Exploring Practical Issues in Smartphone Motion Sensor Fingerprinting and Countermeasures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Samtal 105 Musik 73 Ta Emot Samtal 108 Video 74 Alternativ Under Samtal
SM-G850F Bruksanvisning Swedish. 10/2014. Rev.1.0 www.samsung.com Innehållsförteckning Läs detta först Nätverksanslutning 39 Mobildata 39 Wi-Fi Komma igång 41 Download booster 7 Förpackningens innehåll 41 Internetdelning och Mobile hotspot 8 Enhetslayout 43 Internet 10 Använda SIM- eller USIM-kort och batteri 15 Slå på och av enheten Rörelser och 16 Låsa och låsa upp skärmen användningsfunktioner 46 Rörelser och gester 50 Luftvy Grunder 50 Flera fönster 17 Använda pekskärmen 55 Verktygslåda 20 Hemskärmslayout 56 Öka pekskärmens känslighet 25 Paneler för aviseringar och snabbinställningar 28 Öppna program Personanpassning 29 Installera eller avinstallera program 31 Ange text 57 Hantera hem- och programskärmarna 33 Skärmbild 60 Ställa in bakgrunder och ringsignaler 34 Mina filer 61 Ändra skärmlåsningsmetod 36 Energisparfunktion 62 Fingerläsare 38 Visa hjälpinformation 66 Sekretessläge 67 Enkelt läge 68 Överföra data från din föregående enhet 69 Ställa in konton 2 Innehållsförteckning Telefon Multimedia 70 Ringa samtal 105 Musik 73 Ta emot samtal 108 Video 74 Alternativ under samtal S Health Kontakter 110 Om S Health 76 Lägga till kontakter 111 Konfigurera en användarprofil 77 Hantera kontakter 112 Huvudskärmen för S Health 114 Promenadkompis 116 Träningskompis Meddelanden och e-post 123 Registrera matintag 80 Meddelanden 125 Hantera vikt 83 E-post 127 Installera ytterligare S Health-program 128 Inställningar för S Health Kamera 86 Grundläggande fotografering Säkerhetsfunktioner 90 Fotograferingslägen 130 Nödläge 94 Kamerainställningar 131 -

Compatibility Sheet
COMPATIBILITY SHEET SanDisk Ultra Dual USB Drive Transfer Files Easily from Your Smartphone or Tablet Using the SanDisk Ultra Dual USB Drive, you can easily move files from your Android™ smartphone or tablet1 to your computer, freeing up space for music, photos, or HD videos2 Please check for your phone/tablet or mobile device compatiblity below. If your device is not listed, please check with your device manufacturer for OTG compatibility. Acer Acer A3-A10 Acer EE6 Acer W510 tab Alcatel Alcatel_7049D Flash 2 Pop4S(5095K) Archos Diamond S ASUS ASUS FonePad Note 6 ASUS FonePad 7 LTE ASUS Infinity 2 ASUS MeMo Pad (ME172V) * ASUS MeMo Pad 8 ASUS MeMo Pad 10 ASUS ZenFone 2 ASUS ZenFone 3 Laser ASUS ZenFone 5 (LTE/A500KL) ASUS ZenFone 6 BlackBerry Passport Prevro Z30 Blu Vivo 5R Celkon Celkon Q455 Celkon Q500 Celkon Millenia Epic Q550 CoolPad (酷派) CoolPad 8730 * CoolPad 9190L * CoolPad Note 5 CoolPad X7 大神 * Datawind Ubislate 7Ci Dell Venue 8 Venue 10 Pro Gionee (金立) Gionee E7 * Gionee Elife S5.5 Gionee Elife S7 Gionee Elife E8 Gionee Marathon M3 Gionee S5.5 * Gionee P7 Max HTC HTC Butterfly HTC Butterfly 3 HTC Butterfly S HTC Droid DNA (6435LVW) HTC Droid (htc 6435luw) HTC Desire 10 Pro HTC Desire 500 Dual HTC Desire 601 HTC Desire 620h HTC Desire 700 Dual HTC Desire 816 HTC Desire 816W HTC Desire 828 Dual HTC Desire X * HTC J Butterfly (HTL23) HTC J Butterfly (HTV31) HTC Nexus 9 Tab HTC One (6500LVW) HTC One A9 HTC One E8 HTC One M8 HTC One M9 HTC One M9 Plus HTC One M9 (0PJA1) -

