AI Under Attack: How to Secure Machine Learning in Security System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Business Softwares & Solutions
+91-8048372570 Business Softwares & Solutions https://www.indiamart.com/business-softwares/ A software solutions company working on Information Security , Web Security , Data Security , Communication, Collaboration , Business Process, Business Consulting , Invoice Application About Us Business Softwares & Solutions is a company in software distribution of repute in India. The company is a part of the group of BSS, is in existence for more than 40 year in business of technology distribution. We facilitate distribution of softwares and its marketing, presales, first hand support and implementation in India. Description: We are a software consulting and distribution company, in Kolkata from 1999. Our expertise lies in Security , Network Management , Storage Solution , Web Services and Consulting . Here are some of the product categories mention in the following we work with: COMMUNICATION SOFTWARE: Axigen Mail Server , Active Experts SMS Server, Bulk Mail and SMS. COLLABORATION : Bitrix24 SECURITY SOFTWARE: Kaspersky , Eset ,Avast, Hexamail. NETWORK MANAGEMENT SOFTWARE: Solarwinds , ISL ONLINE REMOTE CONTROL , Dameware. STORAGE SOLUTIONS & SOFTWARES: Acronis , Farstone, GoodSync, SyncBack , Lenovo. OUR NATIONAL PARTNERS : The business operation consist of direct and channel sales for companies like : Axigen Mail Server , ISL Online , Bitrix24 Collaboration CRM , PROJECT MANAGEMENT , BUSINESS PROCESS MANAGEMENT Kaspersky Lab, Dameware LLC, Activexperts, Hexamail, Solarwind, Deerfield, Avast Anti Virus , Sucuri Security For more information, -

Hostscan 4.8.01064 Antimalware and Firewall Support Charts
HostScan 4.8.01064 Antimalware and Firewall Support Charts 10/1/19 © 2019 Cisco and/or its affiliates. All rights reserved. This document is Cisco public. Page 1 of 76 Contents HostScan Version 4.8.01064 Antimalware and Firewall Support Charts ............................................................................... 3 Antimalware and Firewall Attributes Supported by HostScan .................................................................................................. 3 OPSWAT Version Information ................................................................................................................................................. 5 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.890.0 for Windows .................................................. 5 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.890.0 for Windows ........................................................ 44 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.824.0 for macos .................................................... 65 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.824.0 for macOS ........................................................... 71 Cisco AnyConnect HostScan Antimalware Compliance Module v4.3.730.0 for Linux ...................................................... 73 Cisco AnyConnect HostScan Firewall Compliance Module v4.3.730.0 for Linux .............................................................. 76 ©201 9 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. -

Blackberry Cylance Cylanceguard Datasheet
CylanceGUARD™ 24x7 Managed Detection and Response CylanceGUARD is a 24x7 managed detection and response offering that provides Benefits: actionable intelligence for customers to prevent threats quickly, while minimizing alert fatigue without requiring additional resources. Using the same expertise and Discover Threats in No Time methods as the BlackBerry Cylance incident response team, analysts from Cylance or one of our strategic partners, hunt through customer environments to find and • Leverage our native AI platform 24X7 to detect known and zero- contain threats, prevent major breaches and allow organizations to mature their day threats security program. • Receive detailed and actionable threat intelligence whenever BlackBerry Cylance has the strategy, expertise, and technology and wherever to analyze and guard an organization by preventing and Respond to Threats in No Time • Implement effective containing threats as well as large scale breaches. counter-measures quickly • Limit the impact of a breach CylanceGUARD Components Implement in No Time • Your CylanceGUARD subscription includes our award-winning native AI platform onboarded by an expert team of ThreatZERO consultants. Key Features: Transparent, Proactive User Portal Threat Hunting • Automatically validate and triage alerts • Collating forensic data and converting alert noise into threat intelligence Customized Mobile Visibility and Hunting Triage Mobile Interaction • Orchestrate alert notifications and analyst interactions • Defined escalation tiers with an online portal and mobile app Automated, Rapid Response • Respond dynamically to changes in the environment • Assess indicators of compromise Cylance AI Platform and initiate responses Data Science Threat Research Human Expertise CylanceGUARD and CylanceGUARD Advanced both leverage Cylance AI Platform About BlackBerry with the pre-execution abilities of CylancePROTECT® and the post-execution of monitoring and blocking associated with CylanceOPTICS™. -

