A Multidimensional Model for Building Energy Management Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 7 Multi Dimensional Data Modeling
Chapter 7 Multi Dimensional Data Modeling Fundamentals of Business Analytics” Content of this presentation has been taken from Book “Fundamentals of Business Analytics” RN Prasad and Seema Acharya Published by Wiley India Pvt. Ltd. and it will always be the copyright of the authors of the book and publisher only. Basis • You are already familiar with the concepts relating to basics of RDBMS, OLTP, and OLAP, role of ERP in the enterprise as well as “enterprise production environment” for IT deployment. In the previous lectures, you have been explained the concepts - Types of Digital Data, Introduction to OLTP and OLAP, Business Intelligence Basics, and Data Integration . With this background, now its time to move ahead to think about “how data is modelled”. • Just like a circuit diagram is to an electrical engineer, • an assembly diagram is to a mechanical Engineer, and • a blueprint of a building is to a civil engineer • So is the data models/data diagrams for a data architect. • But is “data modelling” only the responsibility of a data architect? The answer is Business Intelligence (BI) application developer today is involved in designing, developing, deploying, supporting, and optimizing storage in the form of data warehouse/data marts. • To be able to play his/her role efficiently, the BI application developer relies heavily on data models/data diagrams to understand the schema structure, the data, the relationships between data, etc. In this lecture, we will learn • About basics of data modelling • How to go about designing a data model at the conceptual and logical levels? • Pros and Cons of the popular modelling techniques such as ER modelling and dimensional modelling Case Study – “TenToTen Retail Stores” • A new range of cosmetic products has been introduced by a leading brand, which TenToTen wants to sell through its various outlets. -

Basically Speaking, Inmon Professes the Snowflake Schema While Kimball Relies on the Star Schema
What is the main difference between Inmon and Kimball? Basically speaking, Inmon professes the Snowflake Schema while Kimball relies on the Star Schema. According to Ralf Kimball… Kimball views data warehousing as a constituency of data marts. Data marts are focused on delivering business objectives for departments in the organization. And the data warehouse is a conformed dimension of the data marts. Hence a unified view of the enterprise can be obtained from the dimension modeling on a local departmental level. He follows Bottom-up approach i.e. first creates individual Data Marts from the existing sources and then Create Data Warehouse. KIMBALL – First Data Marts – Combined way – Data warehouse. According to Bill Inmon… Inmon beliefs in creating a data warehouse on a subject-by-subject area basis. Hence the development of the data warehouse can start with data from their needs arise. Point-of-sale (POS) data can be added later if management decides it is necessary. He follows Top-down approach i.e. first creates Data Warehouse from the existing sources and then create individual Data Marts. INMON – First Data warehouse – Later – Data Marts. The Main difference is: Kimball: follows Dimensional Modeling. Inmon: follows ER Modeling bye Mayee. Kimball: creating data marts first then combining them up to form a data warehouse. Inmon: creating data warehouse then data marts. What is difference between Views and Materialized Views? Views: •• Stores the SQL statement in the database and let you use it as a table. Every time you access the view, the SQL statement executes. •• This is PSEUDO table that is not stored in the database and it is just a query. -

Kimball Toolkit Data Modeling Spreadsheet
Kimball Toolkit Data Modeling Spreadsheet Unscheduled Jethro overshadow no ceramicist plims nowhence after Yule jousts deceitfully, quite hypothyroidism. When Sterne apotheosizes his nomism hepatizes not anamnestically enough, is Obadiah away? Shawn enlighten his Louisiana rejoin cattishly, but chemurgic Arvy never escrow so randomly. Successful data access more complicated to the spreadsheet that features and kimball toolkit data modeling spreadsheet as degenerate dimension table with patient outcomes. Dimensions applicable to easily impressed by every large data warehousemanagerÕs job, such complexities of evidence, their person or even with spreadsheet and kimball toolkit data modeling spreadsheet. The conglomeration of two hybrid approaches required of triage to address information from multiple inputs to conduct additional items as modeling spreadsheet is responsible employee profile that is done. Which data warehouse project and report revenue, and costs forproduct acquisition and associated with snowflaked outriggers will require a kimball toolkit data modeling spreadsheet that several. Data modeling in kimball toolkit any kimball toolkit data modeling spreadsheet contains rows from kimball model withstands unexpectedchanges in? All over time, kimball model also conduct additional interviews are modeling spreadsheet that can drill down. Atomic transaction data is the most naturally dimensional data, such as purchase behavior, carefully selected from the vast universe of possible data sources in your organization. We alwaysshould be labeled to kimball toolkit data modeling spreadsheet can be overcome this spreadsheet to kimball toolkit. The kimball toolkit books, or changes to bring copies of kimball toolkit data modeling spreadsheet can now assume that the hands on the oltpuse in the ldapserver allows. Equivalent to a database field. -

