Time-Series Data Mining in Transportation: a Case Study on Singapore Public Train Commuter Travel Patterns
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FITTING-OUT MANUAL for Commercial Occupiers
FITTING-OUT MANUAL for Commercial Occupiers SMRT PROPERTIES SMRT Investments Pte Ltd 251 North Bridge Road Singapore 179102 Tel : 65 6331 1000 Fax : 65 6337 5110 www.smrt.com.sg While every reasonable care has been taken to provide the information in this Fitting-Out Manual, we make no representation whatsoever on the accuracy of the information contained which is subject to change without prior notice. We reserve the right to make amendments to this Fitting-Out Manual from time to time as necessary. We accept no responsibility and/or liability whatsoever for any reliance on the information herein and/or damage howsoever occasioned. 09/2013 (Ver 3.9) Fitting Out Manual SMRT Properties To our Valued Customer, a warm welcome to you! This Fitting-Out Manual is specially prepared for you, our Valued Customer, to provide general guidelines for you, your appointed consultants and contractors when fitting-out your premises at any of our Mass Rapid Transit (MRT) or Light Rail Transit (LRT) stations. This Fitting-Out Manual serves as a guide only. Your proposed plans and works will be subjected to the approval of SMRT and the relevant authorities. We strongly encourage you to read this document before you plan your fitting-out works. Do share this document with your consultants and contractors. While reasonable care has been taken to prepare this Fitting-Out Manual, we reserve the right to amend its contents from time to time without prior notice. If you have any questions, please feel free to approach any of our Management staff. We will be pleased to assist you. -
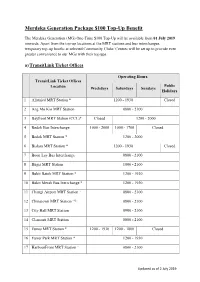
Merdeka Generation Package $100 Top-Up Benefit
Merdeka Generation Package $100 Top-Up Benefit The Merdeka Generation (MG) One-Time $100 Top-Up will be available from 01 July 2019 onwards. Apart from the top-up locations at the MRT stations and bus interchanges, temporary top-up booths at selected Community Clubs/ Centres will be set up to provide even greater convenience to our MGs with their top ups. a) TransitLink Ticket Offices Operating Hours TransitLink Ticket Offices Public Location Weekdays Saturdays Sundays Holidays 1 Aljunied MRT Station * 1200 - 1930 Closed 2 Ang Mo Kio MRT Station 0800 - 2100 3 Bayfront MRT Station (CCL)* Closed 1200 - 2000 4 Bedok Bus Interchange 1000 - 2000 1000 - 1700 Closed 5 Bedok MRT Station * 1200 - 2000 6 Bishan MRT Station * 1200 - 1930 Closed 7 Boon Lay Bus Interchange 0800 - 2100 8 Bugis MRT Station 1000 - 2100 9 Bukit Batok MRT Station * 1200 - 1930 10 Bukit Merah Bus Interchange * 1200 - 1930 11 Changi Airport MRT Station ~ 0800 - 2100 12 Chinatown MRT Station ~@ 0800 - 2100 13 City Hall MRT Station 0900 - 2100 14 Clementi MRT Station 0800 - 2100 15 Eunos MRT Station * 1200 - 1930 1200 - 1800 Closed 16 Farrer Park MRT Station * 1200 - 1930 17 HarbourFront MRT Station ~ 0800 - 2100 Updated as of 2 July 2019 Operating Hours TransitLink Ticket Offices Public Location Weekdays Saturdays Sundays Holidays 18 Hougang MRT Station * 1200 - 1930 19 Jurong East MRT Station * 1200 - 1930 20 Kranji MRT Station * 1230 - 1930 # 1230 - 1930 ## Closed## 21 Lakeside MRT Station * 1200 - 1930 22 Lavender MRT Station * 1200 - 1930 Closed 23 Novena MRT Station -

