Memory System Behavior of Java-Based Middleware
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sun Netra X4250 Server Installation Guide
Sun Netra X4250 Server Installation Guide Part No. 820-4055-11 May 2010, Revision 11 Copyright © 2008, 2010, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related software documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS. Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle USA, Inc., 500 Oracle Parkway, Redwood City, CA 94065. -

Sun Netra 6000 Modular System
ORACLE DATA SHEET SUN NETRA 6000 CHASSIS MAXIMUM EFFICIENCY WITH Oracle’s Sun Netra 6000 modular system is a highly reliable blade server CARRIER GRADE RELIABILITY system designed for customers who need a cost-efficient platform for delivering KEY FEATURES IP services over Telecom Networks. The Sun Netra 6000 chassis, can be filled • Space efficient form factor: 10 RU - AC version and 11 RU- DC version with a combination of SPARC or Intel processor based server modules and • Up to ten server modules 10Gb Ethernet switching to handle the most demanding workloads, including • Up to 20 PCIe Express Modules (EMs) advanced IP-based Telecom/Web services and Operations and Business • Up to two Network Express Modules Support Systems (OSS/BSS) applications. (NEMS) • Chassis Monitoring Module (CMM) with Integrated Lights Out Manager (ILOM) • NEBS™ Level 3 certification and ETSI compliance • Choice of AC or DC power • Choice of SPARC and Intel-processor based modules • Hot-pluggable, hot-swappable and redundant AC or DC power supply and fan modules KEY BENEFITS • High availability and reliability for telecom customers • Reliable operation in severe environmental conditions • Modular design allows easy upgrade and expansion The Sun Netra 6000 modular system is designed for telecom customers • Power and cooling efficiencies cut costs • Fewer qualifications and simpler Sun Netra 6000 Chassis maintenance planning with longer The Sun Netra 6000 combines the benefits of the Sun Blade 6000 modular system with the product life cycles ruggedness and reliability of the Sun Netra server family. The Sun Netra 6000 chassis fits in a compact form factor - only 10 RU (11RU for DC) while supporting up to 10 full-featured, top-performance blade server modules. -

Memory Characterization of the Ecperf Benchmark
Memory Characterization of the ECperf Benchmark Martin Karlsson, Kevin E. Moore, Erik Hagersten, and David A.Wood Uppsala University University of Wisconsin Information Technology Department of Computer Sciences Department of Computer Systems 1210 W. Dayton St. P.O. Box 325, SE-751 05 Uppsala, Sweden Madison, WI 53706 Email: {martink, eh}@it.uu.se Email: {kmoore, david}@cs.wisc.edu Abstract the large market for application servers is evidence that they are an important workload for today’s servers. The quest for quantitative performance analysis in com- Several previous papers have characterized the perfor- puter architecture research and design led to many mance of other commercial workloads, most notably research papers based on the commercially important database systems, running the TPC benchmarks [1][2]. DSS and OLTP database applications. Today’s middle- Application servers, however, behave quite differently ware, and in particular application servers, are rapidly from database engines; they have much smaller data sets gaining popularity as a new workload for commercial than databases and generate much less disk traffic. multiprocessor servers. Therefore, it is important to Also, many commercial application servers are imple- expand architecture studies into this area. SPEC has mented in Java. Like other Java workloads, they are recognized the importance of application servers and influenced by the performance characteristics of the Java-Based middleware with its recent adoption of Java Virtual Machine (JVM) on which they run, includ- SPECjAppServer2001, formerly ECperf, as one of its ing automatic garbage collection and Just-In-Time benchmarks. In this paper, we present a detailed char- compilation. Unlike known Java benchmarks, applica- acterization of the memory system behavior of ECperf tion servers are optimized commercial applications. -
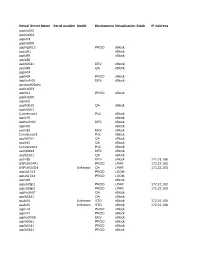
Virtual Server Name Serial Number Model
Virtual Server Name Serial number Model EnvironmentVirtualization Stack IP Address sppbia002 sppbia004 usplv03 sppbia006 usphxplh12 PROD vBlock usqsv01 vBlock usplv89 vBlock usplc35 usdlh05d1 DEV vBlock usqlv38 QA vBlock usplv04 usplv69 PROD vBlock usphxdlh01 DEV vBlock usccisuh06phx sppbia003 usplh11 PROD vBlock sppbia005 usplv02 usqlh05d3 QA vBlock sppbia001 Conversion1 PoC vBlock usplv70 vBlock usphxdlh02 DEV vBlock usplv60 vBlock usdlv32 DEV vBlock Conversion3 PoC vBlock usqlh07d2 QA vBlock usqlv42 QA vBlock Conversion4 PoC vBlock usdlh03d4 DEV vBlock usqlh19d1 QA vBlock usdlv35 DEV vBlock 172.23.166 USPUH24P1 PROD LPAR 172.22.163.14 USPUH24D4 Unknown QA LPAR 172.22.163.80 uspuh17d3 PROD LDOM .80 uspuh17d4 PROD LDOM usplv28 vBlock uspuh28p1 PROD LPAR 172.22.163 uspuh28p2 PROD LPAR 172.22.163.22 usphxqlh07 QA vBlock .102 usqlh18d1 QA vBlock usslv20 Unknown STG vBlock 172.22.168 usslv21 Unknown STG vBlock 172.22.168.147 usplv76 PROD vBlock .148 usplv77 PROD vBlock usphxdlh06 DEV vBlock usplh20d1 PROD vBlock usplh21d1 PROD vBlock usplh24d1 PROD vBlock usslh11d1 STG vBlock usdlv26 DEV vBlock usdlv18 DEV vBlock usplh14 PROD vBlock usplh13 PROD vBlock usplv52 PROD vBlock usplv53 PROD vBlock usplv58 PROD vBlock usplv59 PROD vBlock usplv63 PROD vBlock usplv64 PROD vBlock usqlv34 QA vBlock usqlv35 QA vBlock usslv17 STG vBlock usslv18 STG vBlock usqlv24 QA vBlock usqlv17 QA vBlock usqlv25 QA vBlock usqlv18 QA vBlock usqlv28 QA vBlock usqlv27 QA vBlock usplv92 PROD vBlock usplv91 PROD vBlock usqlv30 QA vBlock usqlv29 QA vBlock usslh12d1 STG LDOM -

