A Large Scale Empirical Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Histcoroy Pyright for Online Information and Ordering of This and Other Manning Books, Please Visit Topwicws W.Manning.Com
www.allitebooks.com HistCoroy pyright For online information and ordering of this and other Manning books, please visit Topwicws w.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact Tutorials Special Sales Department Offers & D e al s Manning Publications Co. 20 Baldwin Road Highligh ts PO Box 761 Shelter Island, NY 11964 Email: [email protected] Settings ©2017 by Manning Publications Co. All rights reserved. Support No part of this publication may be reproduced, stored in a retrieval system, or Sign Out transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps. Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books we publish printed on acidfree paper, and we exert our best efforts to that end. Recognizing also our responsibility to conserve the resources of our planet, Manning books are printed on paper that is at least 15 percent recycled and processed without the use of elemental chlorine. Manning Publications Co. PO Box 761 Shelter Island, NY 11964 www.allitebooks.com Development editor: Cynthia Kane Review editor: Aleksandar Dragosavljević Technical development editor: Stan Bice Project editors: Kevin Sullivan, David Novak Copyeditor: Sharon Wilkey Proofreader: Melody Dolab Technical proofreader: Doug Warren Typesetter and cover design: Marija Tudor ISBN 9781617292576 Printed in the United States of America 1 2 3 4 5 6 7 8 9 10 – EBM – 22 21 20 19 18 17 www.allitebooks.com HistPoray rt 1. -

Beyond Relational Databases
EXPERT ANALYSIS BY MARCOS ALBE, SUPPORT ENGINEER, PERCONA Beyond Relational Databases: A Focus on Redis, MongoDB, and ClickHouse Many of us use and love relational databases… until we try and use them for purposes which aren’t their strong point. Queues, caches, catalogs, unstructured data, counters, and many other use cases, can be solved with relational databases, but are better served by alternative options. In this expert analysis, we examine the goals, pros and cons, and the good and bad use cases of the most popular alternatives on the market, and look into some modern open source implementations. Beyond Relational Databases Developers frequently choose the backend store for the applications they produce. Amidst dozens of options, buzzwords, industry preferences, and vendor offers, it’s not always easy to make the right choice… Even with a map! !# O# d# "# a# `# @R*7-# @94FA6)6 =F(*I-76#A4+)74/*2(:# ( JA$:+49>)# &-)6+16F-# (M#@E61>-#W6e6# &6EH#;)7-6<+# &6EH# J(7)(:X(78+# !"#$%&'( S-76I6)6#'4+)-:-7# A((E-N# ##@E61>-#;E678# ;)762(# .01.%2%+'.('.$%,3( @E61>-#;(F7# D((9F-#=F(*I## =(:c*-:)U@E61>-#W6e6# @F2+16F-# G*/(F-# @Q;# $%&## @R*7-## A6)6S(77-:)U@E61>-#@E-N# K4E-F4:-A%# A6)6E7(1# %49$:+49>)+# @E61>-#'*1-:-# @E61>-#;6<R6# L&H# A6)6#'68-# $%&#@:6F521+#M(7#@E61>-#;E678# .761F-#;)7-6<#LNEF(7-7# S-76I6)6#=F(*I# A6)6/7418+# @ !"#$%&'( ;H=JO# ;(\X67-#@D# M(7#J6I((E# .761F-#%49#A6)6#=F(*I# @ )*&+',"-.%/( S$%=.#;)7-6<%6+-# =F(*I-76# LF6+21+-671># ;G';)7-6<# LF6+21#[(*:I# @E61>-#;"# @E61>-#;)(7<# H618+E61-# *&'+,"#$%&'$#( .761F-#%49#A6)6#@EEF46:1-# -

