Journal Pre-Proof
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

BCVA Cover LZ.1.1
TWO DAY AUCTION, OUR LAST SALES AT BAYNTON ROAD WEDNESDAY 29th and THURSDAY 30th AUGUST BOTH COMMENCING AT 10.00AM LOTS TO INCLUDE: DAY ONE LOTS 1- 407 • SEIZED GOODS, TECHNOLOGY DAY TWO LOTS 408 - 981 • UNCLAIMED PROPERTY • FRAGRANCES AND TOILETRIES • ALCOHOL AND TOBACCO • CLOTHING AND SHOES • JEWELLERY, WATCHES AND GIFTS • HAND TOOLS AND SHIPPING CONTAINER • SPORTS AND LEISURE ITEMS • MEDICAL ACCESSORIES • MISCELLANEOUS ITEMS ON VIEW TUESDAY 28th AUGUST 10.30AM TO 6PM WEDNESDAY 29th AUGUST 9AM TO 6PM AND FROM 9am ON MORNINGA OF SALES Estimates are subject to 24% Buyers Premium (inclusive of VAT), plus VAT (20%) on the hammer price where indicated with an * asterick CATALOGUE £2 YOU CAN BID LIVE ONLINE FOR THIS AUCTION AT I-BIDDER.COM BCVA Asset Valuers & Auctioneers @BCVA_AUCTION Bristol Commercial Valuers & Auctioneers - The Old Brewery, Baynton Road, Ashton, Bristol BS3 2EB United Kingdom tel +44 (0) 117 953 3676 fax +44 (0) 117 953 2135 email [email protected] www.thebcva.co.uk IMPORTANT NOTICES We suggest you read the following guide to buying at BCVA in conjunction with our full Terms & Conditions at the back of the catalogue. HOW TO BID To register as a buyer with us, you must register online or in person and provide photo and address identification by way of a driving licence photo card or a passport/identity card and a utility bill/bank statement. This is a security measure which applies to new registrants only. We operate a paddle bidding system. Lots are offered for sale in numerical order and we usually offer approximately 80-120 lots per hour. -

Samsung Galaxy J3 Prime J327T1 User Manual
SMARTPHONE User Manual Please read this manual before operating your device and keep it for future reference. Table of Contents Special Features . 1 Navigation . 28 Side Speaker . 2 Entering Text . 30 Getting Started . 3 Multi Window . 33 Set Up Your Device . 4. Emergency Mode . 35 Assemble Your Device . .5 Apps . 37 Start Using Your Device . 10 Using Apps . 38 Set Up Your Device . 11 Applications Settings . 41 Learn About Your Device . .15 Calculator . 43 Front View . 16 Calendar . 44 Back View . .18 Camera and Video . 47 Home Screen . .19 Clock . 52 MET_J327T1_EN_UM_TN_QCB_042417_FINAL Contacts . 55 Settings . 100 Email . 62 How to Use Settings . .101 Galaxy Apps . 65 Connections . 102 Gallery . 66 Wi‑Fi . 103 Google Apps . 70 Bluetooth . 106 Internet . 73 Data Usage . 109 Messages . .77 Airplane Mode . 111 MetroPCS Apps . 82 Mobile Hotspot . 111 My Files . 84 Tethering . 114 Phone . 86 Mobile Networks . 114 Samsung Gear . 96 Location . 115 Samsung Notes . 97 Nearby Device Scanning . 117 Samsung+ . 99 Printing . 117 Secure Folder . 99 Virtual Private Networks (VPN) . 117 Table of Contents iii Sounds and Vibration . 120 Display . 130 Sound Mode . .121 Screen Brightness . 131 Easy Mute . .121 Screen Zoom and Font . 131 Vibrations . .121 Home Screen . 132. Volume . 122. Easy Mode . 132 Ringtone . 123 Icon Frames . 133 Notification Sounds . 124 Status Bar . 133 Do Not Disturb . 124 Screen Timeout . 133 System Sounds . 125 Screen Saver . 134 Key ‑Tap Feedback . 125 Wallpapers and Themes . 135 Sound Quality and Effects . 126. Wallpapers . 136 Notifications . 127 Themes . 136 Block App Notifications . 128 Icons . 136 Customize App Notifications . 128 Device Maintenance . .137 Smart Alert . -
