A Portable, Object-Oriented Library for Neural Network Simulation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Embedded Systems Software Engineer Is Responsible for Designing the Embedded Systems and Installing Them in Machines and Tools
Embedded Systems Software Engineer Responsibilities Embedded systems software engineer is responsible for designing the embedded systems and installing them in machines and tools. They design and develop the software that controls the processor (micro-controllers and digital signal processors) of the machine. These systems provide functionality to the machines. The work of an embedded engineer is considered as important and challenging, since their efforts give utility to a machine. If you are keen on handling embedded systems software engineer responsibilities, then you need to be aware of the requirements, duties and career scope of this profile. Here are a few details for your assistance. An embedded system refers to a computerized system that controls the functioning of a specific machine. Every machine is built with a specific purpose. The embedded software functions like the brain of the machine and controls the tasks that the machine is designed to perform. The micro-controller is a chip that has the memory to store program data. It receives the commands, operates as per the inputted data and provides relevant results. Some popular examples of appliances that use embedded systems are digital watches, cars, robots, toys, electric appliances, etc. Understand the client requirements and write down the software details Study the specifications provided by the clients and seek clarifications for the doubts raised Submit the price quote and the details of the time required to execute the plan Receive the client's approval for the -

Preguntas Más Frecuentes Sobre Embarcadero RAD Studio XE Danysoft | Representante Exclusivo En La Península Ibérica
Preguntas más frecuentes sobre Embarcadero RAD Studio XE Danysoft | Representante exclusivo en la península ibérica What is Embarcadero RAD Studio? Embarcadero RAD Studio XE is a comprehensive application development suite and the fastest way to visually build GUI‐intensive, data‐driven applications for Windows, .NET, PHP and the Web. RAD Studio XE includes Delphi®, C++Builder®, Delphi Prism™, and RadPHP™; providing powerful compiled, managed and dynamic language support, heterogeneous database connectivity, rich visual component frameworks, and a vast 3rd party ecosystem – enabling you to deliver applications up to 5x faster across multiple Windows, Web, and database platforms. RAD Studio’s development environments dramatically simplify and speed visual and data‐intensive application development for GUI desktop and touch‐screen applications, database‐driven, multi‐ tier, cloud, and Web applications and services Which editions are available and what are the differences between the editions? RAD Studio XE Professional RAD Studio XE Professional is designed for software developers and teams building native Windows, .NET, and touch‐screen applications with or without embedded and local database persistence. RAD Studio includes Delphi®, C++Builder® , Delphi Prism™, and RadPHP™ providing you with everything needed for fast native Windows, .NET, PHP and Web development. Features include: Local database connectivity to InterBase® and MySQL in Delphi and C++Builder Database connectivity available in Visual Studio via ADO.NET including local -

488-Pc2 Isa Bus Gpib Controller Card
IBM PC GPIB PRODUCTS 488-PC2 ISA BUS GPIB CONTROLLER CARD ■ Converts any ISA bus PC into a GPIB Controller Works in virtually all PCs. DESCRIPTION ■ Fast data transfer rate >300 kbytes/second. ICS's 488-PC2 is an enhanced IEEE 488 Bus Fast throughput. Interface Card that converts any PC with an ISA ■ bus into a full-function IEEE 488.2 Bus Control- DLLs for Windows 3.1, 95 ler. The 488-PC2 Card can also function as an and 98 programs support 16 IEEE 488 interface that lets you use your personal and 32 bit applications. computer as a bus device. The 488-PC2 Card 488.2 support for all MS performs all of the basic IEEE 488.1 functions Windows programming lan- such as talker, listener and system controller or 488-PC2 Card guages. Controller-in-charge. ■ IEEE-488.2 linkable libraries Hardware Keyboard Controller Programs for Quick Basic, MS Visual Basic for DOS, The 488-PC2 card is implemented with pro- The 488-PC2 software also includes DOS Borland C/C++ and grammable logic arrays and an NEC 7210 type and Window versions of ICS's Interactive Key- Microsoft C/C++. bus controller chip to provide high speed DMA board Controller programs These ready-to-run 488.2 support for the most transfers with data rates up to 300 Kbytes per interactive programs give the user direct control popular DOS languages. second. On card switches select the address, DMA of GPIB devices from the computer keyboard channels 1, 2, or 3, Interrupt levels 2 through 7 and without having to write a program. -

