Mobile Ray-Tracing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Efficient Rendering of Caustics with Streamed Photon Mapping
BULLETIN OF THE POLISH ACADEMY OF SCIENCES TECHNICAL SCIENCES, Vol. 65, No. 3, 2017 DOI: 10.1515/bpasts-2017-0040 Efficient rendering of caustics with streamed photon mapping K. GUZEK and P. NAPIERALSKI* Institute of Information Technology, Lodz University of Technology, 215 Wolczanska St., 90-924 Lodz, Poland Abstract. In this paper, we present the streamed photon mapping method for enhancing the rendering of caustics. In order to achieve a realistic caustic effect, global illumination methods require additional data, which are gathered by creating a caustic map or increasing the number of samples used for rendering. Our method employs a stream of photons with a varying luminance level depending on the material properties of the surface. The application of a concentrated photon stream provides the ability to render caustics effectively without increasing the number of photons in a photon map. Such an approach increases visibility of results, while also allowing for faster computations. Key words: rendering, global illumination, photon mapping, caustics. 1. Introduction 2. Rendering caustics The interaction of light with matter in the real world results The first attempt to simulate a natural caustic effect was the in a variety of optical phenomena. Understanding how those path tracing method, introduced by James Kajiya in 1986 [4]. phenomena occur and where to implement them is crucial for However, the method proved to be highly inefficient. The creating realistic image renders. When observing the reflection caustics were poorly rendered, as the light source was obscure. or refraction of light through curved surfaces, one may notice A significant improvement was introduced both and inde- some characteristic patches of light, referred to as caustics. -

An Advanced Path Tracing Architecture for Movie Rendering
RenderMan: An Advanced Path Tracing Architecture for Movie Rendering PER CHRISTENSEN, JULIAN FONG, JONATHAN SHADE, WAYNE WOOTEN, BRENDEN SCHUBERT, ANDREW KENSLER, STEPHEN FRIEDMAN, CHARLIE KILPATRICK, CLIFF RAMSHAW, MARC BAN- NISTER, BRENTON RAYNER, JONATHAN BROUILLAT, and MAX LIANI, Pixar Animation Studios Fig. 1. Path-traced images rendered with RenderMan: Dory and Hank from Finding Dory (© 2016 Disney•Pixar). McQueen’s crash in Cars 3 (© 2017 Disney•Pixar). Shere Khan from Disney’s The Jungle Book (© 2016 Disney). A destroyer and the Death Star from Lucasfilm’s Rogue One: A Star Wars Story (© & ™ 2016 Lucasfilm Ltd. All rights reserved. Used under authorization.) Pixar’s RenderMan renderer is used to render all of Pixar’s films, and by many 1 INTRODUCTION film studios to render visual effects for live-action movies. RenderMan started Pixar’s movies and short films are all rendered with RenderMan. as a scanline renderer based on the Reyes algorithm, and was extended over The first computer-generated (CG) animated feature film, Toy Story, the years with ray tracing and several global illumination algorithms. was rendered with an early version of RenderMan in 1995. The most This paper describes the modern version of RenderMan, a new architec- ture for an extensible and programmable path tracer with many features recent Pixar movies – Finding Dory, Cars 3, and Coco – were rendered that are essential to handle the fiercely complex scenes in movie production. using RenderMan’s modern path tracing architecture. The two left Users can write their own materials using a bxdf interface, and their own images in Figure 1 show high-quality rendering of two challenging light transport algorithms using an integrator interface – or they can use the CG movie scenes with many bounces of specular reflections and materials and light transport algorithms provided with RenderMan. -