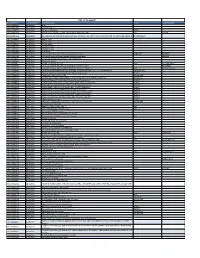
Ctrl + F to Search
Ctrl + F to search Case Number Case Reported Item Description Make Serial Number 2021-00025981 09/23/2021 BIDET 2021-00025981 09/23/2021 JUMPER CABLES 2021-00025723 09/21/2021 3rd Generation Ipad APPLE 2021-00025612 09/20/2021 Jimenez pistol, model J.A. NINE, 9mm calibre, black grip scales JMZ 424198 2021-00025454 09/18/2021 BLK AND BLUE DIAMONDBACK MEN'S BICYCLE W/ BASKET ON FRONT AND CARGO RACK ON THE BACK (UNK SERIAL #) DIAMONDBACK 2021-00025421 09/18/2021 STERLT - 40G 2021-00025421 09/18/2021 STERLT - 40G 2021-00025421 09/18/2021 STORAGE BOX 2021-00025421 09/18/2021 UNDERBED BOX 2021-00025421 09/18/2021 UNDERBED BOX 2021-00025400 09/18/2021 TOW HITCH 2021-00025348 09/17/2021 Gray and Black Evinrude 9.9 horse power boat motor. EVINRUDE R710873 2021-00025290 09/17/2021 Red Sun EZ Sport recumbent bicycle with long wheel base B030333 2021-00025001 09/14/2021 black Appel Iphone 7/8 belonging to Shawn Trontel 2021-00024911 09/13/2021 Dickies seat covers 2021-00024675 09/11/2021 IPHONE 11 WITH BLUE CASE APPLE F4GCG84GN72Y 2021-00024599 09/10/2021 LIV brand mountain bike, Bliss 2 model, teal and coral in color K87035092 2021-00024513 09/09/2021 2018 TREK ROSCOE BICYCLE WITH ORANGE PEDALS, 26 " WHEELS TREK WTU281C0286M 2021-00024462 09/09/2021 CANNONDALE F7 MENS MTN BIKE, SIZE MED, YINGYANG STICKER, COIL LOCK ON SEATPOST CANNONDALE 2021-00024333 09/08/2021 2 DeWalt batteries 5amp labeled with "Plevel Construction" DEWALT 2021-00024333 09/08/2021 3 Milwaukee Fuel batteries 18V MILWAUKEE 2021-00024333 09/08/2021 Cordless Milwaukee Sawzall labeled -

Samsung Galaxy J3 Prime
SMARTPHONE User Manual Please read this manual before operating your device and keep it for future reference. Table of Contents Special Features ................................................................1 Side Speaker ........................................................................................ 2 Getting Started ................................................................. 3 Set Up Your Device ............................................................................. 4 Assemble Your Device ....................................................................... 5 Start Using Your Device .................................................................. 13 Set Up Your Device ........................................................................... 15 Learn About Your Device ..................................................................19 Front View ..........................................................................................20 Back View ...........................................................................................22 Home Screen .....................................................................................23 Navigation .........................................................................................32 Entering Text .....................................................................................35 TFN_S337TL_EN_UM_TN_QC6_042117_FINAL Multi Window ....................................................................................39 Emergency Mode .............................................................................42 -

