Windows 10 System Programming, Part 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Semi-Automated Parallel Programming in Heterogeneous Intelligent Reconfigurable Environments (SAPPHIRE) Sean Stanek Iowa State University
Iowa State University Capstones, Theses and Graduate Theses and Dissertations Dissertations 2012 Semi-automated parallel programming in heterogeneous intelligent reconfigurable environments (SAPPHIRE) Sean Stanek Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/etd Part of the Computer Sciences Commons Recommended Citation Stanek, Sean, "Semi-automated parallel programming in heterogeneous intelligent reconfigurable environments (SAPPHIRE)" (2012). Graduate Theses and Dissertations. 12560. https://lib.dr.iastate.edu/etd/12560 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Graduate Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Semi-automated parallel programming in heterogeneous intelligent reconfigurable environments (SAPPHIRE) by Sean Stanek A dissertation submitted to the graduate faculty in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Major: Computer Science Program of Study Committee: Carl Chang, Major Professor Johnny Wong Wallapak Tavanapong Les Miller Morris Chang Iowa State University Ames, Iowa 2012 Copyright © Sean Stanek, 2012. All rights reserved. ii TABLE OF CONTENTS LIST OF TABLES ..................................................................................................................... -
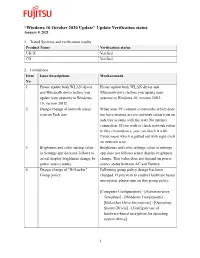
“Windows 10 October 2020 Update” Update Verification Status January 8, 2021
“Windows 10 October 2020 Update” Update Verification status January 8, 2021 1. Tested Systems and verification results Product Name Verification status UH-X Verified CH Verified 2. Limitations Item Issue descriptions Workarounds No 1 Please update both WLAN driver Please update both WLAN driver and and Bluetooth driver before you Bluetooth driver before you update your update your systems to Windows systems to Windows 10, version 20H2. 10, version 20H2. 2 Design change of network status When your PC connect to networks which does icon on Task tray. not have internet access, network status icon on task tray is same with the state No internet connection. If you wish to check network status in this circumstance, you can check it with flyout menu which is pulled out with right click on network icon. 3 Brightness and color setting value Brightness and color settings value in settings in Settings app does not follows to app does not follows actual display brightness actual display brightness change by change. This value does not depend on power power source status. source status between AC and Battery. 4 Design change of "BitLocker" Following group policy design has been Group policy. changed. If you wish to enable Hardware based encryption, please turn on this group policy. [Computer Configuration] - [Administrative Templates] - [Windows Components] - [BitLocker Drive Encryption] - [Operating System Drives] - [Configure use of hardware-based encryption for operating system drives] 1 Previous design: If the policy is not enabled, Hardware based encryption is enabled as default. New design: If the policy is not enabled, Software based encryption is enabled as default. -

THINC: a Virtual and Remote Display Architecture for Desktop Computing and Mobile Devices
THINC: A Virtual and Remote Display Architecture for Desktop Computing and Mobile Devices Ricardo A. Baratto Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2011 c 2011 Ricardo A. Baratto This work may be used in accordance with Creative Commons, Attribution-NonCommercial-NoDerivs License. For more information about that license, see http://creativecommons.org/licenses/by-nc-nd/3.0/. For other uses, please contact the author. ABSTRACT THINC: A Virtual and Remote Display Architecture for Desktop Computing and Mobile Devices Ricardo A. Baratto THINC is a new virtual and remote display architecture for desktop computing. It has been designed to address the limitations and performance shortcomings of existing remote display technology, and to provide a building block around which novel desktop architectures can be built. THINC is architected around the notion of a virtual display device driver, a software-only component that behaves like a traditional device driver, but instead of managing specific hardware, enables desktop input and output to be intercepted, manipulated, and redirected at will. On top of this architecture, THINC introduces a simple, low-level, device-independent representation of display changes, and a number of novel optimizations and techniques to perform efficient interception and redirection of display output. This dissertation presents the design and implementation of THINC. It also intro- duces a number of novel systems which build upon THINC's architecture to provide new and improved desktop computing services. The contributions of this dissertation are as follows: • A high performance remote display system for LAN and WAN environments. -

