Carving and Replaying Differential Unit Test Cases from System Test Cases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Types of Software Testing
Types of Software Testing We would be glad to have feedback from you. Drop us a line, whether it is a comment, a question, a work proposition or just a hello. You can use either the form below or the contact details on the rightt. Contact details [email protected] +91 811 386 5000 1 Software testing is the way of assessing a software product to distinguish contrasts between given information and expected result. Additionally, to evaluate the characteristic of a product. The testing process evaluates the quality of the software. You know what testing does. No need to explain further. But, are you aware of types of testing. It’s indeed a sea. But before we get to the types, let’s have a look at the standards that needs to be maintained. Standards of Testing The entire test should meet the user prerequisites. Exhaustive testing isn’t conceivable. As we require the ideal quantity of testing in view of the risk evaluation of the application. The entire test to be directed ought to be arranged before executing it. It follows 80/20 rule which expresses that 80% of defects originates from 20% of program parts. Start testing with little parts and extend it to broad components. Software testers know about the different sorts of Software Testing. In this article, we have incorporated majorly all types of software testing which testers, developers, and QA reams more often use in their everyday testing life. Let’s understand them!!! Black box Testing The black box testing is a category of strategy that disregards the interior component of the framework and spotlights on the output created against any input and performance of the system. -

Smoke Testing What Is Smoke Testing?
Smoke Testing What is Smoke Testing? Smoke testing is the initial testing process exercised to check whether the software under test is ready/stable for further testing. The term ‘Smoke Testing’ is came from the hardware testing, in the hardware testing initial pass is done to check if it did not catch the fire or smoked in the initial switch on.Prior to start Smoke testing few test cases need to created once to use for smoke testing. These test cases are executed prior to start actual testing to checkcritical functionalities of the program is working fine. This set of test cases written such a way that all functionality is verified but not in deep. The objective is not to perform exhaustive testing, the tester need check the navigation’s & adding simple things, tester needs to ask simple questions “Can tester able to access software application?”, “Does user navigates from one window to other?”, “Check that the GUI is responsive” etc. Here are graphical representation of Smoke testing & Sanity testing in software testing: Smoke Sanity Testing Diagram The test cases can be executed manually or automated; this depends upon the project requirements. In this types of testing mainly focus on the important functionality of application, tester do not care about detailed testing of each software component, this can be cover in the further testing of application. The Smoke testing is typically executed by testers after every build is received for checking the build is in testable condition. This type of testing is applicable in the Integration Testing, System Testing and Acceptance Testing levels. -
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform
Parasoft Static Application Security Testing (SAST) for .Net - C/C++ - Java Platform Parasoft® dotTEST™ /Jtest (for Java) / C/C++test is an integrated Development Testing solution for automating a broad range of testing best practices proven to improve development team productivity and software quality. dotTEST / Java Test / C/C++ Test also seamlessly integrates with Parasoft SOAtest as an option, which enables end-to-end functional and load testing for complex distributed applications and transactions. Capabilities Overview STATIC ANALYSIS ● Broad support for languages and standards: Security | C/C++ | Java | .NET | FDA | Safety-critical ● Static analysis tool industry leader since 1994 ● Simple out-of-the-box integration into your SDLC ● Prevent and expose defects via multiple analysis techniques ● Find and fix issues rapidly, with minimal disruption ● Integrated with Parasoft's suite of development testing capabilities, including unit testing, code coverage analysis, and code review CODE COVERAGE ANALYSIS ● Track coverage during unit test execution and the data merge with coverage captured during functional and manual testing in Parasoft Development Testing Platform to measure true test coverage. ● Integrate with coverage data with static analysis violations, unit testing results, and other testing practices in Parasoft Development Testing Platform for a complete view of the risk associated with your application ● Achieve test traceability to understand the impact of change, focus testing activities based on risk, and meet compliance -

