Distributed Information Management
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Valentine's Day Lacks Focus
Valentine’s Day lacks focus Too many stars, not enough substance Photo copyright cleared Julia Fiztpatrick (Jennifer Garner) receives flowers from Reed Bennett (Ashton Kutcher)in the new film Valentine’s Day. James Butler Anne Hathaway (great in Get Smart and Contributor receiving an Oscar nomination for Rachel Most movies in Hollywood these days Getting Married) and even lesser ones like often have a major star attached to them Jennifer Garner are completely mailing it like George Clooney, Christian Bale, or in, it gets hard to really care about any of Jennifer Aniston, but it really is rare for the characters’ problems. a movie to have as many huge names as The screenplay itself is one of the Valentine’s Day. movie’s redeeming factors. Despite some Clearly catering to the mainstream cringe-worthy lines, it manages to have date movie audience, Valentine’s Day is points that were actually pretty funny. huge on star power, but very low on actual With a few too many story lines, substance. however, it stretches itself too thin, trying The biggest surprise about this movie to move the audience with characters was how they managed to get so many that were not given enough time or effort major stars into a motion picture and not throughout the film. get at least one memorable performance It also suffers from Crash syndrome, out of any of them. i.e., it bashes you over the head with The high profile cast includes Ashton its interconnected story lines and over- Kutcher, Jessica Alba, Julia Roberts, arching theme about the power of love. -

Christian Bale, Steve Carell, Ryan Gosling and Brad Pitt Star in the Unbelievable True Story the BIG SHORT, Coming to Blu-Ray™ Combo Pack March 15, 2016
February 16, 2016 Christian Bale, Steve Carell, Ryan Gosling and Brad Pitt Star in the Unbelievable True Story THE BIG SHORT, Coming to Blu-ray™ Combo Pack March 15, 2016 Critically Acclaimed Hit is Nominated for Five Academy Awards Including Best Picture, Best Director and Best Supporting Actor HOLLYWOOD, Calif.--(BUSINESS WIRE)-- "One of the most absorbing and entertaining films of the year" (Mara Reinstein, Us Weekly), director Adam McKay's "witty, smart, sharp and funny" (Scott Mantz, "Access Hollywood") masterpiece THE BIG SHORT arrives on Blu-ray Combo Pack, DVD and On Demand March 15, 2016 from Paramount Home Media Distribution. This Smart News Release features multimedia. View the full release here: http://www.businesswire.com/news/home/20160216005087/en/ Nominated for five Academy Awards including Best Picture, Best Director, Best Supporting Actor (Christian Bale), Best Adapted Screenplay and Best Editing, THE BIG SHORT also was named one of the top 10 films of the year by The Wall Street Journal, New York Times, Los Angeles Times, Entertainment Weekly, Us Weekly, the American Film Institute and many more. Based on the best-selling book by Michael Lewis, THE BIG SHORT details the true story of four outsiders who risked everything to take on the big banks during the greatest financial fraud in U.S. history. Christian Bale, Steve Carell, Ryan Gosling and Brad Pitt deliver career-best performances in "the most wildly entertaining must-see movie of the year" (Toni Gonzales, Fox-TV). THE BIG SHORT Blu-ray Combo Pack with Digital HD is packed with over an hour of bonus content. -

