Array Optimizations for High Productivity Programming Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Introduction Code Reuse
The Sather Language: Efficient, Interactive, Object-Oriented Programming Stephen Omohundro Dr. Dobbs Journal Introduction Sather is an object oriented language which aims to be simple, efficient, interactive, safe, and non-proprietary. One way of placing it in the "space of languages" is to say that it aims to be as efficient as C, C++, or Fortran, as elegant and safe as Eiffel or CLU, and to support interactive programming and higher-order functions as well as Common Lisp, Scheme, or Smalltalk. Sather has parameterized classes, object-oriented dispatch, statically-checked strong typing, separate implementation and type inheritance, multiple inheritance, garbage collection, iteration abstraction, higher-order routines and iters, exception handling, constructors for arbitrary data structures, and assertions, preconditions, postconditions, and class invariants. This article describes the first few of these features. The development environment integrates an interpreter, a debugger, and a compiler. Sather programs can be compiled into portable C code and can efficiently link with C object files. Sather has a very unrestrictive license which allows its use in proprietary projects but encourages contribution to the public library. The original 0.2 version of the Sather compiler and tools was made available in June 1991. This article describes version 1.0. By the time the article appears, the combined 1.0 compiler/interpreter/debugger should be available on "ftp.icsi.berkeley.edu" and the newsgroup "comp.lang.sather" should be activated for discussion. Code Reuse The primary benefit promised by object-oriented languages is reuse of code. Sather programs consist of collections of modules called "classes" which encapsulate well-defined abstractions. -

Efficient Run Time Optimization with Static Single Assignment
i Jason W. Kim and Terrance E. Boult EECS Dept. Lehigh University Room 304 Packard Lab. 19 Memorial Dr. W. Bethlehem, PA. 18015 USA ¢ jwk2 ¡ tboult @eecs.lehigh.edu Abstract We introduce a novel optimization engine for META4, a new object oriented language currently under development. It uses Static Single Assignment (henceforth SSA) form coupled with certain reasonable, albeit very uncommon language features not usually found in existing systems. This reduces the code footprint and increased the optimizer’s “reuse” factor. This engine performs the following optimizations; Dead Code Elimination (DCE), Common Subexpression Elimination (CSE) and Constant Propagation (CP) at both runtime and compile time with linear complexity time requirement. CP is essentially free, whether the values are really source-code constants or specific values generated at runtime. CP runs along side with the other optimization passes, thus allowing the efficient runtime specialization of the code during any point of the program’s lifetime. 1. Introduction A recurring theme in this work is that powerful expensive analysis and optimization facilities are not necessary for generating good code. Rather, by using information ignored by previous work, we have built a facility that produces good code with simple linear time algorithms. This report will focus on the optimization parts of the system. More detailed reports on META4?; ? as well as the compiler are under development. Section 0.2 will introduce the scope of the optimization algorithms presented in this work. Section 1. will dicuss some of the important definitions and concepts related to the META4 programming language and the optimizer used by the algorithms presented herein. -