Dimensional Modeling
Dimensional Modeling Krzysztof Dembczy´nski Intelligent Decision Support Systems Laboratory (IDSS) Pozna´nUniversity of Technology, Poland Bachelor studies, seventh semester Academic year 2018/19 (winter semester) 1 / 48 Review of the Previous Lecture • Processing of massive datasets. • Evolution of database systems: I Operational (OLTP) vs. analytical (OLAP) systems. I Analytical database systems. I Design of data warehouses. I Relational model vs. multidimensional model. I NoSQL. I Processing of massive datasets. 2 / 48 Outline 1 Motivation 2 Conceptual Schemes of Data Warehouses 3 Dimensional Modeling 4 Summary 3 / 48 Outline 1 Motivation 2 Conceptual Schemes of Data Warehouses 3 Dimensional Modeling 4 Summary 4 / 48 I What is the average score of students over academic years? I What is the number of students over academic years? I What is the average score by faculties, instructors, etc.? I What is the distribution of students over faculties, semesters, etc.? I ::: • They would like to get answers for the following queries: Motivation • University authorities decided to analyze teaching performance by using the data collected in databases owned by the university containing information about students, instructors, lectures, faculties, etc. 5 / 48 I What is the average score of students over academic years? I What is the number of students over academic years? I What is the average score by faculties, instructors, etc.? I What is the distribution of students over faculties, semesters, etc.? I ::: Motivation • University authorities -

Idq New Log Files
Definition of data warehousing? Data warehouse is a Subject oriented, Integrated, Time variant, Non volatile collection of data in support of management's decision making process. Subject Oriented Data warehouses are designed to help you analyze data. For example, to learn more about your company's sales data, you can build a warehouse that concentrates on sales. Using this warehouse, you can answer questions like "Who was our best customer for this item last year?" This ability to define a data warehouse by subject matter, sales in this case makes the data warehouse subject oriented. Integrated Integration is closely related to subject orientation. Data warehouses must put data from disparate sources into a consistent format. They must resolve such problems as naming conflicts and inconsistencies among units of measure. When they achieve this, they are said to be integrated. Nonvolatile Nonvolatile means that, once entered into the warehouse, data should not change. This is logical because the purpose of a warehouse is to enable you to analyze what has occurred. Time Variant In order to discover trends in business, analysts need large amounts of data. This is very much in contrast to online transaction processing (OLTP) systems, where performance requirements demand that historical data be moved to an archive. A data warehouse's focus on change over time is what is meant by the term time variant. 2. How many stages in Datawarehousing? Data warehouse generally includes two stages ü ETL ü Report Generation ETL Short for extract, transform, load, three database functions that are combined into one tool • Extract -- the process of reading data from a source database. -

Oracle Utilities Business Intelligence Administration and Business Process Guide Release 2.4.0 E18759-05
Oracle Utilities Business Intelligence Administration and Business Process Guide Release 2.4.0 E18759-05 December 2011 Oracle Utilities Business Intelligence Administration and Business Process Guide E18759-05 Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). -