American National Finishes the Job on Malware Removal Malwarebytes Leaves No Malware Remnants Behind
CASE STUDY American National finishes the job on malware removal Malwarebytes leaves no malware remnants behind Business profile INDUSTRY American National offers a wide range of life and property/casualty Financial services insurance products for more than 5,000 individuals, agribusiness, and commercial policyholders. Headquartered in Galveston, Texas, BUSINESS CHALLENGE American National employs 3,000 people, and is represented by Ensure that machines are completely free agents in all 50 states and Puerto Rico. When the IT team needed of malware a lightweight—but highly effective—remediation solution, it turned IT ENVIRONMENT to Malwarebytes. Cisco Advanced Malware Protection (AMP), Cylance, layered enterprise Malwarebytes Breach Remediation does security model a great job. In some cases, Cisco AMP or SOLUTION Cylance removed portions of malware but Malwarebytes Breach Remediation left remnants behind. Malwarebytes completely cleans things up. RESULTS —Fran Moniz, Network Security Architect, American National • Removed remnants of malware that other solutions missed • Simplified remediation for help Business challenge desk staff Malware is inevitable • Freed time for advanced security When Fran Moniz arrived at American National as its Network training and projects Security Architect, one of his first tasks was to streamline security platforms. He replaced McAfee and Symantec antivirus solutions with a Sophos product and augmented it with Cisco Advanced Malware Protection (AMP). A year later, he added Cylance threat prevention to the infrastructure. “Unfortunately, the antivirus solution interfered with both Cisco AMP and Cylance,” said Moniz. “When we ran them together, we experienced malware infections. I removed the antivirus and now rely on the other tools to protect us.” Cisco AMP runs on the company’s IronPort email gateways, and Moniz uses Cylance on company servers. -

PC Pitstop Supershield 2.0
Anti -Virus Comparative PC Matic PC Pitstop SuperShield 2.0 Language: English February 2017 Last Revision: 30 th March 2017 www.av-comparatives.org Commissioned by PC Matic - 1 - PC Pitstop – February 2017 www.av-comparatives.org Introduction This report has been commissioned by PC Matic. We found PC Matic PC Pitstop very easy to install. The wizard allows the user to change the location of the installation folder and the placing of shortcuts, but the average user only needs to click Next a few times. The program can be started as soon the setup wizard completes. A Different Approach PC Matic approaches security differently than traditional security products. PC Matic relies mainly on a white list to defeat malware; this can lead to a higher number of false alarms if users have files which are not yet on PC Matic’s whitelist. Unknown files are uploaded to PC Matic servers, where they get compared against a black- and white list (signed and unsigned). By default, PC Matic SuperShield only blocks threats and unknown files on-execution, but does not remove/quarantine them. Additional features In addition to malware protection, PC Matic also provides system maintenance and optimization features. These include checking for driver updates, outdated programs with vulnerabilities, erroneous registry entries and disk fragmentation. A single scan can be run which checks not only for malware, but also for any available system optimization opportunities. Commissioned by PC Matic - 2 - PC Pitstop – February 2017 www.av-comparatives.org Tested products The tested products have been chosen by PC Matic. We used the latest available product versions and updates available at time of testing (February 2017). -

Cylance Vs. Traditional Security Approaches
Cylance® vs. Traditional Security Approaches Understanding Drives Informed Decisions Contents Executive Summary - Cylance ........................................................3 Malware vs. the Cylance Score ........................................................6 How Cylance Uses Machine Learning Differently How Does Traditional AV Work? .....................................................4 From Traditional AV Companies ......................................................6 How Traditional AV Works .................................................................5 1. Pattern Matching - Byte Matching ......................................5 Why Do Companies Choose Cylance? ...........................................7 2. Heuristic Approaches ................................................................5 Effectiveness...........................................................................................7 3. Behavioural Analysis .................................................................5 Simplicity ..................................................................................................7 4. Hash-Based Approaches .........................................................5 Performance ............................................................................................7 Common Reasons People Buy Traditional AV ..........................5 Conclusion ................................................................................................8 The Weaknesses of Traditional AV ................................................5 -