T-Mobile® Service Fee and Deductible Schedule
T-Mobile® Service Fee and Deductible Schedule The service fees/deductibles apply to the following programs: JUMP! Plus Premium Device Protection Plus Tier 1 Tier 3 Tier 5 Service Fee: $20 per claim for accidental damage Service Fee: $20 per claim for accidental damage Service Fee: $99 per claim for accidental damage Deductible: $20 per claim for loss and theft Deductible: $100 per claim for loss and theft Deductible: $175 per claim for loss and theft Unrecovered Equipment Fee: up to $200 Unrecovered Equipment Fee: up to $500 Unrecovered Equipment Fee: up to $900 ALCATEL A30 LG G Stylo Apple iPad Air 2 - 16 / 64 / 128GB ALCATEL Aspire LG G Pad X2 8.0 Plus Apple iPad mini 4 - 64 / 128GB ALCATEL GO FLIP Samsung Galaxy Tab A 8.0 Apple iPad Pro 9.7-inch - 32 / 128 / 256GB ALCATEL LinkZone Hotspot Samsung Gear S2 Apple iPad Pro 10.5-inch - 128GB ALCATEL ONETOUCH POP Astro Apple iPad Pro 12.9-inch - 256GB Coolpad Catalyst Apple iPhone 6s - 16 / 32 / 64 / 128GB Coolpad Rogue Apple iPhone 6s Plus - 16 / 32 / 64 / 128GB Kyocera Rally Apple iPhone 7 - 32 / 128 / 256GB LG Aristo Apple iPhone 7 Plus - 32 / 128 / 256GB LG K7 Apple iPhone 8 - 64 / 256GB LG K20 Apple iPhone 8 Plus - 64 / 256GB LG Leon LTE Apple Watch Series 3 Stainless Steel Case Microsoft Lumia 435 BlackBerry Priv Samsung Galaxy J3 Prime HTC One M9 T-Mobile LineLink HTC 10 T-Mobile REVVL LG G4 ZTE Avid Plus LG G5 ZTE Avid Trio LG G6 ZTE Cymbal LG V10 ZTE Falcon Z-917 Hotspot LG V30 ZTE Obsidian moto z2 force ZTE Zmax Pro Samsung Galaxy Note 5 - 32 / 64GB Samsung Galaxy Note 7 - 64GB -

Tarifas De Servicio/ Deducibles T-Mobile®
Tarifas de servicio/ deducibles T-Mobile® Las tarifas de servicio/deducibles a continuación se aplican a los siguientes programas: JUMP! Plus Protección Premium Plus para Dispositivos Nivel 1 Nivel 3 Nivel 5 Tarifa de servicio: $20 por reclamo Tarifa de servicio: $20 por reclamo Tarifa de servicio: $99 por reclamo para daño accidental para daño accidental para daño accidental Deducible: $20 por reclamo Deducible: $100 por reclamo Deducible: $175 por reclamo para pérdida y robo para pérdida y robo para pérdida y robo Cargo por equipo no recuperado: Cargo por equipo no recuperado: Cargo por equipo no recuperado: hasta $200 hasta $500 hasta $900 ALCATEL A30 HTC U11 life Apple iPad mini 4 - 64 / 128GB ALCATEL Aspire LG G Stylo Apple iPad Pro 9.7-inch - 32 / 128 / 256GB ALCATEL GO FLIP LG G Pad X2 8.0 Plus Apple iPad Pro 10.5-inch - 128GB ALCATEL LinkZone Hotspot Samsung Galaxy Tab A 8.0 Apple iPad Pro 12.9-inch - 256GB ALCATEL ONETOUCH POP Astro Samsung Gear S2 Apple iPhone 6s - 16 / 32 / 64 / 128GB Coolpad Catalyst Apple iPhone 6s Plus - 16 / 32 / 64 / 128GB Coolpad Rogue Apple iPhone 7 - 32 / 128 / 256GB Kyocera Rally Apple iPhone 7 Plus - 32 / 128 / 256GB LG Aristo Apple iPhone 8 - 64 / 256GB LG K7 Apple iPhone 8 Plus - 64 / 256GB LG K20 Apple Watch Series 3 Stainless Steel Case LG Leon LTE BlackBerry Priv Microsoft Lumia 435 HTC One M9 Samsung Galaxy J3 Prime HTC 10 T-Mobile LineLink LG G6 T-Mobile REVVL LG V10 ZTE Avid Plus LG V30 ZTE Avid Trio LG V30+ ZTE Cymbal moto z2 force ZTE Falcon Z-917 Hotspot Samsung Galaxy Note 5 - 32 / 64GB -

