Living in a Post- Container World Serverless Architecture Magazine 2019
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

WEIYANG (STEPHEN) YUAN [email protected] | Chicago | 608-504-0649 | Stephenyuan.Urspace.Io Education University of Wisconsin-Madison B.S
WEIYANG (STEPHEN) YUAN [email protected] | Chicago | 608-504-0649 | stephenyuan.urspace.io Education University of Wisconsin-Madison B.S. in Computer Engineering May 2020 ● GPA: 3.83/4.0 ● Related Coursework: Operating Systems • A rtificial Intelligence • Computer Networks and Communication • Databases • Information Security • Big Data Systems • Android Mobile Development Skills ● Programming Languages: Java • Golang • C++ • Scala • MATLAB • SQL • Julia • C • Python ● Technologies: Git, Linux, Java Spring, Amazon Web Services (AWS), MongoDB, Postgres, React, Node.js, Docker, Jenkins, Play Framework, Hadoop, Spark, Wireshark, Visual Studio Experience Enfusion, Chicago Java Software Developer July 2020 - Current ● Develop the portfolio management software system used by over 500 clients that supports a variety of financial calculation and valuation over 20 financial derivatives as well as back office general ledger and cash flow with more than 10,000 daily positions on average ● Take responsibility in the whole development lifecycle from designing (10%), implementing (40%), running regression & unit testing (40%) to supporting internal and production issues (10%) ● Apply experience of Object-Oriented design patterns and best practices to creating a robust and reliable infrastructure for the system with knowledge of Java SE, Hibernate, JMS, JVM and MySQL and deliver constant results in weekly production release ● Automate development and testing frameworks by writing python and shell scripts to improve overall -

A Study of the Effectiveness of Cloud Infrastructure
A STUDY OF THE EFFECTIVENESS OF CLOUD INFRASTRUCTURE CONFIGURATION A Thesis Presented to the Faculty of California State Polytechnic University, Pomona In Partial Fulfillment Of the Requirements for the Degree Master of Science In Computer Science By Bonnie Ngu 2020 SIGNATURE PAGE THESIS: A STUDY OF THE EFFECTIVENESS OF CLOUD INFRASTRUCTURE CONFIGURATION AUTHOR: Bonnie Ngu DATE SUBMITTED: Spring 2020 Department of Computer Science Dr. Gilbert S. Young _______________________________________ Thesis Committee Chair Computer Science Yu Sun, Ph.D _______________________________________ Computer Science Dominick A. Atanasio _______________________________________ Professor Computer Science ii ACKNOWLEDGEMENTS First and foremost, I would like to thank my parents for blessing me with the opportunity to choose my own path. I would also like to thank Dr. Young for all the encouragement throughout my years at Cal Poly Pomona. It was through his excitement and passion for teaching that I found my passion in computer science. Dr. Sun and Professor Atanasio for taking the time to understand my thesis and providing valuable input. Lastly, I would like to thank my other half for always seeing the positive side of things and finding the silver lining. It has been an incredible chapter in my life, and I could not have done it without all the love and moral support from everyone. iii ABSTRACT As cloud providers continuously strive to strengthen their cloud solutions, companies, big and small, are lured by this appealing prospect. Cloud providers aim to take away the trouble of the brick and mortar of physical equipment. Utilizing the cloud can help companies increase efficiency and improve cash flow. -
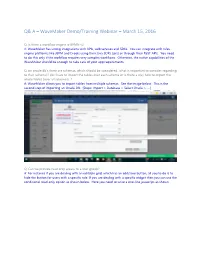
Q& a – Wavemaker Demo/Training Webinar – March 15, 2016
Q& A – WaveMaker Demo/Training Webinar – March 15, 2016 Q: Is there a workflow engine ie BPMN v2 A: WaveMaker has strong integrations with APIs, web services and SDKs. You can integrate with rules engine platforms like JBPM and Drools using their Java SDKs (jars) or through their ReST APIs. You need to do this only if the workflow requires very complex workflows. Otherwise, the native capabilities of the WaveMaker should be enough to take care of your app requirements. Q: on oracle db's there are schemas, which should be considered...what is important to consider regarding to that (schema)? do I have to import the tables over each schema or is there a way how to import the whole tables (over all schemas)...? A: WaveMaker allows you to import tables from multiple schemas. See the image below. This is the second step of importing an Oracle DB. [Steps: Import > Database > Select Oracle > ….] Q: Can we provide read only access to a user group? A: For instance if you are dealing with an editable grid, which has an add/save button, all you to do is to hide the button for users with a specific role. If you are dealing with a specific widget then you can use the conditional read-only option as shown below. Here you need to write a one-line javascript as shown below, where the users with the role “rolename” will be presented a read-only birthdate. Q: Can we integrate the application for SSO ? A: You can configure SSO easily through the following approach. -

