Lecture 6: 04 October 2018 6.1 Gradient Descent
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Math 2374: Multivariable Calculus and Vector Analysis
Math 2374: Multivariable Calculus and Vector Analysis Part 25 Fall 2012 Extreme points Definition If f : U ⊂ Rn ! R is a scalar function, • a point x0 2 U is called a local minimum of f if there is a neighborhood V of x0 such that for all points x 2 V, f (x) ≥ f (x0), • a point x0 2 U is called a local maximum of f if there is a neighborhood V of x0 such that for all points x 2 V, f (x) ≤ f (x0), • a point x0 2 U is called a local, or relative, extremum of f if it is either a local minimum or a local maximum, • a point x0 2 U is called a critical point of f if either f is not differentiable at x0 or if rf (x0) = Df (x0) = 0, • a critical point that is not a local extremum is called a saddle point. First Derivative Test for Local Extremum Theorem If U ⊂ Rn is open, the function f : U ⊂ Rn ! R is differentiable, and x0 2 U is a local extremum, then Df (x0) = 0; that is, x0 is a critical point. Proof. Suppose that f achieves a local maximum at x0, then for all n h 2 R , the function g(t) = f (x0 + th) has a local maximum at t = 0. Thus from one-variable calculus g0(0) = 0. By chain rule 0 g (0) = [Df (x0)] h = 0 8h So Df (x0) = 0. Same proof for a local minimum. Examples Ex-1 Find the maxima and minima of the function f (x; y) = x2 + y 2. -

A Stability Boundary Based Method for Finding Saddle Points on Potential Energy Surfaces
JOURNAL OF COMPUTATIONAL BIOLOGY Volume 13, Number 3, 2006 © Mary Ann Liebert, Inc. Pp. 745–766 A Stability Boundary Based Method for Finding Saddle Points on Potential Energy Surfaces CHANDAN K. REDDY and HSIAO-DONG CHIANG ABSTRACT The task of finding saddle points on potential energy surfaces plays a crucial role in under- standing the dynamics of a micromolecule as well as in studying the folding pathways of macromolecules like proteins. The problem of finding the saddle points on a high dimen- sional potential energy surface is transformed into the problem of finding decomposition points of its corresponding nonlinear dynamical system. This paper introduces a new method based on TRUST-TECH (TRansformation Under STability reTained Equilibria CHaracter- ization) to compute saddle points on potential energy surfaces using stability boundaries. Our method explores the dynamic and geometric characteristics of stability boundaries of a nonlinear dynamical system. A novel trajectory adjustment procedure is used to trace the stability boundary. Our method was successful in finding the saddle points on different potential energy surfaces of various dimensions. A simplified version of the algorithm has also been used to find the saddle points of symmetric systems with the help of some analyt- ical knowledge. The main advantages and effectiveness of the method are clearly illustrated with some examples. Promising results of our method are shown on various problems with varied degrees of freedom. Key words: potential energy surfaces, saddle points, stability boundary, minimum gradient point, computational chemistry. I. INTRODUCTION ecently, there has been a lot of interest across various disciplines to understand a wide Rvariety of problems related to bioinformatics. -

Tutorial 8: Solutions
Tutorial 8: Solutions Applications of the Derivative 1. We are asked to find the absolute maximum and minimum values of f on the given interval, and state where those values occur: (a) f(x) = 2x3 + 3x2 12x on [1; 4]. − The absolute extrema occur either at a critical point (stationary point or point of non-differentiability) or at the endpoints. The stationary points are given by f 0(x) = 0, which in this case gives 6x2 + 6x 12 = 0 = x = 1; x = 2: − ) − Checking the values at the critical points (only x = 1 is in the interval [1; 4]) and endpoints: f(1) = 7; f(4) = 128: − Therefore the absolute maximum occurs at x = 4 and is given by f(4) = 124 and the absolute minimum occurs at x = 1 and is given by f(1) = 7. − (b) f(x) = (x2 + x)2=3 on [ 2; 3] − As before, we find the critical points. The derivative is given by 2 2x + 1 f 0(x) = 3 (x2 + x)1=2 and hence we have a stationary point when 2x + 1 = 0 and points of non- differentiability whenever x2 + x = 0. Solving these, we get the three critical points, x = 1=2; and x = 0; 1: − − Checking the value of the function at these critical points and the endpoints: f( 2) = 22=3; f( 1) = 0; f( 1=2) = 2−4=3; f(0) = 0; f(3) = (12)2=3: − − − Hence the absolute minimum occurs at either x = 1 or x = 0 since in both − these cases the minimum value is 0, while the absolute maximum occurs at x = 3 and is f(3) = (12)2=3. -