Oxygen Forensic® Detectivev.9.4
Release notes June 2017 Oxygen Forensic® Detective v.9.4 SAMSUNG CLOUD DATA SAFARI DATA FROM ICLOUD Oxygen Forensic® Detective 9.4 introduces the ability to extract Web browser artifacts often provide crucial evidence. evidence from Samsung Cloud. Samsung Cloud is currently Critical information can be found in the suspect’s or victim’s available on certain Galaxy devices. Samsung offers 15GB of searches, downloads, saved pages, bookmarks and cookies. free storage to customers to backup, sync and restore their In Oxygen Forensic® Detective 9.4 we’ve significantly data. By using the latest Oxygen Forensic® Detective forensic extended the capability of web browser forensics by adding experts gain immediate access to Samsung Cloud data: Safari bookmarks and history extraction directly from iCloud. account details, device list, contacts, calls, messages, notes, Forensic experts may use either username/password or web browser opened tabs, saved pages and bookmarks. The token to access the cloud. The iCloud token can be extracted password to the Samsung Cloud account can be found in the and decrypted from iOS device via standard iTunes backup mobile device and used to access the cloud storage in one click. procedure in Oxygen Forensic® Detective software. WHATSAPP BACKUP DECRYPTION USER PARTITION DECRYPTION The previous versions of Oxygen Forensic® Oxygen Forensic® Detective 9.4 offers the ability to Detective allowed to acquire and decode find the password and decrypt the user partition encrypted WhatsApp backups from Google Drive of popular Samsung Galaxy S5, Samsung Galaxy by using the key file found in the device. Version S6 and Samsung Galaxy Note 4 devices. -
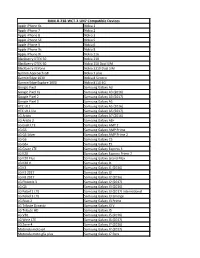
RAM-B-238-WCT-2-UN7 Compatible Devices
RAM-B-238-WCT-2-UN7 Compatible Devices Apple iPhone 6s Nokia 1 Apple iPhone 7 Nokia 2 Apple iPhone 8 Nokia 3 Apple iPhone SE Nokia 5 Apple iPhone X Nokia 6 Apple iPhone Xs Nokia 8 Apple iPhone Xr Nokia 216 Blackberry DTEK 50 Nokia 230 Blackberry DTEK 60 Nokia 150 Dual SIM Blackberry KEYone Nokia 3310 Dual SIM Garmin Approach G8 Nokia 7 plus Garmin Edge 1030 Nokia 8 Sirocco Garmin Edge Explore 1000 Nokia 8110 4G Google Pixel Samsung Galaxy A3 Google Pixel XL Samsung Galaxy A3 (2016) Google Pixel 2 Samsung Galaxy A3 (2017) Google Pixel 3 Samsung Galaxy A5 HTC U11 Samsung Galaxy A5 (2016) HTC U11 life Samsung Galaxy A5 (2017) LG Aristo Samsung Galaxy A7 (2016) LG Aristo 2 Samsung Galaxy A8+ LG Exalt LTE Samsung Galaxy AMP 2 LG G5 Samsung Galaxy AMP Prime LG G5 Silver Samsung Galaxy AMP Prime 2 LG G6 Samsung Galaxy C5 LG G6+ Samsung Galaxy E5 LG Grace LTE Samsung Galaxy Express 3 LG K20 Samsung Galaxy Express Prime 2 LG K20 Plus Samsung Galaxy Grand Max LG K20 V Samsung Galaxy J1 LG K3 Samsung Galaxy J1 (2016) LG K3 2017 Samsung Galaxy J2 LG K8 2017 Samsung Galaxy J2 (2016) LG Phoenix 3 Samsung Galaxy J2 (2017) LG Q6 Samsung Galaxy J3 (2016) LG Rebel 2 LTE Samsung Galaxy J3 (2017) International LG Rebel 3 LTE Samsung Galaxy J3 Emerge LG Risio 2 Samsung Galaxy J3 Prime LG Tribute Dynasty Samsung Galaxy J3 V LG Tribute HD Samsung Galaxy J5 LG V30 Samsung Galaxy J5 (2016) LG Wine LTE Samsung Galaxy J5 (2017) LG Zone 4 Samsung Galaxy J7 (2016) Motorola moto e4 Samsung Galaxy J7 (2017) Motorola moto g5s plus Samsung Galaxy J7 Perx Motorola moto -

