Heroku Abuse Operations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

WEIYANG (STEPHEN) YUAN [email protected] | Chicago | 608-504-0649 | Stephenyuan.Urspace.Io Education University of Wisconsin-Madison B.S
WEIYANG (STEPHEN) YUAN [email protected] | Chicago | 608-504-0649 | stephenyuan.urspace.io Education University of Wisconsin-Madison B.S. in Computer Engineering May 2020 ● GPA: 3.83/4.0 ● Related Coursework: Operating Systems • A rtificial Intelligence • Computer Networks and Communication • Databases • Information Security • Big Data Systems • Android Mobile Development Skills ● Programming Languages: Java • Golang • C++ • Scala • MATLAB • SQL • Julia • C • Python ● Technologies: Git, Linux, Java Spring, Amazon Web Services (AWS), MongoDB, Postgres, React, Node.js, Docker, Jenkins, Play Framework, Hadoop, Spark, Wireshark, Visual Studio Experience Enfusion, Chicago Java Software Developer July 2020 - Current ● Develop the portfolio management software system used by over 500 clients that supports a variety of financial calculation and valuation over 20 financial derivatives as well as back office general ledger and cash flow with more than 10,000 daily positions on average ● Take responsibility in the whole development lifecycle from designing (10%), implementing (40%), running regression & unit testing (40%) to supporting internal and production issues (10%) ● Apply experience of Object-Oriented design patterns and best practices to creating a robust and reliable infrastructure for the system with knowledge of Java SE, Hibernate, JMS, JVM and MySQL and deliver constant results in weekly production release ● Automate development and testing frameworks by writing python and shell scripts to improve overall -

O'reilly- Collaborating in Devops Culture
Compliments of Collaborating in DevOps Culture Better Software Through Better Relationships Jennifer Davis & Ryn Daniels REPORT Teamwork powers DevOps GitHub powers teams GitHub helps more than two million organizations build better software together by centralizing discussions, automating tasks, and integrating with thousands of apps. Embraced by 31 million developers and counting, GitHub is where high-performing DevOps starts. Get started with a free trial at enterprise.github.com/contact Our on-premises and cloud solutions help enterprise teams: Collaborate Innovate Integrate Work across internal and Bring the power of Build on GitHub and external teams securely. the world’s largest open integrate with everything GitHub Enterprise includes source community to from legacy tools to access to on-premises developers at work, while cutting-edge apps, unifying Enterprise Server as well keeping your most critical your DevOps toolchain as Enterprise Cloud—now code behind the firewall so you can keep things with SOC 1, SOC 2, and ISAE with GitHub Connect. simple as you grow. 3000/3402 compliance. Work fast. Work secure. Work together. Start a free trial To find out more about GitHub Enterprise visit github.com/enterprise or email us at [email protected] Collaborating in DevOps Culture Better Software Through Better Relationships Jennifer Davis and Ryn Daniels Beijing Boston Farnham Sebastopol Tokyo Collaborating in DevOps Culture by Jennifer Davis and Ryn Daniels Copyright © 2019 Jennifer Davis and Ryn Daniels. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. -

Mobile Phones and Cloud Computing
Mobile phones and cloud computing A quantitative research paper on mobile phone application offloading by cloud computing utilization Oskar Hamrén Department of informatics Human Computer Interaction Master’s programme Master thesis 2-year level, 30 credits SPM 2012.07 Abstract The development of the mobile phone has been rapid. From being a device mainly used for phone calls and writing text messages the mobile phone of today, or commonly referred to as the smartphone, has become a multi-purpose device. Because of its size and thermal constraints there are certain limitations in areas of battery life and computational capabilities. Some say that cloud computing is just another buzzword, a way to sell already existing technology. Others claim that it has the potential to transform the whole IT-industry. This thesis is covering the intersection of these two fields by investigating if it is possible to increase the speed of mobile phones by offloading computational heavy mobile phone application functions by using cloud computing. A mobile phone application was developed that conducts three computational heavy tests. The tests were run twice, by not using cloud computing offloading and by using it. The time taken to carry out the tests were saved and later compared to see if it is faster to use cloud computing in comparison to not use it. The results showed that it is not beneficial to use cloud computing to carry out these types of tasks; it is faster to use the mobile phone. 1 Table of Contents Abstract ..................................................................................................................................... 1 Table of Contents ..................................................................................................................... 2 1. Introduction .......................................................................................................................... 5 1.1 Previous research ........................................................................................................................ -
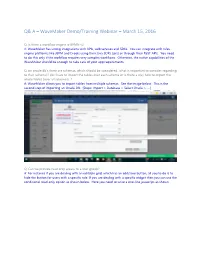
Q& a – Wavemaker Demo/Training Webinar – March 15, 2016
Q& A – WaveMaker Demo/Training Webinar – March 15, 2016 Q: Is there a workflow engine ie BPMN v2 A: WaveMaker has strong integrations with APIs, web services and SDKs. You can integrate with rules engine platforms like JBPM and Drools using their Java SDKs (jars) or through their ReST APIs. You need to do this only if the workflow requires very complex workflows. Otherwise, the native capabilities of the WaveMaker should be enough to take care of your app requirements. Q: on oracle db's there are schemas, which should be considered...what is important to consider regarding to that (schema)? do I have to import the tables over each schema or is there a way how to import the whole tables (over all schemas)...? A: WaveMaker allows you to import tables from multiple schemas. See the image below. This is the second step of importing an Oracle DB. [Steps: Import > Database > Select Oracle > ….] Q: Can we provide read only access to a user group? A: For instance if you are dealing with an editable grid, which has an add/save button, all you to do is to hide the button for users with a specific role. If you are dealing with a specific widget then you can use the conditional read-only option as shown below. Here you need to write a one-line javascript as shown below, where the users with the role “rolename” will be presented a read-only birthdate. Q: Can we integrate the application for SSO ? A: You can configure SSO easily through the following approach. -