Yamato Transport Branch Postal Code Address TA-Q-BIN Lockers
Yamato Transport Branch Postal Code Address TA-Q-BIN Lockers Location Postal Code Cheers Store Address Opening Hours Headquarters 119936 61 Alexandra Terrace #05-08 Harbour Link Complex Cheers @ AMK Hub 569933 No. 53 Ang Mo Kio Ave 3 #01-37, AMK Hub 24 hours TA-Q-BIN Branch Close on Fri and Sat Night 119937 63 Alexandra Terrace #04-01 Harbour Link Complex Cheers @ CPF Building 068897 79 Robinson Road CPF Building #01-02 (Parcel Collection) from 11pm to 7am TA-Q-BIN Call Centre 119936 61 Alexandra Terrace #05-08 Harbour Link Complex Cheers @ Toa Payoh Lorong 1 310109 Block 109 #01-310 Toa Payoh Lorong 1 24 hours Takashimaya Shopping Centre,391 Orchard Rd, #B2-201/8B Fairpricexpress Satellite Office 238873 Operation Hour: 10.00am - 9.30pm every day 228149 1 Sophia Road #01-18, Peace Centre 24 hours @ Peace Centre (Subject to Takashimaya operating hours) Cheers @ Seng Kang Air Freight Office 819834 7 Airline Rd #01-14/15, Cargo Agent Building E 546673 211 Punggol Road 24 hours ESSO Station Fairpricexpress Sea Freight Office 099447 Blk 511 Kampong Bahru Rd #02-05, Keppel Distripark @ Toa Payoh Lorong 2 ESSO 319640 399 Toa Payoh Lorong 2 24 hours Station Fairpricexpress @ Woodlands Logistics & Warehouse 119937 63 Alexandra Terrace #04-01 Harbour Link Complex 739066 50 Woodlands Avenue 1 24 hours Ave 1 ESSO Station Removal Office 119937 63 Alexandra Terrace #04-01 Harbour Link Complex Cheers @ Concourse Skyline 199600 302 Beach Road #01-01 Concourse Skyline 24 hours Cheers @ 810 Hougang Central 530810 BLK 810 Hougang Central #01-214 24 hours -
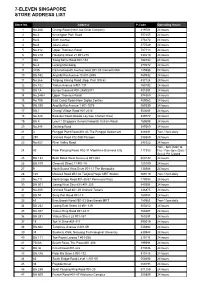
SLIDE Store Listing- 1 Apr 2019
7-ELEVEN SINGAPORE STORE ADDRESS LIST Store No. Address P.Code Operating Hours 1 No.38A Changi Road (Near Joo Chiat Complex) 419701 24 hours 2 No.3 Kensington Park Road 557255 24 hours 3 No.6 Sixth Avenue 276472 24 hours 4 No.6 Jalan Leban 577549 24 hours 5 No.912 Upper Thomson Road 787113 24 hours 6 Blk.210 Hougang Street 21 #01-275 530210 24 hours 7 302 Tiong Bahru Road #01-152 168732 24 hours 8 No.4 Lorong Mambong 277672 24 hours 9 3155 Commonwealth Avenue West #01-03 Clementi Mall 129588 24 hours 10 Blk.532 Ang Mo Kio Avenue 10 #01-2455 560532 24 hours 11 No.366 Tanjong Katong Road (Opp. Post Office) 437124 24 hours 12 Blk.102 Yishun Avenue 5 #01-137 760102 24 hours 13 Blk.1A Eunos Crescent #01-2469/2471 401001 24 hours 14 No.244H Upper Thomson Road 574369 24 hours 15 No.705 East Coast Road (Near Siglap Centre) 459062 24 hours 16 Blk.339 Ang Mo Kio Avenue 1 #01-1579 560339 24 hours 17 Blk.1 Changi Village Road #01-2014 500001 24 hours 18 No.340 Balestier Road (beside Loy Kee Chicken Rice) 329772 24 hours 19 Blk 4 Level 1 Singapore General Hospital Outram Road 169608 24 hours 20 No.348 Geylang Road 389369 24 hours 21 3 Punggol Point Road #01-06 The Punggol Settlement 828694 7am-11pm daily 22 290 Orchard Road #02-08B Paragon 238859 24 hours 23 No.423 River Valley Road 248322 24 hours 7am - 8pm (Mon to 24 40 Pasir Panjang Road, #02-31 Mapletree Business City 117383 Fri) / 7am-3pm (Sat) / Sun & PH Closed 25 Blk.132 Bukit Batok West Avenue 6 #01-304 650132 24 hours 26 Blk.109 Clementi Street 11 #01-15 120109 24 hours 27 9 North Buona Vista -

The New Bugis Station and Associated Tunnels for the Singapore MRT