Sony Pictures Imageworks Arnold
Sony Pictures Imageworks Arnold CHRISTOPHER KULLA, Sony Pictures Imageworks ALEJANDRO CONTY, Sony Pictures Imageworks CLIFFORD STEIN, Sony Pictures Imageworks LARRY GRITZ, Sony Pictures Imageworks Fig. 1. Sony Imageworks has been using path tracing in production for over a decade: (a) Monster House (©2006 Columbia Pictures Industries, Inc. All rights reserved); (b) Men in Black III (©2012 Columbia Pictures Industries, Inc. All Rights Reserved.) (c) Smurfs: The Lost Village (©2017 Columbia Pictures Industries, Inc. and Sony Pictures Animation Inc. All rights reserved.) Sony Imageworks’ implementation of the Arnold renderer is a fork of the and robustness of path tracing indicated to the studio there was commercial product of the same name, which has evolved independently potential to revisit the basic architecture of a production renderer since around 2009. This paper focuses on the design choices that are unique which had not evolved much since the seminal Reyes paper [Cook to this version and have tailored the renderer to the specic requirements of et al. 1987]. lm rendering at our studio. We detail our approach to subdivision surface After an initial period of co-development with Solid Angle, we tessellation, hair rendering, sampling and variance reduction techniques, decided to pursue the evolution of the Arnold renderer indepen- as well as a description of our open source texturing and shading language components. We also discuss some ideas we once implemented but have dently from the commercially available product. This motivation since discarded to highlight the evolution of the software over the years. is twofold. The rst is simply pragmatic: software development in service of lm production must be responsive to tight deadlines CCS Concepts: • Computing methodologies → Ray tracing; (less the lm release date than internal deadlines determined by General Terms: Graphics, Systems, Rendering the production schedule). -

Production Global Illumination
CIS 497 Senior Capstone Design Project Project Proposal Specification Instructors: Norman I. Badler and Aline Normoyle Production Global Illumination Yining Karl Li Advisor: Norman Badler and Aline Normoyle University of Pennsylvania ABSTRACT For my project, I propose building a production quality global illumination renderer supporting a variety of com- plex features. Such features may include some or all of the following: texturing, subsurface scattering, displacement mapping, deformational motion blur, memory instancing, diffraction, atmospheric scattering, sun&sky, and more. In order to build this renderer, I propose beginning with my existing massively parallel CUDA-based pathtracing core and then exploring methods to accelerate pathtracing, such as GPU-based stackless KD-tree construction, and multiple importance sampling. I also propose investigating and possible implementing alternate GI algorithms that can build on top of pathtracing, such as progressive photon mapping and multiresolution radiosity caching. The final goal of this project is to finish with a renderer capable of rendering out highly complex scenes and anima- tions from programs such as Maya, with high quality global illumination, in a timespan measuring in minutes ra- ther than hours. Project Blog: http://yiningkarlli.blogspot.com While competing with powerhouse commercial renderers 1. INTRODUCTION like Arnold, Renderman, and Vray is beyond the scope of this project, hopefully the end result will still be feature- Global illumination, or GI, is one of the oldest rendering rich and fast enough for use as a production academic ren- problems in computer graphics. In the past two decades, a derer suitable for usecases similar to those of Cornell's variety of both biased and unbaised solutions to the GI Mitsuba render, or PBRT. -

Integrating Open Source Distributed Rendering Solutions in Public and Closed Networking Envi- Ronments
Integrating open source distributed rendering solutions in public and closed networking envi- ronments Seppälä, Heikki & Suomalainen, Niko 2010 Leppävaara Laurea University of Applied Sciences Laurea Leppävaara Integrating open source distributed rendering solutions in public and closed networking environments Heikki Seppälä Niko Suomalainen Information Technology Programme Thesis 02/2010 Laurea-ammattikorkeakoulu Tiivistelmä Laurea Leppävaara Tietojenkäsittelyn koulutusohjelma Yritysten tietoverkot Heikki Seppälä & Niko Suomalainen Avoimen lähdekoodin jaetun renderöinnin ratkaisut julkisiin ja suljettuihin ympäristöihin Vuosi 2010 Sivumäärä 64 Moderni tutkimustiede on yhä enemmän riippuvainen tietokoneista ja niiden tuottamasta laskentatehosta. Tutkimusprojektit kasvavat jatkuvasti, mikä aiheuttaa tarpeen suuremmalle tietokoneteholle ja lisää kustannuksia. Ratkaisuksi tähän ongelmaan tiedemiehet ovat kehittäneet hajautetun laskennan järjestelmiä, joiden tarkoituksena on tarjota vaihtoehto kalliille supertietokoneille. Näiden järjestelmien toiminta perustuu yhteisön lahjoittamaan tietokonetehoon. Open Rendering Environment on Laurea-ammattikorkeakoulun aloittama projekti, jonka tärkein tuotos on yhteisöllinen renderöintipalvelu Renderfarm.fi. Palvelu hyödyntää hajautettua laskentaa nopeuttamaan 3D-animaatioiden renderöintiä. Tämä tarjoaa uusia mahdollisuuksia mallintajille ja animaatioelokuvien tekijöille joilta tavallisesti kuluu paljon aikaa ja tietokoneresursseja töidensä valmiiksi saattamiseksi. Renderfarm.fi-palvelu perustuu BOINC-pohjaiseen -