CS153: Compilers Lecture 19: Optimization
CS153: Compilers Lecture 19: Optimization Stephen Chong https://www.seas.harvard.edu/courses/cs153 Contains content from lecture notes by Steve Zdancewic and Greg Morrisett Announcements •HW5: Oat v.2 out •Due in 2 weeks •HW6 will be released next week •Implementing optimizations! (and more) Stephen Chong, Harvard University 2 Today •Optimizations •Safety •Constant folding •Algebraic simplification • Strength reduction •Constant propagation •Copy propagation •Dead code elimination •Inlining and specialization • Recursive function inlining •Tail call elimination •Common subexpression elimination Stephen Chong, Harvard University 3 Optimizations •The code generated by our OAT compiler so far is pretty inefficient. •Lots of redundant moves. •Lots of unnecessary arithmetic instructions. •Consider this OAT program: int foo(int w) { var x = 3 + 5; var y = x * w; var z = y - 0; return z * 4; } Stephen Chong, Harvard University 4 Unoptimized vs. Optimized Output .globl _foo _foo: •Hand optimized code: pushl %ebp movl %esp, %ebp _foo: subl $64, %esp shlq $5, %rdi __fresh2: movq %rdi, %rax leal -64(%ebp), %eax ret movl %eax, -48(%ebp) movl 8(%ebp), %eax •Function foo may be movl %eax, %ecx movl -48(%ebp), %eax inlined by the compiler, movl %ecx, (%eax) movl $3, %eax so it can be implemented movl %eax, -44(%ebp) movl $5, %eax by just one instruction! movl %eax, %ecx addl %ecx, -44(%ebp) leal -60(%ebp), %eax movl %eax, -40(%ebp) movl -44(%ebp), %eax Stephen Chong,movl Harvard %eax,University %ecx 5 Why do we need optimizations? •To help programmers… •They write modular, clean, high-level programs •Compiler generates efficient, high-performance assembly •Programmers don’t write optimal code •High-level languages make avoiding redundant computation inconvenient or impossible •e.g. -

Precise Null Pointer Analysis Through Global Value Numbering
Precise Null Pointer Analysis Through Global Value Numbering Ankush Das1 and Akash Lal2 1 Carnegie Mellon University, Pittsburgh, PA, USA 2 Microsoft Research, Bangalore, India Abstract. Precise analysis of pointer information plays an important role in many static analysis tools. The precision, however, must be bal- anced against the scalability of the analysis. This paper focusses on improving the precision of standard context and flow insensitive alias analysis algorithms at a low scalability cost. In particular, we present a semantics-preserving program transformation that drastically improves the precision of existing analyses when deciding if a pointer can alias Null. Our program transformation is based on Global Value Number- ing, a scheme inspired from compiler optimization literature. It allows even a flow-insensitive analysis to make use of branch conditions such as checking if a pointer is Null and gain precision. We perform experiments on real-world code and show that the transformation improves precision (in terms of the number of dereferences proved safe) from 86.56% to 98.05%, while incurring a small overhead in the running time. Keywords: Alias Analysis, Global Value Numbering, Static Single As- signment, Null Pointer Analysis 1 Introduction Detecting and eliminating null-pointer exceptions is an important step towards developing reliable systems. Static analysis tools that look for null-pointer ex- ceptions typically employ techniques based on alias analysis to detect possible aliasing between pointers. Two pointer-valued variables are said to alias if they hold the same memory location during runtime. Statically, aliasing can be de- cided in two ways: (a) may-alias [1], where two pointers are said to may-alias if they can point to the same memory location under some possible execution, and (b) must-alias [27], where two pointers are said to must-alias if they always point to the same memory location under all possible executions. -

Value Numbering
SOFTWARE—PRACTICE AND EXPERIENCE, VOL. 0(0), 1–18 (MONTH 1900) Value Numbering PRESTON BRIGGS Tera Computer Company, 2815 Eastlake Avenue East, Seattle, WA 98102 AND KEITH D. COOPER L. TAYLOR SIMPSON Rice University, 6100 Main Street, Mail Stop 41, Houston, TX 77005 SUMMARY Value numbering is a compiler-based program analysis method that allows redundant computations to be removed. This paper compares hash-based approaches derived from the classic local algorithm1 with partitioning approaches based on the work of Alpern, Wegman, and Zadeck2. Historically, the hash-based algorithm has been applied to single basic blocks or extended basic blocks. We have improved the technique to operate over the routine’s dominator tree. The partitioning approach partitions the values in the routine into congruence classes and removes computations when one congruent value dominates another. We have extended this technique to remove computations that define a value in the set of available expressions (AVA IL )3. Also, we are able to apply a version of Morel and Renvoise’s partial redundancy elimination4 to remove even more redundancies. The paper presents a series of hash-based algorithms and a series of refinements to the partitioning technique. Within each series, it can be proved that each method discovers at least as many redundancies as its predecessors. Unfortunately, no such relationship exists between the hash-based and global techniques. On some programs, the hash-based techniques eliminate more redundancies than the partitioning techniques, while on others, partitioning wins. We experimentally compare the improvements made by these techniques when applied to real programs. These results will be useful for commercial compiler writers who wish to assess the potential impact of each technique before implementation. -