Corticon Server: Deploying Web Services with .NET
Corticon Server: Deploying Web Services with .NET Notices Copyright agreement © 2014 Progress Software Corporation and/or its subsidiaries or affiliates. All rights reserved. These materials and all Progress® software products are copyrighted and all rights are reserved by Progress Software Corporation. The information in these materials is subject to change without notice, and Progress Software Corporation assumes no responsibility for any errors that may appear therein. The references in these materials to specific platforms supported are subject to change. Business Making Progress, Corticon, DataDirect (and design), DataDirect Cloud, DataDirect Connect, DataDirect Connect64, DataDirect XML Converters, DataDirect XQuery, Fathom, Making Software Work Together, OpenEdge, Powered by Progress, Progress, Progress Control Tower, Progress OpenEdge, Progress RPM, Progress Software Business Making Progress, Progress Software Developers Network, Rollbase, RulesCloud, RulesWorld, SequeLink, SpeedScript, Stylus Studio, and WebSpeed are registered trademarks of Progress Software Corporation or one of its affiliates or subsidiaries in the U.S. and/or other countries. AccelEvent, AppsAlive, AppServer, BusinessEdge, Progress Easyl, DataDirect Spy, DataDirect SupportLink, Easyl, Future Proof, High Performance Integration, Modulus, OpenAccess, Pacific, ProDataSet, Progress Arcade, Progress Pacific, Progress Profiles, Progress Results, Progress RFID, Progress Responsive Process Management, Progress Software, ProVision, PSE Pro, SectorAlliance, SmartBrowser, -

PDF Xpansion SDK Reference
PDF Xpansion SDK 12 Reference soft Xpansion GmbH & Co. KG ● Königsallee 45, 44789 Bochum [email protected] ● www.soft-xpansion.com TABLE OF CONTENTS INTRODUCTION ................................................................................................................................................................ 5 System Requirements ................................................................................................................................................... 6 Installation of SDK ........................................................................................................................................................ 6 Contents of SDK package ........................................................................................................................................ 6 Reference SDK libraries in Your Projects .................................................................................................................... 7 Replace Trial License ................................................................................................................................................ 8 Update of SDK Files ................................................................................................................................................. 8 SDK Samples................................................................................................................................................................ 9 Redistribution of PDF Xpansion .................................................................................................................................... -

MAXPRO Microsoft Windows Patches.Book
MAXPRO® VMS and NVR Approved Microsoft® Windows Patches Technical Notes MICROSOFT® WINDOWS PATCHES TESTED WITH MAXPRO®NVR AND MAXPRO®VMS Overview The purpose of this document is to identify the patches that have been delivered by Microsoft® Windows and which have been tested against the current shipping ver- sions of MAXPRO®NVR and MAXPRO®VMS with no adverse effects being observed. If you have questions concerning the information in this document, please contact Honeywell Technical Support. See the back cover for contact information. Windows Patches Tested with MAXPRO®NVR till the Month of: June, 2020 Windows Patches Tested with MAXPRO®VMS till the Month of: June, 2020 This document contains: Section See... • June - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on page 5 Windows 10 (Enterprise) • June - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ Client on Windows 2016 Standard and Windows 10 (Enterprise) page 5 • May - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on page 5 Windows 10 (Enterprise) • May - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ Client on Windows 2016 Standard and Windows 10 (Enterprise) page 5 • April - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ page 7 Client on Windows 2016 Standard and Windows 10 (Enterprise) • April - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on Windows 10 (Enterprise) page 7 • March - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ page 8 Client on Windows 2016 Standard and Windows 10 (Enterprise) • March - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on Windows 10 (Enterprise) page 8 • February - 2020- Microsoft® Windows Patches Tested with MAXPRO®VMS Server/ page 8 Client on Windows 2016 Standard and Windows 10 (Enterprise) • February - 2020- Microsoft® Windows Patches Tested with MAXPRO®NVR on Windows 10 (Enterprise) page 8 800-19154V9-K_Microsoft Windows Patches 1 Section See.. -

