A Geospatial Analysis of Voting Behavior in Worcester, MA
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2019 TIGER/Line Shapefiles Technical Documentation
TIGER/Line® Shapefiles 2019 Technical Documentation ™ Issued September 2019220192018 SUGGESTED CITATION FILES: 2019 TIGER/Line Shapefiles (machine- readable data files) / prepared by the U.S. Census Bureau, 2019 U.S. Department of Commerce Economic and Statistics Administration Wilbur Ross, Secretary TECHNICAL DOCUMENTATION: Karen Dunn Kelley, 2019 TIGER/Line Shapefiles Technical Under Secretary for Economic Affairs Documentation / prepared by the U.S. Census Bureau, 2019 U.S. Census Bureau Dr. Steven Dillingham, Albert Fontenot, Director Associate Director for Decennial Census Programs Dr. Ron Jarmin, Deputy Director and Chief Operating Officer GEOGRAPHY DIVISION Deirdre Dalpiaz Bishop, Chief Andrea G. Johnson, Michael R. Ratcliffe, Assistant Division Chief for Assistant Division Chief for Address and Spatial Data Updates Geographic Standards, Criteria, Research, and Quality Monique Eleby, Assistant Division Chief for Gregory F. Hanks, Jr., Geographic Program Management Deputy Division Chief and External Engagement Laura Waggoner, Assistant Division Chief for Geographic Data Collection and Products 1-0 Table of Contents 1. Introduction ...................................................................................................................... 1-1 1. Introduction 1.1 What is a Shapefile? A shapefile is a geospatial data format for use in geographic information system (GIS) software. Shapefiles spatially describe vector data such as points, lines, and polygons, representing, for instance, landmarks, roads, and lakes. The Environmental Systems Research Institute (Esri) created the format for use in their software, but the shapefile format works in additional Geographic Information System (GIS) software as well. 1.2 What are TIGER/Line Shapefiles? The TIGER/Line Shapefiles are the fully supported, core geographic product from the U.S. Census Bureau. They are extracts of selected geographic and cartographic information from the U.S. -

Glossary of Redistricting Terms
Glossary of Redistricting Terms Apportionment or Reapportionment Following each decennial census, seats in the United States House of Representatives are apportioned to each state based on population figures derived from the census. Apportionment is the process of determining how many Congressional Districts to allocate to each state, and is different from ‘redistricting,’ which involves redrawing district lines within a state. At-large An election in which candidates run in all parts of a jurisdiction rather than from districts or wards within the jurisdiction. All members of EVIT’s Board of Governors are elected from specific districts within EVIT’s boundary. There are no at-large election contests. Census Block The smallest level of census geography used by the Census Bureau to collect and report census data. Census Blocks are labeled with a four digit number such as 2025 or 1006A. Census Block Group A group of Census Blocks all having the same first block digit. Block 2025 is in Block Group 2. There are 1,023 whole or partial Block Groups within EVIT’s jurisdiction. The latest available population data for this redistricting process is at the Block Group level. Census data Information and statistics on the population of the United States gathered by the Census Bureau and released to the public. Census Tract A level of census geography larger than a census block or census block group that often corresponds to neighborhood boundaries. There are 385 whole or partial Census Tracts within EVIT’s boundary – too few for our purpose in redistricting. Community of interest An area that is defined by residents’ shared demographics or by common threads of social, economic, or political interests such that the area may benefit from common representation. -

Census Bureau Public Geocoder
1. What is Geocoding? Geocoding is an attempt to provide the geographic location (latitude, longitude) of an address by matching the address to an address range. The address ranges used in the geocoder are the same address ranges that can be found in the TIGER/Line Shapefiles which are derived from the Master Address File (MAF). The address ranges are potential address ranges, not actual address ranges. Potential ranges include the full range of possible structure numbers even though the actual structures might not exist. The majority of the address ranges we have are for residential areas. There are limited address ranges available in commercial areas. Our address ranges are regularly updated with the most current information we have available to us. The hypothetical graphic below may help customers understand the concept of geocoding and Census Geography (addresses displayed in this document are factitious and shown for example only.) If we look at Block 1001 in the example below the address range in red 101-199 is the range of numbers that overlap the actual individual house numbers associated with the blue circles (e.g. 103, 117, 135 and 151 Main St) on that side of the street (i.e. the Left side, note the arrow is pointing to the right on Main Street.) Based on this logic, the from address would be 101 and the to address would be 199 for this address range. Besides providing a user with the geographic location of an address the Census Geocoder can also provide all of the additional Census geographic information associated with a location, for example a Census Block, Tract, County, and State. -