Cold War Fever As 1950S Spies, Romance Lead Bafta Picks
SATURDAY, JANUARAY 9, 2016 (From left) Director/writer Alejandro Gonzalez Inarritu, actors Tom Hardy and This photo provided by Open Road Films shows, (from left) Michael Keaton, as Walter “Robby” Robinson, Liev Leonardo DiCaprio arrive at the world premiere of “The Revenant” at the TCL Schreiber as Marty Baron, Mark Ruffalo as Michael Rezendes, Rachel McAdams, as Sacha Pfeiffer, John Slattery Chinese Theatre, in Los Angeles. as Ben Bradlee Jr., and Brian d’Arcy James as Matt Carroll, in a scene from the film, “Spotlight.” The main Bafta Cold War fever as 1950s spies, nominations Best film romance lead Bafta picks “The Big Short” “Bridge of Spies” “Carol” teven Spielberg spy thriller “Bridge of Spies” known for his leading role in television hit “The Revenant” and “Carol”, a story of romance between two “Breaking Bad”. “Spotlight” Swomen, led the nominations on Friday for Britain’s Bafta film awards, seen as a tip for later Outdoor epic Outstanding British film Oscar success. The two Cold War-era stories set in In the best director category, Spielberg is up “45 Years” the United States in the 1950s have nine nomina- against Mexico’s Alejandro Gonzalez Inarritu, “Amy” tions each and are both nominated in the best Britain’s Ridley Scott, and US directors Adam “Brooklyn” film category. McKay and Todd Haynes. “I’m so pleased to see a “The Danish Girl” They are up against financial drama “The Big great wide sweep of films represented, both inti- “Ex Machina” Short” and survival tale “The Revenant”, which has mate portraits-if you might call them that-like eight nominations. -
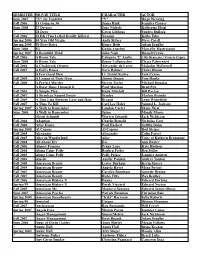
SEMESTER MOVIE TITLE CHARACTER ACTOR Sum 2007 "V
SEMESTER MOVIE TITLE CHARACTER ACTOR Sum 2007 "V" for Vendetta "V" Hugo Weaving Fall 2006 13 Going on 30 Jenna Rink Jennifer Garner Sum 2008 27 Dresses Jane Nichols Katherine Heigl ? 28 Days Gwen Gibbons Sandra Bullock Fall 2006 2LDK (Two Lethal Deadly Killers) Nozomi Koike Eiko Spring 2006 40 Year Old Virgin Andy Stitzer Steve Carell Spring 2005 50 First Dates Henry Roth Adam Sandler Sum 2008 8½ Guido Anselmi Marcello Mastroianni Spring 2007 A Beautiful Mind John Nash Russell Crowe Fall 2006 A Bronx Tale Calogero 'C' Anello Lillo Brancato / Francis Capra Sum 2008 A Bronx Tale Sonny LoSpeecchio Chazz Palmenteri Fall 2006 A Clockwork Orange Alexander de Large Malcolm McDowell Fall 2007 A Doll's House Nora Helmer Claire Bloom ? A Few Good Men Lt. Daniel Kaffee Tom Cruise Fall 2005 A League of Their Own Jimmy Dugan Tom Hanks Fall 2000 A Perfect Murder Steven Taylor Michael Douglas ? A River Runs Through It Paul Maclean Brad Pitt Fall 2005 A Simple Plan Hank Mitchell Bill Paxton Fall 2007 A Streetcar Named Desire Stanley Marlon Brando Fall 2005 A Thin Line Between Love and Hate Brandi Lynn Whitefield Fall 2007 A Time To Kill Carl Lee Haley Samuel L. Jackson Spring 2007 A Walk to Remember Landon Carter Shane West Sum 2008 A Walk to Remember Jaime Mandy Moore ? About Schmidt Warren Schmidt Jack Nickleson Fall 2004 Adaption Charlie/Donald Nicholas Cage Fall 2000 After Hours Paul Hackett Griffin Dunn Spring 2005 Al Capone Al Capone Rod Steiger Fall 2005 Alexander Alexander Colin Farrel Fall 2005 Alice in Wonderland Alice Voice of Kathryn Beaumont -

Book Your Screenings & Events At
Book Your Screenings & Events at 10850 West Pico Blvd. Los Angeles, CA 90064 • Convenient West Side Location • Unmatched Customer Service • Convenient Access for Over 50% of Academy Membership • Plenty of Parking • Over 500 Successful Events Each Year Contact Tom Beddow at 424.731.2429 or [email protected] WORLD CLASS FACILITY • 12 Auditoriums with various seating capacities (40, 100, 200, 250, and 300) • Stadium seating with extra high risers for optimum viewing • Screening lounge seating with plush leather sofas and love seats • Barco digital projectors with any digital format including DCP, BluRay, DVD, or Quicktime/mp4 • Klipsch speakers with DTS and Dolby Digital surround sound • Reception capacityfrom 5o-3oo people • Comfortable lounge setting • Flexible space • Catering options for every budget PAST Q&A APPEARANCES • CHRISTIAN BALE • FRANCIS FORD COPPOLA • RIDLEY SCOTT • PHILIP SEYMOUR HOFFMAN • SAOIRSE RONAN • MARK RUFFALO • STEVIE NICKS • JOAN RIVERS • JUDI DENCH • JK SIMMONS PATRICIA ARQUETTE • DAVID FINCHER • JOSEPH GORDON-LEVITT • SETH ROGEN • ELLEN PAGE • SEAN WILLIAM SCOTT • KRISTEN WIIG • JAMES MCAVOY • RYAN GOSLING • VIOLA DAVIS GOSLING • RYAN MCAVOY WIIG • JAMES • KRISTEN SCOTT WILLIAM SEAN • • SETH ROGEN ELLEN PAGE GORDON-LEVITT FINCHER • JOSEPH ARQUETTE • DAVID PATRICIA FIRST CLASS EVENT SUPPORT • We’re ready for all your Q&As and panel discussions • We provide the podium, director chairs, courtesy water for panelists, stage lighting, and handheld microphones • Connect your computer to the big screen and surround -

