In High Performance Mysql You Will Learn About Mysql Indexing and Optimization in Depth So You Can Make Better Use of These Key Features
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mysql Workbench Mysql Workbench
MySQL Workbench MySQL Workbench Abstract This manual documents the MySQL Workbench SE version 5.2 and the MySQL Workbench OSS version 5.2. If you have not yet installed MySQL Workbench OSS please download your free copy from the download site. MySQL Workbench OSS is available for Windows, Mac OS X, and Linux. Document generated on: 2012-05-01 (revision: 30311) For legal information, see the Legal Notice. Table of Contents Preface and Legal Notice ................................................................................................................. vii 1. MySQL Workbench Introduction ..................................................................................................... 1 2. MySQL Workbench Editions ........................................................................................................... 3 3. Installing and Launching MySQL Workbench ................................................................................... 5 Hardware Requirements ............................................................................................................. 5 Software Requirements .............................................................................................................. 5 Starting MySQL Workbench ....................................................................................................... 6 Installing MySQL Workbench on Windows .......................................................................... 7 Launching MySQL Workbench on Windows ....................................................................... -

Mysql Replication Tutorial
MySQL Replication Tutorial Lars Thalmann Technical lead Replication, Backup, and Engine Technology Mats Kindahl Lead Developer Replication Technology MySQL Conference and Expo 2008 Concepts 3 MySQL Replication Why? How? 1. High Availability Snapshots (Backup) Possibility of fail-over 1. Client program mysqldump 2. Load-balancing/Scale- With log coordinates out 2. Using backup Query multiple servers InnoDB, NDB 3. Off-site processing Don’t disturb master Binary log 1. Replication Asynchronous pushing to slave 2. Point-in-time recovery Roll-forward Terminology Master MySQL Server • Changes data • Has binlog turned on Master • Pushes binlog events to slave after slave has requested them MySQL Server Slave MySQL Server • Main control point of replication • Asks master for replication log Replication • Gets binlog event from master MySQL Binary log Server • Log of everything executed Slave • Divided into transactional components • Used for replication and point-in-time recovery Terminology Synchronous replication Master • A transaction is not committed until the data MySQL has been replicated (and applied) Server • Safer, but slower • This is available in MySQL Cluster Replication Asynchronous replication • A transaction is replicated after it has been committed MySQL Server • Faster, but you can in some cases loose transactions if master fails Slave • Easy to set up between MySQL servers Configuring Replication Required configuration – my.cnf Replication Master log-bin server_id Replication Slave server_id Optional items in my.cnf – What -
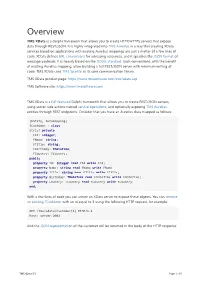
TMS Xdata Documentation
Overview TMS XData is a Delphi framework that allows you to create HTTP/HTTPS servers that expose data through REST/JSON. It is highly integrated into TMS Aurelius in a way that creating XData services based on applications with existing Aurelius mappings are just a matter of a few lines of code. XData defines URL conventions for adressing resources, and it specifies the JSON format of message payloads. It is heavily based on the OData standard. Such conventions, with the benefit of existing Aurelius mapping, allow building a full REST/JSON server with minimum writing of code. TMS XData uses TMS Sparkle as its core communication library. TMS XData product page: https://www.tmssoftware.com/site/xdata.asp TMS Software site: https://www.tmssoftware.com TMS XData is a full-featured Delphi framework that allows you to create REST/JSON servers, using server-side actions named service operations, and optionally exposing TMS Aurelius entities through REST endpoints. Consider that you have an Aurelius class mapped as follows: [Entity, Automapping] TCustomer = class strict private FId: integer; FName: string; FTitle: string; FBirthday: TDateTime; FCountry: TCountry; public property Id: Integer read FId write FId; property Name: string read FName write FName; property Title: string read FTitle write FTitle; property Birthday: TDateTime read FDateTime write FDateTime; property Country: TCountry read FCountry write FCountry; end; With a few lines of code you can create an XData server to expose these objects. You can retrieve an existing TCustomer -