CLOS, Eiffel, and Sather: a Comparison
CLOS, Eiffel, and Sather: A Comparison Heinz W. Schmidt-, Stephen M. Omohundrot " September, 1991 li ____________T_R_._91_-0_47____________~ INTERNATIONAL COMPUTER SCIENCE INSTITUTE 1947 Center Street, Suite 600 Berkeley, California 94704-1105 CLOS, Eiffel, and Sather: A Comparison Heinz W. Schmidt-, Stephen M. Omohundrot September, 1991 Abstract The Common Lisp Object System defines a powerful and flexible type system that builds on more than fifteen years of experience with object-oriented programming. Most current implementations include a comfortable suite of Lisp support tools in cluding an Emacs Lisp editor, an interpreter, an incremental compiler, a debugger, and an inspector that together promote rapid prototyping and design. What else might one want from a system? We argue that static typing yields earlier error detec tion, greater robustness, and higher efficiency and that greater simplicity and more orthogonality in the language constructs leads to a shorter learning curve and more in tuitive programming. These elements can be found in Eiffel and a new object-oriented language, Sather, that we are developing at leS!. Language simplicity and static typ ing are not for free,·though. Programmers have to pay with loss of polymorphism and flexibility in prototyping. We give a short comparison of CLOS, Eiffel and Sather, addressing both language and environment issues. The different approaches taken by the languages described in this paper have evolved to fulfill different needs. While we have only touched on the essential differ ences, we hope that this discussion will be helpful in understanding the advantages and disadvantages of each language. -ICSI, on leave from: Inst. f. Systemtechnik, GMD, Germany tICSI 1 Introduction Common Lisp [25] was developed to consolidate the best ideas from a long line of Lisp systems and has become an important standard. -

Global Value Numbering Using Random Interpretation
Global Value Numbering using Random Interpretation Sumit Gulwani George C. Necula [email protected] [email protected] Department of Electrical Engineering and Computer Science University of California, Berkeley Berkeley, CA 94720-1776 Abstract General Terms We present a polynomial time randomized algorithm for global Algorithms, Theory, Verification value numbering. Our algorithm is complete when conditionals are treated as non-deterministic and all operators are treated as uninter- Keywords preted functions. We are not aware of any complete polynomial- time deterministic algorithm for the same problem. The algorithm Global Value Numbering, Herbrand Equivalences, Random Inter- does not require symbolic manipulations and hence is simpler to pretation, Randomized Algorithm, Uninterpreted Functions implement than the deterministic symbolic algorithms. The price for these benefits is that there is a probability that the algorithm can report a false equality. We prove that this probability can be made 1 Introduction arbitrarily small by controlling various parameters of the algorithm. Detecting equivalence of expressions in a program is a prerequi- Our algorithm is based on the idea of random interpretation, which site for many important optimizations like constant and copy prop- relies on executing a program on a number of random inputs and agation [18], common sub-expression elimination, invariant code discovering relationships from the computed values. The computa- motion [3, 13], induction variable elimination, branch elimination, tions are done by giving random linear interpretations to the opera- branch fusion, and loop jamming [10]. It is also important for dis- tors in the program. Both branches of a conditional are executed. At covering equivalent computations in different programs, for exam- join points, the program states are combined using a random affine ple, plagiarism detection and translation validation [12, 11], where combination. -
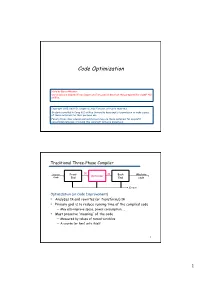
Code Optimization
Code Optimization Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon’s slides that they prepared for COMP 412 at Rice. Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students enrolled in Comp 412 at Rice University have explicit permission to make copies of these materials for their personal use. Faculty from other educational institutions may use these materials for nonprofit educational purposes, provided this copyright notice is preserved. Traditional Three-Phase Compiler Source Front IR IR Back Machine Optimizer Code End End code Errors Optimization (or Code Improvement) • Analyzes IR and rewrites (or transforms) IR • Primary goal is to reduce running time of the compiled code — May also improve space, power consumption, … • Must preserve “meaning” of the code — Measured by values of named variables — A course (or two) unto itself 1 1 The Optimizer IR Opt IR Opt IR Opt IR... Opt IR 1 2 3 n Errors Modern optimizers are structured as a series of passes Typical Transformations • Discover & propagate some constant value • Move a computation to a less frequently executed place • Specialize some computation based on context • Discover a redundant computation & remove it • Remove useless or unreachable code • Encode an idiom in some particularly efficient form 2 The Role of the Optimizer • The compiler can implement a procedure in many ways • The optimizer tries to find an implementation that is “better” — Speed, code size, data space, … To accomplish this, it • Analyzes the code to derive knowledge -