2015 DVD RELEASES at the JPL If the DVD Is Checked Out, Ask to Place It on “HOLD” and You’Ll Be Added to the Wait List
2015 DVD RELEASES at the JPL If the DVD is checked out, ask to place it on “HOLD” and you’ll be added to the wait list. It’s the secret to getting a DVD quicker than waiting for it to get back on the shelf. January-February actors date Alexander and the terrible, horrible,...very bad day Steve Carrell, Jennifer Garner 2/10/15 Annabelle Annabelle Wallis 1/20/15 Before I Go to Sleep Nicole Kidman, Colin Firth 1/27/15 Big Hero 6 animated 2/24/15 Birdman (or the unexpected virture of ignorance) Michael Keaton, Ed Norton, Emma Stone2/17/15 Boardwalk Empire, season #5 HBO series 1/13/15 Book of Life, The animated 1/27/15 Boxtrolls, The animated 1/20/15 Boyhood Patricia Arquette, Ellar Coltrane 1/6/15 Curse of Princess Ivy Sofia the First, animated 2/24/15 Dowton Abbey , season #5 PBS Masterpiece series 1/27/15 Drop, The James Gandolfini, Tom Hardy 1/20/15 Fury Brad Pitt 1/27/15 Game of Thrones, season #4 HBO series 2/17/15 Gone Girl Ben Affleck, Rosamund Pike 1/13/15 Hector and the Search for Happiness Simon Pegg, Jean Reno 2/3/15 Homesman, The Tommy Lee Jones, Hilary Swank 2/17/15 Horns Daniel Radcliffe 1/6/15 Horrible Bosses 2 Jason Bateman, Charlie Day 2/24/15 Interview, The James Franco, Seth Rogen 2/17/15 John Wick Keanu Reeves, Willem Dafoe 2/3/15 Judge, The RobertDowney Jr., Robert Duvall 1/27/15 Justice League vs. -

Dear Academy Member
Relativity Media invites you and a guest to attend Special Screening Of Starring Christian Bale, Woody Harrelson, Casey Affleck, Forest Whitaker, Willem Dafoe with Zoë Saldana and Sam Shepard Friday, November 15 7:30 PM at HARMONY GOLD 7655 West Sunset Boulevard, Los Angeles, CA 90046 Q & A will follow the screening with Director / Co-Writer Scott Cooper, Edited by: David Rosenbloom, A.C.E. Director Of Photography: Masanobu Takayanagi From Scott Cooper, the writer and director of Crazy Heart, comes a drama about family, fate, circumstance, and justice. Russell Baze (Christian Bale) has a rough life: he works a dead-end blue collar job at the local steel mill by day, and cares for his terminally ill father by night. When Russell's brother Rodney (Casey Affleck) returns home from serving time in Iraq, he gets lured into one of the most ruthless crime rings in the Northeast and mysteriously disappears. The police fail to crack the case, so - with nothing left to lose - Russell takes matters into his own hands, putting his life on the line to seek justice for his brother. The cast of Christian Bale and Casey Affleck are rounded out by Woody Harrelson, Forest Whitaker, Willem Dafoe, Zoë Saldana and Sam Shepard. R.S.V.P. by November13 at [email protected] Please include Guild Affiliation, Full Name / Guest Name in subject line or in the body of the E-Mail RELATIVITY MEDIA Presents In Association with RED GRANITE PICTURES a RELATIVITY MEDIA Production a SCOTT FREE and APPIAN WAY Production OUT OF THE FURNACE Directed by: Scott Cooper Written by: Brad Ingelsby and Scott Cooper Produced by: Jennifer Davisson Killoran, Leonardo DiCaprio, Ryan Kavanaugh, Ridley Scott, Michael Costigan Cast: Christian Bale, Woody Harrelson, Casey Affleck, Forest Whitaker, Willem Dafoe with Zoë Saldana and Sam Shepard Rated R for strong violence, language and drug content Opens in Theatres, December 6, 2013 -- 116 minutes PAID FOR BY RELATIVITY MEDIA PLEASE ARRIVE AT LEAST 30 MINUTES EARLY. -