Beyond Relational Databases
EXPERT ANALYSIS BY MARCOS ALBE, SUPPORT ENGINEER, PERCONA Beyond Relational Databases: A Focus on Redis, MongoDB, and ClickHouse Many of us use and love relational databases… until we try and use them for purposes which aren’t their strong point. Queues, caches, catalogs, unstructured data, counters, and many other use cases, can be solved with relational databases, but are better served by alternative options. In this expert analysis, we examine the goals, pros and cons, and the good and bad use cases of the most popular alternatives on the market, and look into some modern open source implementations. Beyond Relational Databases Developers frequently choose the backend store for the applications they produce. Amidst dozens of options, buzzwords, industry preferences, and vendor offers, it’s not always easy to make the right choice… Even with a map! !# O# d# "# a# `# @R*7-# @94FA6)6 =F(*I-76#A4+)74/*2(:# ( JA$:+49>)# &-)6+16F-# (M#@E61>-#W6e6# &6EH#;)7-6<+# &6EH# J(7)(:X(78+# !"#$%&'( S-76I6)6#'4+)-:-7# A((E-N# ##@E61>-#;E678# ;)762(# .01.%2%+'.('.$%,3( @E61>-#;(F7# D((9F-#=F(*I## =(:c*-:)U@E61>-#W6e6# @F2+16F-# G*/(F-# @Q;# $%&## @R*7-## A6)6S(77-:)U@E61>-#@E-N# K4E-F4:-A%# A6)6E7(1# %49$:+49>)+# @E61>-#'*1-:-# @E61>-#;6<R6# L&H# A6)6#'68-# $%&#@:6F521+#M(7#@E61>-#;E678# .761F-#;)7-6<#LNEF(7-7# S-76I6)6#=F(*I# A6)6/7418+# @ !"#$%&'( ;H=JO# ;(\X67-#@D# M(7#J6I((E# .761F-#%49#A6)6#=F(*I# @ )*&+',"-.%/( S$%=.#;)7-6<%6+-# =F(*I-76# LF6+21+-671># ;G';)7-6<# LF6+21#[(*:I# @E61>-#;"# @E61>-#;)(7<# H618+E61-# *&'+,"#$%&'$#( .761F-#%49#A6)6#@EEF46:1-# -

Near Real-Time Synchronization Approach for Heterogeneous Distributed Databases
DBKDA 2015 : The Seventh International Conference on Advances in Databases, Knowledge, and Data Applications Near Real-time Synchronization Approach for Heterogeneous Distributed Databases Hassen Fadoua, Grissa Touzi Amel LIPAH FST, University of Tunis El Manar Tunis, Tunisia e-mail: [email protected], [email protected] Abstract—The decentralization of organizational units led to column is not available in the list of the existing relational database distribution in order to solve high availability and database management systems (RDBMS). This storage performance issues regarding the highly exhausting consumers unit’s variety holds the first problem discussed in this paper: nowadays. The distributed database designers rely on data data exchange format between the heterogeneous nodes in replication to make data as near as possible from the the same Distributed Database Management System requesting systems. The data replication involves a sensitive (DDBMS). The process of transforming raw data from operation to keep data integrity among the distributed architecture: data synchronization. While this operation is source system to an exchange format is called serialization. necessary to almost every distributed system, it needs an in The reverse operation, executed by the receiver side, is depth study before deciding which entity to duplicate and called deserialization. In the heterogeneous context, the which site will hold the copy. Moreover, the distributed receiver side is different from one site to another, and thus environment may hold different types of databases adding the deserialization implementation may vary depending on another level of complexity to the synchronization process. In the local DBMS. This data serialization is a very sensitive the near real-time duplication process, the synchronization task that may speed down the synchronization process and delay is a crucial criterion that may change depending on flood the network. -