Samsung Galaxy S5 Carries Astronomical Bill of Materials, IHS Teardown Reveals Andrew Rassweiler | April 15, 2014
Samsung Galaxy S5 Carries Astronomical Bill of Materials, IHS Teardown Reveals Andrew Rassweiler | April 15, 2014 The latest member of Samsung’s wildly popular line of Galaxy smartphones ups the ante on features—and on cost—with the S5’s discrete-intensive design yielding a high bill of materials (BOM). The Samsung Galaxy S5 with 32 Gigabytes of NAND flash memory carries a BOM of $251.52, according to a preliminary estimate by the Teardown Mobile Handsets Intelligence Service at IHS Technology (NYSE: IHS).The cost rises to $256.52 when the $5.00 manufacturing cost is added. This is more expensive than other high-end smartphones, such as the 32GByte iPhone 5S, which carried a $207.00 BOM based on an IHS pricing estimate in September. The S5’s BOM contrasts even more starkly with smartphones at the lowest end of the cost spectrum, such as two Android devices, the ZTE U793 and K-Touch T619+, which have BOMs of less than $35, according to recent IHS teardowns. “The high cost of the S5 is becoming more typical of Samsung’s flagship Galaxy line,” said Andrew Rassweiler, senior director, cost benchmarking services for IHS. “In the last year, IHS has torn down four Galaxy devices with BOMs ranging from $237.00 to $280.00. “The S5 exemplifies a conservative evolutionary design approach,” Rassweiler said“There are no revolutions or giant steps forward in this design. There’s a lot of similarity and commonality between the S5 and other recent Samsung smartphones IHS has torn down, such as the Galaxy Round and the Note III. -

Electronic 3D Models Catalogue (On July 26, 2019)
Electronic 3D models Catalogue (on July 26, 2019) Acer 001 Acer Iconia Tab A510 002 Acer Liquid Z5 003 Acer Liquid S2 Red 004 Acer Liquid S2 Black 005 Acer Iconia Tab A3 White 006 Acer Iconia Tab A1-810 White 007 Acer Iconia W4 008 Acer Liquid E3 Black 009 Acer Liquid E3 Silver 010 Acer Iconia B1-720 Iron Gray 011 Acer Iconia B1-720 Red 012 Acer Iconia B1-720 White 013 Acer Liquid Z3 Rock Black 014 Acer Liquid Z3 Classic White 015 Acer Iconia One 7 B1-730 Black 016 Acer Iconia One 7 B1-730 Red 017 Acer Iconia One 7 B1-730 Yellow 018 Acer Iconia One 7 B1-730 Green 019 Acer Iconia One 7 B1-730 Pink 020 Acer Iconia One 7 B1-730 Orange 021 Acer Iconia One 7 B1-730 Purple 022 Acer Iconia One 7 B1-730 White 023 Acer Iconia One 7 B1-730 Blue 024 Acer Iconia One 7 B1-730 Cyan 025 Acer Aspire Switch 10 026 Acer Iconia Tab A1-810 Red 027 Acer Iconia Tab A1-810 Black 028 Acer Iconia A1-830 White 029 Acer Liquid Z4 White 030 Acer Liquid Z4 Black 031 Acer Liquid Z200 Essential White 032 Acer Liquid Z200 Titanium