CPU Scheduling (Chapter 7)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Latency and Throughput Optimization in Modern Networks: a Comprehensive Survey Amir Mirzaeinnia, Mehdi Mirzaeinia, and Abdelmounaam Rezgui
READY TO SUBMIT TO IEEE COMMUNICATIONS SURVEYS & TUTORIALS JOURNAL 1 Latency and Throughput Optimization in Modern Networks: A Comprehensive Survey Amir Mirzaeinnia, Mehdi Mirzaeinia, and Abdelmounaam Rezgui Abstract—Modern applications are highly sensitive to com- On one hand every user likes to send and receive their munication delays and throughput. This paper surveys major data as quickly as possible. On the other hand the network attempts on reducing latency and increasing the throughput. infrastructure that connects users has limited capacities and These methods are surveyed on different networks and surrond- ings such as wired networks, wireless networks, application layer these are usually shared among users. There are some tech- transport control, Remote Direct Memory Access, and machine nologies that dedicate their resources to some users but they learning based transport control, are not very much commonly used. The reason is that although Index Terms—Rate and Congestion Control , Internet, Data dedicated resources are more secure they are more expensive Center, 5G, Cellular Networks, Remote Direct Memory Access, to implement. Sharing a physical channel among multiple Named Data Network, Machine Learning transmitters needs a technique to control their rate in proper time. The very first congestion network collapse was observed and reported by Van Jacobson in 1986. This caused about a I. INTRODUCTION thousand time rate reduction from 32kbps to 40bps [3] which Recent applications such as Virtual Reality (VR), au- is about a thousand times rate reduction. Since then very tonomous cars or aerial vehicles, and telehealth need high different variations of the Transport Control Protocol (TCP) throughput and low latency communication. -
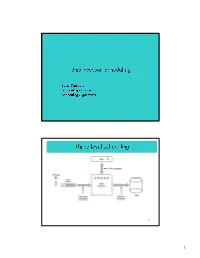
Three Level Scheduling
Uniprocessor Scheduling •Basic Concepts •Scheduling Criteria •Scheduling Algorithms Three level scheduling 2 1 Types of Scheduling 3 Long- and Medium-Term Schedulers Long-term scheduler • Determines which programs are admitted to the system (ie to become processes) • requests can be denied if e.g. thrashing or overload Medium-term scheduler • decides when/which processes to suspend/resume • Both control the degree of multiprogramming – More processes, smaller percentage of time each process is executed 4 2 Short-Term Scheduler • Decides which process will be dispatched; invoked upon – Clock interrupts – I/O interrupts – Operating system calls – Signals • Dispatch latency – time it takes for the dispatcher to stop one process and start another running; the dominating factors involve: – switching context – selecting the new process to dispatch 5 CPU–I/O Burst Cycle • Process execution consists of a cycle of – CPU execution and – I/O wait. • A process may be – CPU-bound – IO-bound 6 3 Scheduling Criteria- Optimization goals CPU utilization – keep CPU as busy as possible Throughput – # of processes that complete their execution per time unit Response time – amount of time it takes from when a request was submitted until the first response is produced (execution + waiting time in ready queue) – Turnaround time – amount of time to execute a particular process (execution + all the waiting); involves IO schedulers also Fairness - watch priorities, avoid starvation, ... Scheduler Efficiency - overhead (e.g. context switching, computing priorities, -

Measuring Latency Variation in the Internet
Measuring Latency Variation in the Internet Toke Høiland-Jørgensen Bengt Ahlgren Per Hurtig Dept of Computer Science SICS Dept of Computer Science Karlstad University, Sweden Box 1263, 164 29 Kista Karlstad University, Sweden toke.hoiland- Sweden [email protected] [email protected] [email protected] Anna Brunstrom Dept of Computer Science Karlstad University, Sweden [email protected] ABSTRACT 1. INTRODUCTION We analyse two complementary datasets to quantify the la- As applications turn ever more interactive, network la- tency variation experienced by internet end-users: (i) a large- tency plays an increasingly important role for their perfor- scale active measurement dataset (from the Measurement mance. The end-goal is to get as close as possible to the Lab Network Diagnostic Tool) which shed light on long- physical limitations of the speed of light [25]. However, to- term trends and regional differences; and (ii) passive mea- day the latency of internet connections is often larger than it surement data from an access aggregation link which is used needs to be. In this work we set out to quantify how much. to analyse the edge links closest to the user. Having this information available is important to guide work The analysis shows that variation in latency is both com- that sets out to improve the latency behaviour of the inter- mon and of significant magnitude, with two thirds of sam- net; and for authors of latency-sensitive applications (such ples exceeding 100 ms of variation. The variation is seen as Voice over IP, or even many web applications) that seek within single connections as well as between connections to to predict the performance they can expect from the network. -

