JXTA Protocols • JXTA Goals
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Planning Guide
Oracle AutoVue 20.2, Client/Server Deployment Planning Guide March 2012 Copyright © 1999, 2012, Oracle and/or its affiliates. All rights reserved. Portions of this software Copyright 1996-2007 Glyph & Cog, LLC. Portions of this software Copyright Unisearch Ltd, Australia. Portions of this software are owned by Siemens PLM © 1986-2012. All rights reserved. This software uses ACIS® software by Spatial Technology Inc. ACIS® Copyright © 1994-2008 Spatial Technology Inc. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Govern- ment, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "com- mercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency- specific supplemental regulations. -

Dynamic Integration of Mobile JXTA with Cloud Computing for Emergency Rural Public Health Care
Osong Public Health Res Perspect 2013 4(5), 255e264 http://dx.doi.org/10.1016/j.phrp.2013.09.004 pISSN 2210-9099 eISSN 2233-6052 - ORIGINAL ARTICLE - Dynamic Integration of Mobile JXTA with Cloud Computing for Emergency Rural Public Health Care Rajasekaran Rajkumar*, Nallani Chackravatula Sriman Narayana Iyengar School of Computing Science and Engineering, VIT University, Vellore, India. Received: August 21, Abstract 2013 Objectives: The existing processes of health care systems where data collection Revised: August 30, requires a great deal of labor with high-end tasks to retrieve and analyze in- 2013 formation, are usually slow, tedious, and error prone, which restrains their Accepted: September clinical diagnostic and monitoring capabilities. Research is now focused on 3, 2013 integrating cloud services with P2P JXTA to identify systematic dynamic process for emergency health care systems. The proposal is based on the concepts of a KEYWORDS: community cloud for preventative medicine, to help promote a healthy rural ambulance alert alarm, community. We investigate the approaches of patient health monitoring, emergency care, and an ambulance alert alarm (AAA) under mobile cloud-based cloud, telecare or community cloud controller systems. JXTA, Methods: Considering permanent mobile users, an efficient health promotion mHealth, method is proposed. Experiments were conducted to verify the effectiveness of P2P the method. The performance was evaluated from September 2011 to July 2012. A total of 1,856,454 cases were transported and referred to hospital, identified with health problems, and were monitored. We selected all the peer groups and the control server N0 which controls N1,N2, and N3 proxied peer groups. -

Solving Quarto with JXTA and JNGI
Solving Quarto with JXTA and JNGI Matthew Shepherd University of Texas at Austin Abstract. This paper presents an implementation of a grid-based autonomous quarto player. The implementation uses the JNGI framework which itself is written on top of JXTA. 1 Introduction Quarto is a game reminiscent of tic-tac-toe. It is played with sixteen unique pieces on a four-by-four square board. Each piece is large or small, black or white, solid or hollow and square or round. The game begins with an empty board and all sixteen pieces available. Two players take successive turns with the first player choosing an available piece. That piece is given to the second player who places it on an empty spot on the board. The roles reverse and the process repeats. A player wins by placing the final piece in a row, column or diagonal where all four pieces have at least one attribute in common. For example, the winner might place a piece that completes a row of four black pieces or a column of four round pieces. My goal was to write an implementation of the game and an autonomous program for a human player to compete against. The program performs an exhaustive search of possible moves in order to find the most appropriate one. If the program were to perform the search on the first move of the game, the sixteen available pieces and sixteen empty squares would combine to produce a (16!)^2 search space. Eliminating the moves that take place after a game has already been won reduces that number, but a single processor would still not be sufficient to perform such a task in a reasonable amount of time. -

Extensions of JADE and JXTA for Implementing a Distributed System
EXTENSIONS OF JADE AND JXTA FOR IMPLEMENTING A DISTRIBUTED SYSTEM Edward Kuan-Hua Chen A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF APPLIED SCIENCE School of Engineering Science O Edward Kuan-Hua Chen 2005 SIMON FRASER UNIVERSITY Spring 2005 All rights reserved. This work may not be reproduced in whole or in part, by photocopy or other means, without the permission of the author. APPROVAL Edward Kuan-Hua Chen Master of Applied Science Extensions of JADE and JXTA for Implementing a Distributed System EXAMINING COMMITTEE Chair: John Jones Professor, School of Engineering Science William A. Gruver Academic Supervisor Professor, School of Engineering Science Dorian Sabaz Technical Supervisor Chief Technology Officer Intelligent Robotics Corporation Shaohong Wu External Examiner National Research Council Date Approved: April 8, 2004 SIMON FRASER UNIVERSITY PARTIAL COPYRIGHT LICENCE The author, whose copyright is declared on the title page of this work, has granted to Simon Fraser University the right to lend this thesis, project or extended essay to users of the Simon Fraser University Library, and to make partial or single copies only for such users or in response to a request from the library of any other university, or other educational institution, on its own behalf or for one of its users. The author has further granted permission to Simon Fraser University to keep or make a digital copy for use in its circulating collection. The author has further agreed that permission for multiple copying of this work for scholarly purposes may be granted by either the author or the Dean of Graduate Studies. -

