Measuring Memory Is Harder Than You Think: How to Avoid Problematic Measurement Practices in Memory Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Calculation of Signal Detection Theory Measures
Behavior Research Methods, Instruments, & Computers 1999, 31 (1), 137-149 Calculation of signal detection theory measures HAROLD STANISLAW California State University, Stanislaus, Turlock, California and NATASHA TODOROV Macquarie University, Sydney, New South Wales, Australia Signal detection theory (SDT) may be applied to any area of psychology in which two different types of stimuli must be discriminated. We describe several of these areas and the advantages that can be re- alized through the application of SDT. Three of the most popular tasks used to study discriminability are then discussed, together with the measures that SDT prescribes for quantifying performance in these tasks. Mathematical formulae for the measures are presented, as are methods for calculating the measures with lookup tables, computer software specifically developed for SDT applications, and gen- eral purpose computer software (including spreadsheets and statistical analysis software). Signal detection theory (SDT) is widely accepted by OVERVIEW OF SIGNAL psychologists; the Social Sciences Citation Index cites DETECTION THEORY over 2,000 references to an influential book by Green and Swets (1966) that describes SDT and its application to Proper application of SDT requires an understanding of psychology. Even so, fewer than half of the studies to which the theory and the measures it prescribes. We present an SDT is applicable actually make use of the theory (Stanislaw overview of SDT here; for more extensive discussions, see & Todorov, 1992). One possible reason for this apparent Green and Swets (1966) or Macmillan and Creelman underutilization of SDT is that relevant textbooks rarely (1991). Readers who are already familiar with SDT may describe the methods needed to implement the theory. -

A Signal Detection Theory Analysis of Several Psychophysical Procedures Used in Lateralization Tasks
Loyola University Chicago Loyola eCommons Master's Theses Theses and Dissertations 1984 A Signal Detection Theory Analysis of Several Psychophysical Procedures Used in Lateralization Tasks Joseph N. Baumann Loyola University Chicago Follow this and additional works at: https://ecommons.luc.edu/luc_theses Part of the Psychology Commons Recommended Citation Baumann, Joseph N., "A Signal Detection Theory Analysis of Several Psychophysical Procedures Used in Lateralization Tasks" (1984). Master's Theses. 3330. https://ecommons.luc.edu/luc_theses/3330 This Thesis is brought to you for free and open access by the Theses and Dissertations at Loyola eCommons. It has been accepted for inclusion in Master's Theses by an authorized administrator of Loyola eCommons. For more information, please contact [email protected]. This work is licensed under a Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 License. Copyright © 1984 Joseph N. Baumann A SIGNAL DETECTION THEORY ANALYSIS OF SEVERAL PSYCHOPHYSICAL PROCEDURES USED IN LATERALIZATION TASKS by Joseph N. Baumann A Thesis Submitted to the Faculty of the Department of Psychology of Loyola University of Chicago in Fulfillment of the Master's Thesis Requirement in Psychology December 1983 ACKNOWLEDGMENTS The following thesis is the product of much collaboration, and I would like to express my gratitude, and acknowledge those people who greatly contributed to its completion. First, I would like to thank my committee, Richard R. Fay, Ph.D., and Raymond H. Dye, Jr., Ph.D., for their continued help and suggestions, both in data collection and analysis. I have learned greatly from the experience. I would also like to thank William A. -

