CPP) is an acoustic measure of voice the combination of CPP with other acoustic cues is relevant for the quality that has been qualified as the most promising and perhaps detection of laryngeal disorders [17], Hartl et al. [18] [19] and Bal- robust acoustic measure of dysphonia severity [1]. Such a definite asubramanium et al. [20] concluded that patients suffering from statement made by Maryn et al is based on a meta-analysis that unilateral vocal fold paralysis exhibited significantly lower values considered previous results by Wolfe and Martin [2], Wolfe et al. -

Exploiting the Symmetry of Integral Transforms for Featuring Anuran Calls
S S symmetry Article Exploiting the Symmetry of Integral Transforms for Featuring Anuran Calls Amalia Luque 1,* , Jesús Gómez-Bellido 1, Alejandro Carrasco 2 and Julio Barbancho 3 1 Ingeniería del Diseño, Escuela Politécnica Superior, Universidad de Sevilla, 41004 Sevilla, Spain; [email protected] 2 Tecnología Electrónica, Escuela Ingeniería Informática, Universidad de Sevilla, 41004 Sevilla, Spain; [email protected] 3 Tecnología Electrónica, Escuela Politécnica Superior, Universidad de Sevilla, 41004 Sevilla, Spain; [email protected] * Correspondence: [email protected]; Tel.: +34-955-420-187 Received: 23 February 2019; Accepted: 18 March 2019; Published: 20 March 2019 Abstract: The application of machine learning techniques to sound signals requires the previous characterization of said signals. In many cases, their description is made using cepstral coefficients that represent the sound spectra. In this paper, the performance in obtaining cepstral coefficients by two integral transforms, Discrete Fourier Transform (DFT) and Discrete Cosine Transform (DCT), are compared in the context of processing anuran calls. Due to the symmetry of sound spectra, it is shown that DCT clearly outperforms DFT, and decreases the error representing the spectrum by more than 30%. Additionally, it is demonstrated that DCT-based cepstral coefficients are less correlated than their DFT-based counterparts, which leads to a significant advantage for DCT-based cepstral coefficients if these features are later used in classification algorithms. Since the DCT superiority is based on the symmetry of sound spectra and not on any intrinsic advantage of the algorithm, the conclusions of this research can definitely be extrapolated to include any sound signal. Keywords: spectrum symmetry; DCT; MFCC; audio features; anuran calls 1. -
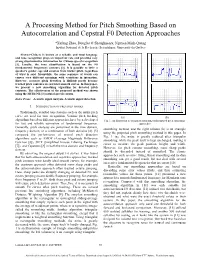
A Processing Method for Pitch Smoothing Based on Autocorrelation and Cepstral F0 Detection Approaches
A Processing Method for Pitch Smoothing Based on Autocorrelation and Cepstral F0 Detection Approaches *Xufang Zhao, Douglas O’Shaughnessy, Nguyen Minh-Quang Institut National de la Recherche Scientifique, Université du Québec Abstract-Chinese is known as a syllabic and tonal language and tone recognition plays an important role and provides very strong discriminative information for Chinese speech recognition [1]. Usually, the tone classification is based on the F0 (fundamental frequency) contours [2]. It is possible to infer a speaker's gender, age and emotion from his/her pitch, regardless of what is said. Meanwhile, the same sequence of words can convey very different meanings with variations in intonation. However, accurate pitch detection is difficult partly because tracked pitch contours are not ideal smooth curves. In this paper, we present a new smoothing algorithm for detected pitch contours. The effectiveness of the proposed method was shown using the HUB4-NE [3] natural speech corpus. Index Terms—Acoustic signal analysis, Acoustic signal detection I. INTRODUCTION OF PREVIOUS WORKS Traditionally, detailed tone features such as the entire pitch curve are used for tone recognition. Various pitch tracking (a) (b) algorithms based on different approaches have been developed Fig. 1: An illustration of triangular smoothing and proposed pitch smoothing for fast and reliable estimation of fundamental frequency. approaches Generally, pitch analyses are performed in the time domain, smoothing method, and the right column (b) is an example frequency domain, or a combination of both domains [4]. [5] using the proposed pitch smoothing method in this paper. In compared the performance of several pitch detection Fig. -