The Effects of Latency on Player Performance and Experience in A
The Effects of Latency on Player Performance and Experience in a Cloud Gaming System Robert Dabrowski, Christian Manuel, Robert Smieja May 7, 2014 An Interactive Qualifying Project Report: submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUTE in partial fulfillment of the requirements for the Degree of Bachelor of Science Approved by: Professor Mark Claypool, Advisor Professor David Finkel, Advisor This report represents the work of three WPI undergraduate students submitted to the faculty as evidence of completion of a degree requirement. WPI routinely publishes these reports on its web site without editorial or peer review. Abstract Due to the increasing popularity of thin client systems for gaming, it is important to un- derstand the effects of different network conditions on users. This paper describes our experiments to determine the effects of latency on player performance and quality of expe- rience (QoE). For our experiments, we collected player scores and subjective ratings from users as they played short game sessions with different amounts of additional latency. We found that QoE ratings and player scores decrease linearly as latency is added. For ev- ery 100 ms of added latency, players reduced their QoE ratings by 14% on average. This information may provide insight to game designers and network engineers on how latency affects the users, allowing them to optimize their systems while understanding the effects on their clients. This experiment design should also prove useful to thin client researchers looking to conduct user studies while controlling not only latency, but also other network conditions like packet loss. Contents 1 Introduction 1 2 Background Research 4 2.1 Thin Client Technology . -

Job Scheduling Strategies for Networks of Workstations
Job Scheduling Strategies for Networks of Workstations 1 1 2 3 B B Zhou R P Brent D Walsh and K Suzaki 1 Computer Sciences Lab oratory Australian National University Canb erra ACT Australia 2 CAP Research Program Australian National University Canb erra ACT Australia 3 Electrotechnical Lab oratory Umezono sukuba Ibaraki Japan Abstract In this pap er we rst intro duce the concepts of utilisation ra tio and eective sp eedup and their relations to the system p erformance We then describ e a twolevel scheduling scheme which can b e used to achieve go o d p erformance for parallel jobs and go o d resp onse for inter active sequential jobs and also to balance b oth parallel and sequential workloads The twolevel scheduling can b e implemented by intro ducing on each pro cessor a registration oce We also intro duce a lo ose gang scheduling scheme This scheme is scalable and has many advantages over existing explicit and implicit coscheduling schemes for scheduling parallel jobs under a time sharing environment Intro duction The trend of parallel computer developments is toward networks of worksta tions or scalable paral lel systems In this typ e of system each pro cessor having a highsp eed pro cessing element a large memory space and full function ality of a standard op erating system can op erate as a standalone workstation for sequential computing Interconnected by highbandwidth and lowlatency networks the pro cessors can also b e used for parallel computing To establish a truly generalpurp ose and userfriendly system one of the main -

Balancing Efficiency and Fairness in Heterogeneous GPU Clusters for Deep Learning
Balancing Efficiency and Fairness in Heterogeneous GPU Clusters for Deep Learning Shubham Chaudhary Ramachandran Ramjee Muthian Sivathanu [email protected] [email protected] [email protected] Microsoft Research India Microsoft Research India Microsoft Research India Nipun Kwatra Srinidhi Viswanatha [email protected] [email protected] Microsoft Research India Microsoft Research India Abstract Learning. In Fifteenth European Conference on Computer Sys- tems (EuroSys ’20), April 27–30, 2020, Heraklion, Greece. We present Gandivafair, a distributed, fair share sched- uler that balances conflicting goals of efficiency and fair- ACM, New York, NY, USA, 16 pages. https://doi.org/10. 1145/3342195.3387555 ness in GPU clusters for deep learning training (DLT). Gandivafair provides performance isolation between users, enabling multiple users to share a single cluster, thus, 1 Introduction maximizing cluster efficiency. Gandivafair is the first Love Resource only grows by sharing. You can only have scheduler that allocates cluster-wide GPU time fairly more for yourself by giving it away to others. among active users. - Brian Tracy Gandivafair achieves efficiency and fairness despite cluster heterogeneity. Data centers host a mix of GPU Several products that are an integral part of modern generations because of the rapid pace at which newer living, such as web search and voice assistants, are pow- and faster GPUs are released. As the newer generations ered by deep learning. Companies building such products face higher demand from users, older GPU generations spend significant resources for deep learning training suffer poor utilization, thus reducing cluster efficiency. (DLT), managing large GPU clusters with tens of thou- Gandivafair profiles the variable marginal utility across sands of GPUs. -