Black 033 Acer Liquid Z200 Fragrant Pink 034 Acer Liquid Z200 Sky Blue 035 Acer Liquid Z200 Sunshine Yellow 036 Acer Liquid Jade Black 037 Acer Liquid Jade Green 038 Acer Liquid Jade White 039 Acer Liquid Z500 Sandy Silver 040 Acer Liquid Z500 Aquamarine Green 041 Acer Liquid Z500 Titanium Black 042 Acer Iconia Tab 7 (A1-713) 043 Acer Iconia Tab 7 (A1-713HD) 044 Acer Liquid E700 Burgundy Red 045 Acer Liquid E700 Titan Black 046 Acer Iconia Tab 8 047 Acer Liquid X1 Graphite Black 048 Acer Liquid X1 Wine Red 049 Acer Iconia Tab 8 W 050 Acer -

Phone Compatibility
Phone Compatibility • Compatible with iPhone models 4S and above using iOS versions 7 or higher. Last Updated: February 14, 2017 • Compatible with phone models using Android versions 4.1 (Jelly Bean) or higher, and that have the following four sensors: Accelerometer, Gyroscope, Magnetometer, GPS/Location Services. • Phone compatibility information is provided by phone manufacturers and third-party sources. While every attempt is made to ensure the accuracy of this information, this list should only be used as a guide. As phones are consistently introduced to market, this list may not be all inclusive and will be updated as new information is received. Please check your phone for the required sensors and operating system. Brand Phone Compatible Non-Compatible Acer Acer Iconia Talk S • Acer Acer Jade Primo • Acer Acer Liquid E3 • Acer Acer Liquid E600 • Acer Acer Liquid E700 • Acer Acer Liquid Jade • Acer Acer Liquid Jade 2 • Acer Acer Liquid Jade Primo • Acer Acer Liquid Jade S • Acer Acer Liquid Jade Z • Acer Acer Liquid M220 • Acer Acer Liquid S1 • Acer Acer Liquid S2 • Acer Acer Liquid X1 • Acer Acer Liquid X2 • Acer Acer Liquid Z200 • Acer Acer Liquid Z220 • Acer Acer Liquid Z3 • Acer Acer Liquid Z4 • Acer Acer Liquid Z410 • Acer Acer Liquid Z5 • Acer Acer Liquid Z500 • Acer Acer Liquid Z520 • Acer Acer Liquid Z6 • Acer Acer Liquid Z6 Plus • Acer Acer Liquid Zest • Acer Acer Liquid Zest Plus • Acer Acer Predator 8 • Alcatel Alcatel Fierce • Alcatel Alcatel Fierce 4 • Alcatel Alcatel Flash Plus 2 • Alcatel Alcatel Go Play • Alcatel Alcatel Idol 4 • Alcatel Alcatel Idol 4s • Alcatel Alcatel One Touch Fire C • Alcatel Alcatel One Touch Fire E • Alcatel Alcatel One Touch Fire S • 1 Phone Compatibility • Compatible with iPhone models 4S and above using iOS versions 7 or higher. -

Case 6:19-Cv-00474-ADA Document 46 Filed 05/05/20 Page 1 of 208
Case 6:19-cv-00474-ADA Document 46 Filed 05/05/20 Page 1 of 208 IN THE UNITED STATES DISTRICT COURT FOR THE WESTERN DISTRICT OF TEXAS WACO DIVISION GPU++, LLC, ) ) Plaintiff, ) ) v. ) ) Civil Action No. W-19-CV-00474-ADA QUALCOMM INCORPORATED; ) QUALCOMM TECHNOLOGIES, INC., ) JURY TRIAL DEMANDED SAMSUNG ELECTRONICS CO., LTD.; ) SAMSUNG ELECTRONICS AMERICA, INC.; ) U.S. Dist. Ct. Judge: Hon. Alan. D. Albright SAMSUNG SEMICONDUCTOR, INC.; ) SAMSUNG AUSTIN SEMICONDUCTOR, ) LLC, ) ) Defendants. ) FIRST AMENDED COMPLAINT Plaintiff GPU++, LLC (“Plaintiff”), by its