Speech Signal Representation
Speech Signal Representation • Fourier Analysis – Discrete-time Fourier transform – Short-time Fourier transform – Discrete Fourier transform • Cepstral Analysis – The complex cepstrum and the cepstrum – Computational considerations – Cepstral analysis of speech – Applications to speech recognition – Mel-Frequency cepstral representation • Performance Comparison of Various Representations 6.345 Automatic Speech Recognition (2003) Speech Signal Representaion 1 Discrete-Time Fourier Transform �+∞ jω −jωn X (e )= x[n]e n=−∞ � π 1 jω jωn x[n]=2π X (e )e dω −π � � �+∞ � � • � � ∞ Sufficient condition for convergence: � x[n]� < + n=−∞ • Although x[n] is discrete, X (ejω) is continuous and periodic with period 2π. • Convolution/multiplication duality: y[n]=x[ n] ∗ h[n] Y (ejω)=X ( ejω)H(ejω) y[n]=x[ n]w[n] � π jω 1 jθ j(ω−θ) Y (e )=2π W (e )X (e )dθ −π 6.345 Automatic Speech Recognition (2003) Speech Signal Representaion 2 Short-Time Fourier Analysis (Time-Dependent Fourier Transform) w [ 50 - m ] w [ 100 - m ] w [ 200 - m ] x [ m ] m 0 n = 50 n = 100 n = 200 ∞ �+ jω −jωm Xn(e )= w[n − m]x[m]e m=−∞ • If n is fixed, then it can be shown that: � π jω 1 jθ jθn j(ω+θ) Xn(e )= 2π W (e )e X (e )dθ −π • The above equation is meaningful only if we assume that X (ejω) represents the Fourier transform of a signal whose properties continue outside the window, or simply that the signal is zero outside the window. jω jω jω • In order for Xn(e ) to correspond to X (e ), W (e ) must resemble an impulse jω with respect to X (e ). -

'Specmurt Anasylis' of Multi-Pitch Signals
‘Specmurt Anasylis’ of Multi-Pitch Signals Shigeki Sagayama, Hirokazu Kameoka, Shoichiro Saito and Takuya Nishimoto The University of Tokyo, Hongo, Bunkyo-ku, Tokyo 113-8656 Japan E-mail: fsagayama,kameoka,saito,[email protected] Abstract— In this paper, we discuss a new concept of specmurt [8], [9], [10], [11], [12], [13]. Reliable determination of the to analyze multi-pitch signals. It is applied to polyphonic music number of sound sources is discussed only recently [14]. signal to extract fundamental frequencies, to produce a piano- As for spectral analysis, wavelet transform using the Gabor roll-like display, and to convert the saound into MIDI data. In contrast with cepstrum which is the inverse Fourier trans- function is one of the popular approach to derive short-time form of log-scaled power spectrum with linear frequency, spec- power spectrum of music signals along logarithmically-scaled murt is defined as the inverse Fourier transform of linear power frequency axis that appropriately suits the music pitch scaling. spectrum with log-scaled frequency. If all tones in a polyphonic Spectrogram, i.e., a 2-dimensional time-frequency display of sound have a common harmonic pattern, it can be regarded as the sequence of short-time spectra, however, is apparently a sum of frequency-stretched common harmonic structure. In the log-frequency domain, it is formulated as the convolution of messed up because of the existence of many overtones (i.e., the distribution density of fundamental frequencies of multiple tones harmonic components of multiple fundamental frequencies), and the common harmonic structure. The fundamental frequency that often prevents us from discovering music notes. -

The Exit-Wave Power-Cepstrum Transform for Scanning Nanobeam Electron Diffraction: Robust Strain Mapping at Subnanometer Resolution and Subpicometer Precision
The Exit-Wave Power-Cepstrum Transform for Scanning Nanobeam Electron Diffraction: Robust Strain Mapping at Subnanometer Resolution and Subpicometer Precision Elliot Padgett1, Megan E. Holtz1,2, Paul Cueva1, Yu-Tsun Shao1, Eric Langenberg2, Darrell G. Schlom2,3, David A. Muller1,3 1 School of Applied and Engineering Physics, Cornell University, Ithaca, New York 14853, United States 2 Department of Materials Science and Engineering, Cornell University, Ithaca, New York 14853, United States 3 Kavli Institute at Cornell for Nanoscale Science, Ithaca, New York 14853, United States Abstract Scanning nanobeam electron diffraction (NBED) with fast pixelated detectors is a valuable technique for rapid, spatially resolved mapping of lattice structure over a wide range of length scales. However, intensity variations caused by dynamical diffraction and sample mistilts can hinder the measurement of diffracted disk centers as necessary for quantification. Robust data processing techniques are needed to provide accurate and precise measurements for complex samples and non-ideal conditions. Here we present an approach to address these challenges using a transform, called the exit wave power cepstrum (EWPC), inspired by cepstral analysis in audio signal processing. The EWPC transforms NBED patterns into real-space patterns with sharp peaks corresponding to inter-atomic spacings. We describe a simple analytical model for interpretation of these patterns that cleanly decouples lattice information from the intensity variations in NBED patterns caused by tilt and thickness. By tracking the inter-atomic spacing peaks in EWPC patterns, strain mapping is demonstrated for two practical applications: mapping of ferroelectric domains in epitaxially strained PbTiO3 films and mapping of strain profiles in arbitrarily oriented core-shell Pt-Co nanoparticle fuel-cell catalysts. -