RM WIRELESS SERVICES, INC. LISTA DE PRECIOS Www
RM WIRELESS SERVICES, INC. LISTA DE PRECIOS Lista de Precios RM_Febrero_2018 www.TuBBMiami.com 4805 NW 79th Ave, Suite 2 - Doral, FL 33166 PH. (305)-594-6670, (305)-721-5001, (0261)-7710097 (Maracaibo), (0212)-7201493 (Caracas), email:[email protected] FECHA: 1-Feb-17 ASUS ASUS CODIGO DETAL MIA MAYOR MIA DETAL VEN (TuBB) MAYOR VEN ASUS ZENFONE 3 LASER 32GB BLANCO (4G LTE, Octa Core, Full HD Display, cam 13.0MP) ASUSZF3L $249.00 $237.00 $269.97*** NUEVO $247.00 ASUS ZENFONE 3 MAX 16GB BLANCO (4G LTE, Octa Core, Full HD Display, cam 13.0MP) ASUSZF3M $197.00 $179.00 $199.97*** NUEVO $187.00 SONY SONY CODIGO DETAL MIA MAYOR MIA DETAL VEN (TuBB) MAYOR VEN (REV) SONY XPERIA E 4GB BLACK/WHITE/RED Android(3G, wifi, gps, Dual core, 3.2 MP) SONYXE $87.00 $79.00 $99.97 $87.00 SONY XPERIA Z3 16GB BLK/WH Android (4G, Quad Core 2.5 Ghz , Resistente al agua, 20.7 MP) SONYXPZ3 $335.00 $307.00 $369.97 $327.00 SONY XPERIA Z5 32GB BLK/WH Android (4G, Octa Core , Resistente al agua, 23 MP) SONYXPZ5 $379.00 $367.00 $399.97 $377.00 HUAWEI HUAWEI / ZTE / ALCATEL CODIGO DETAL MIA MAYOR MIA DETAL VEN (TuBB) MAYOR VEN ZTE MAVEN 3 8GB NEGRO Android (4G LTE, 1GB RAM ,Quad Core 1.2GHz, Cam 5.0MP) ZTEMAVEN3 $77.00 $72.00 $79.97*** $77.00 (REV-$5) ZTE BLADE SPARK 16GB NEGRO (4G LTE, 2GB RAM ,Quad Core 1.4GHz, Cam 13.0MP) ZTEBLADESP $109.00 $97.00 $129.97*** NUEVO $117.00 (REV-$5) ZTE GRAND X4 3 16GB NEGRO Android (4G LTE, Dolby Audio, 2GB RAM ,Quad Core 1.4GHz, Cam 13.0MP) ZTEGRANDX4 $117.00 $109.00 $139.97*** NUEVO $125.00 (REV-$5) ALCATEL IDEALXCITE 8GB NEGRO Android -
Minecraft, the Game - Its History, How to Play, and How to Come out Alive
December 2017 Volume 28, Issue 12 $2.00 Next Meeting, December 5: Minecraft, the Game - Its History, How to Play, and How to Come Out Alive IT COULD HAPPEN TO YOU! 88 paid-up members (including 2 new), Directors’ Notes and 11 in-grace, for a total of 99. Membership 40 people attended the l0/3/2017 gen- Information eral meeting, including 9 visitors. David Danbury Area dacs.doc, ISSN 1084-6573, is published Green reported that press releases were monthly by the Danbury Area Computer Computer Society sent out as usual. Board Meeting Minutes Society, 65 Legion Rd, New Milford, CT Websites: 06776. Annual subscription rates: $60 Wednesday, November 8, 2017 to regular members, $40 electronic ac- The meeting was called to order at Richard reported no significant prob- cess (included in dues). 7:03 pm by the DACS President, David lems on the DAC S website. Green. Postmaster ln attendance were Board members Old Business Send address changes to Danbury Area Richard Corzo, Dick Gingras, Andy Woo- Computer Society, Inc., 4 Gregory Street, Danbury, CT 06810-4430. druff and David Green (President). Also Programs: present was Charles Bovaird, who had At the December 2017 meeting Drew agreed to take minutes of the Kwashnak and his son Thomas will speak meeting. about Minecraft Editorial Committee The Minutes of the 10/3/2017 (Octo- Preview - Jim Scheef Managing Editor: Richard Teasdale Production Editor: Allan Ostergren ber) Board Meeting were accepted. Review - Richard Corzo The October Treasurer's report was re- At the January 2018 meeting Andrew Contributors ceived from Bert. -