Software Testing: Essential Phase of SDLC and a Comparative Study Of
International Journal of System and Software Engineering Volume 5 Issue 2, December 2017 ISSN.: 2321-6107 Software Testing: Essential Phase of SDLC and a Comparative Study of Software Testing Techniques Sushma Malik Assistant Professor, Institute of Innovation in Technology and Management, Janak Puri, New Delhi, India. Email: [email protected] Abstract: Software Development Life-Cycle (SDLC) follows In the software development process, the problem (Software) the different activities that are used in the development of a can be dividing in the following activities [3]: software product. SDLC is also called the software process ∑ Understanding the problem and it is the lifeline of any Software Development Model. ∑ Decide a plan for the solution Software Processes decide the survival of a particular software development model in the market as well as in ∑ Coding for the designed solution software organization and Software testing is a process of ∑ Testing the definite program finding software bugs while executing a program so that we get the zero defect software. The main objective of software These activities may be very complex for large systems. So, testing is to evaluating the competence and usability of a each of the activity has to be broken into smaller sub-activities software. Software testing is an important part of the SDLC or steps. These steps are then handled effectively to produce a because through software testing getting the quality of the software project or system. The basic steps involved in software software. Lots of advancements have been done through project development are: various verification techniques, but still we need software to 1) Requirement Analysis and Specification: The goal of be fully tested before handed to the customer. -

Security Testing TDDC90 – Software Security
Security Testing TDDC90 – Software Security Ulf Kargén Department of Computer and Information Science (IDA) Division for Database and Information Techniques (ADIT) Security testing vs “regular” testing ▪ “Regular” testing aims to ensure that the program meets customer requirements in terms of features and functionality. ▪ Tests “normal” use cases Test with regards to common expected usage patterns. ▪ Security testing aims to ensure that program fulfills security requirements. ▪ Often non-functional. ▪ More interested in misuse cases Attackers taking advantage of “weird” corner cases. 2 Functional vs non-functional security requirements ▪ Functional requirements – What shall the software do? ▪ Non-functional requirements – How should it be done? ▪ Regular functional requirement example (Webmail system): It should be possible to use HTML formatting in e-mails ▪ Functional security requirement example: The system should check upon user registration that passwords are at least 8 characters long ▪ Non-functional security requirement example: All user input must be sanitized before being used in database queries How would you write a unit test for this? 3 Common security testing approaches Often difficult to craft e.g. unit tests from non-functional requirements Two common approaches: ▪ Test for known vulnerability types ▪ Attempt directed or random search of program state space to uncover the “weird corner cases” In today’s lecture: ▪ Penetration testing (briefly) ▪ Fuzz testing or “fuzzing” ▪ Concolic testing 4 Penetration testing ▪ Manually try to “break” software ▪ Relies on human intuition and experience. ▪ Typically involves looking for known common problems. ▪ Can uncover problems that are impossible or difficult to find using automated methods ▪ …but results completely dependent on skill of tester! 5 Fuzz testing Idea: Send semi-valid input to a program and observe its behavior. -

Model-Based Security Testing
Model-Based Security Testing Ina Schieferdecker Juergen Grossmann Fraunhofer FOKUS Fraunhofer FOKUS Berlin, Germany Berlin, Germany Freie Universitaet Berlin [email protected] Berlin, Germany [email protected] Martin Schneider Fraunhofer FOKUS Berlin, Germany [email protected] Security testing aims at validating software system requirements related to security properties like confidentiality, integrity, authentication, authorization, availability, and non-repudiation. Although security testing techniques are available for many years, there has been little approaches that allow for specification of test cases at a higher level of abstraction, for enabling guidance on test identification and specification as well as for automated test generation. Model-based security testing (MBST) is a relatively new field and especially dedicated to the sys- tematic and efficient specification and documentation of security test objectives, security test cases and test suites, as well as to their automated or semi-automated generation. In particular, the com- bination of security modelling and test generation approaches is still a challenge in research and of high interest for industrial applications. MBST includes e.g. security functional testing, model-based fuzzing, risk- and threat-oriented testing, and the usage of security test patterns. This paper provides a survey on MBST techniques and the related models as well as samples of new methods and tools that are under development in the European ITEA2-project DIAMONDS. 1 Introduction The times of rather static communication in strictly controlled, closed networks for limited purposes are over, while the adoption of the Internet and other communication technologies in almost all domes- tic, economic and social sectors with new approaches for rather dynamic and open networked environ- ments overwhelmingly progresses. -