XAMPP Web Development Stack
XAMPP Web Development Stack Overview @author R.L. Martinez, Ph.D. The steps below outline the processes for installing the XAMPP stack on a local machine. The XAMPP (pronounced Zamp) stack includes the following: Apache HTTP Server, MariaDB (essentially MySQL), Database Server, Perl, and the PHP Interpreter. The “X” in XAMPP is used to signify the cross-platform compatibility of the stack. The Apache HTTP Server and PHP are required to run phpMyAdmin which is a PHP application that is used for database administration tasks such as creating databases and tables, adding users, etc. Alternative to XAMPP If you have experience with MySQL Workbench, you may prefer to install MySQL Server and MySQL Workbench via the MySQL Installer. MySQL Workbench performs the same functions as phpMyAdmin. However, unlike phpMyAdmin which is a web-based application, MySQL Workbench is a locally installed application and therefore does not require an HTTP Server (e.g. Apache) to run. Installing XAMPP Many of the steps listed have several alternatives (such as changing MySQL passwords via a command line) and students are welcomed and encouraged to explore alternatives. 1. Download XAMPP from the URL below and place the installer (.exe) in the location where you want to install XAMPP. Placing the installer (.exe) in the same location as the intended installation is not required but preferred. http://www.apachefriends.org/download.html Page 1 of 17 XAMPP Web Development Stack 2. See the warning which recommends not installing to C:\Program Files (x86) which can be restricted by UAC (User Account Control). In the steps below XAMPP is installed to a USB flash drive for portability. -

Mariadb Presentation
THE VALUE OF OPEN SOURCE MICHAEL ”MONTY” WIDENIUS Entrepreneur, MariaDB Hacker, MariaDB CTO MariaDB Corporation AB 2019-09-25 Seoul 11 Reasons Open Source is Better than Closed Source ● Using open standards (no lock in into proprietary standards) ● Resource friendly; OSS software tend to work on old hardware ● Lower cost; Usually 1/10 of closed source software ● No cost for testing the full software ● Better documentation and more troubleshooting resources ● Better support, in many cases directly from the developers ● Better security, auditability (no trap doors and more eye balls) ● Better quality; Developed together with users ● Better customizability; You can also participate in development ● No vendor lock in; More than one vendor can give support ● When using open source, you take charge of your own future Note that using open source does not mean that you have to become a software producer! OPEN SOURCE, THE GOOD AND THE BAD ● Open source is a better way to develop software ● More developers ● More spread ● Better code (in many cases) ● Works good for projects that can freely used by a lot of companies in their production or products. ● It's very hard to create a profitable company developing an open source project. ● Not enough money to pay developers. ● Hard to get money and investors for most projects (except for infrastructure projects like libraries or daemon services). OPEN SOURCE IS NATURAL OR WHY OPEN SOURCE WORKS ● You use open source because it's less expensive (and re-usable) ● You solve your own problems and get free help and development efforts from others while doing it. -

High Performance Mysql Other Microsoft .NET Resources from O’Reilly
High Performance MySQL Other Microsoft .NET resources from O’Reilly Related titles Managing and Using MySQL PHP Cookbook™ MySQL Cookbook™ Practical PostgreSQL MySQL Pocket Reference Programming PHP MySQL Reference Manual SQL Tuning Learning PHP Web Database Applications PHP 5 Essentials with PHP and MySQL .NET Books dotnet.oreilly.com is a complete catalog of O’Reilly’s books on Resource Center .NET and related technologies, including sample chapters and code examples. ONDotnet.com provides independent coverage of fundamental, interoperable, and emerging Microsoft .NET programming and web services technologies. Conferences O’Reilly Media bring diverse innovators together to nurture the ideas that spark revolutionary industries. We specialize in docu- menting the latest tools and systems, translating the innovator’s knowledge into useful skills for those in the trenches. Visit con- ferences.oreilly.com for our upcoming events. Safari Bookshelf (safari.oreilly.com) is the premier online refer- ence library for programmers and IT professionals. Conduct searches across more than 1,000 books. Subscribers can zero in on answers to time-critical questions in a matter of seconds. Read the books on your Bookshelf from cover to cover or sim- ply flip to the page you need. Try it today for free. SECOND EDITION High Performance MySQL Baron Schwartz, Peter Zaitsev, Vadim Tkachenko, Jeremy D. Zawodny, Arjen Lentz, and Derek J. Balling Beijing • Cambridge • Farnham • Köln • Sebastopol • Taipei • Tokyo High Performance MySQL, Second Edition by Baron Schwartz, Peter Zaitsev, Vadim Tkachenko, Jeremy D. Zawodny, Arjen Lentz, and Derek J. Balling Copyright © 2008 O’Reilly Media, Inc. All rights reserved. Printed in the United States of America. -