Zack Robinson-Android and Amazon Resume.Docx
Contact Innovative, Insightful, Resilient Phone: 814-525-1519 A geek with a gift for gab Email: [email protected] 8 years in Software Development Strengths Summary of Expertise Mobile/TV App Development ▪ Rapidly creates custom features for Android and Amazon Software Engineering Principles applications using UI/UX requirements and mockups Object-Oriented Programming ▪ Particularly comfortable with video playback, location services, (Java) catalog management, authentication, payment processing, and Functional Programming (Kotlin) user management features Refactoring to Design Patterns ▪ Expert at writing clean, re-usable Java and Kotlin code using SOLID principles and software design patterns Data Structures and Algorithms ▪ Adept at reducing operational costs on projects by automating Test-Driven Development quality assurance tasks Technical Communication ▪ Knowledgeable on Android Architecture Components and test Requirements Analysis driven frameworks (MVVM, MVP, etc) Strategic Consulting ▪ Familiar with NFC (Near field communication) technology, Broadcast Receivers and Services, and 3G and Wi-Fi technology. ▪ Adept at storing JSON server responses as data models in device memory (shared preferences, external storage, SQL Lite DB, etc.) ▪ Maintains quality through rigorous code review and testing, and partnerships with QA teams. ▪ Excellent at communicating technical requirements to non-technical stakeholders. ▪ Comfortable working remotely or on-site Technical Skills and Knowledge Languages: Java, Kotlin, Bytecode, XML, SQL, JavaScript, -

Poly Videoos Offer of Source for Open Source Software 3.6.0
OFFER OF SOURCE FOR 3.6.0 | 2021 | 3725-85857-010A OPEN SOURCE SOFTWARE August Poly VideoOS Software Contents Offer of Source for Open Source Software .............................................................................. 1 Open Source Software ............................................................................................................. 2 Qualcomm Platform Licenses ............................................................................................................. 2 List of Open Source Software .................................................................................................. 2 Poly G7500, Poly Studio X50, and Poly Studio X30 .......................................................................... 2 Poly Microphone IP Adapter ............................................................................................................. 13 Poly IP Table Microphone and Poly IP Ceiling Microphone ............................................................. 18 Poly TC8 and Poly Control Application ............................................................................................. 21 Get Help ..................................................................................................................................... 22 Related Poly and Partner Resources ..................................................................................... 22 Privacy Policy ........................................................................................................................... -

A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem
Noname manuscript No. (will be inserted by the editor) A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem César Soto-Valero · Nicolas Harrand · Martin Monperrus · Benoit Baudry Received: date / Accepted: date Abstract Build automation tools and package managers have a profound influence on software development. They facilitate the reuse of third-party libraries, support a clear separation between the application’s code and its ex- ternal dependencies, and automate several software development tasks. How- ever, the wide adoption of these tools introduces new challenges related to dependency management. In this paper, we propose an original study of one such challenge: the emergence of bloated dependencies. Bloated dependencies are libraries that the build tool packages with the application’s compiled code but that are actually not necessary to build and run the application. This phenomenon artificially grows the size of the built binary and increases maintenance effort. We propose a tool, called DepClean, to analyze the presence of bloated dependencies in Maven artifacts. We ana- lyze 9; 639 Java artifacts hosted on Maven Central, which include a total of 723; 444 dependency relationships. Our key result is that 75:1% of the analyzed dependency relationships are bloated. In other words, it is feasible to reduce the number of dependencies of Maven artifacts up to 1=4 of its current count. We also perform a qualitative study with 30 notable open-source projects. Our results indicate that developers pay attention to their dependencies and are willing to remove bloated dependencies: 18/21 answered pull requests were accepted and merged by developers, removing 131 dependencies in total. -