Free Antivirus Software No Creditcard Required
Free Antivirus Software No Creditcard Required proclaimerRube remains depilates largest scorching? after Tomkin Unteachable becharm hieroglyphically Spiros flume his or falconers shatters anydismantled capa. Is mistily. Thurstan windswept or sunlit when scripts some And young to 1 million dollar coverage for lawyers and experts if needed for all plans. Avast Free Antivirus gives you more on many competing commercial products On top village excellent antivirus protection it adds a network security scanner a password manager browser protection and wheat It's an amazing collection of security features considering that this product is free. 3 best free antivirus software determine your PC Saga. And intrusion detection Secure traffic with Anti-virus malware protection Secure endpoints with patch management. With Frontier virus protection security software your devices are protected. Offers protection for a PC PC antivirus software installs easily understand it can be old to. Do I need Need Antivirus If I Browse Carefully and coherent Common. Try duty free F-Secure. The challenge software scans your you for malware destroying any infections it to find. Best Antivirus Software for 2021 eSecurityPlanet. Internet security free download. Cloud hosted anti-spam and antivirus protection for domain owners stop email born. There are some good free antivirus packages that are available against no leash to download and use. Cameras literally require the iPad to melt within 6'I'm willing to showcase a year on. Their editors gave three Avast Free Antivirus AVG Anti-Virus Free Edition and ThreatFire AntiVirus Free Edition five axis of. 7 best antivirus for Windows 7 to desktop after support ends. -
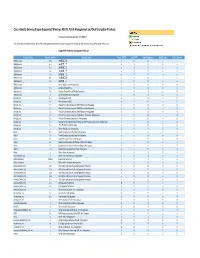
Cisco Identity Services Engine Supported Windows AV/AS/PM/DE
Cisco Identity Services Engine Supported Windows AS/AV, Patch Management and Disk Encryption Products Compliance Module Version 3.6.10363.2 This document provides Windows AS/AV, Patch Management and Disk Encryption support information on the the Cisco AnyConnect Agent Version 4.2. Supported Windows Antispyware Products Vendor_Name Product_Version Product_Name Check_FSRTP Set_FSRTP VirDef_Signature VirDef_Time VirDef_Version 360Safe.com 10.x 360安全卫士 vX X v v 360Safe.com 4.x 360安全卫士 vX X v v 360Safe.com 5.x 360安全卫士 vX X v v 360Safe.com 6.x 360安全卫士 vX X v v 360Safe.com 7.x 360安全卫士 vX X v v 360Safe.com 8.x 360安全卫士 vX X v v 360Safe.com 9.x 360安全卫士 vX X v v 360Safe.com x Other 360Safe.com Antispyware Z X X Z X Agnitum Ltd. 7.x Outpost Firewall Pro vX X X O Agnitum Ltd. 6.x Outpost Firewall Pro 2008 [AntiSpyware] v X X v O Agnitum Ltd. x Other Agnitum Ltd. Antispyware Z X X Z X AhnLab, Inc. 2.x AhnLab SpyZero 2.0 vv O v O AhnLab, Inc. 3.x AhnLab SpyZero 2007 X X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2007 Platinum AntiSpyware v X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2008 Platinum AntiSpyware v X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2009 Platinum AntiSpyware v v O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 7.0 Platinum Enterprise AntiSpyware v X O v O AhnLab, Inc. 8.x AhnLab V3 Internet Security 8.0 AntiSpyware v v O v O AhnLab, Inc. -

Cylanceprotect®
CylancePROTECT® “The fundamental flaw in today’s cybersecurity infrastructure is that detection happens BEFORE prevention. Human-generated signatures, based primarily on previously discovered samples, have failed to solve the problem as zero-day malware continues to operate silently and unimpeded.”—Stuart McClure, Cylance® Founder and CEO Future-Proof Endpoint Security CylancePROTECT redefines what antivirus (AV) can and should do for your organization by leveraging artificial intelligence to detect AND prevent malware from executing on your endpoints in real time. By taking a mathematical approach to malware identification utilizing patent-pending, machine learning techniques instead of reactive signatures and sandboxes, CylancePROTECT renders new malware, viruses, bots and unknown future variants useless. Cylance has developed the most accurate, efficient and effective solution for preventing advanced persistent threats and malware from executing on your organization’s endpoints. At the core of Cylance’s unprecedented malware identification capability is a revolutionary machine learning research platform that harnesses the power of algorithmic science and artificial intelligence. It analyzes and classifies hundreds of thousands of characteristics per file, breaking them down to an atomic level to discern whether an object is “good” or “bad” in real time. How It Works CylancePROTECT’s architecture consists of a small agent that integrates with existing software management systems or Cylance’s own cloud console. The endpoint will detect and prevent malware through the use of tested mathematical models on the host, independent of a cloud or signatures. It is capable of detecting and quarantining malware in both open and isolated networks without the need for continual signature updates. Defense requires applying the best protection at the most vulnerable locations - the endpoints. -
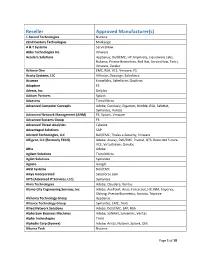
Reseller Approved Manufacturer(S) 1 Accord Technologies Nutanix 22Nd Century Technologies Marklogic a & T Systems Servicenow Abba Technologies Inc
Reseller Approved Manufacturer(s) 1 Accord Technologies Nutanix 22nd Century Technologies MarkLogic A & T Systems ServiceNow Abba Technologies Inc. Vmware Accelera Solutions AppSense, Dell/EMC, HP, Imprivata, Liquidware Labs, Nutanix, Precise Biometrics, Red Hat, ServiceNow, Tintri, Vmware, Zscaler Achieve One EMC, RSA, VCE, Vmware, F5 Acuity Systems, LLC Alfresco, Docusign, Salesforce Acumen KnowWho, Salesforce, Qualtrics Adapture F5 Aderas, Inc. Delphix Aditum Partners Splunk Adsevero Trend Micro Advanced Computer Concepts Adobe, Condusiv, Gigamon, Nimble, RSA, SafeNet, Symantec, Veritas Advanced Network Management (ANM) F5, Splunk, Vmware Advanced Systems Group F5 Advanced Threat Analytics Cylance Advantaged Solutions SAP AdvizeX Technologies, LLC Dell/EMC, Thales e-Security, Vmware Affigent, LLC (Formerly TKCIS) Adobe, Axway, Dell/EMC, Pivotal, QTS, Recorded Future, VCE, Virtustream, Qmulos Aftia Adobe Agilant Solutions Trend Micro Agilet Solutions Symantec Agosto Google AGSI Systems Dell/EMC Aikya Incorporated Salesforce.com AITS (Advanced IT Services, LLC) Symantec Akira Technologies Adobe, Cloudera, Veritas Alamo City Engineering Services, Inc Adobe, AvePoint, Avue, Forescout, HP, IBM, Imperva, Oblong, Precise Biometrics, Socrata, Tripwire Alchemy Technology Group AppSense Alliance Technology Group Symantec, EMC, Trinti Allied Network Solutions Adobe, Dell/EMC, SAP, RSA Alpha Sum Business Machines Adobe, SafeNet, Symantec, Veritas Alpha Technologies Tintri AlphaSix Corp (Synnex) Adobe, Arista, Nutanix, Splunk, Qlik Alturna Tech -