Data Platforms Map from 451 Research
1 2 3 4 5 6 Azure AgilData Cloudera Distribu2on HDInsight Metascale of Apache Kaa MapR Streams MapR Hortonworks Towards Teradata Listener Doopex Apache Spark Strao enterprise search Apache Solr Google Cloud Confluent/Apache Kaa Al2scale Qubole AWS IBM Azure DataTorrent/Apache Apex PipelineDB Dataproc BigInsights Apache Lucene Apache Samza EMR Data Lake IBM Analy2cs for Apache Spark Oracle Stream Explorer Teradata Cloud Databricks A Towards SRCH2 So\ware AG for Hadoop Oracle Big Data Cloud A E-discovery TIBCO StreamBase Cloudera Elas2csearch SQLStream Data Elas2c Found Apache S4 Apache Storm Rackspace Non-relaonal Oracle Big Data Appliance ObjectRocket for IBM InfoSphere Streams xPlenty Apache Hadoop HP IDOL Elas2csearch Google Azure Stream Analy2cs Data Ar2sans Apache Flink Azure Cloud EsgnDB/ zone Platforms Oracle Dataflow Endeca Server Search AWS Apache Apache IBM Ac2an Treasure Avio Kinesis LeanXcale Trafodion Splice Machine MammothDB Drill Presto Big SQL Vortex Data SciDB HPCC AsterixDB IBM InfoSphere Towards LucidWorks Starcounter SQLite Apache Teradata Map Data Explorer Firebird Apache Apache JethroData Pivotal HD/ Apache Cazena CitusDB SIEM Big Data Tajo Hive Impala Apache HAWQ Kudu Aster Loggly Ac2an Ingres Sumo Cloudera SAP Sybase ASE IBM PureData January 2016 Logic Search for Analy2cs/dashDB Logentries SAP Sybase SQL Anywhere Key: B TIBCO Splunk Maana Rela%onal zone B LogLogic EnterpriseDB SQream General purpose Postgres-XL Microso\ Ry\ X15 So\ware Oracle IBM SAP SQL Server Oracle Teradata Specialist analy2c PostgreSQL Exadata -

Research Document
Research Document Student Name: James Heneghan Student ID: C00155861 Course ID: CW_KCSOF_B Project Name: Take Me There Supervisor: Joseph Kehoe Institute: Institute of Technology Carlow Date: 16/10/2014 1 Contents Introduction ............................................................................................................................................ 3 Galileo Board ........................................................................................................................................... 3 Details of the Architecture .................................................................................................................. 3 Communication ................................................................................................................................... 3 Accelerometer......................................................................................................................................... 4 Cloud Hosting .......................................................................................................................................... 4 Google Maps API ..................................................................................................................................... 4 Google Maps JavaScript API ................................................................................................................ 4 Google Static Maps API ...................................................................................................................... -

Data Managementmanagementdata for Scientific Research
DDaattaa MMaannaaggeemmeenntt For Scientific Research Photo: © Stanza. Used with permission. CCoouurrssee IInnttrroodduuccttiioonn Welcome to a course in data management for scientific research projects. CCoouurrssee SSttrruuccttuurree Casual “guided” study-group approach Presentations, demos, hands-on exercises, discussions and “homework” Materials: A textbook, eBooks, websites, and online videos WWhhyy TTaakkee TThhiiss CCoouurrssee?? PracticalComputing.org Researchers work with increasing amounts of data. Many students do not have training in data management. Science degree programs generally do not address this gap. It is difficult for “non-majors” to get into IT courses. This leaves students and research teams struggling to cope. And therefore places a heavy burden on IT support. Our data management course provides the needed skills to address these issues. Exciting new discoveries await those who can effectively sift through mounds of data! Participant IntroductionsIntroductionsParticipant Please introduce yourself and share your: Degree program and emphasis Research area (general topic) Your current research project (specific topic) The types of data or data systems you use in this project What you hope to get out of this course Session 1: Data System Essentials How will you manage your data? You need a data system. There are many choices. To pick the best one, you need to state your requirements. Photo: NASA Today's Learning Objectives In this session, you will … Become familiar with common types of data systems Learn to differentiate between flat files and relational databases Learn to differentiate between spreadsheets and databases Learn how to model system functions and interactions Learn how to create system diagrams Learn how to state system requirements Ultimately, this knowledge will help you select or design the best data system for your needs. -