Study Paper for Timbre Identification in Sound
International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 Vol. 2 Issue 10, October - 2013 Study paper for Timbre identification in Sound Abhilasha Preety Goswami Prof. Makarand Velankar Cummins College of Cummins College of Cummins College of Engineering, Pune Engineering, Pune Engineering,Pune movement of the tongue along the horizontal and Abstract vertical axes. Well specified positions of the mouth Acoustically, all kind of sounds are similar, but they and the tongue can produce the standardized sounds are fundamentally different. This is partly because of the speech vowels, and are also capable of they encode information in fundamentally different imitating many natural sounds. ways. Timbre is the quality of sound which This paper attempts to analyze different methods for differentiates different sounds. These differences are timbre identification and detail study for two methods related to some interesting but difficult questions is done. MFCC (Mel Frequency Cepstrum about timbre. Study has been done to distinguish Coefficients) and Formant analysis are the two main between sounds of different musicals instruments and methods focused on in this paper. Comparative study other sounds. This requires analysis of fundamental of these methods throws more light on the possible properties of sound .We have done exploration about outcomes using them. We have also explored formant timbre identification methods used by researchers in analysis using tool PRAAT and its possible use for music information retrieval. We have observed the timbre identification. major method used by many as MFCC analysis. We have covered two methods i.e. MFCC and Formant 2. Properties of sounds for timbre analysis in more details and done comparison of them. -

L9: Cepstral Analysis
L9: Cepstral analysis • The cepstrum • Homomorphic filtering • The cepstrum and voicing/pitch detection • Linear prediction cepstral coefficients • Mel frequency cepstral coefficients This lecture is based on [Taylor, 2009, ch. 12; Rabiner and Schafer, 2007, ch. 5; Rabiner and Schafer, 1978, ch. 7 ] Introduction to Speech Processing | Ricardo Gutierrez-Osuna | CSE@TAMU 1 The cepstrum • Definition – The cepstrum is defined as the inverse DFT of the log magnitude of the DFT of a signal 푐 푛 = ℱ−1 log ℱ 푥 푛 • where ℱ is the DFT and ℱ−1 is the IDFT – For a windowed frame of speech 푦 푛 , the cepstrum is 푁−1 푁−1 2휋 2휋 −푗 푘푛 푗 푘푛 푐 푛 = log 푥 푛 푒 푁 푒 푁 푛=0 푛=0 푋 푘 푋 푘 푥 푛 DFT log IDFT 푐 푛 Introduction to Speech Processing | Ricardo Gutierrez-Osuna | CSE@TAMU 2 ℱ 푥 푛 log ℱ 푥 푛 −1 ℱ log ℱ 푥 푛 [Taylor, 2009] Introduction to Speech Processing | Ricardo Gutierrez-Osuna | CSE@TAMU 3 • Motivation – Consider the magnitude spectrum ℱ 푥 푛 of the periodic signal in the previous slide • This spectra contains harmonics at evenly spaced intervals, whose magnitude decreases quite quickly as frequency increases • By calculating the log spectrum, however, we can compress the dynamic range and reduce amplitude differences in the harmonics – Now imagine we were told that the log spectra was a waveform • In this case, we would we would describe it as quasi-periodic with some form of amplitude modulation • To separate both components, we could then employ the DFT • We would then expect the DFT to show – A large spike around the “period” of the signal, and – Some “low-frequency” -

ECW-706 Lecture 9 Ver. 1.1 1 Cepstrum Alanysis a Cepstrum Is
ECW-706 Lecture 9 Cepstrum Alanysis A cepstrum is the Fourier transform of the decibel spectrum as if it were a signal. Operations on cepstra are labeled quefrency alanysis, liftering, or cepstral analysis. This analysis is done to estimate the rate of change in the different spectrum bands. It was originally invented for characterizing the seismic echoes resulting from earthquakes and bomb explosions. It has also been used to analyze radar signal returns. Real Ceptrum 휋 1 푗휔 푗휔푛 푐 푛 = log 푋 푒 푒 푑휔 2휋 −휋 Complex Ceptrum 휋 1 푗휔 푗휔푛 푥 푛 = log 푋 푒 푒 푑휔 2휋 −휋 Complex cepstrum is actually the inverse transform of the complex logarithm Fourier transform of the input. Accepted terminology for cepstrum is now inverse FT of log of magnitude of the power spectrum of a signal. Power cepstrum Square of the Fourier transform of the logarithm of the squared magnitude of the Fourier transform of a signal real cepstrum = 0.5*(complex cepstrum + time reversal of complex cepstrum). phase spectrum = (complex cepstrum - time reversal of complex cepstrum).^2 Ver. 1.1 1 ECW-706 Lecture 9 Applications It is used for voice identification, pitch detection. The independent variable of a cepstral graph is called the quefrency. The quefrency is a measure of time, though not in the sense of a signal in the time domain. Liftering A filter that operates on a cepstrum might be called a lifter. A low pass lifter is similar to a low pass filter in the frequency domain. It can be implemented by multiplying by a window in the cepstral domain and when converted back to the time domain, resulting in a smoother signal. -