Openscenegraph 3.0 Beginner's Guide
OpenSceneGraph 3.0 Beginner's Guide Create high-performance virtual reality applications with OpenSceneGraph, one of the best 3D graphics engines Rui Wang Xuelei Qian BIRMINGHAM - MUMBAI OpenSceneGraph 3.0 Beginner's Guide Copyright © 2010 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the authors, nor Packt Publishing and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: December 2010 Production Reference: 1081210 Published by Packt Publishing Ltd. 32 Lincoln Road Olton Birmingham, B27 6PA, UK. ISBN 978-1-849512-82-4 www.packtpub.com Cover Image by Ed Maclean ([email protected]) Credits Authors Editorial Team Leader Rui Wang Akshara Aware Xuelei Qian Project Team Leader Reviewers Lata Basantani Jean-Sébastien Guay Project Coordinator Cedric Pinson -

On Dean W. Arnold's Writing . . . UNKNOWN EMPIRE Th E True Story of Mysterious Ethiopia and the Future Ark of Civilization “
On Dean W. Arnold’s writing . UNKNOWN EMPIRE T e True Story of Mysterious Ethiopia and the Future Ark of Civilization “I read it in three nights . .” “T is is an unusual and captivating book dealing with three major aspects of Ethiopian history and the country’s ancient religion. Dean W. Arnold’s scholarly and most enjoyable book sets about the task with great vigour. T e elegant lightness of the writing makes the reader want to know more about the country that is also known as ‘the cradle of humanity.’ T is is an oeuvre that will enrich our under- standing of one of Africa’s most formidable civilisations.” —Prince Asfa-Wossen Asserate, PhD Magdalene College, Cambridge, and Univ. of Frankfurt Great Nephew of Emperor Haile Selassie Imperial House of Ethiopia OLD MONEY, NEW SOUTH T e Spirit of Chattanooga “. chronicles the fascinating and little-known history of a unique place and tells the story of many of the great families that have shaped it. It was a story well worth telling, and one well worth reading.” —Jon Meacham, Editor, Newsweek Author, Pulitzer Prize winner . THE CHEROKEE PRINCES Mixed Marriages and Murders — Te True Unknown Story Behind the Trail of Tears “A page-turner.” —Gordon Wetmore, Chairman Portrait Society of America “Dean Arnold has a unique way of capturing the essence of an issue and communicating it through his clear but compelling style of writing.” —Bob Corker, United States Senator, 2006-2018 Former Chairman, Senate Foreign Relations Committee THE WIZARD AND THE LION (Screenplay on the friendship between J. -

2014 3-4 Acta Graphica.Indd
Vidmar et al.: Performance Assessment of Three Rendering..., acta graphica 25(2014)3–4, 101–114 author viewpoint acta graphica 234 Performance Assessment of Three Rendering Engines in 3D Computer Graphics Software Authors Žan Vidmar, Aleš Hladnik, Helena Gabrijelčič Tomc* University of Ljubljana Faculty of Natural Sciences and Engineering Slovenia *E-mail: [email protected] Abstract: The aim of the research was the determination of testing conditions and visual and numerical evaluation of renderings made with three different rendering engines in Maya software, which is widely used for educational and computer art purposes. In the theoretical part the overview of light phenomena and their simulation in virtual space is presented. This is followed by a detailed presentation of the main rendering methods and the results and limitations of their applications to 3D ob- jects. At the end of the theoretical part the importance of a proper testing scene and especially the role of Cornell box are explained. In the experimental part the terms and conditions as well as hardware and software used for the research are presented. This is followed by a description of the procedures, where we focused on the rendering quality and time, which enabled the comparison of settings of different render engines and determination of conditions for further rendering of testing scenes. The experimental part continued with rendering a variety of simple virtual scenes including Cornell box and virtual object with different materials and colours. Apart from visual evaluation, which was the starting point for comparison of renderings, a procedure for numerical estimation and colour deviations of ren- derings using the selected regions of interest in the final images is presented. -