Peer-To-Peer Virtualized Services
International Journal on Advances in Internet Technology, vol 4 no 3 & 4, year 2011, http://www.iariajournals.org/internet_technology/ 89 Peer-to-Peer Virtualized Services David Bailey and Kevin Vella University of Malta Msida, Malta Email: [email protected], [email protected] Abstract—This paper describes the design and operation advance a rethink of general purpose operating system of a peer-to-peer framework for providing, locating and architecture. consuming distributed services that are encapsulated within The performance hit commonly associated with virtual- virtual machines. We believe that the decentralized nature of peer-to-peer networks acting in tandem with techniques such ization has been partly addressed on commodity computers as live virtual machine migration and replication facilitate by recent modifications to the x86 architecture [3], with both scalable and on-demand provision of services. Furthermore, AMD and Intel announcing specifications for integrating the use of virtual machines eases the deployment of a wide IOMMUs (Input/Output Memory Management Units) with range of legacy systems that may subsequently be exposed upcoming architectures. While this largely resolves the issue through the framework. To illustrate the feasibility of running distributed services within virtual machines, several computa- of computational slow-down and simplifies hypervisor de- tional benchmarks are executed on a compute cluster running sign, virtualized I/O performance will remain mostly below our framework, and their performance characteristics are par until I/O devices are capable of holding direct and evaluated. While I/O-intensive benchmarks suffer a penalty concurrent conversations with several virtual machines on due to virtualization-related limitations in the prevailing I/O the same host. -
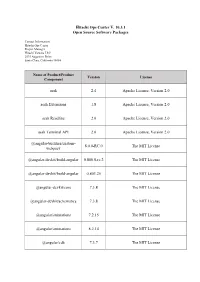
Open Source Software Packages
Hitachi Ops Center V. 10.3.1 Open Source Software Packages Contact Information: Hitachi Ops Center Project Manager Hitachi Vantara LLC 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component aesh 2.4 Apache License, Version 2.0 aesh Extensions 1.8 Apache License, Version 2.0 aesh Readline 2.0 Apache License, Version 2.0 aesh Terminal API 2.0 Apache License, Version 2.0 @angular-builders/custom- 8.0.0-RC.0 The MIT License webpack @angular-devkit/build-angular 0.800.0-rc.2 The MIT License @angular-devkit/build-angular 0.803.25 The MIT License @angular-devkit/core 7.3.8 The MIT License @angular-devkit/schematics 7.3.8 The MIT License @angular/animations 7.2.15 The MIT License @angular/animations 8.2.14 The MIT License @angular/cdk 7.3.7 The MIT License Name of Product/Product Version License Component @angular/cli 8.0.0 The MIT License @angular/cli 8.3.25 The MIT License @angular/common 7.2.15 The MIT License @angular/common 8.2.14 The MIT License @angular/compiler 7.2.15 The MIT License @angular/compiler 8.2.14 The MIT License @angular/compiler-cli 8.2.14 The MIT License @angular/core 7.2.15 The MIT License @angular/forms 7.2.13 The MIT License @angular/forms 7.2.15 The MIT License @angular/forms 8.2.14 The MIT License @angular/forms 8.2.7 The MIT License @angular/language-service 8.2.14 The MIT License @angular/platform-browser 7.2.15 The MIT License @angular/platform-browser 8.2.14 The MIT License Name of Product/Product Version License Component @angular/platform-browser- 7.2.15 The MIT License -

Decentralized Grid Services on P2P Networks: a Case Study
Decentralized Grid Services on P2P Networks: A Case Study FREDRIK SÖDERSTRÖM Master of Science Thesis Stockholm, Sweden 2005 IMIT/LECS-2005-05 Decentralized Grid Services on P2P Networks: A Case Study FREDRIK SÖDERSTRÖM Exam iner Assoc. Prof. Vladim ir Vlassov (IM IT/KTH) Master of Science Thesis Stockholm, Sweden 2005 IMIT/LECS-2005-05 Abstract Computers have been connected to networks for a long time. Traditional networks usually provide only simple services. To keep up with the ever- increasing demand for computing resources, like processing power and storage, there is a need to leverage more power from existing networks. One way of managing all resources of large networks, and letting multiple organizations share these resources with each other, is called Grid comput- ing. In this thesis, we examine one of the services that is necessary for a Grid, namely resource discovery, a mechanism for finding the available re- sources on a network. Resource discovery services are often designed to rely on some kind of central repository where all resources must be regis- tered. But this approach does not work well in very large networks, be- cause the central repository will become a bottleneck. Resource discovery can also be decentralized, and we suggest that it should be built on peer-to- peer technology to achieve maximum scalability. Using JXTA, a peer-to- peer platform, and the Globus Toolkit for Grid services, we create and evaluate a prototype implementation of a distributed discovery service. Acknowledgments I would like to thank my father, Håkan Söderström, for helping me with a number of bugs and reading drafts of the report. -