488-Pc2 Isa Bus Gpib Controller Card
IBM PC GPIB PRODUCTS 488-PC2 ISA BUS GPIB CONTROLLER CARD ■ Converts any ISA bus PC into a GPIB Controller Works in virtually all PCs. DESCRIPTION ■ Fast data transfer rate >300 kbytes/second. ICS's 488-PC2 is an enhanced IEEE 488 Bus Fast throughput. Interface Card that converts any PC with an ISA ■ bus into a full-function IEEE 488.2 Bus Control- DLLs for Windows 3.1, 95 ler. The 488-PC2 Card can also function as an and 98 programs support 16 IEEE 488 interface that lets you use your personal and 32 bit applications. computer as a bus device. The 488-PC2 Card 488.2 support for all MS performs all of the basic IEEE 488.1 functions Windows programming lan- such as talker, listener and system controller or 488-PC2 Card guages. Controller-in-charge. ■ IEEE-488.2 linkable libraries Hardware Keyboard Controller Programs for Quick Basic, MS Visual Basic for DOS, The 488-PC2 card is implemented with pro- The 488-PC2 software also includes DOS Borland C/C++ and grammable logic arrays and an NEC 7210 type and Window versions of ICS's Interactive Key- Microsoft C/C++. bus controller chip to provide high speed DMA board Controller programs These ready-to-run 488.2 support for the most transfers with data rates up to 300 Kbytes per interactive programs give the user direct control popular DOS languages. second. On card switches select the address, DMA of GPIB devices from the computer keyboard channels 1, 2, or 3, Interrupt levels 2 through 7 and without having to write a program. -

Evan A. Bauer
Evan A. Bauer [email protected] Technology executive, architect, strategist, developer, and troubleshooter. Committed to creating revenue and improving business and technical operations through the discovery and application of innovative innovative technology and best practices. Successful implementer of complex applications, enterprise infrastructure, distributed information systems and mission critical trading systems for the financial services industry. More than twenty-five years experience with systems where integrity, performance and availability are critical, including distributed database, data warehouse, real-time, and high volume transaction processing applications. Implement and support leading edge technologies and software engineering methodologies to meet business goals. Effective as both technical leader and manager of high performance teams. Advisor to both investment bankers and venture capital investors on technology products and companies. Accomplished writer, presenter, and teacher to business and technical audiences. Experience with IT in a wide range of industries in in-house, consultant, analyst and vendor, roles. Special interest and expertise in IT for financial services and in enterprise applications of open source technologies. Professional Experience Evan Bauer Information Technology and Fanzilli | Bauer Technology Partners 2002 - current Independent Consultancy Clientele includes financial services firms, major technology companies, venture capital funds, private equity firms, fund-of-hedge-funds, and start-up enterprise -

Fakultas Komputer Name Mahasiswa Section Class Content 1 TEKNIK
Fakultas Komputer Name Mahasiswa Section Class Content TEKNIK INFORMATIKA TENTANG DELPHI SUHARYANTO 165100070 Fakultas Komputer, 448757233 [email protected] Abstract Delphi adalah sebuah IDE compiler untuk bahasa pemrograman Pascal. Borland Delphi merupakan salah satu bahasa pemrograman yang semenjak diluncurkan pertama kali langsung dilirik dan diminati oleh para programmer komputer. Hal ini disebabakan karena Delphi menyediakan fasilitas untuk pembuatan aplikasi dengan antarmuka visual secara mudah dan dapat memberikan hasil yang memuaskan. tapi yang namanya suatu produk mesti ada saja kekurangan nya. Berikut adalah kekurangan dan kelebihan delphi.. Kata Kunci : Teknik Informatika Tentang Delphi A. INTRODUCTION programmer dengan komputer , disebut Materi Ke 1 membahas mengenai i dengan Bahasa Pemrograman. cloud system ...dst tambahkan gambar Bahasa pemrograman adalah untuk memperkuat penjelasan ( Gunakan Minimal 600 kata ) teknik komunikasi standar untuk mengekspresikan instruksi kepada Jawab : komputer. Layaknya bahasa manusia, Ketika seorang programmer ingin setiap bahasa memiliki tata tulis dan membuat sebuah program, sang aturan tertentu. Bahasa pemrograman programmer harus mempunyai suatu memfasilitasi seorang programmer untuk media untuk dapat berkomunikasi dengan secara spesifik apa yang akan dilakukan komputer. Media tersebut akan menjadi oleh komputer selanjutnya, bagaimana penyambung, apa yang diingkinkan oleh data tersebut disimpan dan dikirim, dan sang programmer dengan apa yang apa yang akan dilakukan apabila terjadi nantinya akan di lakukan oleh komputer. kondisi yang variatif. Bahasa Media yang digunakan seorang pemrograman dapat diklasifikasikan 1 Fakultas Komputer Name Mahasiswa Section Class Content menjadi tingkat rendah, menengah, dan 2.1. Sejarah dan Perkembangan Bahasa tingkat tinggi. Pergeseran tingkat dari Pemrograman Secara Umum rendah menuju tinggi menunjukkan kedekatan terhadap ”bahasa manusia”. Sebelum mempelajari lebih dalam tentang suatu bahasa pemrograman tertentu, sebaiknya perlu mengetahui 1. -