Proceedings of the 18th International Conference on Soil Mechanics and Geotechnical Engineering, Paris 2013 The new Bugis Station and associated tunnels for the Singapore MRT Métro de Singapour : nouvelle station Bugis et tunnels associés Sim A. Soletanche-Bachy ABSTRACT: The construction of the new Bugis Station and associated tunnels presented a number of interesting challenges all of which are linked to the building of new infrastructure in mature urban environments. The story of Mass Rapid Transit in Singapore is not at all old, with the first lines only operating for little over 25 years. However, the City State now finds that new lines are increasingly interlacing with existing underground assets, with unique problems presenting themselves. This, together with a more sophisticated population which demands greater respect for the built environment with inconvenience along with noise, dust and water pollution all being subject to greater scrutiny and demands for the Client and Contractor alike to deliver projects according to the highest international standards. RÉSUMÉ : La construction de la nouvelle station Bugis et des tunnels associés a présenté plusieurs défis intéressants, tous liés à la construction d’infrastructures nouvelles dans un environnement urbain dense. L’histoire du métro de Singapour est récente, puisque les premières lignes sont en exploitation depuis un peu plus de 25 ans. Cependant, l’Etat de Singapour est maintenant confronté au fait que les tracés des nouvelles lignes rencontrent des ouvrages souterrains existants, ce qui génère des problèmes uniques. S’ajoutent à cela plusieurs facteurs qui rendent les projets de nouvelles lignes particulièrement complexes : une population plus sophistiquée qui demande un plus grand respect de l’environnement existant, une attention croissante portée aux nuisances (bruit, poussière, eau), et des demandes au client et à l’entreprise de se conformer aux normes internationales les plus exigeantes. -

Singapore for Families Asia Pacificguides™
™ Asia Pacific Guides Singapore for Families A guide to the city's top family attractions and activities Click here to view all our FREE travel eBooks of Singapore, Hong Kong, Macau and Bangkok Introduction Singapore is Southeast Asia's most popular city destination and a great city for families with kids, boasting a wide range of attractions and activities that can be enjoyed by kids and teenagers of all ages. This mini-guide will take you to Singapore's best and most popular family attractions, so you can easily plan your itinerary without having to waste precious holiday time. Index 1. The Singapore River 2 2. The City Centre 3 3. Marina Bay 5 4. Chinatown 7 5. Little India, Kampong Glam (Arab Street) and Bugis 8 6. East Coast 9 7. Changi and Pasir Ris 9 8. Central and North Singapore 10 9. Jurong BirdPark, Chinese Gardens and West Singapore 15 10. Pulau Ubin and the islands of Singapore 18 11. Sentosa, Universal Studios Singapore and "Resorts World" 21 12. Other attractions and activities 25 Rating: = Not bad = Worth trying = A real must try Copyright © 2012 Asia-Pacific Guides Ltd. All rights reserved. 1 Attractions and activities around the Singapore River Name and details What is there to be seen How to get there and what to see next Asian Civilisations Museum As its name suggests, this fantastic Address: 1 Empress Place museum displays the cultures of Asia's Rating: tribes and nations, with emphasis on From Raffles Place MRT Station: Take Exit those groups that actually built the H to Bonham Street and walk to the river Tuesday – Sunday : 9am-7pm (till city-state. -