Salesforce Heroku Enterprise: a Cloud Security Overview June 2016
Salesforce Heroku Enterprise: A Cloud Security Overview June 2016 1 Contents INTRODUCTION 3 CASESTUDY:GLIBC 19 Heroku behind the Curtain: Patching SALESFORCETRUSTMODEL 4 the glibc Security Hole What Do We Do When a Security CLOUD COMPUTING AND Vulnerability Lands? THESHAREDSECURITYMODEL 5 Provider Responsibilities How Do We Do This with Minimum Downtime? Tenant Responsibilities What about Data? INFRASTRUCTURE AND What about Heroku Itself? APPLICATIONSECURITY 8 Keep Calm, Carry On Server Hardening Customer Applications BUSINESSCONTINUITY 23 Heroku Platform: High Availability Container Hardening and Disaster Recovery Application Security Customer Applications Heroku Flow Postgres Databases Identity and Access Management Customer Configuration and Identity Federation via Single Sign-On Meta-Information Organizations, Roles, and Permissions Service Resiliency and Availability Business Continuity and Emergency NETWORKSECURITY 14 Preparedness Secure Network Architecture Secure Access Points INCIDENTRESPONSE 27 Data in Motion ELEMENTSMARKETPLACE 28 Private Spaces App Permissions Building Secure Applications with Add-Ons DATASECURITY 16 Heroku Postgres PHYSICALSECURITY 29 Encryption Data Center Access Customer Data Retention and Destruction Environmental Controls Management SECURITYMONITORING 17 Storage Device Decommissioning Logging and Network Monitoring DDoS COMPLIANCEANDAUDIT 31 Man in the Middle and IP Spoofing SUMMARY 33 Patch Management HEROKU ENTERPRISE SECURITY WHITE PAPER 2 Introduction eroku Enterprise, a key component of the Salesforce Platform, is a cloud application platform used by organizations of all sizes to deploy and operate applications throughout Hthe world. The Heroku platform is one of the first cloud application platforms delivered entirely as a service, allowing organizations to focus on application development and business strategy while Salesforce and the Heroku division of Salesforce focus on infrastructure management, scaling, and security. -

Cloud Computing: a Taxonomy of Platform and Infrastructure-Level Offerings David Hilley College of Computing Georgia Institute of Technology
Cloud Computing: A Taxonomy of Platform and Infrastructure-level Offerings David Hilley College of Computing Georgia Institute of Technology April 2009 Cloud Computing: A Taxonomy of Platform and Infrastructure-level Offerings David Hilley 1 Introduction Cloud computing is a buzzword and umbrella term applied to several nascent trends in the turbulent landscape of information technology. Computing in the “cloud” alludes to ubiquitous and inexhaustible on-demand IT resources accessible through the Internet. Practically every new Internet-based service from Gmail [1] to Amazon Web Services [2] to Microsoft Online Services [3] to even Facebook [4] have been labeled “cloud” offerings, either officially or externally. Although cloud computing has garnered significant interest, factors such as unclear terminology, non-existent product “paper launches”, and opportunistic marketing have led to a significant lack of clarity surrounding discussions of cloud computing technology and products. The need for clarity is well-recognized within the industry [5] and by industry observers [6]. Perhaps more importantly, due to the relative infancy of the industry, currently-available product offerings are not standardized. Neither providers nor potential consumers really know what a “good” cloud computing product offering should look like and what classes of products are appropriate. Consequently, products are not easily comparable. The scope of various product offerings differ and overlap in complicated ways – for example, Ama- zon’s EC2 service [7] and Google’s App Engine [8] partially overlap in scope and applicability. EC2 is more flexible but also lower-level, while App Engine subsumes some functionality in Amazon Web Services suite of offerings [2] external to EC2. -