Iterable Abstract Pattern Matching for Java
JMatch: Iterable Abstract Pattern Matching for Java Jed Liu and Andrew C. Myers Computer Science Department Cornell University, Ithaca, New York Abstract. The JMatch language extends Java with iterable abstract pattern match- ing, pattern matching that is compatible with the data abstraction features of Java and makes iteration abstractions convenient. JMatch has ML-style deep pattern matching, but patterns can be abstract; they are not tied to algebraic data con- structors. A single JMatch method may be used in several modes; modes may share a single implementation as a boolean formula. Modal abstraction simplifies specification and implementation of abstract data types. This paper describes the JMatch language and its implementation. 1 Introduction Object-oriented languages have become a dominant programming paradigm, yet they still lack features considered useful in other languages. Functional languages offer expressive pattern matching. Logic programming languages provide powerful mech- anisms for iteration and backtracking. However, these useful features interact poorly with the data abstraction mechanisms central to object-oriented languages. Thus, ex- pressing some computations is awkward in object-oriented languages. In this paper we present the design and implementation of JMatch, a new object- oriented language that extends Java [GJS96] with support for iterable abstract pattern matching—a mechanism for pattern matching that is compatible with the data abstrac- tion features of Java and that makes iteration abstractions more convenient. -

Concepts in Programming Languages
Concepts in Programming Languages Alan Mycrofta Computer Laboratory University of Cambridge 2014–2015 (Easter Term) http://www.cl.cam.ac.uk/teaching/1415/ConceptsPL/ aNotes largely due to Marcelo Fiore—but errors are my responsibility. 1 Practicalities Course web page: www.cl.cam.ac.uk/teaching/1415/ConceptsPL/ with lecture slides, exercise sheet, and reading material. One exam question. 2 Main books J. C. Mitchell. Concepts in programming languages. Cambridge University Press, 2003. T.W. Pratt and M. V.Zelkowitz. Programming Languages: Design and implementation (3RD EDITION). Prentice Hall, 1999. ⋆ M. L. Scott. Programming language pragmatics (2ND EDITION). Elsevier, 2006. R. Harper. Practical Foundations for Programming Languages. Cambridge University Press, 2013. 3 Context : so many programming languages Peter J. Landin: “The Next 700 Programming Languages”, CACM >>>>1966<<<<. Some programming-language ‘family trees’ (too big for slide): http://www.oreilly.com/go/languageposter http://www.levenez.com/lang/ http://rigaux.org/language-study/diagram.html http://www.rackspace.com/blog/ infographic-evolution-of-computer-languages/ Plan of this course: pick out interesting programming- language concepts and major evolutionary trends. 4 Topics I. Introduction and motivation. II. The first procedural language: FORTRAN (1954–58). III. The first declarative language: LISP (1958–62). IV. Block-structured procedural languages: Algol (1958–68), Pascal (1970). V. Object-oriented languages — Concepts and origins: Simula (1964–67), Smalltalk (1971–80). VI. Languages for concurrency and parallelism. VII. Types in programming languages: ML (1973–1978). VIII. Data abstraction and modularity: SML Modules (1984–97). IX. A modern language design: Scala (2007) X. Miscellaneous concepts 5 Topic I Introduction and motivation References: g g Chapter 1 of Concepts in programming languages by J. -