Reference & Manual
DynaPDF 4.0 Reference & Manual API Reference Version 4.0.59 September 16, 2021 Legal Notices Copyright: © 2003-2021 Jens Boschulte, DynaForms GmbH. All rights reserved. DynaForms GmbH Burbecker Street 24 D-58285 Gevelsberg, Germany Trade Register HRB 9770, District Court Hagen CEO Jens Boschulte Phone: ++49 23 32-666 78 37 Fax: ++49 23 32-666 78 38 If you have questions please send an email to [email protected], or contact us by phone. This publication and the information herein is furnished as is, is subject to change without notice, and should not be construed as a commitment by DynaForms GmbH. DynaForms assumes no responsibility or liability for any errors or inaccuracies, makes no warranty of any kind (express, implied or statutory) with respect to this publication, and expressly disclaims any and all warranties of merchantability, fitness for particular purposes and no infringement of third-party rights. Adobe, Acrobat, and PostScript are trademarks of Adobe Systems Inc. AIX, IBM, and OS/390, are trademarks of International Business Machines Corporation. Microsoft, Windows, and Windows NT are trademarks of Microsoft Corporation. Apple, Mac OS, and Safari are trademarks of Apple Computer, Inc. registered in the United States and other countries. TrueType is a trademark of Apple Computer, Inc. Unicode and the Unicode logo are trademarks of Unicode, Inc. UNIX is a trademark of The Open Group. Solaris is a trademark of Sun Microsystems, Inc. Tru64 is a trademark of Hewlett-Packard. Linux is a trademark of Linus Torvalds. Other company product and service names may be trademarks or service marks of others. -

A Definitive Guide to Windows 10 Management: a Vmware Whitepaper
A Definitive Guide to Windows 10 Management: A VMware Whitepaper November 2015 Table of Contents Executive Summary.................................................................................................................3 Challenges with Windows Management..........................................................................5 How Windows 10 Differs........................................................................................................7 Windows 10 Management Features....................................................................................9 New Methods of Updates......................................................................................................10 New Methods of Enrollment and Device Provisioning................................................11 Unified Application Experiences.........................................................................................13 Domain Joined Management................................................................................................16 Application Delivery.............................................................................................................17 Universal Applications.........................................................................................................17 Classic Windows Applications.........................................................................................17 Cloud-based Applications.................................................................................................17 -

Middleware in Action 2007
Technology Assessment from Ken North Computing, LLC Middleware in Action Industrial Strength Data Access May 2007 Middleware in Action: Industrial Strength Data Access Table of Contents 1.0 Introduction ............................................................................................................. 2 Mature Technology .........................................................................................................3 Scalability, Interoperability, High Availability ...................................................................5 Components, XML and Services-Oriented Architecture..................................................6 Best-of-Breed Middleware...............................................................................................7 Pay Now or Pay Later .....................................................................................................7 2.0 Architectures for Distributed Computing.................................................................. 8 2.1 Leveraging Infrastructure ........................................................................................ 8 2.2 Multi-Tier, N-Tier Architecture ................................................................................. 9 2.3 Persistence, Client-Server Databases, Distributed Data ....................................... 10 Client-Server SQL Processing ......................................................................................10 Client Libraries .............................................................................................................. -