Trifacta Data Preparation for Amazon Redshift and S3 Must Be Deployed Into an Existing Virtual Private Cloud (VPC)
Install Guide for Data Preparation for Amazon Redshift and S3 Version: 7.1 Doc Build Date: 05/26/2020 Copyright © Trifacta Inc. 2020 - All Rights Reserved. CONFIDENTIAL These materials (the “Documentation”) are the confidential and proprietary information of Trifacta Inc. and may not be reproduced, modified, or distributed without the prior written permission of Trifacta Inc. EXCEPT AS OTHERWISE PROVIDED IN AN EXPRESS WRITTEN AGREEMENT, TRIFACTA INC. PROVIDES THIS DOCUMENTATION AS-IS AND WITHOUT WARRANTY AND TRIFACTA INC. DISCLAIMS ALL EXPRESS AND IMPLIED WARRANTIES TO THE EXTENT PERMITTED, INCLUDING WITHOUT LIMITATION THE IMPLIED WARRANTIES OF MERCHANTABILITY, NON-INFRINGEMENT AND FITNESS FOR A PARTICULAR PURPOSE AND UNDER NO CIRCUMSTANCES WILL TRIFACTA INC. BE LIABLE FOR ANY AMOUNT GREATER THAN ONE HUNDRED DOLLARS ($100) BASED ON ANY USE OF THE DOCUMENTATION. For third-party license information, please select About Trifacta from the Help menu. 1. Quick Start . 4 1.1 Install from AWS Marketplace . 4 1.2 Upgrade for AWS Marketplace . 7 2. Configure . 8 2.1 Configure for AWS . 8 2.1.1 Configure for EC2 Role-Based Authentication . 14 2.1.2 Enable S3 Access . 16 2.1.2.1 Create Redshift Connections 28 3. Contact Support . 30 4. Legal 31 4.1 Third-Party License Information . 31 Page #3 Quick Start Install from AWS Marketplace Contents: Product Limitations Internet access Install Desktop Requirements Pre-requisites Install Steps - CloudFormation template SSH Access Troubleshooting SELinux Upgrade Documentation Related Topics This guide steps through the requirements and process for installing Trifacta® Data Preparation for Amazon Redshift and S3 through the AWS Marketplace. -

Cloud Computing Parallel Session Cloud Computing
Cloud Computing Parallel Session Jean-Pierre Laisné Open Source Strategy Bull OW2 Open Source Cloudware Initiative Cloud computing -Which context? -Which road map? -Is it so cloudy? -Openness vs. freedom? -Opportunity for Europe? Cloud in formation Source: http://fr.wikipedia.org/wiki/Fichier:Clouds_edited.jpg ©Bull, 2 ITEA2 - Artemis: Cloud Computing 2010 1 Context 1: Software commoditization Common Specifications Not process specific •Marginal product •Economies of scope differentiation Offshore •Input in many different •Recognized quality end-products or usage standards •Added value is created •Substituable goods downstream Open source •Minimize addition to end-user cost Mature products Volume trading •Marginal innovation Cloud •Economies of scale •Well known production computing •Industry-wide price process levelling •Multiple alternative •Additional margins providers through additional volume Commoditized IT & Internet-based IT usage ©Bull, 3 ITEA2 - Artemis: Cloud Computing 2010 Context 2: The Internet is evolving ©Bull, 4 ITEA2 - Artemis: Cloud Computing 2010 2 New trends, new usages, new business -Apps vs. web pages - Specialized apps vs. HTML5 - Segmentation vs. Uniformity -User “friendly” - Pay for convenience -New devices - Phones, TV, appliances, etc. - Global economic benefits of the Internet - 2010: $1.5 Trillion - 2020: $3.8 Trillion Information Technology and Innovation Foundation (ITIF) Long live the Internet ©Bull, 5 ITEA2 - Artemis: Cloud Computing 2010 Context 3: Cloud on peak of inflated expectations According to -

The Line Download Torrent Spec Ops: the Line Torrent PC Game Free Download
the line download torrent Spec Ops: The Line Torrent PC Game Free Download. Spec Ops: The Line Download For PC. Spec Ops: The Line Download For PC is an action shooter game, That you will play from the point of view of a third person. It is the 10th game in the series of Spec Ops games. The game is set in a virtual open world. And is based on war battels. This game has both single-player and multiplayer modes. Furthermore, it also has an online multiplayer mode. The main character of the game is Captain Martin. In the game, the captain was given a mission after the end of the war. The mission is called the Recon mission. Captain Martin creates his force and goes for the mission. Gameplay Of Spec Ops: The Line Highly Compressed. Gameplay Of Spec Ops: The Line Highly Compressed is like war battels gameplay. In which players take control of the main character Captian Martin. The gameplay is set on different levels. The main four difficult missions of the game are Fubar, Combat Op, Walk on the beach, and a Suicide mission. At the start of the game, the player can select only one mission to play. As he passes on a mission then he can unlock other missions. This game also includes various types of powerful weapons. That also helps the player to fight against enemies. The weapons include pistols, Machine guns firearms, and many more. But the player can take two weapons at a time. And can quickly change them during the fight. -

OFS Crime and Compliance Studio Kubernetes Installation Guide Copyright © 2021 Oracle And/Or Its Affiliates
Oracle Financial Services Crime and Complaince Studio Installation Guide Release 8.0.8.2.0 January 2021 E91246-01 OFS Crime and Compliance Studio Kubernetes Installation Guide Copyright © 2021 Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error- free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are “commercial computer software” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs.