Stack Bounds Protection with Low Fat Pointers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bounds Checking on GPU
Noname manuscript No. (will be inserted by the editor) Bounds Checking on GPU Troels Henriksen Received: date / Accepted: date Abstract We present a simple compilation strategy for safety-checking array indexing in high-level languages on GPUs. Our technique does not depend on hardware support for abnormal termination, and is designed to be efficient in the non-failing case. We rely on certain properties of array languages, namely the absence of arbitrary cross-thread communication, to ensure well-defined execution in the presence of failures. We have implemented our technique in the compiler for the functional array language Futhark, and an empirical eval- uation on 19 benchmarks shows that the geometric mean overhead of checking array indexes is respectively 4% and 6% on two different GPUs. Keywords GPU · functional programming · compilers 1 Introduction Programming languages can be divided roughly into two categories: unsafe languages, where programming errors can lead to unpredictable results at run- time; and safe languages, where all risky operations are guarded by run-time checks. Consider array indexing, where an invalid index will lead an unsafe lan- guage to read from an invalid memory address. At best, the operating system will stop the program, but at worst, the program will silently produce invalid results. A safe language will perform bounds checking to verify that the array index is within the bounds of the array, and if not, signal that something is amiss. Some languages perform an abnormal termination of the program and print an error message pointing to the offending program statement. Other languages throw an exception, allowing the problem to be handled by the pro- gram itself. -

CSE 220: Systems Programming
Memory Allocation CSE 220: Systems Programming Ethan Blanton Department of Computer Science and Engineering University at Buffalo Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Allocating Memory We have seen how to use pointers to address: An existing variable An array element from a string or array constant This lecture will discuss requesting memory from the system. © 2021 Ethan Blanton / CSE 220: Systems Programming 2 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Memory Lifetime All variables we have seen so far have well-defined lifetime: They persist for the entire life of the program They persist for the duration of a single function call Sometimes we need programmer-controlled lifetime. © 2021 Ethan Blanton / CSE 220: Systems Programming 3 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Here, global is statically allocated: It is allocated by the compiler It is created when the program starts It disappears when the program exits © 2021 Ethan Blanton / CSE 220: Systems Programming 4 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary Examples int global ; /* Lifetime of program */ void foo () { int x; /* Lifetime of foo () */ } Whereas x is automatically allocated: It is allocated by the compiler It is created when foo() is called ¶ It disappears when foo() returns © 2021 Ethan Blanton / CSE 220: Systems Programming 5 Introduction The Heap Void Pointers The Standard Allocator Allocation Errors Summary The Heap The heap represents memory that is: allocated and released at run time managed explicitly by the programmer only obtainable by address Heap memory is just a range of bytes to C. -
Memory Allocation Pushq %Rbp Java Vs
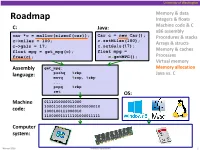
University of Washington Memory & data Roadmap Integers & floats C: Java: Machine code & C x86 assembly car *c = malloc(sizeof(car)); Car c = new Car(); Procedures & stacks c.setMiles(100); c->miles = 100; Arrays & structs c->gals = 17; c.setGals(17); float mpg = get_mpg(c); float mpg = Memory & caches free(c); c.getMPG(); Processes Virtual memory Assembly get_mpg: Memory allocation pushq %rbp Java vs. C language: movq %rsp, %rbp ... popq %rbp ret OS: Machine 0111010000011000 100011010000010000000010 code: 1000100111000010 110000011111101000011111 Computer system: Winter 2016 Memory Allocation 1 University of Washington Memory Allocation Topics Dynamic memory allocation . Size/number/lifetime of data structures may only be known at run time . Need to allocate space on the heap . Need to de-allocate (free) unused memory so it can be re-allocated Explicit Allocation Implementation . Implicit free lists . Explicit free lists – subject of next programming assignment . Segregated free lists Implicit Deallocation: Garbage collection Common memory-related bugs in C programs Winter 2016 Memory Allocation 2 University of Washington Dynamic Memory Allocation Programmers use dynamic memory allocators (such as malloc) to acquire virtual memory at run time . For data structures whose size (or lifetime) is known only at runtime Dynamic memory allocators manage an area of a process’ virtual memory known as the heap User stack Top of heap (brk ptr) Heap (via malloc) Uninitialized data (.bss) Initialized data (.data) Program text (.text) 0 Winter 2016 Memory Allocation 3 University of Washington Dynamic Memory Allocation Allocator organizes the heap as a collection of variable-sized blocks, which are either allocated or free . Allocator requests pages in heap region; virtual memory hardware and OS kernel allocate these pages to the process . -

Unleashing the Power of Allocator-Aware Software
P2126R0 2020-03-02 Pablo Halpern (on behalf of Bloomberg): [email protected] John Lakos: [email protected] Unleashing the Power of Allocator-Aware Software Infrastructure NOTE: This white paper (i.e., this is not a proposal) is intended to motivate continued investment in developing and maturing better memory allocators in the C++ Standard as well as to counter misinformation about allocators, their costs and benefits, and whether they should have a continuing role in the C++ library and language. Abstract Local (arena) memory allocators have been demonstrated to be effective at improving runtime performance both empirically in repeated controlled experiments and anecdotally in a variety of real-world applications. The initial development and subsequent maintenance effort of implementing bespoke data structures using custom memory allocation, however, are typically substantial and often untenable, especially in the limited timeframes that urgent business needs impose. To address such recurring performance needs effectively across the enterprise, Bloomberg has adopted a consistent, ubiquitous allocator-aware software infrastructure (AASI) based on the PMR-style1 plug-in memory allocator protocol pioneered at Bloomberg and adopted into the C++17 Standard Library. In this paper, we highlight the essential mechanics and subtle nuances of programing on top of Bloomberg’s AASI platform. In addition to delineating how to obtain performance gains safely at minimal development cost, we explore many of the inherent collateral benefits — such as object placement, metrics gathering, testing, debugging, and so on — that an AASI naturally affords. After reading this paper and surveying the available concrete allocators (provided in Appendix A), a competent C++ developer should be adequately equipped to extract substantial performance and other collateral benefits immediately using our AASI. -

P1083r2 | Move Resource Adaptor from Library TS to the C++ WP
P1083r2 | Move resource_adaptor from Library TS to the C++ WP Pablo Halpern [email protected] 2018-11-13 | Target audience: LWG 1 Abstract When the polymorphic allocator infrastructure was moved from the Library Fundamentals TS to the C++17 working draft, pmr::resource_adaptor was left behind. The decision not to move pmr::resource_adaptor was deliberately conservative, but the absence of resource_adaptor in the standard is a hole that must be plugged for a smooth transition to the ubiquitous use of polymorphic_allocator, as proposed in P0339 and P0987. This paper proposes that pmr::resource_adaptor be moved from the LFTS and added to the C++20 working draft. 2 History 2.1 Changes from R1 to R2 (in San Diego) • Paper was forwarded from LEWG to LWG on Tuesday, 2018-10-06 • Copied the formal wording from the LFTS directly into this paper • Minor wording changes as per initial LWG review • Rebased to the October 2018 draft of the C++ WP 2.2 Changes from R0 to R1 (pre-San Diego) • Added a note for LWG to consider clarifying the alignment requirements for resource_adaptor<A>::do_allocate(). • Changed rebind type from char to byte. • Rebased to July 2018 draft of the C++ WP. 3 Motivation It is expected that more and more classes, especially those that would not otherwise be templates, will use pmr::polymorphic_allocator<byte> to allocate memory. In order to pass an allocator to one of these classes, the allocator must either already be a polymorphic allocator, or must be adapted from a non-polymorphic allocator. The process of adaptation is facilitated by pmr::resource_adaptor, which is a simple class template, has been in the LFTS for a long time, and has been fully implemented. -

The Slab Allocator: an Object-Caching Kernel Memory Allocator
The Slab Allocator: An Object-Caching Kernel Memory Allocator Jeff Bonwick Sun Microsystems Abstract generally superior in both space and time. Finally, Section 6 describes the allocator’s debugging This paper presents a comprehensive design over- features, which can detect a wide variety of prob- view of the SunOS 5.4 kernel memory allocator. lems throughout the system. This allocator is based on a set of object-caching primitives that reduce the cost of allocating complex objects by retaining their state between uses. These 2. Object Caching same primitives prove equally effective for manag- Object caching is a technique for dealing with ing stateless memory (e.g. data pages and temporary objects that are frequently allocated and freed. The buffers) because they are space-efficient and fast. idea is to preserve the invariant portion of an The allocator’s object caches respond dynamically object’s initial state — its constructed state — to global memory pressure, and employ an object- between uses, so it does not have to be destroyed coloring scheme that improves the system’s overall and recreated every time the object is used. For cache utilization and bus balance. The allocator example, an object containing a mutex only needs also has several statistical and debugging features to have mutex_init() applied once — the first that can detect a wide range of problems throughout time the object is allocated. The object can then be the system. freed and reallocated many times without incurring the expense of mutex_destroy() and 1. Introduction mutex_init() each time. An object’s embedded locks, condition variables, reference counts, lists of The allocation and freeing of objects are among the other objects, and read-only data all generally qual- most common operations in the kernel. -

