Root Failure Analysis in Meshed Tree Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Impact Analysis of System and Network Attacks
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by DigitalCommons@USU Utah State University DigitalCommons@USU All Graduate Theses and Dissertations Graduate Studies 12-2008 Impact Analysis of System and Network Attacks Anupama Biswas Utah State University Follow this and additional works at: https://digitalcommons.usu.edu/etd Part of the Computer Sciences Commons Recommended Citation Biswas, Anupama, "Impact Analysis of System and Network Attacks" (2008). All Graduate Theses and Dissertations. 199. https://digitalcommons.usu.edu/etd/199 This Thesis is brought to you for free and open access by the Graduate Studies at DigitalCommons@USU. It has been accepted for inclusion in All Graduate Theses and Dissertations by an authorized administrator of DigitalCommons@USU. For more information, please contact [email protected]. i IMPACT ANALYSIS OF SYSTEM AND NETWORK ATTACKS by Anupama Biswas A thesis submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in Computer Science Approved: _______________________ _______________________ Dr. Robert F. Erbacher Dr. Chad Mano Major Professor Committee Member _______________________ _______________________ Dr. Stephen W. Clyde Dr. Byron R. Burnham Committee Member Dean of Graduate Studies UTAH STATE UNIVERSITY Logan, Utah 2008 ii Copyright © Anupama Biswas 2008 All Rights Reserved iii ABSTRACT Impact Analysis of System and Network Attacks by Anupama Biswas, Master of Science Utah State University, 2008 Major Professor: Dr. Robert F. Erbacher Department: Computer Science Systems and networks have been under attack from the time the Internet first came into existence. There is always some uncertainty associated with the impact of the new attacks. -

Network Design Reference for Avaya Virtual Services Platform 4000 Series
Network Design Reference for Avaya Virtual Services Platform 4000 Series Release 4.1 NN46251-200 Issue 05.01 January 2015 © 2015 Avaya Inc. applicable number of licenses and units of capacity for which the license is granted will be one (1), unless a different number of All Rights Reserved. licenses or units of capacity is specified in the documentation or other Notice materials available to You. “Software” means computer programs in object code, provided by Avaya or an Avaya Channel Partner, While reasonable efforts have been made to ensure that the whether as stand-alone products, pre-installed on hardware products, information in this document is complete and accurate at the time of and any upgrades, updates, patches, bug fixes, or modified versions printing, Avaya assumes no liability for any errors. Avaya reserves thereto. “Designated Processor” means a single stand-alone the right to make changes and corrections to the information in this computing device. “Server” means a Designated Processor that document without the obligation to notify any person or organization hosts a software application to be accessed by multiple users. of such changes. “Instance” means a single copy of the Software executing at a Documentation disclaimer particular time: (i) on one physical machine; or (ii) on one deployed software virtual machine (“VM”) or similar deployment. “Documentation” means information published by Avaya in varying mediums which may include product information, operating Licence types instructions and performance specifications that Avaya may generally Designated System(s) License (DS). End User may install and use make available to users of its products and Hosted Services. -

Networking Packet Broadcast Storms
Lesson Learned Networking Packet Broadcast Storms Primary Interest Groups Balancing Authorities (BAs) Generator Operators (GOPs) Reliability Coordinators (RCs) Transmission Operators (TOPs) Transmission Owners (TOs) that own and operate an Energy Management System (EMS) Problem Statement When a second network cable was connected from a voice over internet protocol (VOIP) phone to a network switch lacking proper settings, a packet broadcast storm prevented network communications from functioning, and supervisory control and data acquisition (SCADA) was lost for several hours. Broadcast storm events have also arisen from substation local area network (LAN) issues. Details A conference room was set up for a training class that needed to accommodate multiple PCs. The bridge protocol data unit (BPDU) packet propagation prevention setting was disabled on a port in the conference room in order to place a network switch off of that port. Upon completion of the training, the network switch was removed; however, the BPDU packet propagation setting was inadvertently not restored. As part of a telephone upgrade project, the traditional phone in this conference room was recently replaced by a VOIP phone. Later, an additional network cable was connected to the output port of this VOIP phone into a secondary network jack within the conference room. When the second network cable was connected from a VOIP phone to a network switch lacking proper settings, a switching loop resulted. Spanning tree protocol is normally used to prevent switching loops from propagating broadcast packets continuously until the network capacity is overwhelmed. A broadcast packet storm from the switching loop prevented network communications from functioning and SCADA was lost for several hours. -

