Computational Geometry and Topology for Data Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Algorithm for the Construction of Intrinsic Delaunay Triangulations with Applications to Digital Geometry Processing
An Algorithm for the Construction of Intrinsic Delaunay Triangulations with Applications to Digital Geometry Processing Matthew Fisher Boris Springborn Peter Schroder¨ Alexander I. Bobenko Caltech TU Berlin Caltech TU Berlin Abstract The discrete Laplace-Beltrami operator plays a prominent role in many Digital Geometry Processing applications ranging from de- noising to parameterization, editing, and physical simulation. The standard discretization uses the cotangents of the angles in the im- mersed mesh which leads to a variety of numerical problems. We advocate the use of the intrinsic Laplace-Beltrami operator. It sat- isfies a local maximum principle, guaranteeing, e.g., that no flipped triangles can occur in parameterizations. It also leads to better con- ditioned linear systems. The intrinsic Laplace-Beltrami operator is based on an intrinsic Delaunay triangulation of the surface. We detail an incremental algorithm to construct such triangulations to- gether with an overlay structure which captures the relationship be- tween the extrinsic and intrinsic triangulations. Using a variety of example meshes we demonstrate the numerical benefits of the in- trinsic Laplace-Beltrami operator. Figure 1: Left: carrier of the (cat head) surface as defined by the original embedded mesh. Right: the intrinsic Delaunay triangu- 1 Introduction lation of the same carrier. Delaunay edges which appear in the original triangulation are shown in white. Some of the original 2 Delaunay triangulations of domains in R play an important role edges are not present anymore (these are shown in black). In their in many numerical computing applications because of the quality stead we see red edges which appear as the result of intrinsic flip- guarantees they make, such as: among all triangulations of the con- ping. -

Object Oriented Programming
No. 52 March-A pril'1990 $3.95 T H E M TEe H CAL J 0 URN A L COPIA Object Oriented Programming First it was BASIC, then it was structures, now it's objects. C++ afi<;ionados feel, of course, that objects are so powerful, so encompassing that anything could be so defined. I hope they're not placing bets, because if they are, money's no object. C++ 2.0 page 8 An objective view of the newest C++. Training A Neural Network Now that you have a neural network what do you do with it? Part two of a fascinating series. Debugging C page 21 Pointers Using MEM Keep C fro111 (C)rashing your system. An AT Keyboard Interface Use an AT keyboard with your latest project. And More ... Understanding Logic Families EPROM Programming Speeding Up Your AT Keyboard ((CHAOS MADE TO ORDER~ Explore the Magnificent and Infinite World of Fractals with FRAC LS™ AN ELECTRONIC KALEIDOSCOPE OF NATURES GEOMETRYTM With FracTools, you can modify and play with any of the included images, or easily create new ones by marking a region in an existing image or entering the coordinates directly. Filter out areas of the display, change colors in any area, and animate the fractal to create gorgeous and mesmerizing images. Special effects include Strobe, Kaleidoscope, Stained Glass, Horizontal, Vertical and Diagonal Panning, and Mouse Movies. The most spectacular application is the creation of self-running Slide Shows. Include any PCX file from any of the popular "paint" programs. FracTools also includes a Slide Show Programming Language, to bring a higher degree of control to your shows. -