Cmsc330 Cybersecurity
cmsc330 Cybersecurity Cybersecurity Breaches Major security breaches of computer systems are a fact of life. They affect companies, governments, and individuals. Focusing on breaches of individuals' information, consider just a few examples: Equifax (2017) - 145 million consumers’ records Adobe (2013) - 150 million records, 38 million users eBay (2014) - 145 million records Anthem (2014) - Records of 80 million customers Target (2013) - 110 million records Heartland (2008) - 160 million records Vulnerabilities: Security-relevant Defects The causes of security breaches are varied but many of them, including those given above, owe to a defect (or bug) or design flaw in a targeted computer system's software. The software problem can be exploited by an attacker. An exploit is a particular, cleverly crafted input, or a series of (usually unintuitive) interactions with the system, which trigger the bug or flaw in a way that helps the attacker. Kinds of Vulnerability One obvious sort of vulnerability is a bug in security policy enforcement code. For example, suppose you are implementing an operating system and you have code to enforce access control policies on files. This is the code that makes sure that if Alice's policy says that only she is allowed to edit certain files, then user Bob will not be allowed to modify them. Perhaps your enforcement code failed to consider a corner case, and as a result Bob is able to write those files even though Alice's policy says he shouldn't. This is a vulnerability. A more surprising sort of vulnerability is a bug in code that seems to have nothing to do with enforcing security all. -

Fast Efficient Fixed-Size Memory Pool: No Loops and No Overhead
COMPUTATION TOOLS 2012 : The Third International Conference on Computational Logics, Algebras, Programming, Tools, and Benchmarking Fast Efficient Fixed-Size Memory Pool No Loops and No Overhead Ben Kenwright School of Computer Science Newcastle University Newcastle, United Kingdom, [email protected] Abstract--In this paper, we examine a ready-to-use, robust, it can be used in conjunction with an existing system to and computationally fast fixed-size memory pool manager provide a hybrid solution with minimum difficulty. On with no-loops and no-memory overhead that is highly suited the other hand, multiple instances of numerous fixed-sized towards time-critical systems such as games. The algorithm pools can be used to produce a general overall flexible achieves this by exploiting the unused memory slots for general solution to work in place of the current system bookkeeping in combination with a trouble-free indexing memory manager. scheme. We explain how it works in amalgamation with Alternatively, in some time critical systems such as straightforward step-by-step examples. Furthermore, we games; system allocations are reduced to a bare minimum compare just how much faster the memory pool manager is to make the process run as fast as possible. However, for when compared with a system allocator (e.g., malloc) over a a dynamically changing system, it is necessary to allocate range of allocations and sizes. memory for changing resources, e.g., data assets Keywords-memory pools; real-time; memory allocation; (graphical images, sound files, scripts) which are loaded memory manager; memory de-allocation; dynamic memory dynamically at runtime. -

Safe Arrays Via Regions and Dependent Types
Safe Arrays via Regions and Dependent Types Christian Grothoff1 Jens Palsberg1 Vijay Saraswat2 1 UCLA Computer Science Department University of California, Los Angeles [email protected], [email protected] 2 IBM T.J. Watson Research Center P.O. Box 704, Yorktown Heights, NY 10598, USA [email protected] Abstract. Arrays over regions of points were introduced in ZPL in the late 1990s and later adopted in Titanium and X10 as a means of simpli- fying the programming of high-performance software. A region is a set of points, rather than an interval or a product of intervals, and enables the programmer to write a loop that iterates over a region. While conve- nient, regions do not eliminate the risk of array bounds violations. Until now, language implementations have resorted to checking array accesses dynamically or to warning the programmer that bounds violations lead to undefined behavior. In this paper we show that a type system for a language with arrays over regions can guarantee that array bounds vi- olations cannot occur. We have developed a core language and a type system, proved type soundness, settled the complexity of the key deci- sion problems, implemented an X10 version which embodies the ideas of our core language, written a type checker for our X10 version, and ex- perimented with a variety of benchmark programs. Our type system uses dependent types and enables safety without dynamic bounds checks. 1 Introduction Type-safe languages allow programmers to be more productive by eliminating such difficult-to-find errors as memory corruption. However, type safety comes at a cost in runtime performance due to the need for dynamic safety checks. -