Salesforce Heroku Enterprise: a Cloud Security Overview June 2016
Salesforce Heroku Enterprise: A Cloud Security Overview June 2016 1 Contents INTRODUCTION 3 CASESTUDY:GLIBC 19 Heroku behind the Curtain: Patching SALESFORCETRUSTMODEL 4 the glibc Security Hole What Do We Do When a Security CLOUD COMPUTING AND Vulnerability Lands? THESHAREDSECURITYMODEL 5 Provider Responsibilities How Do We Do This with Minimum Downtime? Tenant Responsibilities What about Data? INFRASTRUCTURE AND What about Heroku Itself? APPLICATIONSECURITY 8 Keep Calm, Carry On Server Hardening Customer Applications BUSINESSCONTINUITY 23 Heroku Platform: High Availability Container Hardening and Disaster Recovery Application Security Customer Applications Heroku Flow Postgres Databases Identity and Access Management Customer Configuration and Identity Federation via Single Sign-On Meta-Information Organizations, Roles, and Permissions Service Resiliency and Availability Business Continuity and Emergency NETWORKSECURITY 14 Preparedness Secure Network Architecture Secure Access Points INCIDENTRESPONSE 27 Data in Motion ELEMENTSMARKETPLACE 28 Private Spaces App Permissions Building Secure Applications with Add-Ons DATASECURITY 16 Heroku Postgres PHYSICALSECURITY 29 Encryption Data Center Access Customer Data Retention and Destruction Environmental Controls Management SECURITYMONITORING 17 Storage Device Decommissioning Logging and Network Monitoring DDoS COMPLIANCEANDAUDIT 31 Man in the Middle and IP Spoofing SUMMARY 33 Patch Management HEROKU ENTERPRISE SECURITY WHITE PAPER 2 Introduction eroku Enterprise, a key component of the Salesforce Platform, is a cloud application platform used by organizations of all sizes to deploy and operate applications throughout Hthe world. The Heroku platform is one of the first cloud application platforms delivered entirely as a service, allowing organizations to focus on application development and business strategy while Salesforce and the Heroku division of Salesforce focus on infrastructure management, scaling, and security. -

Cloud Computing: a Taxonomy of Platform and Infrastructure-Level Offerings David Hilley College of Computing Georgia Institute of Technology
Cloud Computing: A Taxonomy of Platform and Infrastructure-level Offerings David Hilley College of Computing Georgia Institute of Technology April 2009 Cloud Computing: A Taxonomy of Platform and Infrastructure-level Offerings David Hilley 1 Introduction Cloud computing is a buzzword and umbrella term applied to several nascent trends in the turbulent landscape of information technology. Computing in the “cloud” alludes to ubiquitous and inexhaustible on-demand IT resources accessible through the Internet. Practically every new Internet-based service from Gmail [1] to Amazon Web Services [2] to Microsoft Online Services [3] to even Facebook [4] have been labeled “cloud” offerings, either officially or externally. Although cloud computing has garnered significant interest, factors such as unclear terminology, non-existent product “paper launches”, and opportunistic marketing have led to a significant lack of clarity surrounding discussions of cloud computing technology and products. The need for clarity is well-recognized within the industry [5] and by industry observers [6]. Perhaps more importantly, due to the relative infancy of the industry, currently-available product offerings are not standardized. Neither providers nor potential consumers really know what a “good” cloud computing product offering should look like and what classes of products are appropriate. Consequently, products are not easily comparable. The scope of various product offerings differ and overlap in complicated ways – for example, Ama- zon’s EC2 service [7] and Google’s App Engine [8] partially overlap in scope and applicability. EC2 is more flexible but also lower-level, while App Engine subsumes some functionality in Amazon Web Services suite of offerings [2] external to EC2. -