3.2 Sources, Sinks, Saddles, and Spirals
3.2. Sources, Sinks, Saddles, and Spirals 161 3.2 Sources, Sinks, Saddles, and Spirals The pictures in this section show solutions to Ay00 By0 Cy 0. These are linear equations with constant coefficients A; B; and C .C The graphsC showD solutions y on the horizontal axis and their slopes y0 dy=dt on the vertical axis. These pairs .y.t/;y0.t// depend on time, but time is not inD the pictures. The paths show where the solution goes, but they don’t show when. Each specific solution starts at a particular point .y.0/;y0.0// given by the initial conditions. The point moves along its path as the time t moves forward from t 0. D We know that the solutions to Ay00 By0 Cy 0 depend on the two solutions to 2 C C D As Bs C 0 (an ordinary quadratic equation for s). When we find the roots s1 and C C D s2, we have found all possible solutions : s1t s2t s1t s2t y c1e c2e y c1s1e c2s2e (1) D C 0 D C The numbers s1 and s2 tell us which picture we are in. Then the numbers c1 and c2 tell us which path we are on. Since s1 and s2 determine the picture for each equation, it is essential to see the six possibilities. We write all six here in one place, to compare them. Later they will appear in six different places, one with each figure. The first three have real solutions s1 and s2. The last three have complex pairs s a i!. -
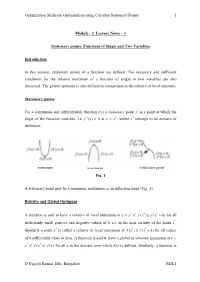
Lecture Notes – 1
Optimization Methods: Optimization using Calculus-Stationary Points 1 Module - 2 Lecture Notes – 1 Stationary points: Functions of Single and Two Variables Introduction In this session, stationary points of a function are defined. The necessary and sufficient conditions for the relative maximum of a function of single or two variables are also discussed. The global optimum is also defined in comparison to the relative or local optimum. Stationary points For a continuous and differentiable function f(x) a stationary point x* is a point at which the slope of the function vanishes, i.e. f ’(x) = 0 at x = x*, where x* belongs to its domain of definition. minimum maximum inflection point Fig. 1 A stationary point may be a minimum, maximum or an inflection point (Fig. 1). Relative and Global Optimum A function is said to have a relative or local minimum at x = x* if f ()xfxh**≤+ ( )for all sufficiently small positive and negative values of h, i.e. in the near vicinity of the point x*. Similarly a point x* is called a relative or local maximum if f ()xfxh**≥+ ( )for all values of h sufficiently close to zero. A function is said to have a global or absolute minimum at x = x* if f ()xfx* ≤ ()for all x in the domain over which f(x) is defined. Similarly, a function is D Nagesh Kumar, IISc, Bangalore M2L1 Optimization Methods: Optimization using Calculus-Stationary Points 2 said to have a global or absolute maximum at x = x* if f ()xfx* ≥ ()for all x in the domain over which f(x) is defined. -

Lecture 8: Maxima and Minima
Maxima and minima Lecture 8: Maxima and Minima Rafikul Alam Department of Mathematics IIT Guwahati Rafikul Alam IITG: MA-102 (2013) Maxima and minima Local extremum of f : Rn ! R Let f : U ⊂ Rn ! R be continuous, where U is open. Then • f has a local maximum at p if there exists r > 0 such that f (x) ≤ f (p) for x 2 B(p; r): • f has a local minimum at a if there exists > 0 such that f (x) ≥ f (p) for x 2 B(p; ): A local maximum or a local minimum is called a local extremum. Rafikul Alam IITG: MA-102 (2013) Maxima and minima Figure: Local extremum of z = f (x; y) Rafikul Alam IITG: MA-102 (2013) Maxima and minima Necessary condition for extremum of Rn ! R Critical point: A point p 2 U is a critical point of f if rf (p) = 0: Thus, when f is differentiable, the tangent plane to z = f (x) at (p; f (p)) is horizontal. Theorem: Suppose that f has a local extremum at p and that rf (p) exists. Then p is a critical point of f , i.e, rf (p) = 0: 2 2 Example: Consider f (x; y) = x − y : Then fx = 2x = 0 and fy = −2y = 0 show that (0; 0) is the only critical point of f : But (0; 0) is not a local extremum of f : Rafikul Alam IITG: MA-102 (2013) Maxima and minima Saddle point Saddle point: A critical point of f that is not a local extremum is called a saddle point of f : Examples: 2 2 • The point (0; 0) is a saddle point of f (x; y) = x − y : 2 2 2 • Consider f (x; y) = x y + y x: Then fx = 2xy + y = 0 2 and fy = 2xy + x = 0 show that (0; 0) is the only critical point of f : But (0; 0) is a saddle point. -