Understanding Linux Internetworking
White Paper by David Davis, ActualTech Media Understanding Linux Internetworking In this Paper Introduction Layer 2 vs. Layer 3 Internetworking................ 2 The Internet: the largest internetwork ever created. In fact, the Layer 2 Internetworking on term Internet (with a capital I) is just a shortened version of the Linux Systems ............................................... 3 term internetwork, which means multiple networks connected Bridging ......................................................... 3 together. Most companies create some form of internetwork when they connect their local-area network (LAN) to a wide area Spanning Tree ............................................... 4 network (WAN). For IP packets to be delivered from one Layer 3 Internetworking View on network to another network, IP routing is used — typically in Linux Systems ............................................... 5 conjunction with dynamic routing protocols such as OSPF or BGP. You c an e as i l y use Linux as an internetworking device and Neighbor Table .............................................. 5 connect hosts together on local networks and connect local IP Routing ..................................................... 6 networks together and to the Internet. Virtual LANs (VLANs) ..................................... 7 Here’s what you’ll learn in this paper: Overlay Networks with VXLAN ....................... 9 • The differences between layer 2 and layer 3 internetworking In Summary ................................................. 10 • How to configure IP routing and bridging in Linux Appendix A: The Basics of TCP/IP Addresses ....................................... 11 • How to configure advanced Linux internetworking, such as VLANs, VXLAN, and network packet filtering Appendix B: The OSI Model......................... 12 To create an internetwork, you need to understand layer 2 and layer 3 internetworking, MAC addresses, bridging, routing, ACLs, VLANs, and VXLAN. We’ve got a lot to cover, so let’s get started! Understanding Linux Internetworking 1 Layer 2 vs. -

Web Management Guide
Web Management Guide Digital Data Communications GmbH. http://www.level1.com Web Management Guide GTP-2871 28-Port L3 Lite Managed Gigabit PoE Switch GTP-5271 52-Port L3 Lite Managed Gigabit PoE Switch How to Use This Guide This guide includes detailed information on the switch software, including how to operate and use the management functions of the switch. To deploy this switch effectively and ensure trouble-free operation, you should first read the relevant sections in this guide so that you are familiar with all of its software features. Who Should Read This guide is for network administrators who are responsible for operating and this Guide? maintaining network equipment. The guide assumes a basic working knowledge of LANs (Local Area Networks), the Internet Protocol (IP), and Simple Network Management Protocol (SNMP). How this Guide This guide provides detailed information about the switch’s key features. It also is Organized describes the switch’s web browser interface. For information on the command line interface refer to the CLI Reference Guide. The guide includes these sections: u Section I “Web Configuration” — Includes all management options available through the web browser interface. Related This guide focuses on switch software configuration through the web browser. Documentation For information on how to manage the switch through the command line interface, see the following guide: CLI Reference Guide Note: For a description of how to initialize the switch for management access via the CLI, web interface or SNMP, refer to “Initial Switch Configuration” in the CLI Reference Guide. Conventions The following conventions are used throughout this guide to show information: Note: Emphasizes important information or calls your attention to related features or instructions. -