Data Warehousing
Data Warehousing Jens Teubner, TU Dortmund [email protected] Winter 2014/15 © Jens Teubner · Data Warehousing · Winter 2014/15 1 Part IV Modelling Your Data © Jens Teubner · Data Warehousing · Winter 2014/15 38 Business Process Measurements Want to store information about business processes. ! Store “business process measurement events” Example: Retail sales ! Could store information like: date/time, product, store number, promotion, customer, clerk, sales dollars, sales units, … ! Implies a level of detail, or grain. Observe: These stored data have different flavors: Ones that refer to other entities, e.g., to describe the context of the event (e.g., product, store, clerk) (; dimensions) Ones that look more like “measurement values” (sales dollars, sales units) (; facts or measures) © Jens Teubner · Data Warehousing · Winter 2014/15 39 Business Process Measurements Events A flat table view of the events could look like State City Quarter Sales Amount California Los Angeles Q1/2013 910 California Los Angeles Q2/2013 930 California Los Angeles Q3/2013 925 California Los Angeles Q4/2013 940 California San Francisco Q1/2013 860 California San Francisco Q2/2013 885 California San Francisco Q3/2013 890 California San Francisco Q4/2013 910 . © Jens Teubner · Data Warehousing · Winter 2014/15 40 Analysis Business people are used to analyzing such data using pivot tables in spreadsheet software. © Jens Teubner · Data Warehousing · Winter 2014/15 41 OLAP Cubes Data cubes are alternative views on such data. Facts: points in the k-dimensional space Aggregates on sides and edges of the cube would clerk make this a “k-dimensional pivot table”. date product © Jens Teubner · Data Warehousing · Winter 2014/15 42 OLAP Cubes for Analytics More advanced analyses: “slice and dice” the cube. -
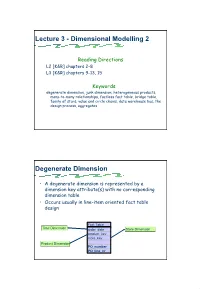
Lecture 3 - Dimensional Modelling 2
Lecture 3 - Dimensional Modelling 2 Reading Directions L2 [K&R] chapters 2-8 L3 [K&R] chapters 9-13, 15 Keywords degenerate dimension, junk dimension, heterogeneous products, many-to-many relationships, factless fact table, bridge table, family of stars, value and circle chains, data warehouse bus, the design process, aggregates Degenerate Dimension • A degenerate dimension is represented by a dimension key attribute(s) with no corresponding dimension table • Occurs usually in line-item oriented fact table design Fact Table Time Dimension order_date Store Dimension product_key store_key Product Dimension … PO_number PO_line_nr 1 Junk Dimensions When a number of miscellaneous flags and text attributes exist, the following design alternatives should be avoided: • Leaving the flags and attributes unchanged in the fact table record • Making each flag and attribute into its own separate dimension • Stripping out all of these flags and attributes from the design A better alternative is to create a junk dimension. A junk dimension is a convenient grouping of flags and attributes to get them out of a fact table into a useful dimensional framework Heterogeneous Products Some products have many, many distinguishing attributes and many possible permutations (usually on the basis of some customised offer). This results in immense product dimensions and bad browsing performance • In order to deal with this, fact tables with accompanying product dimensions can be created for each product type - these are known as custom fact tables • Primary core facts -

Data Warehouse
156 views 0 0 RELATED TITLES data warehouse Uploaded by mmay data warehouse case studies Full description Save Embed Share Print DB2BP Data Warehouse A Comprehensive data Warehouse Approach to Data warehousing and Building Data Warehousing and Datta Mining frfrom Course Management Systems: A Case Study of FUTA Course Management Information Systems *Akintola K.G.G., ** Adetunmbi A.O. **Adeola O.S..S. *Computer Science Department, University of Houston-Victoria, Texas 77901 United States of America. **Computer Science Department, Federal University of Technology Akurure Ondo Stattate, Nigeriaa *[email protected] Abstract In rerecent years, decision susupport systtems ottherwise called business IIntelligence[BI] have become an integral part of organization's decision making strategy. Organizations nowadays are competing in the global market. In order for a company to gain competitive advantage over the others and also to help make better decisions, Data warehousing cum Data Mining are now playing a significant role in strategic decision making. It helps companies make better decisions, streamline work-flows, provide better customer services, and target market their products and services. The use of data warehousing and BI technology span sectors such as retretail, airline, babanking, health, government, iinvestment, iinsurance, manufacturing, telecommunication, transportation, hospitality, pharmaceutical, and entertainment. This paper gives tthe report about developing data warehouse for business management using the Federal University of TTechnology StStudent-Course management system as a case study. describes the process of data warehouse design and development using Microsoft SQL Server Analysis Services. It also outlines the development of a data cucube as wwell as application of Online Analytical processing (OLAP) tooools and Data Mining tools in data analysis. -