A Computational Basis for Conic Arcs and Boolean Operations on Conic Polygons
A Computational Basis for Conic Arcs and Boolean Operations on Conic Polygons Eric Berberich, Arno Eigenwillig, Michael Hemmer Susan Hert, Kurt Mehlhorn, and Elmar Schomer¨ [eric|arno|hemmer|hert|mehlhorn|schoemer]@mpi-sb.mpg.de Max-Planck-Institut fur¨ Informatik, Stuhlsatzenhausweg 85 66123 Saarbruck¨ en, Germany Abstract. We give an exact geometry kernel for conic arcs, algorithms for ex- act computation with low-degree algebraic numbers, and an algorithm for com- puting the arrangement of conic arcs that immediately leads to a realization of regularized boolean operations on conic polygons. A conic polygon, or polygon for short, is anything that can be obtained from linear or conic halfspaces (= the set of points where a linear or quadratic function is non-negative) by regularized boolean operations. The algorithm and its implementation are complete (they can handle all cases), exact (they give the mathematically correct result), and efficient (they can handle inputs with several hundred primitives). 1 Introduction We give an exact geometry kernel for conic arcs, algorithms for exact computation with low-degree algebraic numbers, and a sweep-line algorithm for computing arrangements of curved arcs that immediately leads to a realization of regularized boolean operations on conic polygons. A conic polygon, or polygon for short, is anything that can be ob- tained from linear or conic halfspaces (= the set of points where a linear or quadratic function is non-negative) by regularized boolean operations (Figure 1). A regularized boolean operation is a standard boolean operation (union, intersection, complement) followed by regularization. Regularization replaces a set by the closure of its interior and eliminates dangling low-dimensional features. -

Unknot Recognition Through Quantifier Elimination
UNKNOT RECOGNITION THROUGH QUANTIFIER ELIMINATION SYED M. MEESUM AND T. V. H. PRATHAMESH Abstract. Unknot recognition is one of the fundamental questions in low dimensional topology. In this work, we show that this problem can be encoded as a validity problem in the existential fragment of the first-order theory of real closed fields. This encoding is derived using a well-known result on SU(2) representations of knot groups by Kronheimer-Mrowka. We further show that applying existential quantifier elimination to the encoding enables an UnKnot Recogntion algorithm with a complexity of the order 2O(n), where n is the number of crossings in the given knot diagram. Our algorithm is simple to describe and has the same runtime as the currently best known unknot recognition algorithms. 1. Introduction In mathematics, a knot refers to an entangled loop. The fundamental problem in the study of knots is the question of knot recognition: can two given knots be transformed to each other without involving any cutting and pasting? This problem was shown to be decidable by Haken in 1962 [6] using the theory of normal surfaces. We study the special case in which we ask if it is possible to untangle a given knot to an unknot. The UnKnot Recogntion recognition algorithm takes a knot presentation as an input and answers Yes if and only if the given knot can be untangled to an unknot. The best known complexity of UnKnot Recogntion recognition is 2O(n), where n is the number of crossings in a knot diagram [2, 6]. More recent developments show that the UnKnot Recogntion recogni- tion is in NP \ co-NP. -

Computational Topology and the Unique Games Conjecture
Computational Topology and the Unique Games Conjecture Joshua A. Grochow1 Department of Computer Science & Department of Mathematics University of Colorado, Boulder, CO, USA [email protected] https://orcid.org/0000-0002-6466-0476 Jamie Tucker-Foltz2 Amherst College, Amherst, MA, USA [email protected] Abstract Covering spaces of graphs have long been useful for studying expanders (as “graph lifts”) and unique games (as the “label-extended graph”). In this paper we advocate for the thesis that there is a much deeper relationship between computational topology and the Unique Games Conjecture. Our starting point is Linial’s 2005 observation that the only known problems whose inapproximability is equivalent to the Unique Games Conjecture – Unique Games and Max-2Lin – are instances of Maximum Section of a Covering Space on graphs. We then observe that the reduction between these two problems (Khot–Kindler–Mossel–O’Donnell, FOCS ’04; SICOMP ’07) gives a well-defined map of covering spaces. We further prove that inapproximability for Maximum Section of a Covering Space on (cell decompositions of) closed 2-manifolds is also equivalent to the Unique Games Conjecture. This gives the first new “Unique Games-complete” problem in over a decade. Our results partially settle an open question of Chen and Freedman (SODA, 2010; Disc. Comput. Geom., 2011) from computational topology, by showing that their question is almost equivalent to the Unique Games Conjecture. (The main difference is that they ask for inapproxim- ability over Z2, and we show Unique Games-completeness over Zk for large k.) This equivalence comes from the fact that when the structure group G of the covering space is Abelian – or more generally for principal G-bundles – Maximum Section of a G-Covering Space is the same as the well-studied problem of 1-Homology Localization. -

