Hybrid Metaheuristics for Constrained Portfolio Selection Problems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 8 Constrained Optimization 2: Sequential Quadratic Programming, Interior Point and Generalized Reduced Gradient Methods
Chapter 8: Constrained Optimization 2 CHAPTER 8 CONSTRAINED OPTIMIZATION 2: SEQUENTIAL QUADRATIC PROGRAMMING, INTERIOR POINT AND GENERALIZED REDUCED GRADIENT METHODS 8.1 Introduction In the previous chapter we examined the necessary and sufficient conditions for a constrained optimum. We did not, however, discuss any algorithms for constrained optimization. That is the purpose of this chapter. The three algorithms we will study are three of the most common. Sequential Quadratic Programming (SQP) is a very popular algorithm because of its fast convergence properties. It is available in MATLAB and is widely used. The Interior Point (IP) algorithm has grown in popularity the past 15 years and recently became the default algorithm in MATLAB. It is particularly useful for solving large-scale problems. The Generalized Reduced Gradient method (GRG) has been shown to be effective on highly nonlinear engineering problems and is the algorithm used in Excel. SQP and IP share a common background. Both of these algorithms apply the Newton- Raphson (NR) technique for solving nonlinear equations to the KKT equations for a modified version of the problem. Thus we will begin with a review of the NR method. 8.2 The Newton-Raphson Method for Solving Nonlinear Equations Before we get to the algorithms, there is some background we need to cover first. This includes reviewing the Newton-Raphson (NR) method for solving sets of nonlinear equations. 8.2.1 One equation with One Unknown The NR method is used to find the solution to sets of nonlinear equations. For example, suppose we wish to find the solution to the equation: xe+=2 x We cannot solve for x directly. -

Quadratic Programming GIAN Short Course on Optimization: Applications, Algorithms, and Computation
Quadratic Programming GIAN Short Course on Optimization: Applications, Algorithms, and Computation Sven Leyffer Argonne National Laboratory September 12-24, 2016 Outline 1 Introduction to Quadratic Programming Applications of QP in Portfolio Selection Applications of QP in Machine Learning 2 Active-Set Method for Quadratic Programming Equality-Constrained QPs General Quadratic Programs 3 Methods for Solving EQPs Generalized Elimination for EQPs Lagrangian Methods for EQPs 2 / 36 Introduction to Quadratic Programming Quadratic Program (QP) minimize 1 xT Gx + g T x x 2 T subject to ai x = bi i 2 E T ai x ≥ bi i 2 I; where n×n G 2 R is a symmetric matrix ... can reformulate QP to have a symmetric Hessian E and I sets of equality/inequality constraints Quadratic Program (QP) Like LPs, can be solved in finite number of steps Important class of problems: Many applications, e.g. quadratic assignment problem Main computational component of SQP: Sequential Quadratic Programming for nonlinear optimization 3 / 36 Introduction to Quadratic Programming Quadratic Program (QP) minimize 1 xT Gx + g T x x 2 T subject to ai x = bi i 2 E T ai x ≥ bi i 2 I; No assumption on eigenvalues of G If G 0 positive semi-definite, then QP is convex ) can find global minimum (if it exists) If G indefinite, then QP may be globally solvable, or not: If AE full rank, then 9ZE null-space basis Convex, if \reduced Hessian" positive semi-definite: T T ZE GZE 0; where ZE AE = 0 then globally solvable ... eliminate some variables using the equations 4 / 36 Introduction to Quadratic Programming Quadratic Program (QP) minimize 1 xT Gx + g T x x 2 T subject to ai x = bi i 2 E T ai x ≥ bi i 2 I; Feasible set may be empty .. -
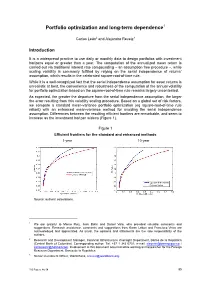
Portfolio Optimization and Long-Term Dependence1
Portfolio optimization and long-term dependence1 Carlos León2 and Alejandro Reveiz3 Introduction It is a widespread practice to use daily or monthly data to design portfolios with investment horizons equal or greater than a year. The computation of the annualized mean return is carried out via traditional interest rate compounding – an assumption free procedure –, while scaling volatility is commonly fulfilled by relying on the serial independence of returns’ assumption, which results in the celebrated square-root-of-time rule. While it is a well-recognized fact that the serial independence assumption for asset returns is unrealistic at best, the convenience and robustness of the computation of the annual volatility for portfolio optimization based on the square-root-of-time rule remains largely uncontested. As expected, the greater the departure from the serial independence assumption, the larger the error resulting from this volatility scaling procedure. Based on a global set of risk factors, we compare a standard mean-variance portfolio optimization (eg square-root-of-time rule reliant) with an enhanced mean-variance method for avoiding the serial independence assumption. Differences between the resulting efficient frontiers are remarkable, and seem to increase as the investment horizon widens (Figure 1). Figure 1 Efficient frontiers for the standard and enhanced methods 1-year 10-year Source: authors’ calculations. 1 We are grateful to Marco Ruíz, Jack Bohn and Daniel Vela, who provided valuable comments and suggestions. Research assistance, comments and suggestions from Karen Leiton and Francisco Vivas are acknowledged and appreciated. As usual, the opinions and statements are the sole responsibility of the authors. -