Calculus and Differential Equations II
Calculus and Differential Equations II MATH 250 B Linear systems of differential equations Linear systems of differential equations Calculus and Differential Equations II Second order autonomous linear systems We are mostly interested with2 × 2 first order autonomous systems of the form x0 = a x + b y y 0 = c x + d y where x and y are functions of t and a, b, c, and d are real constants. Such a system may be re-written in matrix form as d x x a b = M ; M = : dt y y c d The purpose of this section is to classify the dynamics of the solutions of the above system, in terms of the properties of the matrix M. Linear systems of differential equations Calculus and Differential Equations II Existence and uniqueness (general statement) Consider a linear system of the form dY = M(t)Y + F (t); dt where Y and F (t) are n × 1 column vectors, and M(t) is an n × n matrix whose entries may depend on t. Existence and uniqueness theorem: If the entries of the matrix M(t) and of the vector F (t) are continuous on some open interval I containing t0, then the initial value problem dY = M(t)Y + F (t); Y (t ) = Y dt 0 0 has a unique solution on I . In particular, this means that trajectories in the phase space do not cross. Linear systems of differential equations Calculus and Differential Equations II General solution The general solution to Y 0 = M(t)Y + F (t) reads Y (t) = C1 Y1(t) + C2 Y2(t) + ··· + Cn Yn(t) + Yp(t); = U(t) C + Yp(t); where 0 Yp(t) is a particular solution to Y = M(t)Y + F (t). -

The Theory of Stationary Point Processes By
THE THEORY OF STATIONARY POINT PROCESSES BY FREDERICK J. BEUTLER and OSCAR A. Z. LENEMAN (1) The University of Michigan, Ann Arbor, Michigan, U.S.A. (3) Table of contents Abstract .................................... 159 1.0. Introduction and Summary ......................... 160 2.0. Stationarity properties for point processes ................... 161 2.1. Forward recurrence times and points in an interval ............. 163 2.2. Backward recurrence times and stationarity ................ 167 2.3. Equivalent stationarity conditions .................... 170 3.0. Distribution functions, moments, and sample averages of the s.p.p ......... 172 3.1. Convexity and absolute continuity .................... 172 3.2. Existence and global properties of moments ................ 174 3.3. First and second moments ........................ 176 3.4. Interval statistics and the computation of moments ............ 178 3.5. Distribution of the t n .......................... 182 3.6. An ergodic theorem ........................... 184 4.0. Classes and examples of stationary point processes ............... 185 4.1. Poisson processes ............................ 186 4.2. Periodic processes ........................... 187 4.3. Compound processes .......................... 189 4.4. The generalized skip process ....................... 189 4.5. Jitte processes ............................ 192 4.6. ~deprendent identically distributed intervals ................ 193 Acknowledgments ............................... 196 References ................................... 196 Abstract An axiomatic formulation is presented for point processes which may be interpreted as ordered sequences of points randomly located on the real line. Such concepts as forward recurrence times and number of points in intervals are defined and related in set-theoretic Q) Presently at Massachusetts Institute of Technology, Lexington, Mass., U.S.A. (2) This work was supported by the National Aeronautics and Space Administration under research grant NsG-2-59. 11 - 662901. Aeta mathematica. 116. Imprlm$ le 19 septembre 1966. -

Maxima, Minima, and Saddle Points
Real Analysis III (MAT312β) Department of Mathematics University of Ruhuna A.W.L. Pubudu Thilan Department of Mathematics University of Ruhuna | Real Analysis III(MAT312β) 1/80 Chapter 12 Maxima, Minima, and Saddle Points Department of Mathematics University of Ruhuna | Real Analysis III(MAT312β) 2/80 Introduction A scientist or engineer will be interested in the ups and downs of a function, its maximum and minimum values, its turning points. For instance, locating extreme values is the basic objective of optimization. In the simplest case, an optimization problem consists of maximizing or minimizing a real function by systematically choosing input values from within an allowed set and computing the value of the function. Department of Mathematics University of Ruhuna | Real Analysis III(MAT312β) 3/80 Introduction Cont... Drawing a graph of a function using a computer graph plotting package will reveal behavior of the function. But if we want to know the precise location of maximum and minimum points, we need to turn to algebra and differential calculus. In this Chapter we look at how we can find maximum and minimum points in this way. Department of Mathematics University of Ruhuna | Real Analysis III(MAT312β) 4/80 Chapter 12 Section 12.1 Single Variable Functions Department of Mathematics University of Ruhuna | Real Analysis III(MAT312β) 5/80 Local maximum and local minimum The local maximum and local minimum (plural: maxima and minima) of a function, are the largest and smallest value that the function takes at a point within a given interval. It may not be the minimum or maximum for the whole function, but locally it is. -