Webscalesql : Basic Details and Installation
The Customize Windows Technology Blog http://thecustomizewindows.com WebScaleSQL : Basic Details and Installation Author : Abhishek WebScaleSQL is a modified MySQL Database developed by Engineers at Facebook, Google, LinkedIn, and Twitter for making kind of scalable SQL. Everyone knows about MySQL Database. Those who do not know what is MySQL, they can read our previously published article - What is MySQL, Why We Need MySQL. At the time of publishing this article; WebScaleSQL is on everyone's lips. MySQL is great, but it is not intended to be Scalable when it was written, that is the basic reason why we try to make Scalable MySQL Database for CMS like WordPress in a kind of legacy mode. WebScaleSQL is kind of fork of MySQL. WebScaleSQL : Basics Need for the Approach Flexibility and Scalability are the Key Benefits of Cloud Computing. Again, Scalability and Service Continuity are Not equivalent. There is another a MySQL Improved Extension - MySQLi. There are reasons why NoSQL Movement was started. 1 / 4 The Customize Windows Technology Blog http://thecustomizewindows.com Official website of WebScaleSQL is : http://webscalesql.org/ But, we do not need the official website, but the Github repository : https://github.com/webscalesql/webscalesql-5.6/tree/webscalesql-5.6.16 2 / 4 The Customize Windows Technology Blog http://thecustomizewindows.com Do you know that, PostgreSQL; one of the most popular noSQL database actually can be used instead of MySQL for WordPress? MariaDB is constantly merged with MySQL community edition. Instead of writing vague collected data on WebScaleSQL, let us install WebScaleSQL. WebScaleSQL : Installation In order to test WebScaleSQL, we will need the following dependencies : + cmake + gcc + libaio-dev + libncurses5-dev + libreadline- dev + bison + git + perl I believe, WebScaleSQL is not intended for use on a VirtualBox as a Virtual Appliance. -

A Novel Approach for Estimating Truck Factors
A Novel Approach for Estimating Truck Factors Guilherme Avelino∗y, Leonardo Passosz, Andre Hora∗ and Marco Tulio Valente∗ ∗ASERG Group, Department of Computer Science (DCC) Federal University of Minas Gerais (UFMG), Brazil Email: fgaa, mtov, [email protected] y Department of Computing (DC) Federal University of Piaui (UFPI), Brazil zUniversity of Waterloo, Canada Email: [email protected] Abstract—Truck Factor (TF) is a metric proposed by the agile for TF-estimation for which we apply to a target corpus community as a tool to identify concentration of knowledge comprising 133 systems in GitHub. In total, such systems in software development environments. It states the minimal have over 373K files and 41 MLOC; their combined evolution number of developers that have to be hit by a truck (or quit) before a project is incapacitated. In other words, TF helps history sums to over 2 million commits. By surveying and to measure how prepared is a project to deal with developer analyzing answers from 67 target systems, we evidence that in turnover. Despite its clear relevance, few studies explore this 84% of valid answers developers agree or partially agree that metric. Altogether there is no consensus about how to calculate it, the TF’s authors are the main authors of their systems; in 53% and no supporting evidence backing estimates for systems in the we receive a positive or partially positive answer regarding our wild. To mitigate both issues, we propose a novel (and automated) approach for estimating TF-values, which we execute against estimated truck factors. a corpus of 133 popular project in GitHub. -