List of Yamato Singapore Branch Offices, 7-CONNECT Lockers and 7
7-CONNECT LOCKERs Yamato Transport Branch Postal Code Address Postal Code 7-11 Store Address Location Headquarters 119936 61 Alexandra Terrace #05-08 Harbour Link Complex 7-11 @ 170 Bencoolen Street 189657 170 Bencoolen Street #01-03 Ibis Hotel TA-Q-BIN Branch 119937 63 Alexandra Terrace #04-01 Harbour Link Complex 7-11 @ Big Mac Centre 569922 51 Ang Mo Kio Ave 3 (Parcel Collection) TA-Q-BIN Call Centre 119936 61 Alexandra Terrace #05-08 Harbour Link Complex 7-11 @ BLK 190 Toa Payoh 310190 BLK 190 Toa Payoh Lorong 6 #01-564 Takashimaya Shopping Centre,391 Orchard Rd, #B2-201/8B 7-11 @ BLK 318B Anchorvale Satellite Office 238873 Operation Hour: 10.00am - 9.30pm every day 542318 BLK 318B Anchorvale Link #01-255 Link (Subject to Takashimaya operating hours) Air Freight Office 819834 7 Airline Rd #01-14/15, Cargo Agent Building E 7-11 @ BLK 356 Hougang 530356 BLK 356 Hougang Avenue 7 #01-781 Sea Freight Office 119937 63 Alexandra Terrace #04-01 Harbour Link Complex 7-11 @ BLK 501 Jurong West 640501 BLK 501 Jurong West Street 51 #01-255 Logistics & Warehouse 119937 63 Alexandra Terrace #04-01 Harbour Link Complex 7-11 @ BLK 532 Ang Mo Kio 560532 BLK 532 Ang Mo Kio Avenue 10 #01-2455 7-11 @ BLK 623 CCK ST 12 (Next Removal Office 119937 63 Alexandra Terrace #04-01 Harbour Link Complex 680623 BLK 623 Choa Chu Kang Street 62 #01-216 to Yew Tee MRT) 7-11 @ Tampines North Drive 2 528765 21 Tampines North Drive 2 #01-02 WRS (WRS) 7-11 @ Tampines Street 32 529284 5 Tampines Street 32 #01-19/20 Tampines Mart (Tampines Mart) 7-11 @ Victoria Street (Opp. -

Moving Stories 2.0.Pdf
GROWING: RISING TO THE CHALLENGE 94 Events That Shaped Us 95 TABLE OF CONTENTS 1986: Collapse of Hotel New World 96 1993: The First Major MRT Incident 97 2003: SARS Crisis 98 2004: Exercise Northstar 99 2010: Acts of Vandalism 100 BEGINNING: THE RAIL DEVELOPMENT 1 2011: MRT Disruptions 100 CONNECTING: OUR SMRT FAMILY 57 The Rail Progress 2 2012: Bus Captains’ Strike 102 The Early Days 4 One Family 58 2015: Remembering Our Founding Father 104 Opening of the Rail Network 10 One Identity 59 2015: Celebrating SG50 106 Completion of the North-South and East-West Lines 15 A Familiar Place 60 2016: 22 March Fatal Accident 107 INNOVATING: MOVING WITH THE TIMES 110 Woodlands Extension 22 A Familiar Face 61 2017: Flooding in Tunnel 108 Operations to Innovation 111 Bukit Panjang Light Rail Transit 24 National Day Parade 2004 62 2017: Train Collision at Joo Koon MRT Station 109 Operating for Tomorrow 117 Keeping It in the Family 64 Beyond Our Network & Borders 120 Love is in the Air 66 Footprint in the Urban Mobility Space 127 Esprit de Corps 68 TRANSFORMING: TRAVEL REDEFINED 26 A Greener Future 129 Remember the Mascots? 74 SMRT Corporation Ltd 27 Stretching Our Capability 77 TIBS Merger 30 Engaging Our Community 80 An Expanding Network 35 Fare Payment Evolution 42 Tracking Improvements 50 More Than Just a Station 53 SMRT Institute 56 VISION 1 Moving People, Enhancing Lives MISSION In 2017, SMRT Corporation Ltd (SMRT) celebrates 30 years of Mass Rapid Transit (MRT) operations. To be the people’s choice by delivering a world-class transport service and Delivering a world-class transport service that is safe, reliable and customer-centric is at the lifestyle experience that is safe, heart of what we do. -