Object-Oriented and Concurrent Program Design Issues in Ada 95
Object-Oriented and Concurrent Program Design Issues in Ada 95 Stephen H. Kaisler Michael B. Feldman Director, Systems Architecture Professor of Engineering and Applied Science Office of the Sergeant at Arms Dept. of Electrical Engineering and Computer Science United States Senate George Washington University Washington, DC 20510 Washington, DC 20052 202-224-2582 202-994-6083 [email protected] [email protected] 1. ABSTRACT Kaisler [4] identified several design issues that arose 2. INTRODUCTION from developing a process for transforming object- oriented programs written in Ada 95 or other object- Kaisler [4] described research leading to a methodology oriented programming languages to process-oriented for converting object-oriented programs to process- programs written in Ada 95. These issues limit - in the oriented programs and, thereby, making the concurrency authors' opinion - the flexibility of Ada 95 in writing implicit in object-oriented programs explicit. This concurrent programs. These problems arise from research was motivated by the fact that writing specific decisions made by the Ada 95 designers. This concurrent programs is difficult to do - no general paper addresses three of these issues: circular methodology exists - and by our recognition of the references are invalid in packages, lack of a similarity between object-oriented and process-oriented subclassing mechanism for protected types, and an programs. inability to internally invoke access statements from within a task body. Our goal is to raise the Ada 95 We believed that object-oriented programs, which exhibit community's awareness concerning these design issues a potential for concurrency, could be converted to and provide some suggestions for correcting these process-oriented programs, thereby making the problems for a future revision of the Ada concurrency explicit. -

The Australian National University Object Test Coverage Using Finite
The Australian National University TR-CS-95-06 Object Test Coverage Using Finite State Machines Oscar Bosman and Heinz W. Schmidt September 1995 Joint Computer Science Technical Report Series Department of Computer Science Faculty of Engineering and Information Technology Computer Sciences Laboratory Research School of Information Sciences and Engineering This technical report series is published jointly by the Department of Computer Science, Faculty of Engineering and Information Technology, and the Computer Sciences Laboratory, Research School of Information Sciences and Engineering, The Australian National University. Please direct correspondence regarding this series to: Technical Reports Department of Computer Science Faculty of Engineering and Information Technology The Australian National University Canberra ACT 0200 Australia or send email to: [email protected] A list of technical reports, including some abstracts and copies of some full reports may be found at: http://cs.anu.edu.au/techreports/ Recent reports in this series: TR-CS-95-05 Jeffrey X. Yu, Kian-Lee Tan, and Xun Qu. On balancing workload in a highly mobile environment. August 1995. TR-CS-95-04 Department of Computer Science. Annual report 1994. August 1995. TR-CS-95-03 Douglas R. Sweet and Richard P. Brent. Error analysis of a partial pivoting method for structured matrices. June 1995. TR-CS-95-02 Jeffrey X. Yu and Kian-Lee Tan. Scheduling issues in partitioned temporal join. May 1995. TR-CS-95-01 Craig Eldershaw and Richard P. Brent. Factorization of large integers on some vector and parallel computers. January 1995. TR-CS-94-10 John N. Zigman and Peiyi Tang.