Developing Language Processing Components with GATE Version 4 (A User Guide)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Merchandise Planning and Optimization Licensing Information
Oracle® Retail Merchandise Planning and Optimization Licensing Information July 2009 This document provides licensing information for all the third-party applications used by the following Oracle Retail applications: ■ Oracle Retail Clearance Optimization Engine ■ Oracle Retail Markdown Optimization ■ Oracle Retail Place ■ Oracle Retail Plan ■ Oracle Retail Promote (PPO and PI) Prerequisite Softwares and Licenses Oracle Retail products depend on the installation of certain essential products (with commercial licenses), but the company does not bundle these third-party products within its own installation media. Acquisition of licenses for these products should be handled directly with the vendor. The following products are not distributed along with the Oracle Retail product installation media: ® ■ BEA WebLogic Server (http://www.bea.com) ™ ■ MicroStrategy Desktop (http://www.microstrategy.com) ■ MicroStrategy Intelligence Server™ and Web Universal (http://www.microstrategy.com) ® ■ Oracle Database 10g (http://www.oracle.com) ® ■ Oracle Application Server 10g (http://www.oracle.com) ® ■ Oracle Business Intelligence Suite Enterprise Edition Version 10 (http://www.oracle.com) ■ rsync (http://samba.anu.edu.au/rsync/). See rsync License. 1 Softwares and Licenses Bundled with Oracle Retail Products The following third party products are bundled along with the Oracle Retail product code and Oracle has acquired the necessary licenses to bundle the software along with the Oracle Retail product: ■ addObject.com NLSTree Professional version 2.3 -

Open Source Used in Cisco Unity Connection 11.5 SU 1
Open Source Used In Cisco Unity Connection 11.5 SU 1 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-132949842 Open Source Used In Cisco Unity Connection 11.5 SU 1 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-132949842 Contents 1.1 ace 5.3.5 1.1.1 Available under license 1.2 Apache Commons Beanutils 1.6 1.2.1 Notifications 1.2.2 Available under license 1.3 Apache Derby 10.8.1.2 1.3.1 Available under license 1.4 Apache Mina 2.0.0-RC1 1.4.1 Available under license 1.5 Apache Standards Taglibs 1.1.2 1.5.1 Available under license 1.6 Apache STRUTS 1.2.4. 1.6.1 Available under license 1.7 Apache Struts 1.2.9 1.7.1 Available under license 1.8 Apache Xerces 2.6.2. 1.8.1 Notifications 1.8.2 Available under license 1.9 axis2 1.3 1.9.1 Available under license 1.10 axis2/cddl 1.3 1.10.1 Available under license 1.11 axis2/cpl 1.3 1.11.1 Available under license 1.12 BeanUtils(duplicate) 1.6.1 1.12.1 Notifications Open Source Used In Cisco Unity Connection -

XML for Java Developers G22.3033-002 Course Roadmap
XML for Java Developers G22.3033-002 Session 1 - Main Theme Markup Language Technologies (Part I) Dr. Jean-Claude Franchitti New York University Computer Science Department Courant Institute of Mathematical Sciences 1 Course Roadmap Consider the Spectrum of Applications Architectures Distributed vs. Decentralized Apps + Thick vs. Thin Clients J2EE for eCommerce vs. J2EE/Web Services, JXTA, etc. Learn Specific XML/Java “Patterns” Used for Data/Content Presentation, Data Exchange, and Application Configuration Cover XML/Java Technologies According to their Use in the Various Phases of the Application Development Lifecycle (i.e., Discovery, Design, Development, Deployment, Administration) e.g., Modeling, Configuration Management, Processing, Rendering, Querying, Secure Messaging, etc. Develop XML Applications as Assemblies of Reusable XML- Based Services (Applications of XML + Java Applications) 2 1 Agenda XML Generics Course Logistics, Structure and Objectives History of Meta-Markup Languages XML Applications: Markup Languages XML Information Modeling Applications XML-Based Architectures XML and Java XML Development Tools Summary Class Project Readings Assignment #1a 3 Part I Introduction 4 2 XML Generics XML means eXtensible Markup Language XML expresses the structure of information (i.e., document content) separately from its presentation XSL style sheets are used to convert documents to a presentation format that can be processed by a target presentation device (e.g., HTML in the case of legacy browsers) Need a -
5241 Index 0939-0964.Qxd 29/08/02 5.30 Pm Page 941
5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 941 INDEX 941 5241_index_0939-0964.qxd 29/08/02 5.30 pm Page 942 Index 942 Regular A Alternatives, 362 Analysis Patterns: Reusable Expression ABSENT value, 67 Object Models, 521 Symbols abstract attribute, 62, 64–66 ancestor (XPath axis), 54 of complexType element, ancestor-or-self (XPath axis), . escape character, 368, 369 247–248, 512, 719 54 . metacharacter, 361 of element element, 148–149 Annotation, 82 ? metacharacter, 361, 375 mapping to object-oriented defined, 390 ( metacharacter, 361 language, 513–514 mapping to object-oriented ) metacharacter, 361 Abstract language, 521 { metacharacter, 361 attribute type, 934 Microsoft use of term, } metacharacter, 361 defined, 58 821–822 + metacharacter, 361, 375 element type, 16, 17, 18, 934 properties of, 411 * metacharacter, 361, 375 object, corresponding to docu- annotation content option ^ metacharacter, 379 ment, 14 for schema element, 115 \ metacharacter, 361 uses of term, 238, 931–932 annotation element, 82, 83, | metacharacter, 361 Abstract character, 67 254, 260, 722, 859 \. escape character, 366 Abstract document attributes of, 118 \? escape character, 366 document information item content options for, 118–119 \( escape character, 367 view of, 62 example of use of, 117 \) escape character, 367 infoset view of, 62 function of, 116, 124, 128 \{ escape character, 367 makeup of, 59 nested, 83–84 \} escape character, 367 properties of, 66 Anonymous component, 82 \+ escape character, 367 Abstract element, 14–15 any element, 859 \- escape character, -