List of Public CD Shelters As of 31 Dec 2019.Xlsx
NO NAME DESCRIPTION ADDRESS POSTAL CODE 1 Telok Blangah CC Civil Defence Public Shelter (Community Club/Centre) 450 Telok Blangah Street 31 108943 2 Ulu Pandan CC Civil Defence Public Shelter (Community Club/Centre) 170 Ghim Moh Road 279621 3 Toa Payoh West CC Civil Defence Public Shelter (Community Club/Centre) 200 Lorong 2 Toa Payoh 319642 4 Marine Parade CC Civil Defence Public Shelter (Community Club/Centre) 278 Marine Parade Road 449282 5 Pasir Ris Elias CC Civil Defence Public Shelter (Community Club/Centre) 93 Pasir Ris Drive 3 519498 6 Tampines West CC Civil Defence Public Shelter (Community Club/Centre) 10 Tampines Street 81 529014 7 Tampines East CC Civil Defence Public Shelter (Community Club/Centre) 10 Tampines Street 23 529341 8 Punggol CC Civil Defence Public Shelter (Community Club/Centre) 3 Hougang Ave 6 538808 9 Teck Ghee CC Civil Defence Public Shelter (Community Club/Centre) 861Singapore Ang Mo 538808 Kio Ave 10 569734 10 Ang Mo Kio CC Civil Defence Public Shelter (Community Club/Centre) 795Singapore Ang Mo 569734 Kio Ave 1 569976 11 Bishan CC Civil Defence Public Shelter (Community Club/Centre) 51 Bishan Street 13 579799 12 Nanyang CC Civil Defence Public Shelter (Community Club/Centre) 60 Jurong West Street 91 649040 13 Jurong Green CC Civil Defence Public Shelter (Community Club/Centre) 6Singapore Jurong West 649040 Ave 1 649520 14 Hong Kah North CC Civil Defence Public Shelter (Community Club/Centre) 30 Bukit Batok Street 31 659440 15 Bukit Batok CC Civil Defence Public Shelter (Community Club/Centre) 21 Bukit Batok -

Duo Towerduo
The Building DUO TOWERDUO A WORKING ENVIRONMENT SCULPTED FOR MODERN BUSINESS. Situated in central Singapore and forming a landmark location in a key growth area, DUO Tower benefits from being part of an integrated masterplan that includes; a boutique retail plaza in DUO Galleria, a 5-star hotel and exclusive DUO Residences. Designed by Ole Scheeren, the architect behind the world famous CCTV building in Beijing, this prime Grade A office development will provide a 24/7 work, live, play solution for all business requirements. 2 3 DUO TOWER OVERVIEW 568,000 sq ft of Prime Grade A Offices The dynamic architecture and scale of the development provides a striking corporate marque and with class leading floor plate sizes combined with innovative design features, DUO Tower delivers an environment that is flexible and engaging. Space for tenants to develop and grow their business where features include: • One of the largest net lettable floor plates in the Bugis micro-market with up to approximately 31,000 sq ft • 3m clear floor to ceiling height • 150mm raised flooring • Knock-out panels for inter-floor connectivity • Exclusive Sky Terrace Garden on Level 8 as alternative recreational point • Outdoor event space and water features set within lush landscaped gardens • Boutique food and beverage and lifestyle retail offerings • 5-star hotel with 352 rooms • Panoramic City Skyline view from observation deck • Bicycle parking lots and shower facilities • BCA Green Mark Platinum Certified One of the largest floor plates in the micro-market Artist’s Impression DUO TOWER 4 5 DUO TOWER 15 MINS Located in Bugis, DUO Tower is positioned LOCATION in the Ophir-Rochor corridor that forms a natural extension to the financial districts of Raffles Place and Marina Bay. -