Pitch Tracking
Lecture 7 Pitch Analysis What is pitch? • (ANSI) That attribute of auditory sensation in terms of which sounds may be ordered on a scale extending from low to high. Pitch depends mainly on the frequency content of the sound stimulus, but also depends on the sound pressure and waveform of the stimulus. • (operational) A sound has a certain pitch if it can be reliably matched to a sine tone of a given frequency at 40 dB SPL. ECE 272/472 (AME 272, TEE 272) – Audio Signal Processing, Zhiyao Duan, 2018 2 What is pitch? • A perceptual attribute, so subjective • Only defined for (quasi) harmonic sounds – Harmonic sounds are periodic, and the period is 1/F0. • Can be reliably matched to fundamental frequency (F0) – In audio signal processing, people do not often discriminate pitch from F0 • F0 is a physical attribute, so objective ECE 272/472 (AME 272, TEE 272) – Audio Signal Processing, Zhiyao Duan, 2018 3 Harmonic Sound • A complex sound with strong sinusoidal components at integer multiples of a fundamental frequency. These components are called harmonics or overtones. • Sine waves and harmonic sounds are the sounds that may give a perception of “pitch”. ECE 272/472 (AME 272, TEE 272) – Audio Signal Processing, Zhiyao Duan, 2018 4 Classify Sounds by Harmonicity • Sine wave • Strongly harmonic Oboe Clarinet ECE 272/472 (AME 272, TEE 272) – Audio Signal Processing, Zhiyao Duan, 2018 5 Classify Sounds by Harmonicity • Somewhat harmonic (quasi-harmonic) Marimba 0.3 40 0.2 20 Human 0.1 0 voice 0 Amplitude -20 -0.1 (dB) Magnitude -0.2 -40 0 5 10 -

Digital Signal Processing of Multi-Echo Interference for Angle Modulated Signal
DIGITAL SIGNAL PROCESSING OF MULTI-ECHO INTERFERENCE FOR ANGLE MODULATED SIGNAL by GWO-HANN JAIN, B.S. in Eng. A THESIS IN ELECTRICAL ENGINEERING Submitted to the Graduate Faculty of Texas Tech University In Partial Fulfillment of the Requirements for the Degree of MASTER OF SCIENCE IN ELECTRICAL ENGINEERING Approved Accepted August, 1982 iVo. • f ACKNOWLEDGEMENTS I am deeply indebted to Dr. Donald L. Gustafson, the chairman of my degree committee, for his continual encouragement, direction, patience and -help throughout my graduate study. My sincere gratitude is also expressed to committee members. Dr. Kwong Shu Chao and Dr. Wayne T. Ford, for their suggestions and criticism. Thanks to Dr. John J. Murray for his help in solving a lot of mathematical problems. Mrs. Burtis* help in preparing the thesis is also appreciated. A special thanks to my wife, Chai-Fen, for her patience, encouragement, support with all the details. ii TABLE OF CONTENTS ACKNOWLEDGEMENTS ii LIST OF FIGURES v CHAPTER pag:e I. INTRODUCTION 1 II. CEPSTRUM TECHNIQUE AND ITS IMPROVEMENT 6 Introduction 6 The Power Cepstrum 8 „ The complex Cepstrum l1 Phase Unwrapping 14 Comb filter 17 A Different Cepstrum Technique l8 Cepstrums with noise embedded 21 Summary 24 III. EXPERIMENTAL RESULTS OF THE COMPUTER SIMULATION . 25 Introduction 25 Cepstrum of free-noise single-echo case .... 29 Different cepstrum of noiseless single-echo case 35 Cepstrum of noiseless multi-echo case 36 Different cepstrum of noiseless multi-echo case. 41 Cepstrums with noise embedded case 4l Different cepstrum with noise embedded case . 43 Summary 5 3 IV. ALGORITHMS FOR SIMULATION, DIGITAL FILTER AND ECHO DETECTION 54 Introduction 54 Simulation Algorithm 54 1:1 Digital Filter Algorithm 56 Echo Detection Algorithm 59 V.