Official Redistricting Database
CREATING CALIFORNIA’S OFFICIAL REDISTRICTING DATABASE Kenneth F. McCue, Ph.D. Research Scientist, Department of Biology California Institute of Technology http://swdb.berkeley.edu/ August 2011 I. TABLE OF CONTENTS I. TABLE OF CONTENTS ............................................................................................................................ 1 II. EXECUTIVE SUMMARY ....................................................................................................................... 2 III. INPUTS .............................................................................................................................................. 4 A. Census Data ....................................................................................................................................... 4 Figure 1: Geographic Relationships--Small Area Statistical Entities ......................................... 4 Figure 2: A 2010 Census Block Which is Not a City Block ......................................................... 5 B. Registered Voter Data ........................................................................................................................ 5 C. Election Data ..................................................................................................................................... 7 IV. PROCESSING .......................................................................................................................................... 8 A. Creating a Uniform Geography ........................................................................................................ -

2030 Wisconsin State Airport System Plan
8.0 Environmental Justice 8.1 Chapter Purpose and Content Wisconsin is committed to integrating the principle of environmental justice into all transportation planning programs and activities. For purposes of this chapter, environmental justice populations are defined as including minority, low-income, children (age 17 and under), seniors (age 65 and older) and zero-vehicle household populations. These environmental justice populations have been assessed in relation to their geographic location, and the presence and operations of the statewide airport system. The information contained in this chapter includes an evaluation of the relationship between the Wisconsin State Airport System Plan (SASP) recommendations and environmental justice populations. This environmental justice chapter also supplements the system plan environmental evaluation included in Chapter 9, which discusses the potential environmental and community impacts of implementing the SASP. Lastly, this chapter identifies areas for consideration during future planning and project-level activities. It is important to note that this evaluation discusses the SASP recommendations at a state-wide system level. Prior to implementation of each individual project, individual project specific environmental reviews will be completed which will include an environmental justice evaluation. The implementation of any specific improvement identified in this plan remains the responsibility of local airport sponsors, and the projects identified do not constitute a commitment of either state or federal funding. The approval and project justification of local master planning efforts, environmental review processes and funding approvals remain a sponsor responsibility. Similar to Wisconsin’s Long-Range Transportation Plan (Connections 2030), the SASP is a policy- based plan developed to be flexible and responsive to shifts in investment priorities. -

GLOSSARY Glossary
volume 2 | GLOSSARY Glossary TERM DEFINITION adaptive reuse Use of a building for a purpose not originally intended while retaining historic features. affordable housing Housing whose total cost (including insurance and similar expenses) accounts for no more than 30 percent of household income. base flood elevation(BFE) The elevation to which floodwater is anticipated to rise during a flood. A regulatory requirement for the eleva- tion or flood proofing of buildings. ABFE - Advisory Base Flood Elevation. best practice A technique or method that is generally agreed upon by a community of experts to be the most effective means of delivering a particular outcome. block group Census block group blueway A waterway route, typically with landscaped banks and used as a recreational or aesthetic amenity. Big Four Nickname for the four largest developments under the management of the Housing Authority of New Orleans and all in redevelopment as of 2009: B.W. Cooper, C.J. Peete, Lafitte and St. Bernard. bicycle boulevard Bicycle routes on shared roadways with light motorized vehicle traffic that are designed to optimize bicycle travel with safety and traffic calming elements. blight Dilapidated property due to insufficient maintenance or other destructive forces. A blighted property often presents a health and/or safety hazard and is generally considered a public nuisance. brownfield A building or property that contains real or perceived contamination which inhibits its redevelopment or use. bus rapid transit (BRT) A system of public transportation that uses buses to provide higher-speed service than ordinary bus lines, often with reserved traffic lanes, or specialized traffic signals, and stations. -