Guidelines on Minimum Standards for Developer Verification of Software
Guidelines on Minimum Standards for Developer Verification of Software Paul E. Black Barbara Guttman Vadim Okun Software and Systems Division Information Technology Laboratory July 2021 Abstract Executive Order (EO) 14028, Improving the Nation’s Cybersecurity, 12 May 2021, di- rects the National Institute of Standards and Technology (NIST) to recommend minimum standards for software testing within 60 days. This document describes eleven recommen- dations for software verification techniques as well as providing supplemental information about the techniques and references for further information. It recommends the following techniques: • Threat modeling to look for design-level security issues • Automated testing for consistency and to minimize human effort • Static code scanning to look for top bugs • Heuristic tools to look for possible hardcoded secrets • Use of built-in checks and protections • “Black box” test cases • Code-based structural test cases • Historical test cases • Fuzzing • Web app scanners, if applicable • Address included code (libraries, packages, services) The document does not address the totality of software verification, but instead recom- mends techniques that are broadly applicable and form the minimum standards. The document was developed by NIST in consultation with the National Security Agency. Additionally, we received input from numerous outside organizations through papers sub- mitted to a NIST workshop on the Executive Order held in early June, 2021 and discussion at the workshop as well as follow up with several of the submitters. Keywords software assurance; verification; testing; static analysis; fuzzing; code review; software security. Disclaimer Any mention of commercial products or reference to commercial organizations is for infor- mation only; it does not imply recommendation or endorsement by NIST, nor is it intended to imply that the products mentioned are necessarily the best available for the purpose. -
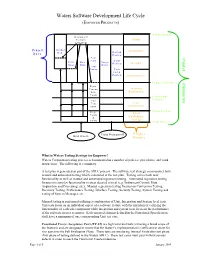
Waters Software Development Life Cycle (EMPOWER PRODUCTS)
Waters Software Development Life Cycle (EMPOWER PRODUCTS) Project Start Document Feature Study Complete Project Market Definition Req. Design Docs. Review Test P Plan Code r Func. Dev. Design Design o Review j Spec. Plan Docs. e Test c Cases Task t Comp. Review Implementation Feature Freeze M Func. i l Freeze Internal e s Acc. Evaluation t Tests o Functional n Freeze e Full s Test Full suite Evaluation Code Freeze Regr. Final Tests Evaluation & (Verify) Verify Final Freeze Field Personnel Project End Users Phases What is Waters Testing Strategy for Empower? Waters Corporation testing process is documented in a number of policies, procedures, and work instructions. The following is a summary. A test plan is generated as part of the SDLC process. The software test strategy encompasses both manual and automated testing which is detailed in the test plan. Testing covers both new functionality as well as manual and automated regression testing. Automated regression testing focuses on complex functionality in areas deemed critical (e.g. Instrument Control, Data Acquisition and Processing, etc.). Manual regression testing focuses on Conversion Testing, Recovery Testing, Performance Testing, Interface Testing, Security Testing, System Testing and testing of System Messages, etc. Manual testing is performed utilizing a combination of Unit, Integration and System level tests. Unit tests focus on an individual aspect of a software feature with the intention of verifying the functionality of each sub-component while integration and system tests focus on the performance of the software in user scenarios. Each required element defined in the Functional Specification shall have a minimum of one corresponding Unit test case. -

Beginners Guide to Software Testing
Beginners Guide To Software Testing Beginners Guide To Software Testing - Padmini C Page 1 Beginners Guide To Software Testing Table of Contents: 1. Overview ........................................................................................................ 5 The Big Picture ............................................................................................... 5 What is software? Why should it be tested? ................................................. 6 What is Quality? How important is it? ........................................................... 6 What exactly does a software tester do? ...................................................... 7 What makes a good tester? ........................................................................... 8 Guidelines for new testers ............................................................................. 9 2. Introduction .................................................................................................. 11 Software Life Cycle ....................................................................................... 11 Various Life Cycle Models ............................................................................ 12 Software Testing Life Cycle .......................................................................... 13 What is a bug? Why do bugs occur? ............................................................ 15 Bug Life Cycle ............................................................................................... 16 Cost of fixing bugs ....................................................................................... -