Executive Summary for the Feature Film, Anthony This Is a Unique Opportunity to Invest in an Impactful Movie with an Outstanding Potential ROI 3X-15X
Executive Summary for the Feature Film, Anthony This is a unique opportunity to invest in an impactful movie with an outstanding potential ROI 3X-15X. The Anthony screenplay has been endorsed by Hollywood’s #1 and #5 rated script consultants as one of the best scripts they’ve ever read. A film like this hasn’t been made before. The Anthony script displays superior craft and genre dominance over top selling box office feature films that have made over $100M worldwide. Anthony is set-up to perform better at the box office than the movie Juno which won an Oscar for best origi- nal screenplay and made $231M worldwide. An impoverished, brilliant kid wants to live and prove his life is valuable by standing up to the status quo and by changing the world in a major way, but will he be able to stand up to the one he loves the most? LOGLINE In the vein of It’s A Wonderful Life, Sixth Sense and Beautiful Mind; Anthony is a smart, thrilling, patriotic drama that is inspiring and compelling. Since childhood, Anthony demonstrates his convictions and boldness to stand up for himself and others. Growing up in a single-parent home, Anthony struggles with the question throughout his life of whether his personal worth is equal to his accomplishments. As an adult, Anthony battles a mysterious illness and it seems someone wants him out of the way. He uses his brilliant mind to try and prove that he is of value by defining himself as a person to his mother, Maria, to his father who SYNOPSIS abandoned him, and to the rest of the world, by striving to save millions of lives including his own. -

Hollywood Costume: 60 Films/60 Days November 29, 2013 – January 31, 2014
COMMUNICATIONS & MARKETING VIRGINIA MUSEUM OF FINE ARTS 200 N. Boulevard I Richmond, Virginia 23220-4007 www.vmfa.museum/pressroom I T 804.204.2704 Hollywood Costume: 60 Films/60 Days November 29, 2013 – January 31, 2014 60 Films/60 Days will showcase 60 movie titles selected from the exhibition throughout 60 days. Mondays – Thursdays: 1 p.m.; Fridays: 6:30 p.m. and Saturdays at 1:30 & Sundays: 1 p.m. Tickets are available at: https://reservations.vmfa.museum/state/Info.aspx?EventID=51 Friday Screenings November 29: The Dark Knight Rises (2012) Christian Bale takes it up another notch in the latest of the iconic and visually stunning Batman series. December 13: The Matrix (1999) The movie that has defined a generation featuring computer hackers, mysterious rebels, virtual reality, and the controllers. December 20: The Blues Brothers (1980) Rollicking flick with rousing R&B/Soul/Rock music, Belushi and Aykroyd, and the car chase to end all car chases. December 27: Raiders of the Lost Ark (1981) The first and fleetest of the wildly successful Spielberg series featuring archeologist and adventurer Indiana Jones. January 3: Valley of the Dolls (1968) A campy, cult relic about three actresses’ rise and fall in the cruel world of prescription drugs, sex, love, and show business. January 10: The Twilight Saga: New Moon (2009) They’re young; they’re hip; they’re vampires (and werewolves) in paranormal relationships. January 17: Dreamgirls (2006) Based on the hit Broadway musical, a Supremes-like trio of female soul singers conquer the pop charts in the 1960s. -