2020 Census Prototype PL 94-171 TIGER/Linetm Shapefiles 2018
2020 Census Prototype P.L. 94-171 TIGER/LineTM Shapefiles 2018 Technical Documentation ™ Issued February 2019 SUGGESTED CITATION FILES: 2020 Census Prototype P.L. 94-171 TIGER/LineTM Shapefiles (machine- readable data files) / prepared by the U.S. Department of Commerce Economic and Statistics Administration U.S. Census Bureau, 2019 Wilbur Ross, Secretary Karen Dunn Kelley, Under Secretary for Economic Affairs TECHNICAL DOCUMENTATION: 2020 Census Prototype P.L. 94-171 TIGER/LineTM Shapefiles Technical Documentation / prepared by the U.S. Census Bureau, 2019 U.S. Census Bureau Steven Dillingham, Albert Fontenot, Director Associate Director for Decennial Census Programs Ron Jarmin, Deputy Director GEOGRAPHY DIVISION Deirdre Dalpiaz Bishop, Chief Andrea G. Johnson, Michael R. Ratcliffe, Assistant Division Chief for Assistant Division Chief for Address and Spatial Data Updates Geographic Standards, Criteria, Research, and Quality Monique Eleby, Assistant Division Chief for Gregory F. Hanks, Jr., Geographic Program Management Deputy Division Chief and External Engagement Laura Waggoner, Assistant Division Chief for Geographic Data Collection and Products 1-0 Table of Contents 1. Introduction ............................................................................................................................................... 1-1 1.1 What is a Shapefile? ............................................................................................................................ 1-1 1.2 What are TIGER/Line Shapefiles? ....................................................................................................... -

Historical Glossary (2010S)
Historical Glossary (2010s) A American Community Survey (ACS) An ongoing census survey sent to a sample of three million housing units annually. The ACS collects detailed demographic and socioeconomic population and housing characteristics, similar to the information collected on the former long-form census questionnaire. The data is collected continuously rather than once a decade, so the ACS provides more current data. Single‐year estimates are available annually for geographic areas with a population of 65,000 or more. Three‐year estimates are available annually for geographic areas with a population of 20,000 or more. In December 2010, the first five‐year estimates at the census tract and block group level were made available. Anglo Those persons who identified their race on the census form as White only and not Hispanic. Assignment unit Any unit of geography that may be used as a building block to draw a redistricting plan. Assignment units available in RedAppl are counties, census tracts, census block groups, census blocks, and VTDs (voting tabulation districts). B Black Those persons who identified their race on the census form as Black, African American, or Negro only or Black and any other race. Black persons can be either Hispanic or non-Hispanic. Black + Hispanic A combined population category that includes all persons who identified their race as Black and all persons who identified themselves as Hispanic. The total is adjusted so that those who indicated they were both Black and Hispanic are not counted twice. The category is frequently examined for redistricting purposes in areas in which Black and Hispanic voters may form political coalitions or vote together as a bloc. -

OFM2010 Population and Housing Estimates Metadata
OFM 2000-2013 SAEP Population and Housing Esimates for 2010 Census Block Groups OFM 2000-2013 SAEP Population and Housing Esimates for 2010 Census Block Groups Metadata: Identification_Information Data_Quality_Information Spatial_Data_Organization_Information Spatial_Reference_Information Entity_and_Attribute_Information Distribution_Information Metadata_Reference_Information Identification_Information: Citation: Citation_Information: Originator: Washington State Office of Financial Management, Forecasting Division and U.S. Department of Commerce, U.S. Census Bureau, Geography Division Publication_Date: 2010 Title: OFM 2000-2013 SAEP Population and Housing Esimates for 2010 Census Block Groups Edition: 2010 Geospatial_Data_Presentation_Form: vector digital data Online_Linkage: <http://www.census.gov/geo/www/tiger> Description: Abstract: The TIGER/Line Files are shapefiles and related database files (.dbf) that are an extract of selected geographic and cartographic information from the U.S. Census Bureau's Master Address File / Topologically Integrated Geographic Encoding and Referencing (MAF/TIGER) Database (MTDB). The MTDB represents a seamless national file with no overlaps or gaps between parts, however, each TIGER/Line File is designed to stand alone as an independent data set, or they can be combined to cover the entire nation. Block Groups (BGs) are defined before tabulation block delineation and numbering, but are clusters of blocks within the same census tract that have the same first digit of their 4-digit census block number from the same decennial census. For example, Census 2000 tabulation blocks 3001, 3002, 3003,.., 3999 within Census 2000 tract 1210.02 are also within BG 3 within that census tract. Census 2000 BGs generally contained between 600 and 3,000 people, with an optimum size of 1,500 people. Most BGs were delineated by local participants in the Census Bureau's Participant Statistical Areas Program (PSAP). -