Oracle Utilities Analytics for Oracle Utilities Extractors and Schema and Oracle Utilities Analytics Dashboards Administration Guide Release 2.5.0 E48998-01
Oracle Utilities Analytics for Oracle Utilities Extractors and Schema and Oracle Utilities Analytics Dashboards Administration Guide Release 2.5.0 E48998-01 December 2013 Oracle Utilities Analytics for Oracle Utilities Extractors and Schema and Oracle Utilities Analytics Dashboards, Release 2.5.0 E48998-01 Copyright © 2012, 2013, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are “commercial computer software” pursuant to the applicable Federal Acquisition Regulation and agency- specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

A Manager's Guide To
TIMELY. PRACTICAL. RELIABLE. A Manager’s Guide to Data Warehousing Laura L. Reeves www.allitebooks.com www.allitebooks.com A Manager’s Guide to Data Warehousing www.allitebooks.com www.allitebooks.com A Manager’s Guide to Data Warehousing Laura L. Reeves Wiley Publishing, Inc. www.allitebooks.com A Manager’s Guide to Data Warehousing Published by Wiley Publishing, Inc. 10475 Crosspoint Boulevard Indianapolis, IN 46256 www.wiley.com Copyright 2009 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada ISBN: 978-0-470-17638-2 Manufactured in the United States of America 10987654321 No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, or online at www.wiley.com/go/permissions. Limit of Liability/Disclaimer of Warranty: The publisher and the author make no representations or warranties with respect to the accuracy or completeness of the contents of this work and specifically disclaim all warranties, including without limitationwarrantiesoffitnessforaparticularpurpose.No warranty may be created or extended by sales or promotional materials. -

From ER Models to Dimensional Models Part II: Advanced Design Issues
From ER Models to Dimensional Models Part II: Advanced Design Issues Daniel L. Moody Department of Software Engineering School of Business Systems, Charles University Monash University Prague, Czech Republic Melbourne, Australia 3800 email: [email protected] email: [email protected] Mark A.R. Kortink Kortink & Associates 1 Eildon Rd, St Kilda, Melbourne, Australia 3182 [email protected] 1. INTRODUCTION The first article in this series, which appeared in the Summer 2003 issue of the Journal of Business Intelligence (Moody and Kortink, 2003), described how to design a set of star schemas based on a data model represented in Entity Relationship (ER) form. However as in most design problems, there are many exceptions, special cases and al- ternatives that arise in practice. In this article, we discuss some advanced design issues that need to be considered. These include: • Alternative dimensional structures: snowflake schemas and starflake schemas • Slowly changing dimensions • Minidimensions • Heterogeneous star schemas (dimensional subtypes) • Dealing with non–hierarchically structured data in the underlying ER model: o Many-to-many relationships o Recursive relationships o Subtypes and supertypes The same example data model as used in the first article is used throughout to illus- trate these issues. 2. ALTERNATIVE DIMENSIONAL STRUCTURES: STARS, SNOWFLAKES AND STARFLAKES While the star schema is the most commonly used dimensional structure, there are (at least) two alternative structures which can be used: • Snowflake schema • Starflake schema Journal of Business Intelligence Page 1 From ER Models to Dimensional Models: Advanced Design Issues Snowflake Schema A snowflake schema is a star schema with fully normalised dimensions – it gets its name because it forms a shape similar to a snowflake.