B.C.A. - Iii Year
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Adventures with Illumos
> Adventures with illumos Peter Tribble Theoretical Astrophysicist Sysadmin (DBA) Technology Tinkerer > Introduction ● Long-time systems administrator ● Many years pointing out bugs in Solaris ● Invited onto beta programs ● Then the OpenSolaris project ● Voted onto OpenSolaris Governing Board ● Along came Oracle... ● illumos emerged from the ashes > key strengths ● ZFS – reliable and easy to manage ● Dtrace – extreme observability ● Zones – lightweight virtualization ● Standards – pretty strict ● Compatibility – decades of heritage ● “Solarishness” > Distributions ● Solaris 11 (OpenSolaris based) ● OpenIndiana – OpenSolaris ● OmniOS – server focus ● SmartOS – Joyent's cloud ● Delphix/Nexenta/+ – storage focus ● Tribblix – one of the small fry ● Quite a few others > Solaris 11 ● IPS packaging ● SPARC and x86 – No 32-bit x86 – No older SPARC (eg Vxxx or SunBlades) ● Unique/key features – Kernel Zones – Encrypted ZFS – VM2 > OpenIndiana ● Direct continuation of OpenSolaris – Warts and all ● IPS packaging ● X86 only (32 and 64 bit) ● General purpose ● JDS desktop ● Generally rather stale > OmniOS ● X86 only ● IPS packaging ● Server focus ● Supported commercial offering ● Stable components can be out of date > XStreamOS ● Modern variant of OpenIndiana ● X86 only ● IPS packaging ● Modern lightweight desktop options ● Extra applications – LibreOffice > SmartOS ● Hypervisor, not general purpose ● 64-bit x86 only ● Basis of Joyent cloud ● No inbuilt packaging, pkgsrc for applications ● Added extra features – KVM guests – Lots of zone features – -

Hardware-Driven Evolution in Storage Software by Zev Weiss A
Hardware-Driven Evolution in Storage Software by Zev Weiss A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Computer Sciences) at the UNIVERSITY OF WISCONSIN–MADISON 2018 Date of final oral examination: June 8, 2018 ii The dissertation is approved by the following members of the Final Oral Committee: Andrea C. Arpaci-Dusseau, Professor, Computer Sciences Remzi H. Arpaci-Dusseau, Professor, Computer Sciences Michael M. Swift, Professor, Computer Sciences Karthikeyan Sankaralingam, Professor, Computer Sciences Johannes Wallmann, Associate Professor, Mead Witter School of Music i © Copyright by Zev Weiss 2018 All Rights Reserved ii To my parents, for their endless support, and my cousin Charlie, one of the kindest people I’ve ever known. iii Acknowledgments I have taken what might be politely called a “scenic route” of sorts through grad school. While Ph.D. students more focused on a rapid graduation turnaround time might find this regrettable, I am glad to have done so, in part because it has afforded me the opportunities to meet and work with so many excellent people along the way. I owe debts of gratitude to a large cast of characters: To my advisors, Andrea and Remzi Arpaci-Dusseau. It is one of the most common pieces of wisdom imparted on incoming grad students that one’s relationship with one’s advisor (or advisors) is perhaps the single most important factor in whether these years of your life will be pleasant or unpleasant, and I feel exceptionally fortunate to have ended up iv with the advisors that I’ve had. -

Wdd-Ebook.Pdf
The illumos Writing Device Drivers Sun Microsystems, Inc. has intellectual property rights relating to technology embodied in the product that is described in this document. In particular, and without limitation, these intellectual property rights may include one or more U.S. patents or pending patent applications in the U.S. and in other countries. U.S. Government Rights – Commercial software. Government users are subject to the Sun Microsystems, Inc. standard license agreement and applicable provisions of the FAR and its supplements. This distribution may include materials developed by third parties. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, the Solaris logo, the Java Coffee Cup logo, docs.sun.com, Java, and Solaris are trademarks or registered trademarks of Sun Microsystems, Inc. or its subsidiaries in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements. -

The Rise & Development of Illumos
Fork Yeah! The Rise & Development of illumos Bryan Cantrill VP, Engineering [email protected] @bcantrill WTF is illumos? • An open source descendant of OpenSolaris • ...which itself was a branch of Solaris Nevada • ...which was the name of the release after Solaris 10 • ...and was open but is now closed • ...and is itself a descendant of Solaris 2.x • ...but it can all be called “SunOS 5.x” • ...but not “SunOS 4.x” — thatʼs different • Letʼs start at (or rather, near) the beginning... SunOS: A peopleʼs history • In the early 1990s, after a painful transition to Solaris, much of the SunOS 4.x engineering talent had left • Problems compounded by the adoption of an immature SCM, the Network Software Environment (NSE) • The engineers revolted: Larry McVoy developed a much simpler variant of NSE called NSElite (ancestor to git) • Using NSElite (and later, TeamWare), Roger Faulkner, Tim Marsland, Joe Kowalski and Jeff Bonwick led a sufficiently parallelized development effort to produce Solaris 2.3, “the first version that worked” • ...but with Solaris 2.4, management took over day-to- day operations of the release, and quality slipped again Solaris 2.5: Do or die • Solaris 2.5 absolutely had to get it right — Sun had new hardware, the UltraSPARC-I, that depended on it • To assure quality, the engineers “took over,” with Bonwick installed as the gatekeeper • Bonwick granted authority to “rip it out if itʼs broken" — an early BDFL model, and a template for later generations of engineering leadership • Solaris 2.5 shipped on schedule and at quality -