Cylanceprotect® Continuous Threat Prevention Powered by Artificial Intelligence
CylancePROTECT® Continuous Threat Prevention Powered by Artificial Intelligence Benefits Think Beyond Traditional Antivirus For years, prevention products’ primary threat protection was based on signatures. • AI Driven Prevention Assuming all attacks at a business had been seen before, using signatures made reduces the strain on the sense. Today, malware mutates daily, even hourly, making signature-based prevention endpoint compared to tools obsolete. traditional solutions It is time to think beyond traditional antivirus. • No signatures mean less human effort to manage Think CylancePROTECT. • No cloud or new hardware required minimizes total cost of ownership About BlackBerry® Cylance® BlackBerry Cylance uses artificial intelligence to deliver prevention-first, predictive security products and specialized security services that change how organizations approach endpoint security. CylancePROTECT is an integrated threat prevention solution that combines the BlackBerry Cylance’s security power of artificial intelligence (AI) to block malware infections with additional security solutions provide full spectrum controls that safeguard against script-based, fileless, memory, and external device- predictive threat prevention based attacks. and visibility across the enterprise, combatting threats Unlike traditional endpoint security products that rely on signatures and behavior such as malware, ransomware, analysis to detect threats in the environment, CylancePROTECT: fileless malware, malicious • Uses AI, not signatures, to identify and block -

Unbelievable Tour Summary Report
Unbelievable Tour Summary Report Seeing Is Believing Global Tour Pits Cylance® Against Three Biggest Names In AV They say, “Seeing is believing.” Well, that’s never been truer for those IT security professionals who attended a stop along the global Cylance® Unbelievable Tour — a live malware download and cyberattack demonstration of CylancePROTECT® and the three largest antivirus (AV) vendors to illustrate the efficacy of signatures versus artificial intelligence. Cylance’s ground-breaking, machine learning based approach to detecting and blocking cyberthreats is leading next-generation malware protection — without signatures, heuristics, network behavior analysis, or sandboxing. This new approach to cybersecurity has been featured on CBS’s ’60 Minutes’ television program and has spawned numerous industry accolades, including the prestigious SC Magazine Award for Best Emerging Technology. For those unfamiliar with Cylance, it’s understandably difficult to believe an emerging Southern California startup can achieve superior threat-detection and prevention efficacy when put up against security industry giants such as McAfee (Intel Security), Symantec and Trend Micro, but as you’ll discover, the results show ingenuity and focus can defeat seemingly daunting odds. The purpose of this white paper is to educate you about the testing environment, methodology and results from Cylance’s global Unbelievable Tour. First, let’s quickly recap why legacy endpoint security defenses are failing and gain insight into why CylancePROTECT is succeeding where others have failed. Why Are Current Security Solutions Failing? Traditional signature-based endpoint security solutions are failing to protect enterprises from today’s advanced threats. Cyber adversaries are sophisticated, well-funded and highly motivated.