The Cognitive Revolution: a Historical Perspective
Review TRENDS in Cognitive Sciences Vol.7 No.3 March 2003 141 The cognitive revolution: a historical perspective George A. Miller Department of Psychology, Princeton University, 1-S-5 Green Hall, Princeton, NJ 08544, USA Cognitive science is a child of the 1950s, the product of the time I went to graduate school at Harvard in the early a time when psychology, anthropology and linguistics 1940s the transformation was complete. I was educated to were redefining themselves and computer science and study behavior and I learned to translate my ideas into the neuroscience as disciplines were coming into existence. new jargon of behaviorism. As I was most interested in Psychology could not participate in the cognitive speech and hearing, the translation sometimes became revolution until it had freed itself from behaviorism, tricky. But one’s reputation as a scientist could depend on thus restoring cognition to scientific respectability. By how well the trick was played. then, it was becoming clear in several disciplines that In 1951, I published Language and Communication [1], the solution to some of their problems depended cru- a book that grew out of four years of teaching a course at cially on solving problems traditionally allocated to Harvard entitled ‘The Psychology of Language’. In the other disciplines. Collaboration was called for: this is a preface, I wrote: ‘The bias is behavioristic – not fanatically personal account of how it came about. behavioristic, but certainly tainted by a preference. There does not seem to be a more scientific kind of bias, or, if there is, it turns out to be behaviorism after all.’ As I read that Anybody can make history. -

An Application of Signal Detection Theory (SDT)
An Application of Signal Detection Theory for Understanding Driver Behavior at Highway-Rail Grade Crossings Michelle Yeh and Jordan Multer Thomas Raslear United States Department of Transportation Federal Railroad Administration Volpe National Transportation Systems Center Washington, DC Cambridge, MA We used signal detection theory to examine if grade crossing warning devices were effective because they increased drivers’ sensitivity to a train’s approach or because they encouraged drivers to stop. We estimated d' and β for eight warning devices using 2006 data from the Federal Railroad Administration’s Highway-Rail Grade Crossing Accident/Incident database and Highway-Rail Crossing Inventory. We also calculated a measure of warning device effectiveness by comparing the maximum likelihood of an accident at a grade crossing with its observed probability. The 2006 results were compared to an earlier analysis of 1986 data. The collective findings indicate that grade crossing warning devices are effective because they encourage drivers to stop. Warning device effectiveness improved over the years, as drivers behaved more conservatively. Sensitivity also increased. The current model is descriptive, but it provides a framework for understanding driver decision-making at grade crossings and for examining the impact of proposed countermeasures. INTRODUCTION State of the World The Federal Railroad Administration (FRA) needs a Train is close Train is not close better understanding of driver decision-making at highway-rail grade crossings. Grade crossing safety has improved; from Valid Stop False Stop 1994 through 2003, the number of grade crossing accidents Yes (Stop) (driver stops at (driver stops decreased by 41 percent and the number of fatalities fell by 48 crossing) unnecessarily) percent. -
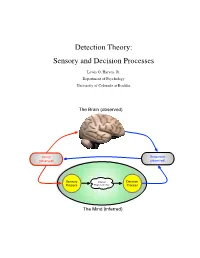
Detection Theory: Sensory and Decision Processes
Detection Theory: Sensory and Decision Processes Lewis O. Harvey, Jr. Department of Psychology University of Colorado at Boulder The Brain (observed) Stimuli Responses (observed) (observed) Sensory Internal Decision Process Representation Process The Mind (inferred) Psychology of Perception Lewis O. Harvey, Jr.–Instructor Psychology 4165-100 Steven M. Parker–Assistant Spring 2014 11:00–11:50 MWF This page blank 2/17 23.Jan.2014 Psychology of Perception Lewis O. Harvey, Jr.–Instructor Psychology 4165-100 Steven M. Parker–Assistant Spring 2014 11:00–11:50 MWF Sensory and Decision Processes A. Introduction All models of detection and discrimination have at least two psychological components or processes: the sensory process (which transforms physical stimulation into internal sensations) and a decision process (which decides on responses based on the output of the sensory process (Krantz, 1969) as illustrated in Figure 1. Stimuli Responses (observed) (observed) Sensory Internal Decision Process Representation Process The Mind (inferred) Figure 1: Detection based on two internal processes: sensory and decision. One goal of classical psychophysical methods was the determination of a stimulus threshold. Types of thresholds include detection, discrimination, recognition, and identification. What is a threshold? The concept of threshold actually has two meanings: One empirical and one theoretical. Empirically speaking, a threshold is the stimulus level needed to allow the observer to perform a task (detection, discrimination, recognition, or identification) at some criterion level of performance (75% or 84% correct, for example). Theoretically speaking, a threshold is property of the detection model’s sensory process. High Threshold Model: The classical concept of a detection threshold, as represented in the high threshold model (HTM) of detection, is a stimulus level below which the stimulus has no effect (as if the stimulus were not there) and above which the stimulus causes the sensory process to generate an output. -