Introducing a New Product
illumos SVOSUG Update Presented by Garrett D'Amore Nexenta Systems, Inc. August 26, 2010 What's In A Name? illumos = illum + OS = “Light + OS” Light as in coming from the Sun... OS as in Operating System Note: illumos not Illumos or IllumOS “illumos” trademark application in review. Visual branding still under consideration. Not All of OpenSolaris is Open Source ● Critical components closed source – libc_i18n (needed for working C library) – NFS lock manager – Portions of crypto framework – Numerous critical drivers (e.g. mpt) ● Presents challenges to downstream dependents – Nexenta, Belenix, SchilliX, etc. – See “Darwin” and “MacOS X” for the worst case What's Good ● The Technology! – ZFS, DTrace, Crossbow, Zones, etc. ● The People – World class engineers! – Great community of enthusiasts – Vibrant ecosystem ● The Code is Open – Well most of it, at least illumos – the Project ● Derivative (child) of OS/Net (aka ON) – Solaris/OpenSolaris kernel and foundation – 100% ABI compatible with Solaris ON – Now a real fork of ON, but will merge when code available from Oracle ● No closed code – Open source libc, kernel, and drivers! ● Repository for other “experimental” innovations – Can accept changes from contributors that might not be acceptable to upstream illumos – the Ecosystem ● illumos-gate is just ON – Focused on “Core Foundation Blocks” – Flagship project ● Expanding to host other affiliated projects – Umbrella organization – X11 components? – Desktop components? – C++ Runtime? – Distributions? illumos – the Community ● Stands independently -

A New Flame: Experiences Starting an Open Source Operating System
A New Flame: Experiences Starting an Open Source Operating System Garrett D’Amore SCALE 10X, January 2012 What is an illumos? • An Open Source operating system • Based on Solaris (POSIX/UNIX) • By the community • For the community • Core of several commercial projects Roots • BSD begat SunOS • SunOS & SVR4 begat Solaris • Solaris begat OpenSolaris • OpenSolaris begat illumos (Aug 3, 2010) Why illumos? Why illumos? Why illumos? Why illumos? • FOSS Continuity for OpenSolaris • Ability to fork(2) • Home for Collaboration Attitude Counts • Tap turns off • bad? no! • freedom to innovate! • Optimism and energy critical • Demonstrate pace • Avoid the FUD Code First! Make sure you have something to show when you announce! Events • Community events drive momentum • User group meetings • SCALE 9X, SCALE 10X! • Open Storage Summit • Hackathons • FOSDEM, etc. Think Global! • Not just MPK17 • Not just SFBAY • Euro. Russia. India. • Local user groups • Local events • Localized software and documentation • Next: Mars? GSoC • Students are the future • Great way to appeal outside your core community • Identification of good projects key • Good mentors are critical Governance • Less is more • Separate admin & tech • Ends to a mean Press Relations • Press releases = buzz • Early “announce” • Trade press • Slashdot Commercialization • Critical to success • Don’t yield control • OS development • Marketing Partnerships • ISV relationships = commercial sponsors • IHV relationships = broad H/W support • FOSS relationships = community collaboration Hardware Partners -
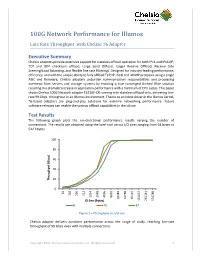
100G Network Performance for Illumos
100G Network Performance for Illumos Line Rate Throughput with Chelsio T6 Adapter Executive Summary Chelsio adapters provide extensive support for stateless offload operation for both IPv4 and IPv6 (IP, TCP and UDP checksum offload, Large Send Offload, Larger Receive Offload, Receive Side Steering/Load Balancing, and flexible line rate Filtering). Designed for industry-leading performance, efficiency, and with the unique ability to fully offload TCP/IP, iSCSI and iWARP protocols using a single ASIC and firmware, Chelsio adapters unburden communication responsibilities and processing overhead from servers and storage systems by enabling a true converged Unified Wire solution resulting in a dramatic increase in application performance with a minimum of CPU cycles. This paper shows Chelsio 100G Network adapter T62100-CR running with stateless offload only, delivering line- rate 99 Gbps throughput in an Illumos environment. Thanks to an inbox driver in the Illumos kernel, T6-based adapters are plug-and-play solutions for extreme networking performance. Future software releases can enable the various offload capabilities in the silicon. Test Results The following graph plots the uni-directional performance results varying the number of connections. The results are obtained using the Iperf tool across I/O sizes ranging from 64 bytes to 512 Kbytes. 100 80 60 40 Throughput(Gbps) 20 0 64 128 256 512 1024 2048 4096 8192 16384 32768 65535 262144 524288 IO Size (Bytes) 131072 8 16 32 Figure 1 – Throughput vs. I/O size Chelsio adapter delivers consitent performance across the range of study, reaching line-rate throughput of 99 Gbps even with multiple connections. Copyright 2020. -