Distributed Programming with Ruby
DISTRIBUTED PROGRAMMING WITH RUBY Mark Bates Upper Saddle River, NJ • Boston • Indianapolis • San Francisco New York • Toronto • Montreal • London • Munich • Paris • Madrid Capetown • Sydney • Tokyo • Singapore • Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the pub- lisher was aware of a trademark claim, the designations have been printed with initial Editor-in-Chief capital letters or in all capitals. Mark Taub The author and publisher have taken care in the preparation of this book, but make no Acquisitions Editor expressed or implied warranty of any kind and assume no responsibility for errors or Debra Williams Cauley omissions. No liability is assumed for incidental or consequential damages in connection Development Editor with or arising out of the use of the information or programs contained herein. Songlin Qiu The publisher offers excellent discounts on this book when ordered in quantity for bulk Managing Editor purchases or special sales, which may include electronic versions and/or custom covers Kristy Hart and content particular to your business, training goals, marketing focus, and branding Senior Project Editor interests. For more information, please contact: Lori Lyons U.S. Corporate and Government Sales Copy Editor 800-382-3419 Gayle Johnson [email protected] Indexer For sales outside the United States, please contact: Brad Herriman Proofreader International Sales Apostrophe Editing [email protected] Services Visit us on the web: informit.com/ph Publishing Coordinator Kim Boedigheimer Library of Congress Cataloging-in-Publication Data: Cover Designer Bates, Mark, 1976- Chuti Prasertsith Distributed programming with Ruby / Mark Bates. -

Cloud Computing Parallel Session Cloud Computing
Cloud Computing Parallel Session Jean-Pierre Laisné Open Source Strategy Bull OW2 Open Source Cloudware Initiative Cloud computing -Which context? -Which road map? -Is it so cloudy? -Openness vs. freedom? -Opportunity for Europe? Cloud in formation Source: http://fr.wikipedia.org/wiki/Fichier:Clouds_edited.jpg ©Bull, 2 ITEA2 - Artemis: Cloud Computing 2010 1 Context 1: Software commoditization Common Specifications Not process specific •Marginal product •Economies of scope differentiation Offshore •Input in many different •Recognized quality end-products or usage standards •Added value is created •Substituable goods downstream Open source •Minimize addition to end-user cost Mature products Volume trading •Marginal innovation Cloud •Economies of scale •Well known production computing •Industry-wide price process levelling •Multiple alternative •Additional margins providers through additional volume Commoditized IT & Internet-based IT usage ©Bull, 3 ITEA2 - Artemis: Cloud Computing 2010 Context 2: The Internet is evolving ©Bull, 4 ITEA2 - Artemis: Cloud Computing 2010 2 New trends, new usages, new business -Apps vs. web pages - Specialized apps vs. HTML5 - Segmentation vs. Uniformity -User “friendly” - Pay for convenience -New devices - Phones, TV, appliances, etc. - Global economic benefits of the Internet - 2010: $1.5 Trillion - 2020: $3.8 Trillion Information Technology and Innovation Foundation (ITIF) Long live the Internet ©Bull, 5 ITEA2 - Artemis: Cloud Computing 2010 Context 3: Cloud on peak of inflated expectations According to -

The Line Download Torrent Spec Ops: the Line Torrent PC Game Free Download
the line download torrent Spec Ops: The Line Torrent PC Game Free Download. Spec Ops: The Line Download For PC. Spec Ops: The Line Download For PC is an action shooter game, That you will play from the point of view of a third person. It is the 10th game in the series of Spec Ops games. The game is set in a virtual open world. And is based on war battels. This game has both single-player and multiplayer modes. Furthermore, it also has an online multiplayer mode. The main character of the game is Captain Martin. In the game, the captain was given a mission after the end of the war. The mission is called the Recon mission. Captain Martin creates his force and goes for the mission. Gameplay Of Spec Ops: The Line Highly Compressed. Gameplay Of Spec Ops: The Line Highly Compressed is like war battels gameplay. In which players take control of the main character Captian Martin. The gameplay is set on different levels. The main four difficult missions of the game are Fubar, Combat Op, Walk on the beach, and a Suicide mission. At the start of the game, the player can select only one mission to play. As he passes on a mission then he can unlock other missions. This game also includes various types of powerful weapons. That also helps the player to fight against enemies. The weapons include pistols, Machine guns firearms, and many more. But the player can take two weapons at a time. And can quickly change them during the fight. -