Psychophysics & a Brief Intro to the Nervous System
Psychophysics & a brief intro to the nervous system Jonathan Pillow Perception (PSY 345 / NEU 325) Princeton University, Fall 2017 Lec. 3 Outline for today: • psychophysics • Weber-Fechner Law • Signal Detection Theory • basic neuroscience overview The Dawn of Psychophysics Gustav Fechner (1801–1887) often considered founder of experimental psychology psychophysics mind matter • scientific theory of the relationship between mind and matter Fechner’s law The Dawn of Psychophysics Ernst Weber (1795–1878) “Weber’s Law” • law about how stimulus intensity relates to detectability of stimulus changes • As stimulus intensity increases, magnitude of change must increase proportionately to remain noticeable Example: 1 pound change in a 20 pound weight = .05 is just as detectable as 0.2 pound change in a 4 pound weight = .05 The Dawn of Psychophysics Ernst Weber (1795–1878) Weber Fraction • ratio of change magnitude to stimulus magnitude that is required for detecting the change change in stimulus stimulus intensity = .05 Q: what’s the smallest change in a 100 pound weight could you detect? = .05 The Dawn of Psychophysics Ernst Weber (1795–1878) Weber Fraction • ratio of change magnitude to stimulus magnitude that is required for detecting the change Just-Noticeable Difference (JND) • smallest magnitude change that can be detected = .05 Q: what’s the smallest change in a 100 pound weight could you detect? = .05 Look at Fechner’s law again: A little math (don’t freak out) Fechner’s law: percept stimulus differentiate both sides intensity intensity change in Weber’s law: stimulus intensity change in percept intensity So detectability (“how much the percept changes”) is determined by the ratio of stimulus change dR to stimulus intensity R. -

Pre Test Excerpt
Using Signal Detection Theory to Investigate the Role of Visual Information in Performance Monitoring in Typing Svetlana Pinet ([email protected]) Basque Center on Cognition, Brain and Language Paseo Mikeletegi 69, 2nd Floor, 20009 Donostia-San Sebastian, Spain Nazbanou Nozari ([email protected]) Department of Psychology, Carnegie Mellon University, 5000 Forbes Ave. Pittsburgh, PA 15213 USA Abstract alternative mechanisms that monitor performance internally (internal-channel monitoring; e.g., Hickok, 2012; Nozari et This paper uses the signal detection theory (SDT) to investigate the contribution of visual information to two al., 2011). The question remains: How is labor divided monitoring-dependent functions, metacognitive awareness of between these two monitoring channels? This study uses errors and error corrections. Data from two experiments signal detection theory (SDT) to answer this question. show that complete removal of visual outcome results in a mild decrease in error awareness and a much more significant Language production monitoring as SDT decrease in correction rates. Partially restoring visual information by including positional information (as in masked The challenge of answering questions about the password typing) causes a modest but statistically significant contribution of external vs. internal monitoring channels to improvement in correction performance. Interestingly, monitoring stems from the fact that models of external and participants treat the change to the quality of information internal monitoring often propose very different differently across the tasks, with more conservative behavior mechanisms. To quantify performance across such models, (avoiding false alarms) in the correction task. These findings a common currency is needed. A suitable candidate for such show the SDT’s ability to quantify, in a graded manner, the contribution of specific types of information to monitoring in currency is the notion of conflict (Botvinick et al., 2001). -