Analyzing Frameworks for HPC Systems Regression Testing Sadie Nederveld & Berkelly Gonzalez
Analyzing Frameworks for HPC Systems Regression Testing Sadie Nederveld & Berkelly Gonzalez Mentors: Alden Stradling, Kathleen Kelly, Travis Cotton LA-UR-20-26069 1 1 Background 2 What is Systems Regression Testing? Our working definition: Tests that the system was set up correctly: eg. files have correct permissions, nodes can communicate, required mounts are present, updates have been implemented. Checks to make sure that changes, including flaw fixes, that have been made do not get reverted and that new changes don’t break other things that were previously working. Checks things required for the specific system consistently over time via automation, not just in conjunction with maintenance windows. Goal: identifying problems with the system before they become problems for the customers. 3 Early Research ● Began with a broad overview what regression testing is and looked for existing frameworks for HPC systems regression testing ○ “HPC Systems Acceptance Testing: Controlled Chaos” ○ “Getting Maximum Performance Out of HPC Systems” ○ ReFrame Readthedocs ● ReFrame? ← not actually systems regression! ● No frameworks for HPC systems regression testing ● Now what? 4 Our Project ● Goal: Identify frameworks that could be used for systems regression testing, and evaluate them to see which one(s) would work. If none, then determine that a systems regression framework would need to be built. ● Identified Pavilion, NHC, and Interstate as potential candidates ● Implemented Pavilion, Interstate, and NHC, and analyzed them based on a list of 22 characteristics. -

ISTQB Question Paper 1
ISTQB Foundation level exam Sample paper - I For more testing free downloads Visit http://softwaretestinghelp.com Question 1 We split testing into distinct stages primarily because: a) Each test stage has a different purpose. b) It is easier to manage testing in stages. c) We can run different tests in different environments. d) The more stages we have, the better the testing. 2 Which of the following is likely to benefit most from the use of test tools providing test capture and replay facilities? a) Regression testing b) Integration testing c) System testing d) User acceptance testing 3 Which of the following statements is NOT correct? a) A minimal test set that achieves 100% LCSAJ coverage will also achieve 100% branch coverage. b) A minimal test set that achieves 100% path coverage will also achieve 100% statement coverage. c) A minimal test set that achieves 100% path coverage will generally detect more faults than one that achieves 100% statement coverage. d) A minimal test set that achieves 100% statement coverage will generally detect more faults than one that achieves 100% branch coverage. 4 Which of the following requirements is testable? a) The system shall be user friendly. b) The safety-critical parts of the system shall contain 0 faults. c) The response time shall be less than one second for the specified design load. d) The system shall be built to be portable. 5 Analyze the following highly simplified procedure: Ask: "What type of ticket do you require, single or return?" IF the customer wants ‘return’ Ask: "What rate, Standard or Cheap-day?" IF the customer replies ‘Cheap-day’ Say: "That will be £11:20" ELSE Say: "That will be £19:50" ENDIF ELSE Say: "That will be £9:75" ENDIF Now decide the minimum number of tests that are needed to ensure that all the questions have been asked, all combinations have occurred and all replies given. -

The Nature of Exploratory Testing
The Nature of Exploratory Testing by Cem Kaner, J.D., Ph.D. Professor of Software Engineering Florida Institute of Technology and James Bach Principal, Satisfice Inc. These notes are partially based on research that was supported by NSF Grant EIA-0113539 ITR/SY+PE: "Improving the Education of Software Testers." Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. Kaner & Bach grant permission to make digital or hard copies of this work for personal or classroom use, including use in commercial courses, provided that (a) Copies are not made or distributed outside of classroom use for profit or commercial advantage, (b) Copies bear this notice and full citation on the front page, and if you distribute the work in portions, the notice and citation must appear on the first page of each portion. Abstracting with credit is permitted. The proper citation for this work is ”Exploratory & Risk-Based Testing (2004) www.testingeducation.org", (c) Each page that you use from this work must bear the notice "Copyright (c) Cem Kaner and James Bach", or if you modify the page, "Modified slide, originally from Cem Kaner and James Bach", and (d) If a substantial portion of a course that you teach is derived from these notes, advertisements of that course should include the statement, "Partially based on materials provided by Cem Kaner and James Bach." To copy otherwise, to republish or post on servers, or to distribute to lists requires prior specific permission and a fee.