Oncommand Core Package Software Products
Notices About this information The following copyright statements and licenses apply to software components that are distributed with various versions of the OnCommand Core package software products. Your product does not necessarily use all the software components referred to below. Where required, source code is published at the following location: ftp://ftp.netapp.com/frm-ntap/opensource/ Copyrights and licenses The following components are subject to the Apache License 1.1: ◆ Apache Tomcat - 5.0.20 Copyright © 2004 The Apache Software Foundation. All rights reserved. ◆ Apache-HTTP Server - 1.1.1 Copyright © 2000-2002 The Apache Software Foundation. All rights reserved. ◆ Apache Jakarta BCEL 5 Copyright © 2001 The Apache Software Foundation. All rights reserved. ◆ Apache Xerces Java XML Parser 2.6.1 Copyright © 1999- 2003 The Apache Software Foundation. All rights reserved. ◆ Apache Base64 functions 1.1 Copyright © 2000- 2002 The Apache Software Foundation. All rights reserved. ◆ Apache HTTP Server 1.1.1 Copyright © 2000- 2002 The Apache Software Foundation. All rights reserved. ◆ Apache Xerces Java XML Parser 2.6.2 Copyright © 2000- 2002 The Apache Software Foundation. All rights reserved. ◆ Apache Jakarta Commons CLI - 1.0 Copyright © 2002-2010 The Apache Software Foundation. All rights reserved. ◆ Apache Jakarta Commons Collections - 2.1 Copyright © 2001-2008 The Apache Software Foundation. All rights reserved. ◆ Apache Jakarta Commons Discovery - 0.2 Copyright © 2002-2011 The Apache Software Foundation . ◆ Apache Jakarta Commons FileUpload - 1.0 Copyright © 2002-2010 The Apache Software Foundation . All rights reserved. ◆ Apache log4j - 1.2.8 Notices 1 215-05829_A0—Copyright © 2011 NetApp, Inc. All rights reserved. Copyright 2007 The Apache Software Foundation. -

Xerox® Igen™ 150 Press 3 Party Software License Disclosure
Xerox® iGen™ 150 Press 3rd Party Software License Disclosure October 2013 The following software packages are copyrighted for use in this product according to the license stated. Full terms and conditions of all 3rd party software licenses are available from the About screen under the Help menu on the Press Interface or by accessing the Support & Drivers page located on the http://www.xerox.com website. Adobe Icons and Web Logos, license: Adobe Icons and Web Logos License Apache log4j 1.2.8, Apache log4j 1.2.9, Apache Web Services XML-RPC 1.2.b1, Apache Lucene Java 1.3, Apache Tomcat 4.1.27, license: Apache License 1.1 Apache Axis 1.x 1.4, Apache Jakarta Commons HttpClient 3.0.alpha1, Apache Jakarta Commons Logging 1.0.4, Apache Jakarta Lucene 1.9.1, Apache XML Security Java 1.3.0, saxpath 1.0 FCS, Skin Look And Feel (skinlf) 1.2.8, Spring Framework Utilities 0.7, Apache Web Services Axis 1.2rc3, Apache Xerces Java XML Parser 2.7.1, Apache XML Xalan-Java 2.7.0, Jetty - Java HTTP Servlet Server 4.0.D0, Lucene Snowball, Streaming API for XML (StAX) - JSR-173 20040819, license: Apache License 2.0 Perl 5.8.5, Perl 5.10.0, AppConfig-1.66, Archive-Tar-1.58, Compress::Zlib-2.020, Expect.pm- 1.21, File-NCopy-0.36, File-NFSLock-1.20, Filesys-Df-0.92, Filesys-DiskFree-0.06, HTML- Parser-3.69, HTML-Tagset-3.20, HTML-Template-2.9, IO-Stty-0.02, IO-Tty-1.08, IO-Zlib- 1.09, libxml-perl-0.08, Net-Netmask-1.9015, Net-Telnet-3.03, perl-5.8.3, perlindex-1.605, Pod- Escapes-1.04, Pod-POM-0.25, Pod-Simple-3.13, Proc-ProcessTable-0.45, Socket6-0.23, Stat- -