Evaluating the Latency Impact of Ipv6 on a High Frequency Trading System
Evaluating the Latency Impact of IPv6 on a High Frequency Trading System Nereus Lobo, Vaibhav Malik, Chris Donnally, Seth Jahne, Harshil Jhaveri [email protected] , [email protected] , [email protected] , [email protected] , [email protected] A capstone paper submitted as partial fulfillment of the requirements for the degree of Masters in Interdisciplinary Telecommunications at the University of Colorado, Boulder, 4 May 2012. Project directed by Dr. Pieter Poll and Professor Andrew Crain. 1 Introduction Employing latency-dependent strategies, financial trading firms rely on trade execution speed to obtain a price advantage on an asset in order to earn a profit of a fraction of a cent per asset share [1]. Through successful execution of these strategies, trading firms are able to realize profits on the order of billions of dollars per year [2]. The key to success for these trading strategies are ultra-low latency processing and networking systems, henceforth called High Frequency Trading (HFT) systems, which enable trading firms to execute orders with the necessary speed to realize a profit [1]. However, competition from other trading firms magnifies the need to achieve the lowest latency possible. A 1 µs latency disadvantage can result in unrealized profits on the order of $1 million per day [3]. For this reason, trading firms spend billions of dollars on their data center infrastructure to ensure the lowest propagation delay possible [4]. Further, trading firms have expanded their focus on latency optimization to other aspects of their trading infrastructure including application performance, inter-application messaging performance, and network infrastructure modernization [5]. -

Low-Latency Networking: Where Latency Lurks and How to Tame It Xiaolin Jiang, Hossein S
1 Low-latency Networking: Where Latency Lurks and How to Tame It Xiaolin Jiang, Hossein S. Ghadikolaei, Student Member, IEEE, Gabor Fodor, Senior Member, IEEE, Eytan Modiano, Fellow, IEEE, Zhibo Pang, Senior Member, IEEE, Michele Zorzi, Fellow, IEEE, and Carlo Fischione Member, IEEE Abstract—While the current generation of mobile and fixed The second step in the communication networks revolutions communication networks has been standardized for mobile has made PSTN indistinguishable from our everyday life. Such broadband services, the next generation is driven by the vision step is the Global System for Mobile (GSM) communication of the Internet of Things and mission critical communication services requiring latency in the order of milliseconds or sub- standards suite. In the beginning of the 2000, GSM has become milliseconds. However, these new stringent requirements have a the most widely spread mobile communications system, thanks large technical impact on the design of all layers of the commu- to the support for users mobility, subscriber identity confiden- nication protocol stack. The cross layer interactions are complex tiality, subscriber authentication as well as confidentiality of due to the multiple design principles and technologies that user traffic and signaling [4]. The PSTN and its extension via contribute to the layers’ design and fundamental performance limitations. We will be able to develop low-latency networks only the GSM wireless access networks have been a tremendous if we address the problem of these complex interactions from the success in terms of Weiser’s vision, and also paved the way new point of view of sub-milliseconds latency. In this article, we for new business models built around mobility, high reliability, propose a holistic analysis and classification of the main design and latency as required from the perspective of voice services. -

Rotating Between Scheduling Algorithms
CARNEGIE MELLON UNIVERSITY - 15418: PARALLEL COMPUTER ARCHITECTURE AND PROGRAMMING 1 sdgOS: Rotating Between Scheduling Algorithms Valerie Choung and Samuel Damashek Abstract| We extended the SouperDamGoodOS (sdgOS) from 15-410 to support symmetric multiprocessing (SMP). Additionally, we created a mechanism for a process to select which scheduling mode it would prefer to run under. The two scheduling modes currently supported are a normal round-robin scheduling algorithm with thread-level granularity, and the other is an approximation of gang scheduling. In this paper, we discuss the implementation details our operating system and also analyze the performance of some sample programs under both scheduling algorithms. Keywords|Scheduling, Gang scheduling, OS, Autogroup. F 1 Introduction very similar to gang scheduling, except that if a processor cannot find more work from the cur- A very simple scheduling algorithm (which rently active process, it will steal work from an- we call the \normal scheduling mode", or NSM) other process's work queue. may treat all threads equally, and rotate through Our project builds on the SouperDamGoodOS threads in a round-robin fashion. However, this (sdgOS), which runs on an x86 machine support- introduces process/task-level fairness issues: if one ing a PS/2 keyboard. This environment can be process creates many threads, threads in that pro- simulated on Simics. Our study primarily has cess would take up more processor time slices in three parts to it: a given time frame when compared against other, less thread-intensive processes. 1) Implement symmetric multi-processing Gang scheduling is one way to ensure that a (SMP) process experiences a reasonable number of clock 2) Support scheduling algorithm rotations ticks before the process is switched away from to 3) Implement as syscall to switch a process be run at a later time. -