Facebook Mysql Async.Pdf
Asynchronous MySQL How Facebook Queries Databases Chip Turner – [email protected] 2014-04-02 Our Codebase § A fancy website written in PHP (which became Hack) § Grew organically over time § Accrued technical debt, then paid it off as we scaled § Many backend services written in C++ § Operations tools (99% Python, 1% PHP, 1% Perl, 1% …) Our Servers and Network § Hundreds of thousands of servers § “Many, many” webservers § “Many” databases § Sharded data model § Single master, multiple replicas § One copy of each shard in each datacenter § Multiple datacenters worldwide A Sense of Scale § PHP code issues 10,000 QPS … of errors § Connection refused, failovers, solar flares, timeouts, you name it § Retries usually make these invisible to the application § 12,000,000 QPS of actual queries from webservers § 8,400,000 QPS of Async MySQL queries (up from 0 one year ago) § Average query time: 9ms § 30 hours of queries executed per second § This is just PHP – does not include TAO, warehousing, or other use cases DB Client Team § Formed a team in early 2013 to focus on database client issues § Most original database client code came along as necessary, not designed § Problem space is both querying databases and finding the right database to query; this is surprisingly tricky § Primarily OLTP workload § Usability, security, reliability are all goals Security - http://xkcd.com/327/ Security team also focuses on this area; joint responsibility. They make it secure, we make it easier to use. Different Kinds of Performance § Throughput § Queries per second or -

Alibaba Open-Source Fast Facts 2019 November
Alibaba Open-source Fast Facts 2019 November Overview Since the first batch of open-source projects launched in 2011, developers at Alibaba have been actively contributing to open-source communities. Alibaba now boasts over 180 open-source projects, contributing codes to all aspects of software solutions, including cloud infrastructure and machine learning, container, enterprise-class system, database and network. Alibaba and its computing arm Alibaba Cloud have been taking prominent role in a number of worlds’ leading open-source communities, such as Linux Foundation, Apache Software Foundation, MariaDB Foundation, Cloud Foundry Foundation, Cloud Native Computing Foundation ⚫ In the star ranking of world’s largest developer community Github, Alibaba has gained over 690,000 stars, with about 20,000 contributors, as one of the top ten organizations. ⚫ Since 2011, Alibaba has contributed to open source communities including Cloud Native Computing Foundation, Aliance for Open Media, Cloud Foundry, Hyperledger, Open Container Initiative, Continuous Delivery Foundation, The Apache Software Foundation, MariaDB Foundation, The Linux Foundation. ⚫ Linux Community, Alibaba has contributed over 290 patches ⚫ Alibaba’s open-source project “Dubbo” “RocketMQ” “Weex” “JStorm” were donated to Apache Foundation, “Dubbo” and RockeMQ became the top-level project at Apache ⚫ Alibaba Cloud’s OSS has become the third official recognized cloud storage by Hadoop ⚫ Alibaba Cloud has helped MySQL to identify nearly 300 bugs, contributed all the patches to MariaDB -