September 2014 Movies
SEPTEMBER 2014 MOVIES e Glendora Community Services Department shows movies at no cost for seniors every Tuesday at 1:00 p.m. at the La Fetra Center, in the Living Room. e following is a schedule of movies for the month of SEPTEMBER ... Closed caption now available on some movies. September 2: LABOR DAY September 9: IRON MAN 3 September 16: AMERICAN HUSTLE September 23: GRAVITY September 30: THE WOLF OF WALL STREET Lunch is available prior to the movie at 12 noon. Reservations are required; please call two (2) days in advance for reservations, 914-0560. The cost for lunch is a suggested $2 donation for age 60 and over, under 60 please pay $3.75. La Fetra Center is located at 333 E. Foothill Blvd, Glendora, CA 91741 626-914-8235 Labor Day (2013) Drama What begins as a short ride turns into a life-changing event for divorced single mother Adele Wheeler and her 13-year-old son, Henry, when they give a lift to a bloodied man on a fateful Labor Day weekend. Cast: Kate Winslet, Josh Brolin, Gattlin Griffith, Tobey Maguire, Tom Lipinski, Maika Monroe, Clark Gregg, James Van Der Beek, J.K. Simmons, Brooke Smith, Brighid Fleming, Alexie Gilmore, Lucas Hedges, Micah Fowler Director: Jason Reitman 111 minutes (1 hour 51 minutes) Iron Man 3 (2013) Action & Adventure Robert Downey Jr. dons his powerful armor suit again, portraying popular Marvel comic book character industrialist Tony Stark -- aka Iron Man -- who takes on power-mad villains intent on destroying the world. Cast: Robert Downey Jr., Gwyneth Paltrow, Don Cheadle, Ben Kingsley, Guy Pearce, Rebecca Hall, James Badge Dale, Jon Favreau Director: Shane Black 130 minutes (2 hours 10 minutes) American Hustle (2013) Drama This fictionalization of the "Abscam" scandal of the early 1980s follows con man Irving Rosenfeld and his lover, Sydney Prosser, as they help an eccentric FBI agent expose corruption among several members of Congress in New Jersey and Pennsylvania. -

Christian Bale Biography - Life, Family, Children, Parents, Name, Story, History, Wife, Mother, Young
3/5/2020 Christian Bale Biography - life, family, children, parents, name, story, history, wife, mother, young World Biography (../in… / A-Ca (index.html) / Christian Bale Bio… Christian Bale Biography Christian Bale © Axel/Zuma/Corbis. January 30, 1974 • Pembrokeshire, Wales Actor Christian Bale has performed a feat that is astonishing for most Hollywood actors. Although he became a professional performer at age ten and a star at age thirteen when he played the lead in Steven Spielberg's World War II epic Empire of the Sun, Bale did not follow the usual path of the child actor. Many fall prey to the temptations of early fame and quite a few struggle to make the transition to adult movie roles—not the Welsh-born Bale, who shunned the limelight and instead focused on building an impressive body of work. Acting steadily since the late 1980s, Bale has appeared in over twenty-five films, most notably American Psycho (2000), and the critically acclaimed independent film, The Machinist (2004). Even as an adult, the modest actor steers clear of the spotlight; but considering he donned a flowing black cape to appear in Batman Begins (2005), he may not be able to maintain his usual low profile. After all, everyone wants to know the man behind the mask. Born into show biz Christian Charles Philip Bale was born on January 30, 1974, in Pembrokeshire, Wales, into a family with a long history in entertainment. His grandfather was a stand-up comic and children's entertainer; his great-uncle, Rex, was an actor; and his mother, Jenny, was a former circus performer. -

Defining Moments FORGIVENESS - Week 2 Discussion Guide
Defining Moments FORGIVENESS - Week 2 Discussion Guide This week in our Defining Moments series, we are continuing to look at how life- changing experiences can help us learn to live more like Jesus. • Who was the best Batman? (Adam West, Michael Keaton, George Clooney, Val Kilmer, Ben Affleck, Christian Bale) Revenge may be one of the most human emotions. We have a natural desire for the world to be fair. When someone violates that sense of fairness it can lead to a desire for revenge. • Have you felt the desire for revenge? • Did you act upon it? • What was the result? Judges 16:28 Then Samson prayed to the Lord, “Sovereign Lord, remember me. Please, God, strengthen me just once more, and let me with one blow get revenge on the Philistines for my two eyes.” Luke 23:34 Jesus said, “Father, forgive them, for they do not know what they are doing.” • Reflect on these two prayers and talk about the differences. • Which one of these prayers do you see yourself praying? When we seek revenge, we focus more on the event and it plays over and over in our minds. However, when we offer forgiveness, we are able to let go and move on. Your ability to give and receive forgiveness determines your freedom. • Have you experienced forgiveness from someone when you may not have deserved it? Real forgiveness is about giving up the need for revenge, for justice. Understand that it is a process, but it starts with releasing the desire for revenge. Letting go. As you do that you can start to move on.