Nvidia Rtx™ Server for Bare Metal Rendering with Autodesk Arnold 5.3.0.0 on @Xi 4029Gp- Trt2 Design Guide
NVIDIA RTX™ SERVER FOR BARE METAL RENDERING WITH AUTODESK ARNOLD 5.3.0.0 ON @XI 4029GP- TRT2 DESIGN GUIDE VERSION: 1.0 TABLE OF CONTENTS Chapter 1. SOLUTION OVERVIEW ....................................................................... 1 1.1 NVIDIA RTX Server Overview ........................................................................... 1 Chapter 2. SOLUTION DETAILS .......................................................................... 2 2.1 Solution Configuration .................................................................................. 3 | ii Chapter 1. SOLUTION OVERVIEW Designed and tested through multi-vendor cooperation between NVIDIA and its system and ISV partners, NVIDIA RTX™ Server provides a trusted environment for artists and designers to create professional, photorealistic images for the Media & Entertainment; Architecture, Engineering & Construction; and Manufacturing & Design industries. 1.1 NVIDIA RTX SERVER OVERVIEW Introduction: Content production is undergoing a massive surge as render complexity and quality increases. Designers and artists across industries continually strive to produce more visually rich content faster than ever before, yet find their creativity and productivity bound by inefficient CPU- based render solutions. NVIDIA RTX Server is a validated solution that brings GPU-accelerated power and performance to deliver the most efficient end-to-end rendering solution, from interactive sessions in the desktop to final batch rendering in the data center. Audience: The audience for this document -

DVD-Ofimática 2014-07
(continuación 2) Calizo 0.2.5 - CamStudio 2.7.316 - CamStudio Codec 1.5 - CDex 1.70 - CDisplayEx 1.9.09 - cdrTools FrontEnd 1.5.2 - Classic Shell 3.6.8 - Clavier+ 10.6.7 - Clementine 1.2.1 - Cobian Backup 8.4.0.202 - Comical 0.8 - ComiX 0.2.1.24 - CoolReader 3.0.56.42 - CubicExplorer 0.95.1 - Daphne 2.03 - Data Crow 3.12.5 - DejaVu Fonts 2.34 - DeltaCopy 1.4 - DVD-Ofimática Deluge 1.3.6 - DeSmuME 0.9.10 - Dia 0.97.2.2 - Diashapes 0.2.2 - digiKam 4.1.0 - Disk Imager 1.4 - DiskCryptor 1.1.836 - Ditto 3.19.24.0 - DjVuLibre 3.5.25.4 - DocFetcher 1.1.11 - DoISO 2.0.0.6 - DOSBox 0.74 - DosZip Commander 3.21 - Double Commander 0.5.10 beta - DrawPile 2014-07 0.9.1 - DVD Flick 1.3.0.7 - DVDStyler 2.7.2 - Eagle Mode 0.85.0 - EasyTAG 2.2.3 - Ekiga 4.0.1 2013.08.20 - Electric Sheep 2.7.b35 - eLibrary 2.5.13 - emesene 2.12.9 2012.09.13 - eMule 0.50.a - Eraser 6.0.10 - eSpeak 1.48.04 - Eudora OSE 1.0 - eViacam 1.7.2 - Exodus 0.10.0.0 - Explore2fs 1.08 beta9 - Ext2Fsd 0.52 - FBReader 0.12.10 - ffDiaporama 2.1 - FileBot 4.1 - FileVerifier++ 0.6.3 DVD-Ofimática es una recopilación de programas libres para Windows - FileZilla 3.8.1 - Firefox 30.0 - FLAC 1.2.1.b - FocusWriter 1.5.1 - Folder Size 2.6 - fre:ac 1.0.21.a dirigidos a la ofimática en general (ofimática, sonido, gráficos y vídeo, - Free Download Manager 3.9.4.1472 - Free Manga Downloader 0.8.2.325 - Free1x2 0.70.2 - Internet y utilidades). -