Ryle Design Product List - Winter 1998 Visit Our World Wide Web Site Or Call/Fax/Email for Detailed Specifications
Ryle Design Product List - Winter 1998 Visit our World Wide Web site or call/fax/email for detailed specifications ExacTicks V1.1 .................................................................................................................................................. US$149.95 ExacTicks provides precision microsecond resolution timing, delays, alarms, and millisecond resolution event scheduling under Windows 3.1, Windows 95, and Windows NT. ExacTicks is the new Windows version of our popular PC Timer Tools and PC Timer Objects libraries for DOS, and provides 16 and 32 bit DLLs to implement precise time measurement and scheduling under Windows. ExacTicks ships with 16 and 32 bit DLL interface code for C/C++, Borland C++ Builder, Delphi, and Visual Basic. Full source and a royalty free DLL distribution license is included BGI SVGA Video Driver Toolkit V1.0 ................................................................................................................ US$129.95 High resolution Super VGA video drivers for the Borland BGI graphics library. Our single SVGA video driver supports 24 different SVGA chipsets and VESA, and runs at up to 1280x1024 pixels in both 16 and 256 color modes. Includes full SVGA mouse support, multiple video pages, and PCX/BMP file import/export. Complete with source code, royalty-free driver distribution license, support for Turbo/Borland C/C++, Turbo/Borland Pascal, real and 16 bit protected modes. If you’ve got a serious BGI graphics app, don’t settle for an unsupported and out of date shareware or public domain SVGA BGI driver - get a quality SVGA driver and make your BGI graphics app look its high resolution best. BGI Printer Driver Toolkit V1.2 .......................................................................................................................... US$129.95 High resolution BGI printer drivers for the Borland BGI graphics library. -
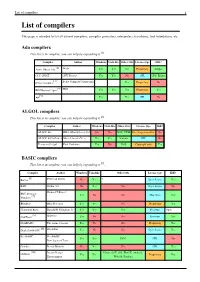
List of Compilers 1 List of Compilers
List of compilers 1 List of compilers This page is intended to list all current compilers, compiler generators, interpreters, translators, tool foundations, etc. Ada compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [2] Aonix Object Ada Atego Yes Yes Yes Proprietary Eclipse GCC GNAT GNU Project Yes Yes No GPL GPS, Eclipse [3] Irvine Compiler Irvine Compiler Corporation Yes Proprietary No [4] IBM Rational Apex IBM Yes Yes Yes Proprietary Yes [5] A# Yes Yes GPL No ALGOL compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? ALGOL 60 RHA (Minisystems) Ltd No No DOS, CP/M Free for personal use No ALGOL 68G (Genie) Marcel van der Veer Yes Yes Various GPL No Persistent S-algol Paul Cockshott Yes No DOS Copyright only Yes BASIC compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [6] BaCon Peter van Eerten No Yes ? Open Source Yes BAIL Studio 403 No Yes No Open Source No BBC Basic for Richard T Russel [7] Yes No No Shareware Yes Windows BlitzMax Blitz Research Yes Yes No Proprietary Yes Chipmunk Basic Ronald H. Nicholson, Jr. Yes Yes Yes Freeware Open [8] CoolBasic Spywave Yes No No Freeware Yes DarkBASIC The Game Creators Yes No No Proprietary Yes [9] DoyleSoft BASIC DoyleSoft Yes No No Open Source Yes FreeBASIC FreeBASIC Yes Yes DOS GPL No Development Team Gambas Benoît Minisini No Yes No GPL Yes [10] Dream Design Linux, OSX, iOS, WinCE, Android, GLBasic Yes Yes Proprietary Yes Entertainment WebOS, Pandora List of compilers 2 [11] Just BASIC Shoptalk Systems Yes No No Freeware Yes [12] KBasic KBasic Software Yes Yes No Open source Yes Liberty BASIC Shoptalk Systems Yes No No Proprietary Yes [13] [14] Creative Maximite MMBasic Geoff Graham Yes No Maximite,PIC32 Commons EDIT [15] NBasic SylvaWare Yes No No Freeware No PowerBASIC PowerBASIC, Inc. -