Algebraic Topology
Algebraic Topology Vanessa Robins Department of Applied Mathematics Research School of Physics and Engineering The Australian National University Canberra ACT 0200, Australia. email: [email protected] September 11, 2013 Abstract This manuscript will be published as Chapter 5 in Wiley's textbook Mathe- matical Tools for Physicists, 2nd edition, edited by Michael Grinfeld from the University of Strathclyde. The chapter provides an introduction to the basic concepts of Algebraic Topology with an emphasis on motivation from applications in the physical sciences. It finishes with a brief review of computational work in algebraic topology, including persistent homology. arXiv:1304.7846v2 [math-ph] 10 Sep 2013 1 Contents 1 Introduction 3 2 Homotopy Theory 4 2.1 Homotopy of paths . 4 2.2 The fundamental group . 5 2.3 Homotopy of spaces . 7 2.4 Examples . 7 2.5 Covering spaces . 9 2.6 Extensions and applications . 9 3 Homology 11 3.1 Simplicial complexes . 12 3.2 Simplicial homology groups . 12 3.3 Basic properties of homology groups . 14 3.4 Homological algebra . 16 3.5 Other homology theories . 18 4 Cohomology 18 4.1 De Rham cohomology . 20 5 Morse theory 21 5.1 Basic results . 21 5.2 Extensions and applications . 23 5.3 Forman's discrete Morse theory . 24 6 Computational topology 25 6.1 The fundamental group of a simplicial complex . 26 6.2 Smith normal form for homology . 27 6.3 Persistent homology . 28 6.4 Cell complexes from data . 29 2 1 Introduction Topology is the study of those aspects of shape and structure that do not de- pend on precise knowledge of an object's geometry. -

Geometry-Aware Topological Decompositions of Meshes
UC Irvine UC Irvine Electronic Theses and Dissertations Title Geometry-aware topological decompositions of meshes Permalink https://escholarship.org/uc/item/3vh0q7wn Author Chen, Jia Publication Date 2019 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, IRVINE Geometry-aware topological decompositions of meshes DISSERTATION submitted in partial satisfaction of the requirements for the degree of DOCTOR OF PHILOSOPHY in Computer Science by Jia Chen Dissertation Committee: Professor Gopi Meenakshisundaram, Chair Professor Aditi Majumder Professor Shuang Zhao 2019 Chapter3 c 2016 ACM New York, NY, USA Chapter3 c 2018 ACM New York, NY, USA All other materials c 2019 Jia Chen DEDICATION To my family \. a man who keeps company with glaciers comes to feel tolerably insignificant by and by." { Mark Twain, A Tramp Abroad ii TABLE OF CONTENTS Page LIST OF FIGURESv LIST OF TABLESx LIST OF ALGORITHMS xi ACKNOWLEDGMENTS xii CURRICULUM VITAE xiii ABSTRACT OF THE DISSERTATION xiv 1 Introduction1 1.1 Cycles of topological properties.........................2 1.2 Topological decompositions of meshes......................4 2 Definitions and Background7 2.1 Surfaces and their topological classification...................7 2.2 Primal graph and dual graph embedded on a surface.............8 2.3 Paths and cycles.................................9 2.4 Tunnel and handle cycles............................. 11 3 Iterative localization of handle and tunnel cycles 13 3.1 Related work................................... 14 3.2 Problem formulation............................... 15 3.3 Localizing handle and tunnel cycles....................... 16 3.3.1 Iterative tree-cotree algorithm...................... 16 3.3.2 Cycle tightening.............................. 20 3.3.3 Decoupling composite fundamental cycles............... -