CA Server Automation Release Notes, See the Bookshelf at CA Support Online
CA Server Automation Release Notes Release 12.8 This Documentation, which includes embedded help systems and electronically distributed materials, (hereinafter referred to as the “Documentation”) is for your informational purposes only and is subject to change or withdrawal by CA at any time. This Documentation may not be copied, transferred, reproduced, disclosed, modified or duplicated, in whole or in part, without the prior written consent of CA. This Documentation is confidential and proprietary information of CA and may not be disclosed by you or used for any purpose other than as may be permitted in (i) a separate agreement between you and CA governing your use of the CA software to which the Documentation relates; or (ii) a separate confidentiality agreement between you and CA. Notwithstanding the foregoing, if you are a licensed user of the software product(s) addressed in the Documentation, you may print or otherwise make available a reasonable number of copies of the Documentation for internal use by you and your employees in connection with that software, provided that all CA copyright notices and legends are affixed to each reproduced copy. The right to print or otherwise make available copies of the Documentation is limited to the period during which the applicable license for such software remains in full force and effect. Should the license terminate for any reason, it is your responsibility to certify in writing to CA that all copies and partial copies of the Documentation have been returned to CA or destroyed. TO THE EXTENT PERMITTED BY APPLICABLE LAW, CA PROVIDES THIS DOCUMENTATION “AS IS” WITHOUT WARRANTY OF ANY KIND, INCLUDING WITHOUT LIMITATION, ANY IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, OR NONINFRINGEMENT. -

Project JXTA Technology Overview
PPrroojjeecctt JXTJXTAA TTeecchhnnoollooggyy OOveverrvviieeww Dr Simon See Technical Director Asia Pacific Science & Technology Center www.jxta.org Sun Microsystems Inc. The Time Is Right for P2P and Project JXTA Peer-to-Peer (P2P) is not new. However, the time is now right for the broad P2P applications deployment. The Project JXTA technology lets developers build and deploy P2P solutions more quickly. Topics • Peer-to-Peer computing • Project JXTA technology • Project JXTA today • Future directions What Is Peer-to-Peer (P2P)? • P2P covers a wide range of applications… – Sharing files, distributed search and indexing – Sharing CPU and storage resources – Instant messaging & devices communicating together – Collaborative work (and games) – Web services – New forms of content distribution, sharing, and delivery • P2P is not… – New or a specific architecture, technology, business model, or market – About eliminating servers or centralized services PP22PP iiss aabboouutt aannyy ddeevviiccee eeaassiillyy ccoonnnneeccttiinngg ““ddiirreeccttllyy”” ttoo ootthheerr ddeevviicceess ttoo eennaabbllee aa mmoorree ccooooppeerraattiivvee,, oorr ssoocciiaall,, ssttyyllee ooff ccoommppuuttiinngg.. P2P Makes Sense Now • More people connected, more Network Computing Explosion data generated Everythiing that touches • More nodes on the Internet the network iis growiing Devices and wireless Web at an exponential rate Data • More bandwidth available Users Services • More computing power Transactions Bandwidth available (disk, memory, CPU) Use of the Network/ -