attorneys, demands a trial by jury on all issues so triable and for its complaint against Qualcomm Incorporated and Qualcomm Technologies, Inc. (collectively, “Qualcomm”) and Samsung Electronics Co., Ltd., Samsung Electronics America, Inc., Samsung Semiconductor, Inc., and Samsung Austin Semiconductor, LLC (collectively, “Samsung”) (Qualcomm and Samsung collectively, “Defendants”), and alleges as follows: NATURE OF THE ACTION 1. This is a civil action for patent infringement under the patent laws of the United States, Title 35, United States Code, Section 271, et seq., involving United States Patent No. 8,988,441 (Exhibit A, “’441 patent”) and seeking damages and injunctive relief as provided in 35 U.S.C. §§ 281 and 283-285. THE PARTIES 2. Plaintiff is a California limited liability company with a principal place of business Case 6:19-cv-00474-ADA Document 46 Filed 05/05/20 Page 2 of 208 at 650-B Fremont Avenue #137, Los Altos, CA 94024. Plaintiff is the owner by assignment of the ʼ441 patent. 3. On information and belief, Qualcomm Incorporated is a corporation organized and existing under the laws of the State of Delaware, having a principal place of business at 5775 Morehouse Dr., San Diego, California, 92121. -

Baromètre Des Connexions Internet Mobiles En Polynésie Française. Publication Du 12 Mars 2020
Baromètre des Connexions Internet Mobiles en Polynésie Française. Publication du 12 Mars 2020 Rapport 2019 nPerf est un service proposé par la société nPerf, située 87 rue de Sèze 69006 LYON – France. Table des matières 1 Synthèse des résultats annuels globaux ..................................................................................... 2 1.1 Scores nPerf, toutes technologies confondues ................................................................... 2 1.2 Notre analyse ........................................................................................................................ 3 2 Les résultats annuels globaux ..................................................................................................... 3 2.1 Taux de réussite .................................................................................................................... 4 2.2 Débits descendants .............................................................................................................. 4 2.3 Débits montants .................................................................................................................... 5 2.4 Temps de réponse (Latence) ................................................................................................ 6 2.5 Qualité de service .................................................................................................................. 6 2.5.1 Navigation ..................................................................................................................... -

Brand Old Device