Signal Detection Theory
Signal Detection Theory Professor David Heeger November 12, 1997 The starting point for signal detection theory is that nearly all decision making takes place in the presence of some uncertainty. Signal detection theory provides a precise lan- guage and graphic notation for analyzing decision making in the presence of uncertainty. Simple Forced Choice I begin here with the classic example of detecting brief, dim flashes of light in a dark room. Imagine that we use a simple forced-choice method in which the light is flashed on half of the trials (randomly interleaved). On each trial, the subject must respond ”yes” or ”no” to indicate whether or not they think the light was flased. We assume that the subjects’ performance is determined by the number of photon absorptions/photopigment isomerizations on each trial. There are two kinds of noise factors that limit the subject’s performance: internal noise and external noise. External noise. There are many possible sources of external noise. The main source of external noise to consider here is the quantal nature of light. On average, the light source is set up to deliver a certain stimulus intensity, say 100 photons. A given trial, however, there will rarely be exactly 100 photons emitted. Instead, the photon count will vary from trial to trial following a Poisson distribution. Internal noise. Internal noise refers to the fact that neural responses would be noisy, even if the stimulus was exactly the same on each trial. Some of the emitted photons will be scattered by the cornea, the lens, and the other goopy stuff in the eye. -

Sensitivity and Bias - an Introduction to Signal Detection Theory
University of Birmingham School of Psychology Postgraduate research methods course - Mark Georgeson Sensitivity and Bias - an introduction to Signal Detection Theory Aim To give a brief introduction to the central concepts of Signal Detection Theory and its application in areas of Psychophysics and Psychology that involve detection, identification, recognition and classification tasks. The common theme is that we are analyzing decision-making under conditions of uncertainty and bias, and we aim to determine how much information the decision maker is getting. Objectives After this session & further reading you should: • be acquainted with the generality and power of SDT as a framework for analyzing human performance • grasp the distinction between sensitivity and bias, and be more aware of the danger of confusing them • be able to distinguish between single-interval and forced-choice methods in human performance tasks • be able to calculate sensitivity d’ and criterion C from raw data Key references N A Macmillan & C D Creelman (1991) "Detection Theory: A User's guide" Cambridge University Press (out of print, alas) Green DM, Swets JA (1974) Signal Detection Theory & Psychophysics (2nd ed.) NY: Krieger Illustrative papers Azzopardi P, Cowey A (1998) Blindsight and visual awarenss. Consciousness & Cognition 7, 292- 311. McFall RM, Treat TA (1999) Quantifying the information value of clinical assessments with signal detection theory. Ann. Rev. Psychol. 50, 215-241. [ free from http://www.AnnualReviews.org ] Single-interval and forced-choice -

Signal Detection Theory (SDT)
Signal Detection Theory (SDT) Hervé Abdi1 1 Overview Signal Detection Theory (often abridged as SDT) is used to analyze data coming from experiments where the task is to categorize am- biguous stimuli which can be generated either by a known process (called the signal) or be obtained by chance (called the noise in the SDT framework). For example a radar operator must decide if what she sees on the radar screen indicates the presence of a plane (the signal) or the presence of parasites (the noise). This type of appli- cations was the original framework of SDT (see the founding work of Green & Swets, 1966) But the notion of signal and noise can be somewhat metaphorical is some experimental contexts. For example, in a memory recognition experiment, participants have to decide if the stimulus they currently see was presented before. Here the signal corresponds to a familiarity feeling generated by a memorized stimulus whereas the noise corresponds to a familiar- ity feeling generated by a new stimulus. The goal of detection theory is to estimate two main parame- ters from the experimental data. The first parameter, called d ′, in- dicates the strength of the signal (relative to the noise). The second parameter called C (a variant of it is called β), reflects the strategy 1In: Neil Salkind (Ed.) (2007). Encyclopedia of Measurement and Statistics. Thousand Oaks (CA): Sage. Address correspondence to: Hervé Abdi Program in Cognition and Neurosciences, MS: Gr.4.1, The University of Texas at Dallas, Richardson, TX 75083–0688, USA E-mail: [email protected] http://www.utd.edu/ herve ∼ 1 Hervé Abdi: Signal Detection Theory Table 1: The four possible types of response in sdt DECISION: (PARTICIPANT’S RESPONSE) REALITY Yes No Signal Present Hit Miss Signal Absent False Alarm (FA) Correct Rejection of response of the participant (e.g., saying easily yes rather than no). -