Mysql Administration Contents 1 Introduction 2 Server Configuration
SA|MySQL Administration Page 1 1 -- From Linux command-line: MySQL Administration 2 sudo install mysql-server mysql by Terry Sergeant 3 sudo mysql_secure_installation 4 mysql -u root 5 Contents 6 -- now we are in the MySQL client: 7 SELECT user, host, authentication_string, plugin FROM mysql.user; 1 Introduction 1 8 ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password'; 1.1 Installation . 1 9 FLUSH PRIVILEGES; 1.2 First Steps . 1 10 \q 1.3 Some Other Useful Commands . 1 11 12 -- Back at Linux command-line ... test new password 2 Server Configuration 1 13 mysql -u root -p 2.1 SQL Mode . 1 2.2 Logging . 2 1.3 Some Other Useful Commands 3 MySQL Clients 2 From Linux command-line: 4 Data Types 2 1 systemctl status mysql 4.1 Numeric . 2 2 systemctl restart mysql 4.2 Character . 2 3 systemctl enable mysql 4.3 Binary . 2 4 systemctl is-enabled mysql 4.4 Temporal . 2 4.5 Other . 2 From MySQL command-line: 5 Obtaining Metadata 3 1 show databases; 2 use DBNAME; 6 Storage Engines 3 3 show tables; 6.1 MyISAM (default) . 3 4 desc TNAME; 6.2 InnoDB . 3 5 create database DBNAME; 6.3 InnoBase . 3 6 source SQLFILE; -- same as \. SQLFILE 6.4 MEMORY . 3 7 select @@datadir; 6.5 Other Engines . 3 7 Security and User Management 3 2 Server Configuration 7.1 Risks . 3 7.2 Some Commands . 3 Here are some common ways to tweak the server's configuration. 8 Backup and Recovery 4 mysqld --verbose --help (to see runtime options sup- 8.1 Backup Types . -

Navicat Wine En.Pdf
Table of Contents Getting Started 8 System Requirements 9 Registration 9 Installation 10 Maintenance/Upgrade 11 End-User License Agreement 11 Connection 17 Navicat Cloud 18 General Settings 21 Advanced Settings 24 SSL Settings 27 SSH Settings 28 HTTP Settings 29 Server Objects 31 MySQL/MariaDB Objects 31 MySQL Tables 31 MySQL/MariaDB Table Fields 32 MySQL/MariaDB Table Indexes 34 MySQL/MariaDB Table Foreign Keys 35 MySQL/MariaDB Table Triggers 36 MySQL/MariaDB Table Options 37 MySQL/MariaDB Views 40 MySQL/MariaDB Functions/Procedures 41 MySQL/MariaDB Events 43 Oracle Objects 44 Oracle Data Pump (Available only in Full Version) 44 Oracle Data Pump Export 45 Oracle Data Pump Import 48 Oracle Debugger (Available only in Full Version) 52 Oracle Physical Attributes/Default Storage Characteristics 53 Oracle Tables 55 Oracle Normal Tables 55 Oracle Table Fields 55 Oracle Table Indexes 57 Oracle Table Foreign Keys 58 Oracle Table Uniques 59 Oracle Table Checks 59 Oracle Table Triggers 60 Oracle Table Options 61 Oracle External Tables 62 2 Fields for Oracle External Tables 62 External Properties for Oracle External Tables 63 Access Parameters for Oracle External Tables 64 Oracle Index Organized Tables 64 Options for Oracle Index Organized Tables 64 Oracle Views 65 Oracle Functions/Procedures 66 Oracle Database Links 68 Oracle Indexes 68 Oracle Java 71 Oracle Materialized Views 72 Oracle Materialized View Logs 75 Oracle Packages 76 Oracle Sequences 77 Oracle Synonyms 78 Oracle Triggers 78 Oracle Types 81 Oracle XML Schemas 82 Oracle Recycle Bin -