# New Device Old Device - Brand Old Device - Model Name 1 Galaxy A6+ Asus Asus Zenfone 2 Laser ZE500KL 2 Galaxy A6+ Asus Asus Zenfone 2 Laser ZE601KL 3 Galaxy A6+ Asus Asus ZenFone 2 ZE550ML 4 Galaxy A6+ Asus Asus Zenfone 2 ZE551ML 5 Galaxy A6+ Asus Asus Zenfone 3 Laser 6 Galaxy A6+ Asus Asus Zenfone 3 Max ZC520TL 7 Galaxy A6+ Asus Asus Zenfone 3 Max ZC553KL 8 Galaxy A6+ Asus Asus Zenfone 3 ZE520KL 9 Galaxy A6+ Asus Asus Zenfone 3 ZE552KL 10 Galaxy A6+ Asus Asus Zenfone 3s Max 11 Galaxy A6+ Asus Asus Zenfone Max 12 Galaxy A6+ Asus Asus Zenfone Selfie 13 Galaxy A6+ Asus Asus ZenFone Zoom ZX550 14 Galaxy A6+ Gionee Gionee A1 15 Galaxy A6+ Gionee Gionee A1 Lite 16 Galaxy A6+ Gionee Gionee A1 Plus 17 Galaxy A6+ Gionee Gionee Elife E8 18 Galaxy A6+ Gionee Gionee Elife S Plus 19 Galaxy A6+ Gionee Gionee Elife S7 20 Galaxy A6+ Gionee Gionee F103 21 Galaxy A6+ Gionee Gionee F103 Pro 22 Galaxy A6+ Gionee Gionee Marathon M4 23 Galaxy A6+ Gionee Gionee Marathon M5 24 Galaxy A6+ Gionee Gionee marathon M5 Lite 25 Galaxy A6+ Gionee Gionee Marathon M5 Plus 26 Galaxy A6+ Gionee Gionee P5L 27 Galaxy A6+ Gionee Gionee P7 Max 28 Galaxy A6+ Gionee Gionee S6 29 Galaxy A6+ Gionee Gionee S6 Pro 30 Galaxy A6+ Gionee Gionee S6s 31 Galaxy A6+ Gionee Gionee X1s 32 Galaxy A6+ Google Google Pixel 33 Galaxy A6+ Google Google Pixel XL LTE 34 Galaxy A6+ Google Nexus 5X 35 Galaxy A6+ Google Nexus 6 36 Galaxy A6+ Google Nexus 6P 37 Galaxy A6+ HTC Htc 10 38 Galaxy A6+ HTC Htc Desire 10 Pro 39 Galaxy A6+ HTC Htc Desire 628 40 Galaxy A6+ HTC HTC Desire 630 41 Galaxy A6+ -

Boso Mobile App.Pdf
App Download App Quick guide Main menu Menu Scan QR code with a smartphone camera to directly access the respective shop Data transfer Upper menu bar boso medicus system Premium upper arm blood pressure monitor with app Linking with Apple Health (iOS) and SciTIM The link is activated in the user data. Bottom menu bar The demo user included in the boso app cannot be modi- fied, it cannot be linked with Apple Health or SciTIM to avoid sending demo data. • Requires interaction with the boso app The measured data is automatically transferred to Apple Health and/or SciTIM after a measurement. If you experi- ence problems with Apple Health, make sure that all he- alth data in the Apple Health app has been activated for • Requires interaction with the reception. boso medicus system Certifi ed for Information on tele-monitoring with SciTIM | boso.de/SciTIM The boso app is compatible with the following devices running iOS 11 / Android 5 and above: iPhone 6 | iPhone 7 | iPhone 8 | iPhone XR | iPhone XS | iPad Air | iPad Pro Samsung Galaxy S5 | Samsung Galaxy S5 mini | Samsung Galaxy S5 Neo Samsung Galaxy S6 | Samsung Galaxy S7 | Samsung Galaxy S8 | Samsung Galaxy S9 Samsung Galaxy S10 | Samsung Galaxy A3 | Samsung Galaxy A5 BOSCH + SOHN GmbH u. Co. KG Samsung Galaxy Grand Prime | Samsung Galaxy Alpha Samsung Galaxy Tab A | Samsung Galaxy Tab S Bahnhofstraße 64 Moto Z Play | Motorola Moto e Gen 2 | Sony XPERIA Z3 | Google Nexus 5X D-72417 Jungingen Huawei P9 Lite | Huawei p20 Pro | LG G4 | LG G5 | T + 49 (0) 74 77 92 75 - 0 The current list is online and can be accessed by QR code: F + 49 (0) 74 77 10 21 boso.de/produkte/blutdruckmessgeraete-fuer-die-selbstmessung/ E zentrale @ boso.de oberarmgeraete.html boso.de 07/2019 blood pressure monitoring is boso. -