Simulation and Comparison of Various Scheduling Algorithm for Improving the Interrupt Latency of Real –Time Kernal
Journal of Computer Science and Applications. ISSN 2231-1270 Volume 6, Number 2 (2014), pp. 115-123 © International Research Publication House http://www.irphouse.com Simulation And Comparison of Various Scheduling Algorithm For Improving The Interrupt Latency of Real –Time Kernal 1.Lavanya Dhanesh 2.Dr.P.Murugesan 1.Research Scholar, Sathyabama University, Chennai, India. 2.Professor, S.A. Engineering College, Chennai, India. Email:1. [email protected] Abstract The main objective of the research is to improve the performance of the Real- time Interrupt Latency using Pre-emptive task Scheduling Algorithm. Interrupt Latency provides an important metric in increasing the performance of the Real Time Kernal So far the research has been investigated with respect to real-time latency reduction to improve the task switching as well the performance of the CPU. Based on the literature survey, the pre-emptive task scheduling plays an vital role in increasing the performance of the interrupt latency. A general disadvantage of the non-preemptive discipline is that it introduces additional blocking time in higher priority tasks, so reducing schedulability . If the interrupt latency is increased the task switching delay shall be increasing with respect to each task. Hence most of the research work has been focussed to reduce interrupt latency by many methods. The key area identified is, we cannot control the hardware interrupt delay but we can improve the Interrupt service as quick as possible by reducing the no of preemptions. Based on this idea, so many researches has been involved to optimize the pre-emptive scheduling scheme to reduce the real-time interrupt latency. -

CPU Scheduling
CPU Scheduling CS 416: Operating Systems Design Department of Computer Science Rutgers University http://www.cs.rutgers.edu/~vinodg/teaching/416 What and Why? What is processor scheduling? Why? At first to share an expensive resource ± multiprogramming Now to perform concurrent tasks because processor is so powerful Future looks like past + now Computing utility – large data/processing centers use multiprogramming to maximize resource utilization Systems still powerful enough for each user to run multiple concurrent tasks Rutgers University 2 CS 416: Operating Systems Assumptions Pool of jobs contending for the CPU Jobs are independent and compete for resources (this assumption is not true for all systems/scenarios) Scheduler mediates between jobs to optimize some performance criterion In this lecture, we will talk about processes and threads interchangeably. We will assume a single-threaded CPU. Rutgers University 3 CS 416: Operating Systems Multiprogramming Example Process A 1 sec start idle; input idle; input stop Process B start idle; input idle; input stop Time = 10 seconds Rutgers University 4 CS 416: Operating Systems Multiprogramming Example (cont) Process A Process B start B start idle; input idle; input stop A idle; input idle; input stop B Total Time = 20 seconds Throughput = 2 jobs in 20 seconds = 0.1 jobs/second Avg. Waiting Time = (0+10)/2 = 5 seconds Rutgers University 5 CS 416: Operating Systems Multiprogramming Example (cont) Process A start idle; input idle; input stop A context switch context switch to B to A Process B idle; input idle; input stop B Throughput = 2 jobs in 11 seconds = 0.18 jobs/second Avg. -

Telematic Performance and the Challenge of Latency
This is a repository copy of Telematic performance and the challenge of latency. White Rose Research Online URL for this paper: https://eprints.whiterose.ac.uk/126501/ Version: Accepted Version Article: Rofe, Michael and Reuben, Federico orcid.org/0000-0003-1330-7346 (2017) Telematic performance and the challenge of latency. The Journal of Music, Technology and Education. 167–183. ISSN 1752-7074 https://doi.org/10.1386/jmte.10.2-3.167_1 Reuse Items deposited in White Rose Research Online are protected by copyright, with all rights reserved unless indicated otherwise. They may be downloaded and/or printed for private study, or other acts as permitted by national copyright laws. The publisher or other rights holders may allow further reproduction and re-use of the full text version. This is indicated by the licence information on the White Rose Research Online record for the item. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ Telematic performance and the challenge of latency Michael Rofe | Federico Reuben Abstract Any attempt to perform music over a network requires engagement with the issue of latency. Either latency needs to be reduced to the point where it is no longer noticeable or creative alternatives to working with latency need to be developed. Given that Online Orchestra aimed to enable performance in community contexts, where significant bandwidth and specialist equipment were not available, it would not be possible to reduce latency below the 20–30ms cut-off at which it becomes noticeable.