Controlling Robot Through Internet Using Java by Mr
Journal of Industrial Technology • Volume 20, Number 3 • June 2004 through August 2004 • www.nait.org Volume 20, Number 3 - June 2004 through August 2004 Controlling Robot Through Internet Using Java By Mr. Ravindra Thamma, Dr. Luke H. Huang, Dr. Shi-Jer Lou and Dr. C. Ray Diez Peer-Refereed Article KEYWORD SEARCH CIM Distance Learning Internet Manufacturing Robotics Teaching Methods The Official Electronic Publication of the National Association of Industrial Technology • www.nait.org © 2004 1 Journal of Industrial Technology • Volume 20, Number 3 • June 2004 through August 2004 • www.nait.org Controlling Robot Through Internet Using Java By Mr. Ravindra Thamma, Dr. Luke H. Huang, Dr. Shi-Jer Lou and Dr. C. Ray Diez Mr. Ravindra Thamma. MSIT, is an Assistant pro- Background and Need on arbitrary remote computer platforms fessor in the Department of Technology at Univer- An issue with people who want to interacting with a robotic control. sity of North Dakota. He conducts research on ro- botic, intelligent controls system, computer inter- pursue an education is how to enroll in face and ultrasonic. He teaches electro mechani- courses while working full-time. While In a study conducted to access a remote cal fundamentals, digital integrated circuits, PLCs, micro controllers, and robotics. working everyday diminishes opportu- manufacturing system through internet, nities for on campus study, distance Calkin and Parkin (1998) developed education becomes a major option and simulation tools for remotely-con- has been accepted widely. Though trolled robots. The simulation tools for distance education works for many the robotic hardware were developed fields of study, it is difficult for those using Java and VRML 97 to create a fields that require laboratory activities, desktop virtual-reality environment. -

Preguntas + Frecuentes Delphi XE Danysoft | Representante Exclusivo En La Península Ibérica
Preguntas + Frecuentes Delphi XE Danysoft | Representante exclusivo en la península ibérica ¿What is Delphi? Embarcadero® Delphi® XE is the fastest way to deliver ultra‐rich, ultra‐fast Windows applications. Used by millions of developers, Delphi combines a leading‐edge object‐oriented language, fast native compilation, heterogeneous database connectivity, and a rich visual component‐based development framework supported by thousands of third party components and add‐ons. Delphi’s fully visual two‐way RAD IDE is designed to dramatically simplify and speed development of visual and data‐intensive applications including native Windows GUI desktop applications, interactive touch‐screen, kiosk, and database‐driven multi‐tier, cloud, and Web applications. Deliver applications up to 5x faster and with fewer developers across multiple Windows and database platforms. Which editions are available and what are the differences between the editions? Delphi XE Professional Delphi® XE Professional is designed for developers building high‐performance desktop GUI and touch‐screen applications with or without embedded and local database persistence. Delphi XE Professional's ability to generate fast single exe Windows applications with rich user experiences makes it especially well‐suited for ISVs building highly‐graphical "packaged" Windows applications that seamlessly support an array of Windows versions without modification. Delphi XE Enterprise Delphi XE Enterprise is designed for developers building rich, data‐oriented client/server, cloud, and multi‐tier GUI and Web applications that work seamlessly with a wide variety of database servers and data sources. Delphi Enterprise’s high‐ performance heterogeneous database server support is ideal for multi‐vendor database server scenarios, or building turnkey applications that can work with a wide array of database servers. -