(Rapid) Spanning Tree Protocol
STP – Spanning Tree Protocol indigoo.com STP & RSTP (RAPID) SPANNING TREE PROTOCOL DESCRIPTION OF STP AND RSTP, PROTOCOLS FOR LOOP FREE LAN TOPOLOGIES Peter R. Egli INDIGOO.COM1/57 © Peter R. Egli 2015 Rev. 1.60 STP – Spanning Tree Protocol indigoo.com Contents 1. Goal of STP: Loop-free topology for Ethernet networks 2. STP standards overview 3. IEEE 802.1D STP protocol 4. IEEE 802.1w RSTP Rapid STP 5. IEEE 802.1Q CST Common Spanning Tree 6. Cisco PVST+ and PVRST+ 7. IEEE 802.1s MST Multiple Spanning Tree Protocol 8. STP Pros and Cons 2/57 © Peter R. Egli 2015 Rev. 1.60 STP – Spanning Tree Protocol indigoo.com 1. Goal of STP: Loop-free topology for Ethernet networks Ethernet bridges (or switches) must forward unknown unicast and broadcast Ethernet frames to all physical ports. Therefore Ethernet networks require a loop-free topology, otherwise more and more broadcast and unknown unicast frames would swamp the network (creation of frame duplicates resulting in a broadcast storm). Unknown unicast frame: Frame with a target Ethernet address that is not yet known by the receiving bridge. Broadcast frame: Ethernet frame with a broadcast target Ethernet address, e.g. for protocols such as ARP or BOOTP / DHCP. Broadcast Ethernet frames and unknown unicast frames circle forever in an Ethernet network with loops. 3/57 © Peter R. Egli 2015 Rev. 1.60 STP – Spanning Tree Protocol indigoo.com 2. STP standards overview: A number of different STP ‘standards’ and protocols evolved over time. Standard Description Abbreviation Spanning Tree Protocol • Loop prevention. IEEE 802.1D • Automatic reconfiguration of tree in case of topology changes (e.g. -

Network Storm Testing
NETWORK STORM TESTING VERIFYING THE ROBUSTNESS OF CONTROL SYSTEM COMMUNICATIONS In this white paper, we discuss a stress situation that can impact communication and redundancy of networked control systems. How can this situation arise, and why should we test for it? Furthermore, we look into what we recommend, how control systems should be tested to avoid that their communication is impacted by network overload. 1/7 INTRODUCTION Let us start with a citation from a senior engineer with A normal Ethernet switch forwards broadcast and the major E&P company of Norway: multicast traffic on all its ports. Other (up- or down- link) switches receiving these broadcast or multicast “Be a demanding customer, prior to FAT, messages, will again forward them to all their ports and apply traffic generator packets on network so on. In an Ethernet network, any looped packet might remain on the network forever. A network storm, i.e. a segments to full bandwidth. Peer to Peer, network stress situation can arise in various ways and multicast and broadcast packets. Graceful can cause a Denial of Service (DoS) in the worst case. reconnect after storm or need for restart?” Probably, the most common reason for a network – Sr. IT Security Engineer, Statoil ASA storm is cabling problems, in particular if a cable loop But what is an unexpected network overload, or net- is present. Other factors contributing to a network work storm situation actually? A network storm can be stress situation are: compared to a room full of people talking loudly and making a conversation between 2 individuals impos- Poor network management and monitoring; sible. -

Pakedge SK-8-EP User Guide
SX-8-EP Enterprise-AV, Smart Managed Switches User Guide This device complies with Part 15 of the FCC Rules. Operation is subject to the following two conditions: 1. This device may not cause harmful interference. 2. This device must accept any interference received, including interference that may cause undesired operation. NOTE: This equipment has been tested and found to comply with the limits for a Class B digital device, pursuant to Part 15 of the FCC Rules. These limits are designed to provide reasonable protection against harmful interference in a residential installation. This equipment generates, uses and can radiate radio frequency energy and, if not installed and used in accordance with the instructions, may cause harmful interference to radio communications. However, there is no guarantee that interference will not occur in a particular installation. If this equipment does cause harmful interference to radio or television reception, which can be determined by turning the equipment off and on, the user is encouraged to try to correct the interference by one of the following measures: Reorient or relocate the receiving antenna. Increase the separation between the equipment and receiver. Connect the equipment into an outlet on a circuit different from that to which the receiver is connected. Consult the dealer or an experienced radio/TV technician for help. WARNING: Any changes or modifications not expressly approved by the party responsible for compliance could void the user's authority to operate this equipment. WARNING: TO PREVENT FIRE OR SHOCK HAZARD, DO NOT EXPOSE THIS PRODUCT TO RAIN OR MOISTURE. THE UNIT MUST NOT BE EXPOSED TO DRIPPING OR SPLASHING WATER. -