Gauss-Newton SQP
TEMPO Spring School: Theory and Numerics for Nonlinear Model Predictive Control Exercise 3: Gauss-Newton SQP J. Andersson M. Diehl J. Rawlings M. Zanon University of Freiburg, March 27, 2015 Gauss-Newton sequential quadratic programming (SQP) In the exercises so far, we solved the NLPs with IPOPT. IPOPT is a popular open-source primal- dual interior point code employing so-called filter line-search to ensure global convergence. Other NLP solvers that can be used from CasADi include SNOPT, WORHP and KNITRO. In the following, we will write our own simple NLP solver implementing sequential quadratic programming (SQP). (0) (0) Starting from a given initial guess for the primal and dual variables (x ; λg ), SQP solves the NLP by iteratively computing local convex quadratic approximations of the NLP at the (k) (k) current iterate (x ; λg ) and solving them by using a quadratic programming (QP) solver. For an NLP of the form: minimize f(x) x (1) subject to x ≤ x ≤ x; g ≤ g(x) ≤ g; these quadratic approximations take the form: 1 | 2 (k) (k) (k) (k) | minimize ∆x rxL(x ; λg ; λx ) ∆x + rxf(x ) ∆x ∆x 2 subject to x − x(k) ≤ ∆x ≤ x − x(k); (2) @g g − g(x(k)) ≤ (x(k)) ∆x ≤ g − g(x(k)); @x | | where L(x; λg; λx) = f(x) + λg g(x) + λx x is the so-called Lagrangian function. By solving this (k) (k+1) (k) (k+1) QP, we get the (primal) step ∆x := x − x as well as the Lagrange multipliers λg (k+1) and λx . -

Implementing Customized Pivot Rules in COIN-OR's CLP with Python
Cahier du GERAD G-2012-07 Customizing the Solution Process of COIN-OR's Linear Solvers with Python Mehdi Towhidi1;2 and Dominique Orban1;2 ? 1 Department of Mathematics and Industrial Engineering, Ecole´ Polytechnique, Montr´eal,QC, Canada. 2 GERAD, Montr´eal,QC, Canada. [email protected], [email protected] Abstract. Implementations of the Simplex method differ only in very specific aspects such as the pivot rule. Similarly, most relaxation methods for mixed-integer programming differ only in the type of cuts and the exploration of the search tree. Implementing instances of those frame- works would therefore be more efficient if linear and mixed-integer pro- gramming solvers let users customize such aspects easily. We provide a scripting mechanism to easily implement and experiment with pivot rules for the Simplex method by building upon COIN-OR's open-source linear programming package CLP. Our mechanism enables users to implement pivot rules in the Python scripting language without explicitly interact- ing with the underlying C++ layers of CLP. In the same manner, it allows users to customize the solution process while solving mixed-integer linear programs using the CBC and CGL COIN-OR packages. The Cython pro- gramming language ensures communication between Python and COIN- OR libraries and activates user-defined customizations as callbacks. For illustration, we provide an implementation of a well-known pivot rule as well as the positive edge rule|a new rule that is particularly efficient on degenerate problems, and demonstrate how to customize branch-and-cut node selection in the solution of a mixed-integer program. -