On Combinatorial Approximation Algorithms in Geometry Bruno Jartoux
On combinatorial approximation algorithms in geometry Bruno Jartoux To cite this version: Bruno Jartoux. On combinatorial approximation algorithms in geometry. Distributed, Parallel, and Cluster Computing [cs.DC]. Université Paris-Est, 2018. English. NNT : 2018PESC1078. tel- 02066140 HAL Id: tel-02066140 https://pastel.archives-ouvertes.fr/tel-02066140 Submitted on 13 Mar 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Université Paris-Est École doctorale MSTIC On Combinatorial Sur les algorithmes d’approximation Approximation combinatoires Algorithms en géométrie in Geometry Bruno Jartoux Thèse de doctorat en informatique soutenue le 12 septembre 2018. Composition du jury : Lilian Buzer ESIEE Paris Jean Cardinal Université libre de Bruxelles président du jury Guilherme Dias da Fonseca Université Clermont Auvergne rapporteur Jesús A. de Loera University of California, Davis rapporteur Frédéric Meunier École nationale des ponts et chaussées Nabil H. Mustafa ESIEE Paris directeur Vera Sacristán Universitat Politècnica de Catalunya Kasturi R. Varadarajan The University of Iowa rapporteur Last revised 16th December 2018. Thèse préparée au laboratoire d’informatique Gaspard-Monge (LIGM), équipe A3SI, dans les locaux d’ESIEE Paris. LIGM UMR 8049 ESIEE Paris Cité Descartes, bâtiment Copernic Département IT 5, boulevard Descartes Cité Descartes Champs-sur-Marne 2, boulevard Blaise-Pascal 77454 Marne-la-Vallée Cedex 2 93162 Noisy-le-Grand Cedex Bruno Jartoux 2018. -
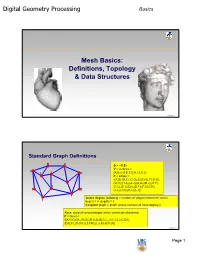
Digital Geometry Processing Mesh Basics
Digital Geometry Processing Basics Mesh Basics: Definitions, Topology & Data Structures 1 © Alla Sheffer Standard Graph Definitions G = <V,E> V = vertices = {A,B,C,D,E,F,G,H,I,J,K,L} E = edges = {(A,B),(B,C),(C,D),(D,E),(E,F),(F,G), (G,H),(H,A),(A,J),(A,G),(B,J),(K,F), (C,L),(C,I),(D,I),(D,F),(F,I),(G,K), (J,L),(J,K),(K,L),(L,I)} Vertex degree (valence) = number of edges incident on vertex deg(J) = 4, deg(H) = 2 k-regular graph = graph whose vertices all have degree k Face: cycle of vertices/edges which cannot be shortened F = faces = {(A,H,G),(A,J,K,G),(B,A,J),(B,C,L,J),(C,I,L),(C,D,I), (D,E,F),(D,I,F),(L,I,F,K),(L,J,K),(K,F,G)} © Alla Sheffer Page 1 Digital Geometry Processing Basics Connectivity Graph is connected if there is a path of edges connecting every two vertices Graph is k-connected if between every two vertices there are k edge-disjoint paths Graph G’=<V’,E’> is a subgraph of graph G=<V,E> if V’ is a subset of V and E’ is the subset of E incident on V’ Connected component of a graph: maximal connected subgraph Subset V’ of V is an independent set in G if the subgraph it induces does not contain any edges of E © Alla Sheffer Graph Embedding Graph is embedded in Rd if each vertex is assigned a position in Rd Embedding in R2 Embedding in R3 © Alla Sheffer Page 2 Digital Geometry Processing Basics Planar Graphs Planar Graph Plane Graph Planar graph: graph whose vertices and edges can Straight Line Plane Graph be embedded in R2 such that its edges do not intersect Every planar graph can be drawn as a straight-line plane graph © -