Sun Netra T5220 Server Administration Guide
Sun Netra T5220 Server Administration Guide Part No. 820-3010-12 April 2010, Revision A Copyright © 2008, 2010 Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related software documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle USA, Inc., 500 Oracle Parkway, Redwood City, CA 94065. -

Sun Netra X4450 Server Product Notes
Sun Netra™ X4450 Server Product Notes Sun Microsystems, Inc. www.sun.com Part No. 820-4018-12 February 2009, Revision A Submit comments about this document at: http://www.sun.com/hwdocs/feedback Copyright 2009 Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, U.S.A. All rights reserved. Sun Microsystems, Inc. has intellectual property rights relating to technology that is described in this document. In particular, and without limitation, these intellectual property rights may include one or more of the U.S. patents listed at http://www.sun.com/patents and one or more additional patents or pending patent applications in the U.S. and in other countries. This document and the product to which it pertains are distributed under licenses restricting their use, copying, distribution, and decompilation. No part of the product or of this document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and in other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, Java, JRE, Sun Java Enterprise, Sun Netra, Netra, the Netra logo, SunSolve, Netbeans, docs.sun.com, and Solaris are trademarks or registered trademarks of Sun Microsystems, Inc., or its subsidiaries, in the U.S. and in other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. -

Sun Netra T5440 Server Architecture
An Oracle White Paper March 2010 Sun Netra T5440 Server Architecture Oracle White Paper—Sun Netra T5440 Server Architecture Introduction..........................................................................................1 Managing Complexity ..........................................................................2 Introducing the Sun Netra T5440 Server .........................................2 The UltraSPARC T2 Plus Processor and the Evolution of Throughput Computing .....................................10 Diminishing Returns of Traditional Processor Designs .................10 Chip Multiprocessing (CMP) with Multicore Processors................11 Chip Multithreading (CMT) ............................................................11 UltraSPARC Processors with CoolThreads Technology ...............13 Sun Netra T5440 Servers ..............................................................21 Sun Netra T5440 Server Architecture................................................21 System-Level Architecture.............................................................21 Sun Netra T5440 Server Overview and Subsystems ....................22 RAS Features ................................................................................30 Carrier-Grade Software Support........................................................31 System Management Technology .................................................32 Scalability and Support for CoolThreads Technology....................35 Cool Tools for SPARC: Performance and Rapid Time to Market ..39 Java -

Netra™ 20 Server
one tough customer Netra™ 20 Server RUGGED, RACK-OPTIMIZED, AND BOASTING UP TO TWO 900-MHZ PROCESSORS, IT’S THE SYSTEM THAT MAKES THE NET WORK HARDER–NO MATTER HOW INHOSPITABLE THE ENVIRONMENT NETRA™ 20 SERVER SPECIFICATIONS NETRA RACK-OPTIMIZED PROCESSORS ENVIRONMENT SERVICES PLATFORMS Architecture One or two Superscalar SPARC® Version 9, 64-bit AC power 90-264 V AC (47-63 Hz) The Netra™ 20 server is an ideal system RISC UltraSPARC® III Cu processors at 900 MHz 90 V/47 Hz Maximum input power 735 W Cache 8-MB integrated second-level cache per processor Nominal input power 418 W for rack-intensive environments where Nominal input current 4.685 A SYSTEM BUS Nominal thermal dissipation 1313 BTU/hr. reliability and compute density are para- Bus width is 576-bits running at 150 MHz with 240 V/63 Hz Maximum input power 683 W 2.4-GB/sec. bandwidth Nominal input power 388 W mount and space is at a premium. These MAIN MEMORY Nominal input current 1.557 A Nominal thermal dissipation 1218 BTU/hr. Netra T1 ® Eight slots populated in two banks of four 256-, servers pack up to two UltraSPARC III Cu 512-, or 1024-MB DIMMs DC power -48 to -60 V DC (dual isolated inputs) System configurations from 1 GB (4 x 256 MB) -48 V DC Maximum input power 770 W processors, front-accessible components to 8 GB (8 x 1024 MB) ECC memory Nominal input power 430.3 W Nominal input current 8.97 A and front and back LEDs, a removable STANDARD INTERFACES Nominal thermal dissipation 1351.14 BTU/hr. -