Affective Bias Through the Lens of Signal Detection Theory Abstract
Affective bias through the lens of Signal Detection Theory Shannon M. Locke1 & Oliver J. Robinson2,3* 1 Laboratoire des Syst`emesPerceptifs, D´epartement d'Etudes´ Cognitives, Ecole´ Normale Sup´erieure,PSL University, CNRS, 75005 Paris, France 2 Institute of Cognitive Neuroscience, University College London, London, UK 3 Research Department of Clinical, Educational and Health Psychology, University College London, London, UK *Corresponding author: [email protected] Abstract 1 Affective bias - a propensity to focus on negative information at the expense of positive in- 2 formation - is a core feature of many mental health problems. However, it can be caused by 3 wide range of possible underlying cognitive mechanisms. Here we illustrate this by focusing on 4 one particular behavioural signature of affective bias - increased tendency of anxious/depressed 5 individuals to predict lower rewards - in the context of the Signal Detection Theory (SDT) 6 modelling framework. Specifically, we apply this framework to a tone-discrimination task (Ayl- 7 ward et al., 2019a), and argue that the same behavioural signature (differential placement of 8 the 'decision criterion' between healthy controls and individuals with mood/anxiety disorders) 9 might be driven by multiple SDT processes. Building on this theoretical foundation, we propose 10 five experiments to test five hypothetical sources of this affective bias: beliefs about prior proba- 11 bilities, beliefs about performance, subjective value of reward, learning differences, and need for 12 accuracy differences. We argue that greater precision about the mechanisms driving affective 13 bias may eventually enable us to better understand and treat mood and anxiety disorders. 14 Author Summary 15 We apply the Signal Detection Theory framework to understanding the mechanisms behind 16 affective bias in individuals with mood and anxiety disorders. -

Targeting Separate Specific Learning Parameters Underlying Cognitive
Journal of Behavior Therapy and Experimental Psychiatry 65 (2019) 101498 Contents lists available at ScienceDirect Journal of Behavior Therapy and Experimental Psychiatry journal homepage: www.elsevier.com/locate/jbtep Targeting separate specific learning parameters underlying cognitive behavioral therapy can improve perceptual judgments of anger T Spencer K. Lynna,1, Eric Buib,c, Susanne S. Hoeppnerb,c, Emily B. O'Dayc,2, Sophie A. Palitzc,2, ∗ Lisa F. Barretta,d,e, Naomi M. Simonf,c, a Department of Psychology, Northeastern University, 360 Huntington Ave, Boston, MA, USA, 02115 b Harvard Medical School, 25 Shattuck St., Boston, MA 02115, Boston, MA, USA, 02114 c Center for Anxiety and Traumatic Stress Disorders, Massachusetts General Hospital, 1 Bowdoin St., Boston, MA, 02114, USA d Psychiatric Neuroimaging Division, Department of Psychiatry, Massachusetts General Hospital and Harvard Medical School, USA e Athinoula A. Martinos Center for Biomedical Imaging, Massachusetts General Hospital, USA f New York University School of Medicine, One Park Avenue 8th Floor, New York, NY, 10016, USA ARTICLE INFO ABSTRACT Keywords: Background and objectives: Anxiety disorders are characterized by biased perceptual judgment. An experimental Social anxiety disorder model using simple verbal instruction to target specific decision parameters that influence perceptual judgment Generalized anxiety disorder was developed to test if it could influence anger perception, and to examine differences between individuals with Emotion perception social anxiety disorder (SAD) relative to generalized anxiety disorder (GAD) or non-psychiatric controls. Decision making Methods: Anger perception was decomposed into three decision parameters (perceptual similarity of angry vs. Signal detection theory not-angry facial expressions, base rate of encountering angry vs.