Mysql Database Administrator
MySQL Database Administrator Author: Kacper Wysocki Contact: [email protected] Date: December 2010 License: Creative Commons: CC BY-SA Oslo, December 2010, CC BY-SA Contents Introduction 5 Introductions everybody 5 About this course 5 Course outline 6 Course schedule 6 How to do excersies 6 MySQL: history and future 6 MySQL: the present 7 MySQL: the future 7 MySQL compared to other DBs 7 MySQL language support 8 Embedding MySQL 8 Getting help with MySQL 8 MySQL architecture 9 Modular architecture 9 The MySQL modules 9 Client/server architecture 10 Installing MySQL 10 Installation process 10 Distribution packages 11 MySQL official binaries 11 Deploying sandboxes 12 Installing from source 13 Server Startup and Shutdown 14 MySQL relevant files 15 Excersises: Installation 15 Upgrading MySQL 16 Clients: the mysql* suite 16 Client: mysql 16 Excersise: Client mysql 16 Excersise: mysql CLI 17 Further CLI fun 17 Digression: some SQL 18 Client: mysqladmin 18 Excersises: Client: mysql 18 Clients: applications and libraries 18 Oslo, December 2010, CC BY-SA migration 19 Importing data: timezones 19 Importing data 19 Excersises: importing data 20 Excersises: time zones 20 Exporting data 20 Excersises: Exporting data 21 Configuration 21 More configuration 21 Run-time Variables 22 MySQL Architecture 23 Storage Engines 23 Storage Engines 23 Storage Engines types 23 MyISAM 24 MYISAM_MRG 24 InnoDB 24 Excersises: InnoDB 24 FEDERATED 25 CSV 25 ARCHIVE 25 MEMORY 25 BLACKHOLE 25 So... which engine? 26 Engine Excersises 26 Implementing Security 26 -

How Mysql Handles ORDER BY, GROUP BY, and DISTINCT
How MySQL handles ORDER BY, GROUP BY, and DISTINCT Sergey Petrunia, [email protected] MySQL University Session November 1, 2007 Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 1 Handling ORDER BY • Available means to produce ordered streams: – Use an ordered index • range access – not with MyISAM/InnoDB's DS-MRR – not with Falcon – Has extra (invisible) cost with NDB • ref access (but not ref-or-null) results of ref(t.keypart1=const) are ordered by t.keypart2, t.keypart3, ... • index access – Use filesort Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 2 Executing join and producing ordered stream There are three ways to produce ordered join output Method EXPLAIN shows Use an ordered index Nothing particular Use filesort() on 1st non-constant table “Using filesort” in the first row Put join result into a temporary table “Using temporary; Using filesort” in the and use filesort() on it first row EXPLAIN is a bit counterintuitive: id select_type table type possible_keys key key_len ref rows Extra Using where; 1 SIMPLE t2 range a a 5 NULL 10 Using temporary; Using filesort 1 SIMPLE t2a ref a a 5 t2.b 1 Using where Copyright 2007 MySQL AB The World’s Most Popular Open Source Database 3 Using index to produce ordered join result • ORDER BY must use columns from one index • DESC is ok if it is present for all columns • Equality propagation: – “a=b AND b=const” is detected – “WHERE x=t.key ORDER BY x” is not • Cannot use join buffering – Use of matching join order disables use of join buffering.