PC Magazine Fighting Spyware Viruses And
01_577697 ffirs.qxd 12/7/04 11:49 PM Page i PC Magazine® Fighting Spyware, Viruses, and Malware Ed Tittel TEAM LinG - Live, Informative, Non-cost and Genuine ! 01_577697 ffirs.qxd 12/7/04 11:49 PM Page ii PC Magazine® Fighting Spyware, Viruses, and Malware Published by Wiley Publishing, Inc. 10475 Crosspoint Boulevard Indianapolis, IN 46256-5774 www.wiley.com Copyright © 2005 by Wiley Publishing Published simultaneously in Canada ISBN: 0-7645-7769-7 Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1 1B/RW/RS/QU/IN No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, (317) 572-3447, fax (317) 572-4355, e-mail: [email protected]. Limit of Liability/Disclaimer of Warranty: The publisher and the author make no representations or warranties with respect to the accuracy or completeness of the contents of this work and specifically disclaim all warranties, including without limitation warranties of fitness for a particular purpose. No warranty may be created or extended by sales or promotional materials. -

Descarga De Software Y Configuración De Azure Education A) Creación De
Descarga de software y configuración de Azure Education a) Creación de cuenta en Azure Education - Ingrese a http://aka.ms/devtoolsforteaching - Seleccione la opción - Inicie sesión con su cuenta Microsoft vinculada a sus correos @udp.cl o @mail.udp.cl (mismas cuentas para descarga de office en https://www.microsoft.com/es- es/education/products/office). Fig. 1: Login - Si usted ya tiene creada si cuenta Microsoft asociada a su correo mail.udp.cl o udp.cl puede realizar el login directamente. En caso de que su cuenta no esté activada, debe realizar primero el registro. - Es probable que se requiera agregar medios de verificación y de recuperación de cuenta por olvido de clave (a través de celular o de correo electrónico alternativo). - Una vez finalizados los pasos anteriores, se debe aceptar los términos y condiciones. El único obligatorio es el primer recuadro de la figura expuesta a continuación). Fig. 2: Términos y condiciones b) Descarga de software para la docencia Una vez finalizado el registro, verá una pantalla Fig. 3: Pantalla inicial Podrá realizar mini-tutoriales (ej: cómo construir web apps en Azure), cursos, descarga de software, entre otros. Para instalar un software específico, debe dar click a la opción “Software” del menú lateral izquierdo, desplegándose todo lo disponible para descarga. Fig. 4: Software Para descargar, debe hacer click en el software de interés. Aparecerá una ventana en el costado derecho de la pantalla. Fig. 5: Descarga de instalador Al dar click en el botón Download comenzará la descarga del instalador. Debe copiar la clave de instalación (Product Key que aparecerá al dar click al botón “View Key”). -
![[MS-ERREF]: Windows Error Codes](https://docslib.b-cdn.net/cover/7109/ms-erref-windows-error-codes-437109.webp)
[MS-ERREF]: Windows Error Codes
[MS-ERREF]: Windows Error Codes Intellectual Property Rights Notice for Open Specifications Documentation . Technical Documentation. Microsoft publishes Open Specifications documentation for protocols, file formats, languages, standards as well as overviews of the interaction among each of these technologies. Copyrights. This documentation is covered by Microsoft copyrights. Regardless of any other terms that are contained in the terms of use for the Microsoft website that hosts this documentation, you may make copies of it in order to develop implementations of the technologies described in the Open Specifications and may distribute portions of it in your implementations using these technologies or your documentation as necessary to properly document the implementation. You may also distribute in your implementation, with or without modification, any schema, IDL's, or code samples that are included in the documentation. This permission also applies to any documents that are referenced in the Open Specifications. No Trade Secrets. Microsoft does not claim any trade secret rights in this documentation. Patents. Microsoft has patents that may cover your implementations of the technologies described in the Open Specifications. Neither this notice nor Microsoft's delivery of the documentation grants any licenses under those or any other Microsoft patents. However, a given Open Specification may be covered by Microsoft Open Specification Promise or the Community Promise. If you would prefer a written license, or if the technologies described in the Open Specifications are not covered by the Open Specifications Promise or Community Promise, as applicable, patent licenses are available by contacting [email protected]. Trademarks. The names of companies and products contained in this documentation may be covered by trademarks or similar intellectual property rights.