Ryan Zezeski // Illumos Day // Sep 2015
fixing bugs in illumos Ryan Zezeski // illumos day // Sep 2015 my favorite part of illumos is the tooling Debugging Tools • truss — sycall and userspace tracer • ptools: proc(1) — various process-focused introspection • mdb(1) — modular debugger, core dump analysis, live kernel introspection with -k • dtrace(1) — dynamic tracing of the entire system, the best debugging tool ever made How My Printer Caused Excessive Syscalls & UDP Traffic http://zinascii.com/2014/how-my-printer-caused-excessive- syscalls.html DTracing in Anger http://dtrace.org/blogs/brendan/2012/11/14/dtracing-in- anger/ Shouting in the Datacenter https://www.youtube.com/watch?v=tDacjrSCeq4 The Setup Pre-Setup • A lot of ex-Sun people. • Their traditions and nomenclature carried over. • Confusing, and perhaps frustrating, at first. Be patient. • Decades of history. Give their process a chance before criticizing it. You might end up liking it! • http://zinascii.com/2014/my-first-illumos-build.html Install OmniOS • http://omnios.omniti.com/ • Recently gained ability to build gate. I use 151014. • I run OmniOS on SmartOS KVM, but recommend a spare machine or VMWare Fusion to start. • Tell Fusion to use Solaris 10 64-bit and don’t forget to add a floppy (to appease the installer). • http://omnios.omniti.com/wiki.php/VMwareNotes “Zero Out” Your Environment • Before trying to fix anything make sure you can build gate without any modifications. • Many versions of instructions on how to build gate, lots of opinions. Often results in pain for newcomers. • Use my nightly-setup script to -

Nexentastor 4.0.4 User Guide
NexentaStor User Guide 4.0.4 Date: June, 2015 Subject: NexentaStor User Guide Software: NexentaStor Software Version: 4.0.4 Part Number: 3000-nxs-4.0.4 000057-B Copyright © 2015 Nexenta Systems, ALL RIGHTS RESERVED www.nexenta.com NexentaStor User Guide Copyright © 2015 Nexenta SystemsTM, ALL RIGHTS RESERVED Notice: No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or stored in a database or retrieval system for any purpose, without the express written permission of Nexenta Systems (hereinafter referred to as “Nexenta”). Nexenta reserves the right to make changes to this document at any time without notice and assumes no responsibility for its use. Nexenta products and services only can be ordered under the terms and conditions of Nexenta Systems’ applicable agreements. All of the features described in this document may not be available currently. Refer to the latest product announcement or contact your local Nexenta Systems sales office for information on feature and product availability. This document includes the latest information available at the time of publication. Nexenta, NexentaStor, NexentaEdge, and NexentaConnect are registered trademarks of Nexenta Systems in the United States and other countries. All other trademarks, service marks, and company names in this document are properties of their respective owners. Product Versions Applicable to this Documentation: Product Versions supported NexentaStorTM 4.0.4 Copyright © 2015 Nexenta Systems, ALL RIGHTS RESERVED ii www.nexenta.com NexentaStor User Guide Contents Preface . xv 1 Introduction . .1 About NexentaStor . .1 About NexentaStor Components . .2 Using Plugins . -