HPE Security Fortify Runtime Application Protection Rulepack Kit
HPE Security Fortify Runtime Software Version: 17.3 Versions 2017.1.3 (Java) and 2017.1.3 (.NET) Application Protection Rulepack Kit Guide Document Release Date: April 2017 Software Release Date: April 2017 Application Protection Rulepack Kit Guide Legal Notices Warranty The only warranties for Hewlett Packard Enterprise Development products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HPE shall not be liable for technical or editorial errors or omissions contained herein. The information contained herein is subject to change without notice. Restricted Rights Legend Confidential computer software. Valid license from HPE required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license. The software is restricted to use solely for the purpose of scanning software for security vulnerabilities that is (i) owned by you; (ii) for which you have a valid license to use; or (iii) with the explicit consent of the owner of the software to be scanned, and may not be used for any other purpose. You shall not install or use the software on any third party or shared (hosted) server without explicit consent from the third party. Copyright Notice © Copyright 2010 - 2017 Hewlett Packard Enterprise Development LP Trademark Notices Adobe™ is a trademark of Adobe Systems Incorporated. Microsoft® and Windows® are U.S. registered trademarks of Microsoft Corporation. UNIX® is a registered trademark of The Open Group. -

ECX Third Party Notices
ECX ™ ECX Release 2.4 Third Party Software Information The accompanying program and the related media, documentation and materials (“Software”) are protected by copyright law and international treaties. Unauthorized reproduction or distribution of the Software, or any portion of it, may result in severe civil and criminal penalties, and will be prosecuted to the maximum extent possible under the law. Copyright (c) Catalogic Software, Inc., 2016. All rights reserved. The Software contains proprietary and confidential material, and is only for use by the lessees of the ECX proprietary software system. The Software may not be reproduced in whole or in part, in any form, except with written permission from Catalogic Software, Inc. The Software is provided under the accompanying Software License Agreement (“SLA”) ECX is a registered trademark of Catalogic Software, Inc. All other third-party brand names and product names used in this documentation are trade names, service marks, trademarks, or registered trademarks of their respective owners. The Software is a proprietary product of Catalogic Software, Inc., but incorporates certain third-party components that are subject to separate licenses and/or notice requirements. (Note, however, that while these separate licenses cover the corresponding third-party components, they do not modify or form any part of Catalogic Software’s SLA.) Links to third-party license agreements referenced in this product are listed below. Third Party Software License or Agreement Reference to License or Agreement -
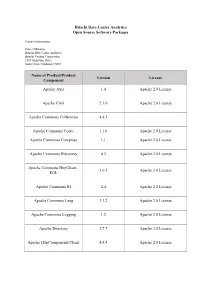
Hitachi Data Center Analytics Open Source Software Packages
Hitachi Data Center Analytics Open Source Software Packages Contact Information: Project Manager Hitachi Data Center Analytics Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component Apache Axis 1.4 Apache 2.0 License Apache Click 2.3.0 Apache 2.0 License Apache Commons Collections 4.4.1 Apache Commons Codec 1.10 Apache 2.0 License Apache Commons Compress 1.1 Apache 2.0 License Apache Commons Discovery 0.2 Apache 2.0 License Apache Commons HttpClient - 3.0.1 Apache 2.0 License EOL Apache Commons IO 2.4 Apache 2.0 License Apache Commons Lang 3.3.2 Apache 2.0 License Apache Commons Logging 1.2 Apache 2.0 License Apache Directory 2.7.7 Apache 2.0 License Apache HttpComponents Client 4.4.4 Apache 2.0 License Name of Product/Product Version License Component Apache HttpComponents 5.5.2 Apache 2.0 License Apache Log4j 1.2.17 Apache 2.0 License Apache Log4net 1.2.10 Apache 2.0 License Apache PDF Box 2.0.2 Apache 2.0 License Apache POI 3.15 Apache 2.0 License Apache Thrift 0.9.1 Apache 2.0 License Apache Web Services 1.0.2 Apache 2.0 License Apache Xerces Java Parser 2.9.0 Apache 2.0 License Apache XML Graphics 1.4 Apache 2.0 License Apache XML-RPC 3.1 Apache 2.0 License Apache XMLBeans 2.6.0 Apache 2.0 License Bouncy Castle Crypto API 1.45.0 MIT license CHILKAT CRYPT 9.5.0 Paid click-calendar 1.3.0 Apache 2.0 License Customized log4j File Appender Apache 2.0 License docx4j 2.7.0 Apache 2.0 License Name of Product/Product Version License Component dom4j 1.6.1 Apache 2.0 -