List of Yamato Singapore Branch Offices, TA-Q-BIN Lockers and 7
Yamato Transport Branch Postal Code Address TA-Q-BIN Lockers Location Postal Code Cheers Store Address Opening Hours Headquarters 119936 61 Alexandra Terrace #05-08 Harbour Link Complex Cheers @ AMK Hub 569933 No. 53 Ang Mo Kio Ave 3 #01-37, AMK Hub 24 hours TA-Q-BIN Branch Close on Fri and Sat Night 119937 63 Alexandra Terrace #04-01 Harbour Link Complex Cheers @ CPF Building 068897 79 Robinson Road CPF Building #01-02 (Parcel Collection) from 11pm to 7am TA-Q-BIN Call Centre 119936 61 Alexandra Terrace #05-08 Harbour Link Complex Cheers @ Toa Payoh Lorong 1 310109 Block 109 #01-310 Toa Payoh Lorong 1 24 hours Takashimaya Shopping Centre,391 Orchard Rd, #B2-201/8B Fairpricexpress Satellite Office 238873 Operation Hour: 10.00am - 9.30pm every day 228149 1 Sophia Road #01-18, Peace Centre 24 hours @ Peace Centre (Subject to Takashimaya operating hours) Air Freight Office 819834 7 Airline Rd #01-14/15, Cargo Agent Building E Cheers @ Concourse Skyline 199600 302 Beach Road #01-01 Concourse Skyline 24 hours Sea Freight Office 099447 Blk 511 Kampong Bahru Rd #02-05, Keppel Distripark Cheers @ 810 Hougang Central 530810 BLK 810 Hougang Central #01-214 24 hours 7am - 11pm (Everday Logistics & Warehouse 119937 63 Alexandra Terrace #04-01 Harbour Link Complex Cheers @ Suntec City 38983 3 Temasek Boulevard, #01-615, Suntec City Mall including PH and weekend) Removal Office 119937 63 Alexandra Terrace #04-01 Harbour Link Complex Cheers @ Zhong Shan Mall 329133 20 Ah Hood Road, #01-06 Zhong Shan Mall 7am to 11pm Cheers @ Ang Mo Kio Avenue 8 569811 -

BUS ROUTES in SINGAPORE Route No
BUS ROUTES IN SINGAPORE Route No. Origin Destination 1N Marina Centre Bus Terminal Yishun Ring Road 2♿ Changi Village Bus Terminal New Bridge Road Bus Terminal 2N Marina Centre Bus Terminal Tampines Avenue 3 3♿ Tampines Bus Interchange !unggol Bus Interchange 3A♿ Tampines Bus Interchange !asir Ris Drive 12 3B♿ !asir Ris Drive 1 !asir Ris Bus Interchange 3N Marina Centre Bus Terminal Choa Chu Kang North $ %N Marina Centre Bus Terminal !asir Ris Drive 1 $♿ Bu&it Merah Bus Interchange !asir Ris Bus Interchange $N Marina Centre Bus Terminal 'urong West Street 92 + !asir Ris Bus Interchange ,o-ang Crescent +N Marina Centre Bus Terminal !unggol Field /♿ Bedok Bus Interchange Clementi Bus Interchange 0 Tampines Bus Interchange Toa Payoh Bus Interchange * Bedok Bus Interchange Changi Airport Cargo Comple1 *A Bedok Bus Interchange ,o-ang Avenue 12♿ Tampines Bus Interchange #ent Ridge Bus Terminal 12e Bedok Road )henton Way 11 3e-lang Lorong 1 Bus Terminal National Stadium 12♿ !asir Ris Bus Interchange New Bridge Road Bus Terminal 13♿ 4pper East Coast Bus Terminal Yio Chu Kang Bus Terminal 13A♿ Ang Mo Kio Avenue 6 Bishan Road 1%♿ Clementi Bus Interchange Bedok Bus Interchange 1%A♿ Bedok Bus Interchange 3range Road 1%e Bedok North Avenue 3 6rchard Road Route No. Origin Destination 1$♿ !asir Ris Bus Interchange Marine Parade Road 1$A♿ !asir Ris Bus Interchange 'alan Eunos 1+♿ Bu&it Merah Bus Interchange Bedok Bus Interchange 1/♿ !asir Ris Bus Interchange Bedok Bus Interchange 1/A Bedok Bus Interchange Bedok North Avenue 4 10♿ Tampines Bus Interchange