Federal Register/Vol. 73, No. 51/Friday, March 14, 2008/Notices
Federal Register / Vol. 73, No. 51 / Friday, March 14, 2008 / Notices 13829 Deletion which would be likely to significantly group criteria for the 2010 Census Regulatory Flexibility Act Certification frustrate implementation of a proposed remain unchanged from those used in agency action. (5 U.S.C. 552b.(c)(9)(B)) conjunction with the 2000 Decennial I certify that the following action will not have a significant impact on a substantial In addition, part of the discussion will Census, except as follows. First, the number of small entities. The major factors relate solely to the internal personnel same population and housing unit considered for this certification were: and organizational issues of the BBG or thresholds, a minimum of 600 people or 1. If approved, the action should not result the International Broadcasting Bureau. 240 housing units and a maximum of in additional reporting, recordkeeping or (5 U.S.C. 552b.(c)(2) and (6)). 3,000 people or 1,200 housing units, other compliance requirements for small CONTACT PERSON FOR MORE INFORMATION: will apply to all types of populated entities. Persons interested in obtaining more block groups, including block groups 2. If approved, the action may result in delineated within American Indian authorizing small entities to furnish the information should contact Timi service to the Government. Nickerson Kenealy at (202) 203–4545. reservations and off-reservation trust lands, the Island Areas, and 3. There are no known regulatory Dated: March 11, 2008. encompassing group quarters, military alternatives which would accomplish the Timi Nickerson Kenealy, objectives of the Javits-Wagner-O’Day Act (41 installations, and institutions. -

Geographic Levels in NEO CANDO 2010+
Geographic Levels in NEO CANDO 2010+ Data in NEO CANDO 2010+ are available at several levels of aggregation including census geographies and locally defined geographies. Descriptions of each of the different aggregations are provided below. For more detailed information about the census geographies click here. All of the data in NEO CANDO 2010+ are based on 2010 tract boundary definitions. In addition to the 2010 Census and estimates from the American Community Survey (ACS), NEO CANDO 2010+ provides estimates of the 2000 census data in 2010 census geography. Because of changes in boundaries between 2000 and 2010, we have estimated the 2000 data using apportionment methods. We also geocode data we receive at the address level and assign and aggregate it to the 2010 census geography. Census tract level data are available for the following 17 counties: Ashland, Ashtabula, Columbiana, Cuyahoga, Erie, Geauga, Huron, Lake, Lorain, Mahoning, Medina, Portage, Richland, Stark, Summit, Trumbull, and Wayne. Keep in mind that some census tracts have changed numbers, been split, or changed physical boundaries over the last decade. Analysis of trends over time requires that data be based on the same geographic boundaries. A tract that existed in 2000 may not exist in 2010; the tract number may have changed, or the physical boundaries may have changed. We ensure the user is comparing apples to apples by converting all of our data in NEO CANDO 2010+ into the same geographic boundaries -- 2010 geography. The user should not compare data in the 2000 geography to data in the 2010 geography. CENSUS GEOGRAPHIES1 Census Block Census blocks are the smallest census geography. -
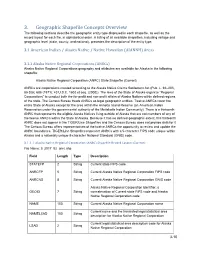
2017 TIGER/Line Shapefiles Technical Documentation Chapter 3
3. Geographic Shapefile Concepts Overview The following sections describe the geographic entity type displayed in each shapefile, as well as the record layout for each file, in alphabetical order. A listing of all available shapefiles, including vintage and geographic level (state, county, and national), precedes the description of the entity type. 3.1 American Indian / Alaska Native / Native Hawaiian (AIANNH) Areas 3.1.1 Alaska Native Regional Corporations (ANRCs) Alaska Native Regional Corporations geography and attributes are available for Alaska in the following shapefile: Alaska Native Regional Corporation (ANRC) State Shapefile (Current) ANRCs are corporations created according to the Alaska Native Claims Settlement Act (Pub. L. 92–203, 85 Stat. 688 (1971); 43 U.S.C. 1602 et seq. (2000)). The laws of the State of Alaska organize “Regional Corporations” to conduct both the for-profit and non-profit affairs of Alaska Natives within defined regions of the state. The Census Bureau treats ANRCs as legal geographic entities. Twelve ANRCs cover the entire State of Alaska except for the area within the Annette Island Reserve (an American Indian Reservation under the governmental authority of the Metlakatla Indian Community). There is a thirteenth ANRC that represents the eligible Alaska Natives living outside of Alaska that are not members of any of the twelve ANRCs within the State of Alaska. Because it has no defined geographic extent, this thirteenth ANRC does not appear in the TIGER/Line Shapefiles and the Census Bureau does not provide data for it. The Census Bureau offers representatives of the twelve ANRCs the opportunity to review and update the ANRC boundaries.