Dynamicsignals / Gage Applied Compuscope 220 Driver Manual (Pdf)
Full-service, independent repair center -~ ARTISAN® with experienced engineers and technicians on staff. TECHNOLOGY GROUP ~I We buy your excess, underutilized, and idle equipment along with credit for buybacks and trade-ins. Custom engineering Your definitive source so your equipment works exactly as you specify. for quality pre-owned • Critical and expedited services • Leasing / Rentals/ Demos equipment. • In stock/ Ready-to-ship • !TAR-certified secure asset solutions Expert team I Trust guarantee I 100% satisfaction Artisan Technology Group (217) 352-9330 | [email protected] | artisantg.com All trademarks, brand names, and brands appearing herein are the property o f their respective owners. Find the DynamicSignals / GaGe Compuscope 220 at our website: Click HERE CompuScope Drivers for the CompuScope 6012 CompuScope 1012 CompuScope 250 CompuScope 225 CompuScope 220 CompuScope LITE DOS Driver and Windows DLL Documentation for Borland C 3.1 + Microsoft C 5.1 + Watcom C 9.0 + Turbo Pascal for Windows 1.0 + Visual Basic 1.0 + Quick Basic 4.5 Protected Mode Pascal 7.0 LabWindows / CVI Copyright (C) 1994 by Gage Applied Sciences Inc. Phone (514) 337-6893 Fax (514) 337-8411 BBS (514) 337-4317 Artisan Technology Group - Quality Instrumentation ... Guaranteed | (888) 88-SOURCE | www.artisantg.com © Copyright Gage Applied Sciences Inc. 1994 5465 Vanden Abeele, Montreal, Quebec, Canada H4S 1S1 Tel: 1-800-567-GAGE or (514) 337-6893. Fax: (514) 337-8411. BBS: (514) 337-4317 GAGESCOPE, COMPUSCOPE, COMPUSCOPE LITE, COMPUSCOPE 220, COMPUSCOPE 250, COMPUSCOPE 1012, COMPUSCOPE 6012 AND MULTI-CARD are registered trademarks of Gage Applied Sciences Inc. MS-DOS, Microsoft Windows, Quick Basic, Visual Basic and Visual C++ are trademarks of Microsoft Incorporated. -

BORLAND Bar/Ana C++ Version 2.0
2.0 BORLAND Bar/ana C++ Version 2.0 Getting Started BORLAND INTERNATIONAL, INC. 1800 GREEN HILLS ROAD P.O. BOX 660001, SCOTTS VALLEY, CA 95067-0001 Copyright © 1991 by Borland International. All rights reserved. All Borland products are trademarks or registered trademarks of Borland International, Inc. Other brand and product names are trademarks or registered trademarks of their respective holders. Windows, as used in this manual, refers to Microsoft's implementation of a windows system. PRINTED IN THE USA. Rl 10987654 c o N T E N T s Introduction 1 Built-in assembly language What's in Borland c++ . .. 1 programming ..................... 22 Hardware and software requirements ... 3 VROOMM (overlays) . .. 23 Writing for Windows . .. 3 Borland's Programmer's Platform The Borland c++ implementation ....... 3 (IDE) ............................. 23 The Borland c++ package .............. 4 Using the manuals ................... 23 Getting Started ...................... 4 Programmers learning C or C++ ..... 24 The User's Guide . .. 5 Experienced C and C++ programmers . 24 The Programmer's Guide .............. 5 Chapter 3 For Microsoft C users 25 The Library Reference . .. 6 Environment and tools ............... 25 The Whitewater Resource Toolkit . ....... 7 The IDE and Windows ............. 26 Typefaces and icons used in these books . 7 Paths for.h and .LIB files ............ 26 How to contact Borland . .. 8 MAKE ............................ 28 Chapter 1 Installing Borland C++ 11 Command-line compiler ............ 32 Using INSTALL ..................... 12 Compatibility command-line options and Laptop systems .................... 13 libraries .......................... 37 The README file . .. 13 Linker ............................ 37 The HELPME!.DOC file ............... 14 Source-level compatibility ............. 39 Turbo Calc . .. 14 __MSC ........................... 39 Customizing the IDE ................. 14 Header files ....................... 39 Running BCINST .................