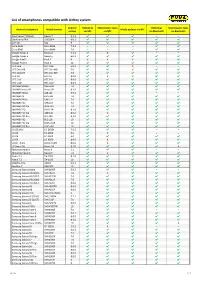
List of Smartphones Compatible with Airkey System
List of smartphones compatible with AirKey system Android Unlocking Maintenance tasks Unlocking Maintenance tasks Android smartphone Model number Media updates via NFC version via NFC via NFC via Bluetooth via Bluetooth Asus Nexus 7 (Tablet) Nexus 7 5.1.1 ✔ ✔ ✔ – – Blackberry PRIV STV100-4 6.0.1 ✔ ✔ ✔ ✔ ✔ CAT S61 S61 9 ✔ ✔ ✔ ✔ ✔ Doro 8035 Doro 8035 7.1.2 – – – ✔ ✔ Doro 8040 Doro 8040 7.0 – – – ✔ ✔ Google Nexus 4 Nexus 4 5.1.1 ✔ X ✔ – – Google Nexus 5 Nexus 5 6.0.1 ✔ ✔ ✔ ✔ ✔ Google Pixel 2 Pixel 2 9 X X X ✔ ✔ Google Pixel 4 Pixel 4 10 ✔ ✔ ✔ ✔ ✔ HTC One HTC One 5.0.2 ✔ ✔ X – – HTC One M8 HTC One M8 6.0 ✔ ✔ X ✔ ✔ HTC One M9 HTC One M9 7.0 ✔ ✔ ✔ ✔ ✔ HTC 10 HTC 10 8.0.0 ✔ X X ✔ ✔ HTC U11 HTC U11 8.0.0 ✔ ✔ ✔ ✔ ✔ HTC U12+ HTC U12+ 8.0.0 ✔ ✔ ✔ ✔ ✔ HUAWEI Mate 9 MHA-L09 7.0 ✔ ✔ ✔ ✔ ✔ HUAWEI Nexus 6P Nexus 6P 8.1.0 ✔ ✔ ✔ ✔ ✔ HUAWEI P8 lite ALE-L21 5.0.1 ✔ ✔ ✔ – – HUAWEI P9 EVA-L09 7.0 ✔ ✔ ✔ ✔ ✔ HUAWEI P9 lite VNS-L21 7.0 ✔ ✔ ✔ ✔ ✔ HUAWEI P10 VTR-L09 7.0 ✔ ✔ ✔ ✔ ✔ HUAWEI P10 lite WAS-LX1 7.0 ✔ ✔ ✔ ✔ ✔ HUAWEI P20 EML-L29 8.1.0 ✔ ✔ ✔ ✔ ✔ HUAWEI P20 lite ANE-LX1 8.0.0 ✔ X ✔ ✔ ✔ HUAWEI P20 Pro CLT-L29 8.1.0 ✔ ✔ ✔ ✔ ✔ HUAWEI P30 ELE-L29 10 ✔ ✔ ✔ ✔ ✔ HUAWEI P30 lite MAR-LX1A 10 ✔ ✔ ✔ ✔ ✔ HUAWEI P30 Pro VOG-L29 10 ✔ ✔ ✔ ✔ ✔ LG G2 Mini LG-D620r 5.0.2 ✔ ✔ ✔ – – LG G3 LG-D855 5.0 ✔ X ✔ – – LG G4 LG-H815 6.0 ✔ ✔ ✔ ✔ ✔ LG G6 LG-H870 8.0.0 ✔ X ✔ ✔ ✔ LG G7 ThinQ LM-G710EM 8.0.0 ✔ X ✔ ✔ ✔ LG Nexus 5X Nexus 5X 8.1.0 ✔ ✔ ✔ ✔ X Motorola Moto X Moto X 5.1 ✔ ✔ ✔ – – Motorola Nexus 6 Nexus 6 7.0 ✔ X ✔ ✔ ✔ Nokia 7.1 TA-1095 8.1.0 ✔ ✔ X ✔ ✔ Nokia 7.2 TA-1196 10 ✔ ✔ ✔ -
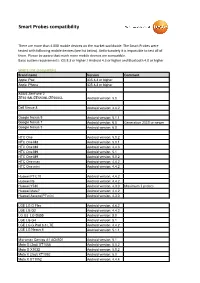
Smart Probes Compatibility
Smart Probes compatibility There are more than 4.000 mobile devices on the market worldwide. The Smart Probes were tested with following mobile devices (see list below). Unfortunately it is impossible to test all of them. Please be aware that much more mobile devices are compatible. Basic system requirements: iOS 8.3 or higher / Android 4.3 or higher and Bluetooth 4.0 or higher. WHITE LIST (compatible) Brand name Version Comment Apple iPad iOS 8.3 or higher Apple iPhone iOS 8.3 or higher ASUS ZenFone 2 ZE551ML/ZE550ML/ZE500CL Android version: 5.0 Dell Venue 8 Android version: 4.4.2 Google Nexus 9 Andorid version: 5.1.1 Google Nexus 7 Android version: 6.0 Generation 2013 or newer Google Nexus 5 Android version: 6.0 HTC One Android version: 5.0.2 HTC One M8 Android version: 5.0.1 HTC One M8 Android version: 4.4.3 HTC One M9 Android version: 5.1 HTC One M9 Android version: 5.0.2 HTC One max Android version: 4.4.2 HTC One mini Android version: 4.4.2 Huawei P7-L10 Android version: 4.4.2 Huawei P6 Android version: 4.4.2 Huawei Y530 Android