Virtualization and Namespace Isolation in the Solaris Operating System (PSARC/2002/174)
Virtualization and Namespace Isolation in the Solaris Operating System (PSARC/2002/174) John Beck, David Comay, Ozgur L., Daniel Price, and Andy T. Solaris Kernel Technology Andrew G. and Blaise S. Solaris Network and Security Technologies Revision 1.6 (OpenSolaris) September 7, 2006 ii Contents 1 Introduction 1 1.1 Zone Basics . 2 1.2 Zone Principles . 3 1.3 Terminology and Conventions . 5 1.4 Outline . 6 2 Related Work 7 3 Zone Runtime 9 3.1 Zone State Model . 9 3.2 Zone Names and Numeric IDs . 10 3.3 Zone Runtime Support . 10 3.3.1 zoneadmd(1M) ............................... 10 3.3.2 zsched . 12 3.4 Listing Zone Information . 12 4 Zone Administration 13 4.1 Zone Configuration . 13 4.1.1 Configuration Data . 14 4.2 Zone Installation . 15 4.3 Virtual Platform Administration . 16 4.3.1 Readying Zones . 16 4.3.2 Booting Zones . 16 4.3.3 Halting Zones . 17 4.3.4 Rebooting Zones . 17 4.3.5 Automatic Zone Booting . 18 4.4 Zone Login . 18 4.4.1 Zone Console Login . 18 4.4.2 Interactive and Non-Interactive Modes . 19 4.4.3 Failsafe Mode . 20 4.4.4 Remote Login . 20 4.5 Monitoring and Controlling Zone Processes . 21 iii 5 Administration within Zones 23 5.1 Node Name . 23 5.2 Name Service Usage within a Zone . 23 5.3 Default Locale and Timezone . 24 5.4 Initial Zone Configuration . 24 5.5 System Log Daemon . 24 5.6 Commands . 25 5.7 Internals of Booting Zones . -

Adventures with Illumos
> Adventures with illumos Peter Tribble Theoretical Astrophysicist Sysadmin (DBA) Technology Tinkerer > Introduction ● Long-time systems administrator ● Many years pointing out bugs in Solaris ● Invited onto beta programs ● Then the OpenSolaris project ● Voted onto OpenSolaris Governing Board ● Along came Oracle... ● illumos emerged from the ashes > illumos key strengths ● ZFS – reliable and easy to manage ● Dtrace – extreme observability ● Zones – lightweight virtualization ● Standards – pretty strict ● Compatibility – decades of heritage ● “Solarishness” > Directions ● ZFS (OpenZFS) ● XPG7 standards ● Missing pieces from open code ● Cleaning cruft – But can we preserve heritage? ● LX brand (native Linux emulation) > Distributions ● OpenIndiana – OpenSolaris ● OmniOS – server focus ● SmartOS – Joyent's cloud ● Delphix/Nexenta/+ – storage focus ● Tribblix – one of the small fry ● Quite a few others > Why? ● Because it's hard ● Understand the inner workings ● Satisfy the target audience ● Make a flexible platform for development of new ideas ● Didn't like other distros! > Tribblix values ● Modern components ● Retro styling ● Lightweight window managers ● SVR4 packaging ● Lightweight and fast ● Simplicity and “just works” > Tribblix futures ● Zones and app deployment – Sparse-root, whole, partial, alien ● Simplify administration - “just works” – Make internals invisible ● Modern application stacks – Many on top of go – Integrated with zones and zfs > Potholes ● Not enough time/people ● Fragmentation – All the work done at the distro level ● SPARC port struggling ● No cgo yet > Further reading http://www.illumos.org/ http://www.tribblix.org/ http://www.petertribble.co.uk/ [email protected] . -

Operating Systems. Lecture 2
Operating systems. Lecture 2 Michał Goliński 2018-10-09 Introduction Recall • Basic definitions – Operating system – Virtual memory – Types of OS kernels • Booting process – BIOS, MBR – UEFI Questions? Plan for today • History of Unix-like systems • Introduction to Linux • Introduction to bash • Getting help in bash • Managing files in bash History History of Unix-like systems • 1960s – Multics (MIT, AT&T Bell Labs, General Electric) • 1960s/1970s – UNIX (Ken Thompson, Dennis Ritchie) 1 PDP-7 History of UNIX-like systems • 1970s, 1980s – popularization, standardization and commerciallization of UNIX • 1983 – the GNU Project is stared 2 • 1988 – the first version of the POSIX standard History of Unix-like systems • 1991 – the first version of a Unix clone – Linux (Linux is not Unix) • 1992 – the license is fixed as GPLv2 • 1996 – version 2.0, supporting many processors • 2003 – version 2.6, new scheduler, much better with multiprocessor machines, preemptive kernel, rewriting code to not depend on the so- called Big Kernel Lock • if the version scheme had not been changed, the current kernel (4.18) would be 2.6.78 Genealogy 1969 Unnamed PDP-7 operating system 1969 Open source 1971 to 1973 Unix 1971 to 1973 Version 1 to 4 Mixed/shared source 1974 to 1975 Unix 1974 to 1975 Version 5 to 6 PWB/Unix Closed source 1978 1978 BSD 1.0 to 2.0 Unix 1979 Version 7 1979 Unix/32V 1980 1980 BSD 3.0 to 4.1 1981 Xenix System III 1981 1.0 to 2.3 1982 1982 Xenix 3.0 1983 BSD 4.2 SunOS 1983 1 to 1.1 System V R1 to R2 1984 SCO Xenix 1984 Unix 1985 Version 8