12.Raytracing.Pdf
Základní raytracing Detaily implementace Distribuovaný raytracing Další globální zobrazovací metody Galerie Literatura Raytracing a další globální zobrazovací metody Pavel Strachota FJFI CVUTˇ v Praze 11. kvetnaˇ 2015 Základní raytracing Detaily implementace Distribuovaný raytracing Další globální zobrazovací metody Galerie Literatura Obsah 1 Základní raytracing 2 Detaily implementace 3 Distribuovaný raytracing 4 Další globální zobrazovací metody 5 Galerie Základní raytracing Detaily implementace Distribuovaný raytracing Další globální zobrazovací metody Galerie Literatura Obsah 1 Základní raytracing 2 Detaily implementace 3 Distribuovaný raytracing 4 Další globální zobrazovací metody 5 Galerie Základní raytracing Detaily implementace Distribuovaný raytracing Další globální zobrazovací metody Galerie Literatura Motivace obsah prednáškyˇ až dosud: kroky vedoucí k prímémuˇ zobrazení jednotlivých objekt˚una pr˚umetnuˇ =) vhodné pro zobrazování v reálném caseˇ definice scény, triangulace promítání - maticová transformace rešeníˇ viditelnosti - obrazový a objektový prístup,ˇ více ciˇ méneˇ univerzální algoritmy, z-buffer, prímýˇ výpocetˇ stín ˚u osvetlováníˇ a metody stínování - aplikace osvetlovacíhoˇ modelu na polygonální sít’ mapování textur (bude potrebaˇ i pro globální metody), perspektivneˇ korektní mapování prímoˇ v pr ˚umetnˇ eˇ nyní: globální zobrazovací metody, snaha o fotorealistické zobrazování =) barvu každého pixelu ovlivnujíˇ obecneˇ všechny objekty ve scéneˇ Základní raytracing Detaily implementace Distribuovaný raytracing Další -
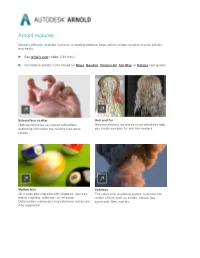
Arnold Features
Arnold features Memory-efficient, scalable raytracer rendering software helps artists render complex scenes quickly and easily. See what's new (video: 2:31 min.) Get feature details in the Arnold for Maya, Houdini, Cinema 4D, 3ds Max, or Katana user guides Subsurface scatter Hair and fur High-performance ray-traced subsurface Memory-efficient ray-traced curve primitives help scattering eliminates the need to tune point you create complex fur and hair renders. clouds. Motion blur Volumes 3D motion blur interacts with shadows, volumes, The volumetric rendering system in Arnold can indirect lighting, reflection, or refraction. render effects such as smoke, clouds, fog, Deformation motion blur and rotational motion are pyroclastic flow, and fire. also supported. Instances Subdivision and displacement Arnold can more efficiently ray trace instances of Arnold supports Catmull-Clark subdivision many scene objects with transformation and surfaces. material overrides. OSL support Light Path Expressions Arnold now features support for Open Shading LPEs give you power and flexibility to create Language (OSL), an advanced shading language Arbitrary Output Variables to help meet the needs for Global Illumination renderers. of production. NEW | Adaptive sampling NEW | Toon shader Adaptive sampling gives users another means of An advanced Toon shader is part of a non- tuning images, allowing them to reduce render photorealistic solution provided in combination times without jeopardizing final image quality. with the Contour Filter. NEW | Denoising NEW | Material assignments and overrides Two denoising solutions in Arnold offer flexibility Operators make it possible to override any part of by allowing users to use much lower-quality a scene at render time and enable support for sampling settings.