version: 4.3.0 Maximum 3 probes Huawei Mate7 Android version: 4.4.2 Huawei Ascend P7 mini Android version: 4.3.0 LGE LG G Flex Android version: 4.4.2 LGE LG G2 Android version: 4.4.2 LG G3 LG-D855 Android version: 5.0 LGE LG G4 Android version: 5.1 LGE LG G Pad 8.3 LTE Android version: 4.4.2 LGE LG Nexus 4 Andriod version: 5.1.1 Micromax Canvas A1 AQ4501 Android version: 5.1 Moto G (2nd) XT1068 Android version: 5.0.2 Moto G X1032 Android version: 5.0.2 Moto X (2nd) XT1092 Android version: 5.0 Moto X XT1052 Android version: 4.4.4 Motorola Droid RAZR M Android version: 4.4.2 Motorola Moto E XT1021 Android version: 4.4.4 Maximum 3 probes Motorola Moto E (2nd gen) XT1021 Android version: 5.0.2 Motorola Nexus 6 Android version: 5.1.0 Motorola Nexus 6 Android version: 5.1.1 Motorola RAZR HD XT925 Android version: 4.4.2 Motorola X8 Android version: 4.4.2 OnePlusOne A0001 Android version: 5.0. -

Mobile Device & OS Compatibility
Mobile Device & OS Compatibility Click here for English Cliquez ici pour Français Haga clic aquí para seleccionar Español Klicka här för Svenska Klicken Sie hier für Deutsch Fare clic qui per Italiano Hier klikken voor Nederlands Valitse tästä kieleksi suomi Κάντε κλικ εδώ για Ελληνικά Kliknij tutaj, aby włączyć język polski Haga clic aquí para la versión en español Cliquez ici pour le français Clique aqui para Português Klik her for dansk Klikk her for norsk اﻧﻘﺮ ھﻨﺎ ﻟﻠﻐﺔ اﻟﻌﺮﺑﯿﺔ Clique aqui para Português 點選此處瀏覽中文版 לחץ כאן עבור עברית 한국어를 선택하려면 여기를 클릭하십시오 Нажмите здесь, чтобы перейти на русский Türkçe için buraya tıklayın 中 文( 简 体 )请 点 击 这 里 FreeStyle, Libre, and related brand marks are trademarks of Abbott Diabetes Care Inc. in various jurisdictions. Other trademarks are the property of their respective owners. ©2019 Abbott ART39109-001 Rev. H 02/20 MOBILE DEVICE & OS COMPATIBILITY Popular mobile devices and operating systems (OS) are regularly tested to evaluate NFC scan performance, Bluetooth connectivity, and app compatibility with Sensors. We recommend checking this guide before installing a new OS version on your phone or before using the app with a new phone. Recommended app, device, and operating systems APP / VERSION DEVICE OS iPhone 7, 7 Plus, 8, 8 Plus, X, XS, XS Max, XR FreeStyle LibreLink Samsung Galaxy S6, Galaxy S7 Edge, Galaxy S8, Galaxy S8+, Galaxy S9 iOS: 12, 13 (version 2.4) Google Pixel, Pixel 2, Pixel 2 XL Android: 8, 9, 10 LG Nexus 5X iPhone 7, 7 Plus, 8, 8 Plus, X, XS, XS Max, XR Samsung Galaxy S5, Galaxy S6, Galaxy S7, Galaxy S7 Edge, Galaxy S8, FreeStyle LibreLink Galaxy S8+, Galaxy S9 iOS: 11, 12, 13 Android: 5, 6, 7, 8, 9, 10 (version 2.3) Google Pixel, Pixel 2, Pixel 2 XL LG Nexus 5X iPhone 7, 7 Plus, 8, 8 Plus, X Samsung Galaxy S5, Galaxy S6, Galaxy S7, Galaxy S7 Edge, Galaxy S8, Galaxy S8+, Galaxy S9 FreeStyle LibreLink iOS: 11, 12, 13 (version 2.2) Google Pixel, Pixel 2, Pixel 2 XL Android: 5, 6, 7, 8, 9, 10 Nexus 5X, 6P OnePlus 5T This table will be updated as other devices and operating systems are evaluated.