2020 SIGACT REPORT SIGACT EC – Eric Allender, Shuchi Chawla, Nicole Immorlica, Samir Khuller (Chair), Bobby Kleinberg September 14Th, 2020
2020 SIGACT REPORT SIGACT EC – Eric Allender, Shuchi Chawla, Nicole Immorlica, Samir Khuller (chair), Bobby Kleinberg September 14th, 2020 SIGACT Mission Statement: The primary mission of ACM SIGACT (Association for Computing Machinery Special Interest Group on Algorithms and Computation Theory) is to foster and promote the discovery and dissemination of high quality research in the domain of theoretical computer science. The field of theoretical computer science is the rigorous study of all computational phenomena - natural, artificial or man-made. This includes the diverse areas of algorithms, data structures, complexity theory, distributed computation, parallel computation, VLSI, machine learning, computational biology, computational geometry, information theory, cryptography, quantum computation, computational number theory and algebra, program semantics and verification, automata theory, and the study of randomness. Work in this field is often distinguished by its emphasis on mathematical technique and rigor. 1. Awards ▪ 2020 Gödel Prize: This was awarded to Robin A. Moser and Gábor Tardos for their paper “A constructive proof of the general Lovász Local Lemma”, Journal of the ACM, Vol 57 (2), 2010. The Lovász Local Lemma (LLL) is a fundamental tool of the probabilistic method. It enables one to show the existence of certain objects even though they occur with exponentially small probability. The original proof was not algorithmic, and subsequent algorithmic versions had significant losses in parameters. This paper provides a simple, powerful algorithmic paradigm that converts almost all known applications of the LLL into randomized algorithms matching the bounds of the existence proof. The paper further gives a derandomized algorithm, a parallel algorithm, and an extension to the “lopsided” LLL. -

Evolution of the Graphical Processing Unit
University of Nevada Reno Evolution of the Graphical Processing Unit A professional paper submitted in partial fulfillment of the requirements for the degree of Master of Science with a major in Computer Science by Thomas Scott Crow Dr. Frederick C. Harris, Jr., Advisor December 2004 Dedication To my wife Windee, thank you for all of your patience, intelligence and love. i Acknowledgements I would like to thank my advisor Dr. Harris for his patience and the help he has provided me. The field of Computer Science needs more individuals like Dr. Harris. I would like to thank Dr. Mensing for unknowingly giving me an excellent model of what a Man can be and for his confidence in my work. I am very grateful to Dr. Egbert and Dr. Mensing for agreeing to be committee members and for their valuable time. Thank you jeffs. ii Abstract In this paper we discuss some major contributions to the field of computer graphics that have led to the implementation of the modern graphical processing unit. We also compare the performance of matrix‐matrix multiplication on the GPU to the same computation on the CPU. Although the CPU performs better in this comparison, modern GPUs have a lot of potential since their rate of growth far exceeds that of the CPU. The history of the rate of growth of the GPU shows that the transistor count doubles every 6 months where that of the CPU is only every 18 months. There is currently much research going on regarding general purpose computing on GPUs and although there has been moderate success, there are several issues that keep the commodity GPU from expanding out from pure graphics computing with limited cache bandwidth being one. -

Computer Graphics CMU 15-462/15-662 Scotty 3D Setup Recitation Today! Hunt Library Computer Lab 3:30-5Pm
Digital Geometry Processing Computer Graphics CMU 15-462/15-662 Scotty 3D setup recitation Today! Hunt Library Computer Lab 3:30-5pm CMU 15-462/662 Last time part 1: overview of geometry Many types of geometry in nature Geometry Demand sophisticated representations Two major categories: - IMPLICIT - “tests” if a point is in shape - EXPLICIT - directly “lists” points Lots of representations for both CMU 15-462/662 Last time part 2: Meshes & Manifolds Mathematical description of geometry - simplifying assumption: manifold - for polygon meshes: “fans, not fins” Data structures for surfaces - polygon soup - halfedge mesh - storage cost vs. access time, etc. Today: next how do we manipulate geometry? twin - face edge - geometry processing / resampling Halfedge vertex CMU 15-462/662 Today: Geometry Processing & Queries Extend traditional digital signal processing (audio, video, etc.) to deal with geometric signals: - upsampling / downsampling / resampling / filtering ... - aliasing (reconstructed surface gives “false impression”) Also ask some basic questions about geometry: - What’s the closest point? Do two triangles intersect? Etc. Beyond pure geometry, these are basic building blocks for many algorithms in graphics (rendering, animation...) CMU 15-462/662 Digital Geometry Processing: Motivation 3D Scanning 3D Printing CMU 15-462/662 Geometry Processing Pipeline scan print process CMU 15-462/662 Geometry Processing Tasks reconstruction filtering remeshing parameterization compression shape analysis CMU 15-462/662 Geometry Processing: Reconstruction