Phone Models by OEM and Year
IN RE: Qualcomm Antitrust Litigation PHONE MODELS BY YEAR AND OEM Schedule 1.1 2011 2012 Alcatel / TCL One Touch 909S Alcatel / TCL Blaze Alcatel / TCL One Touch 990S Alcatel / TCL One Touch 909S Apple iPhone 3Gs Alcatel / TCL One Touch 918 Mix Apple iPhone 4 Alcatel / TCL One Touch 990S Apple iPhone 4s Alcatel / TCL One Touch 995 BlackBerry 8830 Alcatel / TCL Shockwave BlackBerry Bold 9650 Alcatel / TCL Unite BlackBerry Bold 9700 Alcatel / TCL Venture BlackBerry Bold 9780 Apple iPhone 3Gs BlackBerry Bold 9900 Apple iPhone 4 BlackBerry Bold 9930 Apple iPhone 4s BlackBerry Curve 8530 Apple iPhone 5 BlackBerry Curve 9300 BlackBerry 8830 BlackBerry Curve 9350 BlackBerry Bold 9650 BlackBerry Curve 9360 BlackBerry Bold 9900 BlackBerry Pearl 8130 BlackBerry Bold 9930 BlackBerry Pearl 9105 BlackBerry Curve 8530 BlackBerry Pearl Flip 8230 BlackBerry Curve 9300 BlackBerry Storm2 9550 BlackBerry Curve 9310 BlackBerry Style 9670 BlackBerry Curve 9315 BlackBerry Torch 9800 BlackBerry Curve 9350 BlackBerry Torch 9810 BlackBerry Curve 9360 BlackBerry Torch 9850 BlackBerry Curve 9370 BlackBerry Torch 9860 BlackBerry Torch 9810 BlackBerry Tour 9630 BlackBerry Torch 9850 HTC Amaze 4G BlackBerry Torch 9860 HTC Aria Coolpad Quattro HTC Arrive HTC 8X HTC Desire HTC Amaze 4G HTC Droid Incredible HTC Arrive HTC Droid Incredible 2 HTC Desire C HTC HD2 HTC Droid DNA HTC HD7 HTC Droid Incredible HTC Hero HTC Droid Incredible 2 HTC Inspire 4G HTC Evo HTC Merge HTC HD7 HTC Radar HTC Inspire 4G HTC Rezound HTC Merge HTC Rhyme HTC One S HTC Sensation HTC One V HTC -

Compatible Devices.Pdf
Compatible Devices Apple iPhone 6s Nokia 150 Dual SIM Samsung Galaxy S6 Apple iPhone 7 Nokia 3310 Dual SIM Samsung Galaxy S6 Active Apple iPhone 8 Nokia 7 plus Samsung Galaxy S6 Edge Apple iPhone SE Nokia 8 Sirocco Samsung Galaxy S6 Edge+ Apple iPhone X Nokia 8110 4G Samsung Galaxy S7 Blackberry DTEK 50 Samsung Galaxy A3 Samsung Galaxy S7 Active Blackberry DTEK 60 Samsung Galaxy A3 (2016) Samsung Galaxy S7 Edge Blackberry KEYone Samsung Galaxy A3 (2017) Samsung Galaxy S8 Google Pixel Samsung Galaxy A5 Samsung Galaxy S8 Active Google Pixel XL Samsung Galaxy A5 (2016) Samsung Galaxy S8+ Google Pixel 2 Samsung Galaxy A5 (2017) Samsung Galaxy S9 HTC U11 Samsung Galaxy A7 (2016) Samsung Galaxy S9+ HTC U11 life Samsung Galaxy A8+ Samsung Galaxy V Plus LG Aristo Samsung Galaxy AMP 2 Samsung Galaxy Xcover 3 LG Aristo 2 Samsung Galaxy AMP Prime Samsung Galaxy Xcover 4 LG Exalt LTE Samsung Galaxy AMP Prime 2 Samsung W2017 LG G5 Samsung Galaxy C5 Samsung Z1 LG G5 Silver Samsung Galaxy E5 Samsung Z2 LG G6 Samsung Galaxy Express 3 Samsung Z3 LG G6+ Samsung Galaxy Express Prime 2 Samsung Z4 LG Grace LTE Samsung Galaxy Grand Max Sony Xperia L1 LG K20 Samsung Galaxy J1 Sony Xperia X LG K20 Plus Samsung Galaxy J1 (2016) Sony Xperia X Compact LG K20 V Samsung Galaxy J2 Sony Xperia X Performance LG K3 Samsung Galaxy J2 (2016) Sony Xperia XA LG K3 2017 Samsung Galaxy J2 (2017) Sony Xperia XA1 LG K8 2017 Samsung Galaxy J3 (2016) Sony Xperia XA1 Plus LG Phoenix 3 Samsung Galaxy J3 (2017) International Sony Xperia XA2 LG Q6 Samsung Galaxy J3 Emerge Sony Xperia