Recent Trends in Data Persistence and Analysis
SQL Strikes Back Recent Trends in Data Persistence and Analysis Codemesh 2014 November 4, 2014 Dean Wampler, Ph.D [email protected] ©Typesafe 2014 – All Rights Reserved Tuesday, November 4, 14 All photos are copyright (C) 2008 - 2014, Dean Wampler. All Rights Reserved. Photo: Before dawn above the Western USA [email protected] polyglotprogramming.com/talks @deanwampler ©Typesafe 2014 – All Rights Reserved 2 Tuesday, November 4, 14 Typesafe provides products and services for building Reactive, Big Data applications typesafe.com/reactive-big-data ©Typesafe 2014 – All Rights Reserved 3 Tuesday, November 4, 14 For @coderoshi... Cat meme! ©Typesafe 2014 – All Rights Reserved 4 Tuesday, November 4, 14 If you were at Eric Raymond’s (@coderoshi’s) talk... My cat Oberon. Three Trends ©Typesafe 2014 – All Rights Reserved 5 Tuesday, November 4, 14 Three trends to organizer our thinking… Photo: Dusk over the American Midwest, in Winter Data Size ⬆ ©Typesafe 2014 – All Rights Reserved 6 Tuesday, November 4, 14 Data volumes are obviously growing… rapidly. Facebook now has over 600PB (Petabytes) of data in Hadoop clusters! Formal Schemas ⬇ ©Typesafe 2014 – All Rights Reserved 7 Tuesday, November 4, 14 There is less emphasis on “formal” schemas and domain models, i.e., both relaonal models of data and OO models, because data schemas and sources change rapidly, and we need to integrate so many disparate sources of data. So, using relavely-agnos^c so_ware, e.g., collec^ons of things where the so_ware is more agnos^c about the structure of the data and the domain, tends to be faster to develop, test, and deploy. -
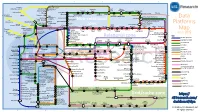
Data Platforms
1 2 3 4 5 6 Towards Apache Storm SQLStream enterprise search Treasure AWS Azure Apache S4 HDInsight DataTorrent Qubole Data EMR Hortonworks Metascale Lucene/Solr Feedzai Infochimps Strao Doopex Teradata Cloud T-Systems MapR Apache Spark A Towards So`ware AG ZeUaset IBM Azure Databricks A SRCH2 IBM for Hadoop E-discovery Al/scale BigInsights Data Lake Oracle Big Data Cloud Guavus InfoSphere CenturyLink Data Streams Cloudera Elas/c Lokad Rackspace HP Found Non-relaonal Oracle Big Data Appliance Autonomy Elas/csearch TIBCO IBM So`layer Google Cloud StreamBase Joyent Apache Hadoop Platforms Oracle Azure Dataflow Data Ar/sans Apache Flink Endeca Server Search AWS xPlenty zone IBM Avio Kinesis Trafodion Splice Machine MammothDB Presto Big SQL CitusDB Hadapt SciDB HPCC AsterixDB IBM InfoSphere Starcounter Towards NGDATA SQLite Apache Teradata Map Data Explorer Firebird Apache Apache Crate Cloudera JethroData Pivotal SIEM Tajo Hive Drill Impala HD/HAWQ Aster Loggly Sumo LucidWorks Ac/an Ingres Big Data SAP Sybase ASE IBM PureData June 2015 Logic for Analy/cs/dashDB Logentries SAP Sybase SQL Anywhere Key: B TIBCO EnterpriseDB B LogLogic Rela%onal zone SQream General purpose Postgres-XL Microso` vFabric Postgres Oracle IBM SAP SQL Server Oracle Teradata Specialist analy/c Splunk PostgreSQL Exadata PureData HANA PDW Exaly/cs -as-a-Service Percona Server MySQL MarkLogic CortexDB ArangoDB Ac/an PSQL XtremeData BigTables OrientDB MariaDB Enterprise MariaDB Oracle IBM Informix SQL HP NonStop SQL Metamarkets Druid Orchestrate Sqrrl Database DB2 Server -

Co-Change Clustering
LUCIANA LOURDES SILVA CO-CHANGE CLUSTERING Thesis presented to the Graduate Program in Computer Science of the Federal Univer- sity of Minas Gerais in partial fulfillment of the requirements for the degree of Doctor in Computer Science. Advisor: Marco Túlio de Oliveira Valente Co-Advisor: Marcelo de Almeida Maia Belo Horizonte October 30, 2015 Abstract Modularity is a key concept to embrace when designing complex software systems. Nonetheless, modular decomposition is still a challenge after decades of research on new techniques for software modularization. One reason is that modularization might not be viewed with single lens due to the multiple facets that a software must deal with. Research in programming languages still tries to define new modularization mechanisms to deal with these different facets, such as aspects and features. Addition- ally, the traditional modular structure defined by the package hierarchy suffers from the dominant decomposition problem and it is widely accepted that alternative forms of modularization are necessary to increase developer’s productivity. In order to con- tribute with a solution to this problem, in this thesis we propose a novel technique to assess package modularity based on co-change clusters, which are highly inter-related source code files considering co-change relations. The co-change clusters are classified in six patterns regarding their projection to the package structure: Encapsulated, Well- Confined, Crosscutting, Black-Sheep, Octopus, and Squid. We evaluated our technique in three different fronts: (i) a quantitative analysis on four real-world systems, (ii) a qualitative analysis on six systems implemented in two languages to reveal developer’s perception of co-change clusters, (iii) a large scale study in a corpus of 133 GitHub projects implemented in six programming languages.