Java Everywhere
Java Everywhere Simon Ritter Technology Evangelist Sun Microsystems, Inc. Agenda ● Data & Web Services ● The Sun Java Enterprise System ● Future Directions For Java – Ease of Development ● Summary Things - 1014 Embedded Computers Waves of the Internet 11 10 TThheerrmmoossttatatss CCararss Switches Computers TVs 8 Packages 10 PPhohoneness GGamameess Clothes Desktops Clients Functions Transfers Transactions Content Telemetry CControol IP v4 IP Layer IP v6 Protocols Organization Things - 1014 Embedded Computers Waves of the Internet 11 10 Thermostats CCararss SSwwiittcchehess Computers TVs 8 Packages 10 PPhohoneness GGamameess Clothes Desktops Clients Functions Transfers Transactions Content Telemetry Control IP v4 IP Layer IP v6 Protocols FTP SMTP X RMI/IIOP RPC/XDR Identity LDAP Identity Organization Telnet HTTP SOAP Jini Client/Server UDDI JXTA N-tier Web Applications Web Polyarchical Services FFrracacttalal Auto-ID/RFID: The New Barcode ● Radio Frequency Identity Tags ● Data can be changed ● No line of site required ● 96-bits is plenty of storage Lots Of Possibilities... ● Supply chain management ● Parcel tracking ● Refrigerator/oven ● Washing machine ● Personalised advertising ● Use your imagination... Three “Laws” of Computing ● Moore's Law – Computing power doubles every 18 months ● Gilder's Law – Network bandwidth capacity doubles every 12 months ● Metcalfe's Law (Net Effect) – Value of network increases exponentially as number of participants increases Platform Evolution The Network The Computer Is Network of Catch Is the Computer Legacy to the Embedded Network Phrase Objects the Web Network Things of Things Scale 100s 1,000s 1,000,000s 10,000,000s 100,000,000s 100,000,000s When/Peak 1984/1987 1990/1993 1996/1999 2001/2003 1998/2004 2004/2007 Leaf X X +HTTP +XML +RM Unknown Protocol(s) (+JVM) Portal Directory(s) NS, NS+ +CDS +LDAP(*) +UDDI +Jini +? Session RPC, XDR +CORBA +CORBA, +SOAP, +RM/Jini +? RM XML Schematic Design Patterns: Web Service Bus. -

Edge-Based Network Attack Detection Using Apache Pulsar
Volume 5, Issue 8, August – 2020 International Journal of Innovative Science and Research Technology ISSN No:-2456-2165 Edge Based Network Attack Detection Using Pulsar Sheetal Dash IJISRT20AUG624 www.ijisrt.com 1501 Volume 5, Issue 8, August – 2020 International Journal of Innovative Science and Research Technology ISSN No:-2456-2165 ABSTRACT The edge-based network attacks are increasing largely in size, scale and frequency with the booming internet. The Distributed Denial of Service (DDoS) attacks is one of the most diffused types of attacks in the cyberworld which is a great concern for all organizations today. There were 5.2 billion Google searches in the year 2017 alone. Research shows that there cannot be a better example to show how prevalent internet use is nowadays. What started off as a point to point conversation in 1970s as a mode of communication has expanded to millions and millions of devices communicating with each other via some or the other form of the web. And therefore, this research focuses on the strategic approach that has been taken to defend from the growing cyber threat. In this dissertation, the focus is on defending against these edge-based network attacks and collaborating with other neighboring networks in order to communicate with them to transfer information about potentially malicious hosts. This research has focused on exploring ways of integrating the Software Defined Networking with the pub-sub messaging system in order to show a collaborative approach of defense to these attacks. The attacks from unknown multiple sources have also been analyzed in order to cope with them through this robust solution that has been proposed and implemented in this dissertation. -

Extending JXTA for P2P File Sharing Systems
Extending JXTA for P2P File Sharing Systems Bhanu Krushna Rout(10506012) Smrutiranjan Sahu(10506034) Department of Computer Science and Engi nee ring National Institute of Technology Rourkel a Rourkela-769 008, Orissa, India Extending JXTA for P2P File Sharing Systems Thesis submitted in partial fulfillment of the requirements for the degree of Bachelor of Technology in Computer Science and Engineering by Bhanu Krushna Rout(10506012) Smrutiranjan Sahu(10506034) under the guidance of Prof. Sujata Mohanty Department of Computer Science and Engi nee ring National Institute of Technology Rourkel a Rourkela-769 008, Orissa, India May 2009 Department of Computer Science and Engineering National Institute of Technology Rourkela Rourkela-769 008, Orissa, India. Certifica te This is to certify that the work in the thesis entitled Extending JXTA for P2P File Sharing Systems , submitted by Smrutiranjan Sahu and Bhanukrushna Rout is a record of an original research work carried out by them under our supervision and guidance in partial fulfillment of the requirements for the award of the degree of Bachelor of Technology in Computer Sci ence and Engineering during the session 2008–2009 in the department of Computer Science and Engineering, National Institute of Technology Rourkela(Deemed University). Neither this thesis nor any part of it has been submitted for any degree or academic award elsewhere. HOD Prof Sujata Mohanty Department of CSE Department of CSE NIT Rourkela NIT Rourkela Place: NIT Rourkela Place: NIT Rourkela Date: Date: Signature of External Acknowledgement We express our sincere gratitude to Sujata Mohanty Professor Department of Computer science and Engineering, National Institute of Technology, Rourkela, for her valuable guidance and timely suggestions during the entire duration of our project work, without which this work would not have been possible.