Licensing Information Release 13.2.2
Oracle® Retail Merchandise Planning and Optimization Licensing Information Release 13.2.2 E22836-01 April 2011 This document provides licensing information for all the third-party applications used by the following Oracle Retail applications: ■ Oracle Retail Clearance Optimization Engine ■ Oracle Retail Markdown Optimization ■ Oracle Retail Place ■ Oracle Retail Plan ■ Oracle Retail Promotion Intelligence and Promotion Planning and Optimization Prerequisite Softwares and Licenses Oracle Retail products depend on the installation of certain essential products (with commercial licenses), but the company does not bundle these third-party products within its own installation media. Acquisition of licenses for these products should be handled directly with the vendor. The following products are not distributed along with the Oracle Retail product installation media: ™ ■ MicroStrategy Desktop (http://www.microstrategy.com) ■ MicroStrategy Intelligence Server™ and Web Universal (http://www.microstrategy.com) ® ■ Oracle Application Server 10g (http://www.oracle.com) ® ■ Oracle Business Intelligence Suite Enterprise Edition Version 10 (http://www.oracle.com) ® ■ Oracle Database 10g (http://www.oracle.com) ® ■ Oracle Database 11g (http://www.oracle.com) ® ■ Oracle WebLogic Server (http://www.oracle.com) ■ rsync (http://samba.anu.edu.au/rsync/). See rsync License. 1 Softwares and Licenses Bundled with Oracle Retail Products The following third party products are bundled along with the Oracle Retail product code and Oracle has acquired the necessary -

(F/K/A LCCP) Open Source Disclosure
Below are the licenses for open source software used in the LCCP product and platform. You may download certain source code (as required by applicable licenses below) from verizon.com/opensource. 1. Xerces 3.1.1 2. Libtins 3. G3log v1.1 4. Winpcap v4.1.0.902 5. jersey-container-servlet-core 2.23.1 6. jersey-media-moxy 2.23.1 7. jersey-container-servlet 2.7 8. jersey-media-multipart 2.23.2 9. jersey-media-json-jackson 2.23.2 10. derby 10.12.1.1 11. Log4j 1.2.17 12. quartz 2.2.1 13. jetty-server/jetty-servlet/jetty-webapp 9.2.3.v20140905 14. commons-dbcp 1.4 15. json 20160810 16. gson 2.7 17. mimepull 1.9.3 18. poi 3.15 19. poi-ooxml 3.15 20. ibatis-sqlmap 2.3.0 21. commons-net 3.4 22. commons-lang 3 23. Angular JS/Angular Cookies/Angular Routes/Angular Sanitize 1.5.7 24. Angular ToolTips 1.1.7 25. Google Material Design 26. jQuery v3.0 27. ngDraggable 28. Simple Pagination 29. Animation 3.5.1 30. Freemarker library 2.3.25 31. jetty-runner 9 32. jersey-client 1.8 33. jersey-core 1.8 34. jackson-core-asl-1.7.1 35. jackson-mapper-asl-1.7.1 36. device-api 0.3.2 37. ddmlib 24.5.0 38. ADB 39. AdbWinAPI.dll 40. NVD 3 1.8.1 41. JSCH – 0.1.55 42. Libssh2 – 0.74 43. COMMON DEVELOPMENT AND DISTRIBUTION LICENSE (CDDL) Version 1.1 44. -

SVG Essentials
SVG Essentials J. David Eisenberg Publisher: O'Reilly First Edition February 2002 ISBN: 0-596-00223-8, 364 pages Scalable Vector Graphics—or SVG—is the new XML-based graphics standard Copyright Table of Contents from the W3C that will enable Web documents to be smaller, faster and more Index interactive. This insightful book takes you through the ins and outs of SVG, Full Description from the basics to more complicated features. Whether you're a graphic Reviews designer looking for new tools, or a programmer creating and managing Examples graphics, this book provides a solid foundation. Reader reviews Errata 1 TEAM FLY PRESENTS Table of Content Table of Content ............................................................................................................. 2 Dedication..................................................................................................................... .. 6 Preface........................................................................................................................ ..... 6 Who Should Read This Book?.................................................................................... 6 Who Should Not Read This Book?............................................................................. 6 If You're Still Reading This........................................................................................ 6 About the Examples.................................................................................................... 7 Request for Comments.............................................................................................