A Sequential Quadratic Programming Algorithm with an Additional Equality Constrained Phase
A Sequential Quadratic Programming Algorithm with an Additional Equality Constrained Phase Jos´eLuis Morales∗ Jorge Nocedal † Yuchen Wu† December 28, 2008 Abstract A sequential quadratic programming (SQP) method is presented that aims to over- come some of the drawbacks of contemporary SQP methods. It avoids the difficulties associated with indefinite quadratic programming subproblems by defining this sub- problem to be always convex. The novel feature of the approach is the addition of an equality constrained phase that promotes fast convergence and improves performance in the presence of ill conditioning. This equality constrained phase uses exact second order information and can be implemented using either a direct solve or an iterative method. The paper studies the global and local convergence properties of the new algorithm and presents a set of numerical experiments to illustrate its practical performance. 1 Introduction Sequential quadratic programming (SQP) methods are very effective techniques for solv- ing small, medium-size and certain classes of large-scale nonlinear programming problems. They are often preferable to interior-point methods when a sequence of related problems must be solved (as in branch and bound methods) and more generally, when a good estimate of the solution is available. Some SQP methods employ convex quadratic programming sub- problems for the step computation (typically using quasi-Newton Hessian approximations) while other variants define the Hessian of the SQP model using second derivative informa- tion, which can lead to nonconvex quadratic subproblems; see [27, 1] for surveys on SQP methods. ∗Departamento de Matem´aticas, Instituto Tecnol´ogico Aut´onomode M´exico, M´exico. This author was supported by Asociaci´onMexicana de Cultura AC and CONACyT-NSF grant J110.388/2006. -

A Parallel Quadratic Programming Algorithm for Model Predictive Control
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com A Parallel Quadratic Programming Algorithm for Model Predictive Control Brand, M.; Shilpiekandula, V.; Yao, C.; Bortoff, S.A. TR2011-056 August 2011 Abstract In this paper, an iterative multiplicative algorithm is proposed for the fast solution of quadratic programming (QP) problems that arise in the real-time implementation of Model Predictive Control (MPC). The proposed algorithm–Parallel Quadratic Programming (PQP)–is amenable to fine-grained parallelization. Conditions on the convergence of the PQP algorithm are given and proved. Due to its extreme simplicity, even serial implementations offer considerable speed advantages. To demonstrate, PQP is applied to several simulation examples, including a stand- alone QP problem and two MPC examples. When implemented in MATLAB using single-thread computations, numerical simulations of PQP demonstrate a 5 - 10x speed-up compared to the MATLAB active-set based QP solver quadprog. A parallel implementation would offer a further speed-up, linear in the number of parallel processors. World Congress of the International Federation of Automatic Control (IFAC) This work may not be copied or reproduced in whole or in part for any commercial purpose. Permission to copy in whole or in part without payment of fee is granted for nonprofit educational and research purposes provided that all such whole or partial copies include the following: a notice that such copying is by permission of Mitsubishi Electric Research Laboratories, Inc.; an acknowledgment of the authors and individual contributions to the work; and all applicable portions of the copyright notice. Copying, reproduction, or republishing for any other purpose shall require a license with payment of fee to Mitsubishi Electric Research Laboratories, Inc. -