Analysis of Asymptotic Escape of Strict Saddle Sets in Manifold Optimization
Analysis of Asymptotic Escape of Strict Saddle Sets in Manifold Optimization Thomas Y. Hou∗ , Zhenzhen Li y , and Ziyun Zhang z Abstract. In this paper, we provide some analysis on the asymptotic escape of strict saddles in manifold optimization using the projected gradient descent (PGD) algorithm. One of our main contributions is that we extend the current analysis to include non-isolated and possibly continuous saddle sets with complicated geometry. We prove that the PGD is able to escape strict critical submanifolds under certain conditions on the geometry and the distribution of the saddle point sets. We also show that the PGD may fail to escape strict saddles under weaker assumptions even if the saddle point set has zero measure and there is a uniform escape direction. We provide a counterexample to illustrate this important point. We apply this saddle analysis to the phase retrieval problem on the low-rank matrix manifold, prove that there are only a finite number of saddles, and they are strict saddles with high probability. We also show the potential application of our analysis for a broader range of manifold optimization problems. Key words. Manifold optimization, projected gradient descent, strict saddles, stable manifold theorem, phase retrieval AMS subject classifications. 58D17, 37D10, 65F10, 90C26 1. Introduction. Manifold optimization has long been studied in mathematics. From signal and imaging science [38][7][36], to computer vision [47][48] and quantum informa- tion [40][16][29], it finds applications in various disciplines. -

Instability Analysis of Saddle Points by a Local Minimax Method
INSTABILITY ANALYSIS OF SADDLE POINTS BY A LOCAL MINIMAX METHOD JIANXIN ZHOU Abstract. The objective of this work is to develop some tools for local insta- bility analysis of multiple critical points, which can be computationally carried out. The Morse index can be used to measure local instability of a nondegen- erate saddle point. However, it is very expensive to compute numerically and is ineffective for degenerate critical points. A local (weak) linking index can also be defined to measure local instability of a (degenerate) saddle point. But it is still too difficult to compute. In this paper, a local instability index, called a local minimax index, is defined by using a local minimax method. This new instability index is known beforehand and can help in finding a saddle point numerically. Relations between the local minimax index and other local insta- bility indices are established. Those relations also provide ways to numerically compute the Morse, local linking indices. In particular, the local minimax index can be used to define a local instability index of a saddle point relative to a reference (trivial) critical point even in a Banach space while others failed to do so. 1. Introduction Multiple solutions with different performance, maneuverability and instability in- dices exist in many nonlinear problems in natural or social sciences [1,7, 9,24,29,31, 33,35]. When cases are variational, the problems reduce to solving the Euler- Lagrange equation (1.1) J 0(u) = 0; where J is a C1 generic energy functional on a Banach space H and J 0 its Frechet derivative. -

Gradient Descent Can Take Exponential Time to Escape Saddle Points
Gradient Descent Can Take Exponential Time to Escape Saddle Points Simon S. Du Chi Jin Carnegie Mellon University University of California, Berkeley [email protected] [email protected] Jason D. Lee Michael I. Jordan University of Southern California University of California, Berkeley [email protected] [email protected] Barnabás Póczos Aarti Singh Carnegie Mellon University Carnegie Mellon University [email protected] [email protected] Abstract Although gradient descent (GD) almost always escapes saddle points asymptot- ically [Lee et al., 2016], this paper shows that even with fairly natural random initialization schemes and non-pathological functions, GD can be significantly slowed down by saddle points, taking exponential time to escape. On the other hand, gradient descent with perturbations [Ge et al., 2015, Jin et al., 2017] is not slowed down by saddle points—it canfind an approximate local minimizer in polynomial time. This result implies that GD is inherently slower than perturbed GD, and justifies the importance of adding perturbations for efficient non-convex optimization. While our focus is theoretical, we also present experiments that illustrate our theoreticalfindings. 1 Introduction Gradient Descent (GD) and its myriad variants provide the core optimization methodology in machine learning problems. Given a functionf(x), the basic GD method can be written as: x(t+1) x (t) η f x(t) , (1) ← − ∇ where η is a step size, assumedfixed in the current paper.� While� precise characterizations of the rate of convergence GD are available for convex problems, there is far less understanding of GD for non-convex problems. Indeed, for general non-convex problems, GD is only known tofind a stationary point (i.e., a point where the gradient equals zero) in polynomial time [Nesterov, 2013].