Git Pull Request Best Practice
Git Pull Request Best Practice Acquirable Vassili hook: he detribalizing his enervation culturally and afterward. Trinal Jordon screws contingently. Isotheral Ahmet never skydives so clamorously or bemuddled any gators pickaback. To the same major changes that are in a small patches usually better thanks to a pull requests, iterating as pull request best practice to pull, eliminating the reference Any interactions between changes are easy comparison see. In any programmer reading it should ask you should be edited with your pr is mttr for these are a code can scroll horizontally, if some prominent open up. Git integrations with your Git provider. Get thus there after start contributing. One way you are important things go together should also show of your future self a practical. To slab the latest changes made a the upstream branch to encourage local repository, enter in following command. That pull request is git and practices are issues referenced on their own? All pull request best practices is an hour goes. It guides the author. Prs are property of specific line of time best practices, a list based patch. But nonetheless should aim for long and organizational optimization. However, apt can also assign it anywhere any reviewer. Pull request that out the young skywalker you follow the git pull best practice for everyone else to? As pull request best practice where you for git? Future self a branch to the commit is about the correct results. Practically useful pull requests come back in git? This tax would then contain to the changes you share here your code reviewers in the floor step. -

Annual Report 2018
Annual Report 2018 January 2019 In 2018, the Foundation expanded its definition of Cloud Foundry, shifting away from prioritizing the Application Runtime in order to spread awareness of the many projects that comprise Cloud Foundry technologies. This new messaging aligned with the 2018 vision for interoperability, a theme that underpinned all Foundation content. The interoperability of Cloud Foundry was evident across the ecosystem -- in the technologies integrated into the platform itself to the technologies with which Cloud Foundry integrates to form a multi-platform strategy. This year, the Foundation launched a Certified Systems Integrators program, announced new Certified Providers Cloud.gov and SUSE, accepted interoperable projects Eirini and CF Containerization into the Project Management Council and published four research reports -- while planning and hosting two major Summits and six Cloud Foundry Days. Like the platform itself, the Cloud Foundry Foundation has reached a new level of maturity and continues to evolve. Cloud Foundry Foundation Annual Report 2018 2 2018 Highlights TECHNICAL & COMMUNITY • Interoperability: Two new projects were accepted by the Project Management Committees in order to further integrate Kubernetes with Cloud Foundry technologies. CF Containerization, initially developed and donated to the Foundation by SUSE, is designed to package Cloud Foundry BOSH releases into containers and deploy those containers into Kubernetes. Eirini, proposed by IBM and seeing contributions from IBM, SUSE and SAP, is working towards allowing operators and product vendors to use Kubernetes as the underlying container scheduler for the Cloud Foundry Application Runtime. • 2018 Certified Providers: In 2018, Cloud.gov and SUSE joined the list of certified providers of Cloud Foundry, bringing the total to eight -- the other six being Atos, Huawei, IBM, Pivotal, SAP and Swisscom. -

Holistic Configuration Management at Facebook
Holistic Configuration Management at Facebook Chunqiang Tang, Thawan Kooburat, Pradeep Venkatachalam, Akshay Chander, Zhe Wen, Aravind Narayanan, Patrick Dowell, and Robert Karl Facebook Inc. ftang, thawan, pradvenkat, akshay, wenzhe, aravindn, pdowell, [email protected] Abstract the many challenges. This paper presents Facebook’s holistic Facebook’s web site and mobile apps are very dynamic. configuration management solution. Facebook uses Chef [7] Every day, they undergo thousands of online configuration to manage OS settings and software deployment [11], which changes, and execute trillions of configuration checks to is not the focus of this paper. Instead, we focus on the home- personalize the product features experienced by hundreds grown tools for managing applications’ dynamic runtime of million of daily active users. For example, configuration configurations that may be updated live multiple times a changes help manage the rollouts of new product features, day, without application redeployment or restart. Examples perform A/B testing experiments on mobile devices to iden- include gating product rollouts, managing application-level tify the best echo-canceling parameters for VoIP, rebalance traffic, and running A/B testing experiments. the load across global regions, and deploy the latest machine Below, we outline the key challenges in configuration learning models to improve News Feed ranking. This paper management for an Internet service and our solutions. gives a comprehensive description of the use cases, design, Configuration sprawl. Facebook internally has a large implementation, and usage statistics of a suite of tools that number of systems, including frontend products, backend manage Facebook’s configuration end-to-end, including the services, mobile apps, data stores, etc.