Netra 1290 Server Datasheet
Netra™ 1290 Server Powerful, reliable, rack-ready, and vertically scalable Highlights • Telcordia Network Equipment < Building Standard (NEBS) Level 3 The Netra™ 1290 server with new high-performance UltraSPARC IV+ dual-core processors certification, for reliable operation is uniquely positioned in the class of vertically integrated, ruggedized, carrier-grade in severe environmental conditions servers for the telecommunications market. The Netra 1290 server provides exceptional • Scales up to 12 1.5 GHz computing power, breakthrough price/performance, and high reliability in a compact, UltraSPARC® IV+ dual-core high- two-per-rack frame. It scales up to 12 UltraSPARC IV+ 64-bit chip multithreading (CMT) processors, performance processors with 24 threads and up to 96 GB of memory. • 32 MB of external L3 cache per processor, and up to 192 GB of The Netra 1290 server delivers enterprise- UltraSPARC IV+ processor-based servers memory, to provide headroom class reliability, availability, and serviceability deliver up to five times the performance of for future growth (RAS) features like hot-swap CPU/memory UltraSPARC III processor-based servers. They • Hot-swap CPU/memory board boards, Lights Out Management, front and provide an even more compelling value when with Dynamic Reconfiguration, back LEDs, a removable system configuration coupled with the Solaris™ 10 OS, which dual-grid (2N) hot-swap AC and DC card, and dual redundant AC/DC power increases system utilization up to 80 percent power supplies, hot-swap disks, supplies. Powered by the reliable, scalable with features like Solaris Containers. The and Lights Out Management (LOM) for reduced downtime and Solaris™ Operating System, the NEBS Level Solaris 10 OS also delivers superior RAS easier maintenance 3-certified Netra 1290 server delivers an through Predictive Self-Healing, and provides • Compact chassis with 22-inch outstanding solution for the telecommunica- industry-leading performance, scalability, depth fits a wide range of indus- tions industry and other applications in less and security. -

Etitive Profiles
..Financials Headquarters SUN 2003E 2002 2001 4150 Network Circle Revenue $ 11,872 $ 12,496 $ 18,250 Santa Clara, CA 95054 650-960-1300 Cost of Goods Sold $ 8,228 $ 5,056 $ 10,302 http://www.sun.com/ Gross Profit Margin 41.8% 39.3% 44% SG&A Expense $ 3,362 $ 3,868 $ 6,560 Management Operating Income $ 39 $ 784 $ 1,388 Total Net Income $ 106 $ -229 $ 927 President & CEO - Scott McNealy Chief Scientist & CEO - Bill Joy CIO - H. William Howard Executive VP - Crawford Beveridge Revenue by Product Line Senior VP & Special Counsel - Michael Morris CEO SW Senior VP, Workplace Resources - William T. Agnello Microelec. Executive VP & CTO - Greg Papadopoulos 5% $200 M Executive VP, Software Group - Jonathan Schwartz Add-Ons $645 M Executive VP, Sun Services - Patricia Sueltz Storage $2,165 M Executive VP, Marketing & Strategy - Mark Tolliver HW Wkstn. $855 M Services 80% CEO 15% Servers $5,416 M CIO Business Sun Microsystems is a leading maker of UNIX-based, number-crunching workstation computers, storage devices, and servers for powering corporate computer networks and Web sites. The company is the largest to make computers that use its own chips, SPARC, and operating systems, Solaris. Sun's most talked-about product may be Java, a programming language intended to create software that can run unchanged on any kind of computer. Its Jini technology enab les electronic devices to communicate with each other and over networks. Sun sells to customers in the telecommunications, financial, healthcare, retail, government, manufacturing, and education markets. Since the company's inception in 1982, a singular vision -- The Network Is The Computer-- has propelled Sun Microsystems to its position as a leading provider of industrial-strength hardware, software, and services that power the Net and allow enterprises worldwide to take their businesses to the nth. -

Sun Netra X6270 M2 Server Module Installation Guide • October 2010 Reinstalling the Oracle Solaris Operating System 40 Download the Oracle Solaris Operating System 40
Sun Netra X6270 M2 Server Module Installation Guide Part No. 821-0937-10, Rev. A October 2010 Copyright © 2010, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related software documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS. Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle America, Inc., 500 Oracle Parkway, Redwood City, CA 94065. -

Sun Netra X4250 Server Product Notes
Sun Netra X4250 Server Product Notes Part No. 820-4059-12 May 2010, Revision A Copyright © 2008, 2010, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related software documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms set forth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle USA, Inc., 500 Oracle Parkway, Redwood City, CA 94065.