1 Linear Programming
ORF 523 Lecture 9 Princeton University Instructor: A.A. Ahmadi Scribe: G. Hall Any typos should be emailed to a a [email protected]. In this lecture, we see some of the most well-known classes of convex optimization problems and some of their applications. These include: • Linear Programming (LP) • (Convex) Quadratic Programming (QP) • (Convex) Quadratically Constrained Quadratic Programming (QCQP) • Second Order Cone Programming (SOCP) • Semidefinite Programming (SDP) 1 Linear Programming Definition 1. A linear program (LP) is the problem of optimizing a linear function over a polyhedron: min cT x T s.t. ai x ≤ bi; i = 1; : : : ; m; or written more compactly as min cT x s.t. Ax ≤ b; for some A 2 Rm×n; b 2 Rm: We'll be very brief on our discussion of LPs since this is the central topic of ORF 522. It suffices to say that LPs probably still take the top spot in terms of ubiquity of applications. Here are a few examples: • A variety of problems in production planning and scheduling 1 • Exact formulation of several important combinatorial optimization problems (e.g., min-cut, shortest path, bipartite matching) • Relaxations for all 0/1 combinatorial programs • Subroutines of branch-and-bound algorithms for integer programming • Relaxations for cardinality constrained (compressed sensing type) optimization prob- lems • Computing Nash equilibria in zero-sum games • ::: 2 Quadratic Programming Definition 2. A quadratic program (QP) is an optimization problem with a quadratic ob- jective and linear constraints min xT Qx + qT x + c x s.t. Ax ≤ b: Here, we have Q 2 Sn×n, q 2 Rn; c 2 R;A 2 Rm×n; b 2 Rm: The difficulty of this problem changes drastically depending on whether Q is positive semidef- inite (psd) or not. -

Practical Implementation of the Active Set Method for Support Vector Machine Training with Semi-Definite Kernels
PRACTICAL IMPLEMENTATION OF THE ACTIVE SET METHOD FOR SUPPORT VECTOR MACHINE TRAINING WITH SEMI-DEFINITE KERNELS by CHRISTOPHER GARY SENTELLE B.S. of Electrical Engineering University of Nebraska-Lincoln, 1993 M.S. of Electrical Engineering University of Nebraska-Lincoln, 1995 A dissertation submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy in the Department of Electrical Engineering and Computer Science in the College of Engineering and Computer Science at the University of Central Florida Orlando, Florida Spring Term 2014 Major Professor: Michael Georgiopoulos c 2014 Christopher Sentelle ii ABSTRACT The Support Vector Machine (SVM) is a popular binary classification model due to its superior generalization performance, relative ease-of-use, and applicability of kernel methods. SVM train- ing entails solving an associated quadratic programming (QP) that presents significant challenges in terms of speed and memory constraints for very large datasets; therefore, research on numer- ical optimization techniques tailored to SVM training is vast. Slow training times are especially of concern when one considers that re-training is often necessary at several values of the models regularization parameter, C, as well as associated kernel parameters. The active set method is suitable for solving SVM problem and is in general ideal when the Hessian is dense and the solution is sparse–the case for the `1-loss SVM formulation. There has recently been renewed interest in the active set method as a technique for exploring the entire SVM regular- ization path, which has been shown to solve the SVM solution at all points along the regularization path (all values of C) in not much more time than it takes, on average, to perform training at a sin- gle value of C with traditional methods. -

A Multi-Objective Approach to Portfolio Optimization
Rose-Hulman Undergraduate Mathematics Journal Volume 8 Issue 1 Article 12 A Multi-Objective Approach to Portfolio Optimization Yaoyao Clare Duan Boston College, [email protected] Follow this and additional works at: https://scholar.rose-hulman.edu/rhumj Recommended Citation Duan, Yaoyao Clare (2007) "A Multi-Objective Approach to Portfolio Optimization," Rose-Hulman Undergraduate Mathematics Journal: Vol. 8 : Iss. 1 , Article 12. Available at: https://scholar.rose-hulman.edu/rhumj/vol8/iss1/12 A Multi-objective Approach to Portfolio Optimization Yaoyao Clare Duan, Boston College, Chestnut Hill, MA Abstract: Optimization models play a critical role in determining portfolio strategies for investors. The traditional mean variance optimization approach has only one objective, which fails to meet the demand of investors who have multiple investment objectives. This paper presents a multi- objective approach to portfolio optimization problems. The proposed optimization model simultaneously optimizes portfolio risk and returns for investors and integrates various portfolio optimization models. Optimal portfolio strategy is produced for investors of various risk tolerance. Detailed analysis based on convex optimization and application of the model are provided and compared to the mean variance approach. 1. Introduction to Portfolio Optimization Portfolio optimization plays a critical role in determining portfolio strategies for investors. What investors hope to achieve from portfolio optimization is to maximize portfolio returns and minimize portfolio risk. Since return is compensated based on risk, investors have to balance the risk-return tradeoff for their investments. Therefore, there is no a single optimized portfolio that can satisfy all investors. An optimal portfolio is determined by an investor’s risk-return preference. -