Location-Based Deferred Broadcast for Ad-Hoc Named Data Networking
future internet Article Location-Based Deferred Broadcast for Ad-Hoc Named Data Networking Meng Kuai *,† ID and Xiaoyan Hong * Department of Computer Science, The University of Alabama, Tuscaloosa, AL 35487, USA * Correspondence: [email protected] (M.K.); [email protected] (X.H.); Tel.: +1-205-454-6260 (M.K.); +1-205-348-4042 (X.H.) † Kuai is currently with GetHired, Inc. 540 University Ave, Palo Alto, CA 94301, USA. Received: 1 May 2019; Accepted: 14 June 2019; Published: 24 June 2019 Abstract: The emerging connected and autonomous vehicles (CAVs) challenge ad hoc wireless multi-hop communications by mobility, large-scale, new data acquisition and computing patterns. The Named Data Networking (NDN) is suitable for such vehicle ad hoc networks due to its information centric networking approach. However, flooding interest packets in ad-hoc NDN can lead to broadcast storm issue. Existing solutions will either increase the number of redundant interest packets or need a global knowledge about data producers. In this paper, a Location-Based Deferred Broadcast (LBDB) scheme is introduced to improve the efficiency and performance of interest broadcast in ad-hoc NDN. The scheme takes advantage of location information to set up timers when rebroadcasting an interest. The LBDB is implemented in V-NDN network architecture using ndnSIM simulator. Comparisons with several existing protocols are conducted in simulation. The results show that LBDB improves the overhead, the average number of hops and delay while maintaining an average satisfaction ratio when compared with several other broadcast schemes. The improvement can help offer timely data acquisition for quick responses in emergent CAV application situations. -

Implementing a Broadcast Storm Attack on a Mission-Critical
Implementing a Broadcast Storm Attack on a Mission-Critical Wireless Sensor Network Irina Krivtsova, Ilya Lebedev, Mikhail Sukhoparov, Nurzhan Bazhayev, Igor Zikratov, Aleksandr Ometov, Sergey Andreev, Pavel Masek, Radek Fujdiak, Jiri Hosek To cite this version: Irina Krivtsova, Ilya Lebedev, Mikhail Sukhoparov, Nurzhan Bazhayev, Igor Zikratov, et al.. Imple- menting a Broadcast Storm Attack on a Mission-Critical Wireless Sensor Network. 14th International Conference on Wired/Wireless Internet Communication (WWIC), May 2016, Thessaloniki, Greece. pp.297-308, 10.1007/978-3-319-33936-8_23. hal-01434859 HAL Id: hal-01434859 https://hal.inria.fr/hal-01434859 Submitted on 13 Jan 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Implementing a Broadcast Storm Attack on a Mission-Critical Wireless Sensor Network Irina Krivtsova1, Ilya Lebedev1, Mikhail Sukhoparov1, Nurzhan Bazhayev1, Igor Zikratov1, Aleksandr Ometov2, Sergey Andreev2, Pavel Masek3, Radek Fujdiak3, and Jiri Hosek3 1 Saint Petersburg National Research University of Information Technologies, Mechanics and Optics (ITMO University), St.Petersburg, Russia 2 Tampere University of Technology, Korkeakoulunkatu 10, FI-33720, Finland 3 Brno University of Technology, Czech Republic, Brno, Technicka 3082/12 Email: [email protected] Abstract. -