Runtime Defenses 1 Baggy Bounds Checking
Runtime Defenses Nicholas Carlini 7 September, 2011 1 Baggy Bounds Checking 1.1 Motivation There are large amounts of legacy C programs which can not be rewritten entirely. Since memory must be manually managed in C, and bounds are not checked automatically on pointer dereferences, C often contains many memory-saftey bugs. One common type of bug is buffer overflows, where the length of an array is not checked before copying data in to the array: data is written past the end of the array and on top of whatever happens to be at that memory location. 1.2 Baggy Bounds Checking Baggy bounds checking was proposed as a possible defense which would detect when pointers wrote to a memory location out of bounds. It is a runtime defense, which uses source code instrumentation. At a very high level, baggy bounds checking keeps track of bounds information on allocated objects. When a pointer which indexes in to allocated memory is dereferenced, bounds checking code ensures that the pointer still is indexing the same allocated memory location. If the pointer points out of bounds of that object, the program is halted. Baggy bounds checking uses a buddy allocator to return objects of size 2n, and fills the remaining unused bytes with 0s. A bounds table is created containing the log of the sizes of every allocated object. Using this table allows for single-memory-access lookups, which is much more efficient than other methods which require multiple memory accesses. 1.3 Baggy Bounds Checking Failures Baggy bounds checking does not work in all situations, however. -

Effective STL
Effective STL Author: Scott Meyers E-version is made by: Strangecat@epubcn Thanks is given to j1foo@epubcn, who has helped to revise this e-book. Content Containers........................................................................................1 Item 1. Choose your containers with care........................................................... 1 Item 2. Beware the illusion of container-independent code................................ 4 Item 3. Make copying cheap and correct for objects in containers..................... 9 Item 4. Call empty instead of checking size() against zero. ............................. 11 Item 5. Prefer range member functions to their single-element counterparts... 12 Item 6. Be alert for C++'s most vexing parse................................................... 20 Item 7. When using containers of newed pointers, remember to delete the pointers before the container is destroyed. ........................................................... 22 Item 8. Never create containers of auto_ptrs. ................................................... 27 Item 9. Choose carefully among erasing options.............................................. 29 Item 10. Be aware of allocator conventions and restrictions. ......................... 34 Item 11. Understand the legitimate uses of custom allocators........................ 40 Item 12. Have realistic expectations about the thread safety of STL containers. 43 vector and string............................................................................48 Item 13. Prefer vector -

Spring 2015 CS 161 Computer Security Optional Notes Memory
CS 161 Optional Notes Spring 2015 Computer Security 1 Memory safety | Attacks and Defenses In the first few lectures we will be looking at software security|problems associated with the software implementation. You may have a perfect design, a perfect specification, perfect algorithms, but still have implementation vulnerabilities. In fact, after configuration errors, implementation errors are probably the largest single class of security errors exploited in practice. We will start by looking at a particularly prevalent class of software flaws, those that concern memory safety. Memory safety refers to ensuring the integrity of a program's data structures: preventing attackers from reading or writing to memory locations other than those intended by the programmer. Because many security-critical applications have been written in C, and because C has peculiar pitfalls of its own, many of these examples will be C-specific. Implementation flaws can in fact occur at all levels: in improper use of the programming language, the libraries, the operating system, or in the application logic. We will look at some of these others later in the course. 1 Buffer overflow vulnerabilities We'll start with one of the most common types of error|buffer overflow (also called buffer overrun) vulnerabilities. Buffer overflow vulnerabilities are a particular risk in C. Since it is an especially widely used systems programming language, you might not be surprised to hear that buffer overflows are one of the most pervasive kind of implementation flaws around. As a low-level language, we can think of C as a portable assembly language. The programmer is exposed to the bare machine (which is one reason that C is such a popular systems language).