Achieving Portfolio Diversification for Individuals with Low Financial
sustainability Article Achieving Portfolio Diversification for Individuals with Low Financial Sustainability Yongjae Lee 1 , Woo Chang Kim 2 and Jang Ho Kim 3,* 1 Department of Industrial Engineering, Ulsan National Institute of Science and Technology (UNIST), Ulsan 44919, Korea; [email protected] 2 Department of Industrial and Systems Engineering, Korea Advanced Institute of Science and Technology (KAIST), Daejeon 34141, Korea; [email protected] 3 Department of Industrial and Management Systems Engineering, Kyung Hee University, Yongin-si 17104, Gyeonggi-do, Korea * Correspondence: [email protected] Received: 5 August 2020; Accepted: 26 August 2020; Published: 30 August 2020 Abstract: While many individuals make investments to gain financial stability, most individual investors hold under-diversified portfolios that consist of only a few financial assets. Lack of diversification is alarming especially for average individuals because it may result in massive drawdowns in their portfolio returns. In this study, we analyze if it is theoretically feasible to construct fully risk-diversified portfolios even for the small accounts of not-so-rich individuals. In this regard, we formulate an investment size constrained mean-variance portfolio selection problem and investigate the relationship between the investment amount and diversification effect. Keywords: portfolio size; portfolio diversification; individual investor; financial sustainability 1. Introduction Achieving financial sustainability is a basic goal for everyone and it has become a shared concern globally due to increasing life expectancy. Low financial sustainability may refer to individuals with low financial wealth, as well as investors with a lack of financial literacy. Especially for individuals with limited wealth, financial sustainability after retirement is a real concern because of uncertainty in pension plans arising from relatively early retirement age and change in the demographic structure (see, for example, [1,2]). -

Optimization of Conditional Value-At-Risk
Implemented in Portfolio Safeguard by AORDA.com Optimization of conditional value-at-risk R. Tyrrell Rockafellar Department of Applied Mathematics, University of Washington, 408 L Guggenheim Hall, Box 352420, Seattle, Washington 98195-2420, USA Stanislav Uryasev Department of Industrial and Systems Engineering, University of Florida, PO Box 116595, 303 Weil Hall, Gainesville, Florida 32611-6595, USA A new approach to optimizing or hedging a portfolio of ®nancial instruments to reduce risk is presented and tested on applications. It focuses on minimizing conditional value-at-risk CVaR) rather than minimizing value-at-risk VaR),but portfolios with low CVaR necessarily have low VaR as well. CVaR,also called mean excess loss,mean shortfall,or tail VaR,is in any case considered to be a more consistent measure of risk than VaR. Central to the new approach is a technique for portfolio optimization which calculates VaR and optimizes CVaR simultaneously. This technique is suitable for use by investment companies,brokerage ®rms,mutual funds, and any business that evaluates risk. It can be combined with analytical or scenario- based methods to optimize portfolios with large numbers of instruments,in which case the calculations often come down to linear programming or nonsmooth programming. The methodology can also be applied to the optimization of percentiles in contexts outside of ®nance. 1. INTRODUCTION This paper introduces a new approach to optimizing a portfolio so as to reduce the risk of high losses. Value-at-risk VaR) has a role in the approach, but the emphasis is on conditional value-at-risk CVaR), which is also known as mean excess loss, mean shortfall, or tail VaR.