Braving the Broadcast Storm: Infrastructural Support for Ad Hoc Routing
Computer Networks 41 (2003) 687–706 www.elsevier.com/locate/comnet Braving the broadcast storm: infrastructural support for ad hoc routing Raghupathy Sivakumar a,*, Prasun Sinha b, Vaduvur Bharghavan c a School of Electrical and Computer Engineering, Georgia Institute of Technology, 777 Atlantic Drive, Atlanta, GA 30332-0250, USA b Bell Labs, Lucent Technologies, Murray Hill, NJ 07974, USA c Meru Networks, Santa Clara, CA 95054, USA Received 12 November 2001; received in revised form 26 June 2002; accepted 6 November 2002 Responsible Editor: B. Yener Abstract Several routing algorithms for mobile ad hoc networks have been proposed in the recent past [Broch et al., The Dynamic Source Routing Protocol for Mobile Ad Hoc Networks, Internet Draft draft-ietf-manet-dsr-03.txt, October 1999; Perkins et al., Ad Hoc On Demand Distance Vector (AODV) Routing, Internet Draft draft-ietf-manet-aodv- 04.txt, October 1999; Haas and Pearlman, The Zone Routing Protocol (ZRP) for Ad Hoc Networks, Internet Draft draft-zone-routing-protocol-01.txt, August 1998; IEEE J. Select. Areas Commun. 17 (8) (1999) 1454]. With the ex- ception of a few, these protocols (i) involve all nodes in the route management process, (ii) rely on the use of broadcast relays for route computation, and (iii) are primarily reactive in nature. Related work [Broch et al., Performance Comparison of Multi-Hop Wireless Ad Hoc Network Routing Protocols, Proceedings of IEEE MOBICOM, Dallas, TX, October 1998; Johansson et al., Scenario-based Performance Analysis of Routing Protocols for Mobile Ad-hoc Networks, Proceedings of IEEE MOBICOM, Seattle, August 1999] has shown that the capacity utilization in ad hoc networks decreases significantly when broadcast relays or ‘‘broadcast storms’’ are performed frequently. -
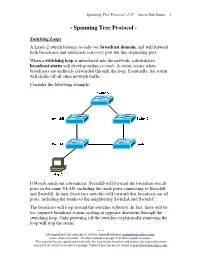
Spanning Tree Protocol (STP)
Spanning Tree Protocol v1.31 – Aaron Balchunas 1 - Spanning Tree Protocol - Switching Loops A Layer-2 switch belongs to only one broadcast domain, and will forward both broadcasts and multicasts out every port but the originating port. When a switching loop is introduced into the network, a destructive broadcast storm will develop within seconds . A storm occurs when broadcasts are endlessly forwarded through the loop. Eventually, the storm will choke off all other network traffic. Consider the following example: If HostA sends out a broadcast, SwitchD will forward the broadcast out all ports in the same VLAN, including the trunk ports connecting to SwitchB and SwitchE. In turn, those two switches will forward that broadcast out all ports, including the trunks to the neighboring SwitchA and SwitchC. The broadcast will loop around the switches infinitely . In fact, there will be two separate broadcast storms cycling in opposite directions through the switching loop. Only powering off the switches or physically removing the loop will stop the storm. * * * All original material copyright © 2014 by Aaron Balchunas ([email protected] ), unless otherwise noted. All other material copyright © of their respective owners. This material may be copied and used freely, but may not be altered or sold without the expressed written consent of the owner of the above copyright. Updated material may be found at http://www.routeralley.com . Spanning Tree Protocol v1.31 – Aaron Balchunas 2 Spanning Tree Protocol (STP) Spanning Tree Protocol (STP) was developed to prevent the broadcast storms caused by switching loops. STP was originally defined in IEEE 802.1D .